Esercitazione: Usare Apache HBase in Azure HDInsight
Questa esercitazione illustra come creare un cluster Apache HBase in Azure HDInsight, come creare tabelle HBase e come eseguire query sulle tabelle con Apache Hive. Per informazioni generali su HBase, vedere Panoramica di HDInsight HBase.
In questa esercitazione apprenderai a:
- Creare un cluster Apache HBase
- Creare tabelle HBase e inserire dati
- Usare Hive per eseguire query su Apache HBase
- Usare le API REST HBase mediante Curl
- Controllare lo stato del cluster
Prerequisiti
Un client SSH. Per altre informazioni, vedere Connettersi a HDInsight (Apache Hadoop) con SSH.
Bash. Per i comandi curl, gli esempi in questo articolo usano la shell Bash in Windows 10. Per la procedura di installazione, vedere Guida all'installazione del sottosistema Windows per Linux per Windows 10. Anche altre shell Unix funzionano. Gli esempi di curl, con alcune lievi modifiche, funzionano in un prompt dei comandi di Windows. In alternativa, è possibile usare il cmdlet di Windows PowerShell Invoke-RestMethod.
Creare un cluster Apache HBase
La procedura seguente usa un modello di Azure Resource Manager per creare un cluster HBase. Il modello crea anche l'account di archiviazione di Azure predefinito dipendente. Per comprendere i parametri usati nella procedure e altri metodi di creazione del cluster, vedere Creare cluster Hadoop basati su Linux in HDInsight.
Selezionare l'immagine seguente per aprire il modello nel portale di Azure. Il modello si trova in Modelli di avvio rapido di Azure.

Nella finestra di dialogo Distribuzione personalizzata immettere i valori seguenti:
Proprietà Descrizione Abbonamento selezionare la sottoscrizione di Azure che viene usata per creare il cluster. Gruppo di risorse creare un nuovo gruppo di Azure Resource Manager o usarne uno esistente. Ufficio consente di specificare la posizione del gruppo di risorse. NomeCluster immettere un nome per il cluster HBase. ID di accesso e password del cluster Il nome di accesso predefinito è admin.Nome utente e password SSH Il nome utente predefinito è sshuser.Gli altri parametri sono facoltativi.
Ogni cluster ha una dipendenza dall'account di Archiviazione di Azure. Dopo aver eliminato un cluster, i dati rimangono nell'account di archiviazione. Il nome dell'account di archiviazione predefinito del cluster è il nome del cluster a cui viene aggiunto "store". È hardcoded nella sezione delle variabili del modello.
Selezionare Accetto le condizioni riportate sopra e quindi Acquista. La creazione di un cluster richiede circa 20 minuti.
Dopo l'eliminazione di un cluster HBase, è possibile creare un altro cluster HBase usando lo stesso contenitore BLOB predefinito. Il nuovo cluster seleziona le tabelle HBase create nel cluster originale. Per evitare incoerenze, è consigliabile disabilitare le tabelle HBase prima di eliminare il cluster.
Creare tabelle e inserire dati
È possibile usare SSH per connettersi ai cluster HBase e usare la shell di Apache HBase per creare tabelle HBase, inserire dati ed eseguire query sui dati.
Per la maggior parte delle persone, i dati vengono visualizzati in formato tabulare:

In HBase, che rappresenta un'implementazione di Cloud BigTable, gli stessi dati sono simili a:

Per usare la shell HBase
Usare il comando
sshper connettersi al cluster HBase. Modificare il comando seguente sostituendoCLUSTERNAMEcon il nome del cluster e quindi immettere il comando :ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netUsare il comando
hbase shellper avviare la shell interattiva di HBase. Immettere il comando seguente nella connessione SSH:hbase shellUsare
createil comando per creare una tabella HBase con famiglie a due colonne. I nomi di tabella e colonna fanno distinzione tra maiuscole e minuscole. Immettere il comando seguente:create 'Contacts', 'Personal', 'Office'Usare il comando
listper elencare tutte le tabelle in HBase. Immettere il comando seguente:listUsare il comando
putper inserire i valori per una determinata colonna in una determinata riga di una determinata tabella. Immettere i comandi seguenti:put 'Contacts', '1000', 'Personal:Name', 'John Dole' put 'Contacts', '1000', 'Personal:Phone', '1-425-000-0001' put 'Contacts', '1000', 'Office:Phone', '1-425-000-0002' put 'Contacts', '1000', 'Office:Address', '1111 San Gabriel Dr.'Usare il comando
scanper analizzare e restituire i dati della tabellaContacts. Immettere il comando seguente:scan 'Contacts'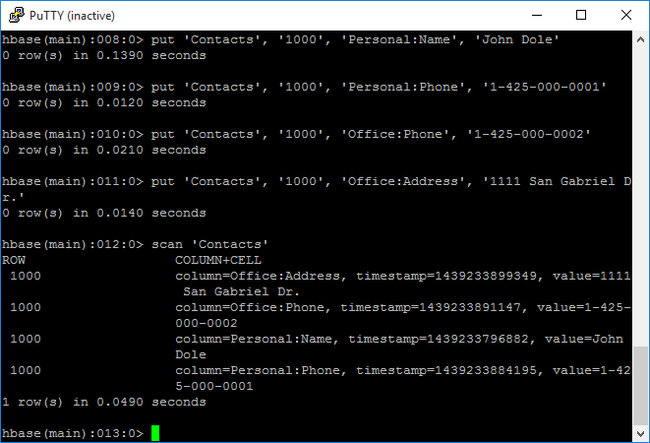
Usare il comando
getper recuperare il contenuto di una riga. Immettere il comando seguente:get 'Contacts', '1000'Verranno visualizzati risultati simili a quelli che si ottengono usando il comando
scanperché esiste solo una riga.Per altre informazioni sullo schema di tabella HBase, vedere Introduzione alla progettazione dello schema Apache HBase. Per altri comandi HBase, vedere Apache HBase Reference Guide (Guida di riferimento di Apache HBase).
Usare il comando
exitper interrompere la shell interattiva di HBase. Immettere il comando seguente:exit
Per il caricamento bulk dei dati nella tabella HBase dei contatti
HBase include diversi metodi di caricamento dei dati nelle tabelle. Per altre informazioni, vedere Caricamento bulk.
Un file di dati di esempio è disponibile in un contenitore BLOB pubblico, wasb://hbasecontacts@hditutorialdata.blob.core.windows.net/contacts.txt. Il contenuto del file di dati è il seguente:
8396 Calvin Raji 230-555-0191 230-555-0191 5415 San Gabriel Dr.
16600 Karen Wu 646-555-0113 230-555-0192 9265 La Paz
4324 Karl Xie 508-555-0163 230-555-0193 4912 La Vuelta
16891 Jonn Jackson 674-555-0110 230-555-0194 40 Ellis St.
3273 Miguel Miller 397-555-0155 230-555-0195 6696 Anchor Drive
3588 Osa Agbonile 592-555-0152 230-555-0196 1873 Lion Circle
10272 Julia Lee 870-555-0110 230-555-0197 3148 Rose Street
4868 Jose Hayes 599-555-0171 230-555-0198 793 Crawford Street
4761 Caleb Alexander 670-555-0141 230-555-0199 4775 Kentucky Dr.
16443 Terry Chander 998-555-0171 230-555-0200 771 Northridge Drive
È facoltativamente possibile creare un file di testo e caricare il file nel proprio account di archiviazione. Per le istruzioni, vedere Caricare dati per processi Apache Hadoop in HDInsight.
Questa procedura usa la tabella HBase Contacts creata nella procedura precedente.
Dalla connessione SSH aperta eseguire il comando seguente per trasformare il file di dati in StoreFiles e archiviarlo in un percorso relativo specificato da
Dimporttsv.bulk.output.hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.columns="HBASE_ROW_KEY,Personal:Name,Personal:Phone,Office:Phone,Office:Address" -Dimporttsv.bulk.output="/example/data/storeDataFileOutput" Contacts wasb://hbasecontacts@hditutorialdata.blob.core.windows.net/contacts.txtEseguire il comando seguente per caricare i dati da
/example/data/storeDataFileOutputnella tabella HBase:hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /example/data/storeDataFileOutput ContactsÈ possibile aprire la shell HBase e usare il comando
scanper visualizzare i contenuti della tabella.
Usare Hive per eseguire query su Apache HBase
È possibile eseguire query sui dati nelle tabelle HBase tramite Apache Hive. In questa sezione si crea una tabella Hive che esegue il mapping alla tabella HBase e la usa per la query dei dati nella tabella HBase.
Dalla connessione SSH aperta usare il comando seguente per avviare Beeline:
beeline -u 'jdbc:hive2://localhost:10001/;transportMode=http' -n adminPer altre informazioni su Beeline, vedere Usare Hive con Hadoop in HDInsight con Beeline.
Eseguire il seguente script HiveQL per creare una tabella Hive mappata alla tabella HBase. Prima di eseguire questa istruzione, assicurarsi di aver creato la tabella di esempio usata in precedenza come riferimento in questo articolo tramite la shell HBase.
CREATE EXTERNAL TABLE hbasecontacts(rowkey STRING, name STRING, homephone STRING, officephone STRING, officeaddress STRING) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ('hbase.columns.mapping' = ':key,Personal:Name,Personal:Phone,Office:Phone,Office:Address') TBLPROPERTIES ('hbase.table.name' = 'Contacts');Eseguire il seguente script HiveQL per eseguire query sui dati nella tabella HBase:
SELECT count(rowkey) AS rk_count FROM hbasecontacts;Per uscire da Beeline, usare
!exit.Per chiudere la connessione SSH, usare
exit.
Separare i cluster Hive e HBase
Non è necessario eseguire la query Hive per accedere ai dati di HBase dal cluster HBase. Per eseguire query sui dati di HBase si può usare qualsiasi cluster fornito con Hive (inclusi Spark, Hadoop, HBase o Interactive Query), purché siano stati completati i passaggi seguenti:
- Collegare entrambi i cluster alla stessa rete virtuale e alla stessa subnet
- Copiare
/usr/hdp/$(hdp-select --version)/hbase/conf/hbase-site.xmli nodi head del cluster HBase nei nodi head e del ruolo di lavoro del cluster Hive.
Proteggere i cluster
È possibile eseguire query sui dati di HBase da Hive anche tramite HBase abilitato per ESP:
- Se si segue un modello multicluster, entrambi i cluster devono essere abilitati per ESP.
- Per consentire a Hive di eseguire query sui dati di HBase, assicurarsi che all'utente
hivesiano concesse le autorizzazioni per accedere ai dati di HBase tramite il plug-in Apache Ranger HBase - Quando si usano cluster separati abilitati per ESP, il contenuto dei
/etc/hostsnodi head del cluster HBase deve essere aggiunto ai/etc/hostsnodi head del cluster Hive e di lavoro.
Nota
Se si ridimensiona uno dei cluster, /etc/hosts deve essere accodato di nuovo
Usare l'API REST HBase tramite Curl
L'API REST HBase è protetta tramite l'autenticazione di base. Le richieste vengono sempre eseguite usando il protocollo HTTPS (Secure HTTP) per essere certi che le credenziali vengano inviate in modo sicuro al server.
Per abilitare l'API REST HBase nel cluster HDInsight, aggiungere lo script di avvio personalizzato seguente alla sezione Azione script. È possibile aggiungere lo script di avvio durante la creazione del cluster o successivamente. Per Tipo di nodo selezionare Server di area per assicurarsi che lo script venga eseguito solo in server di area HBase. Lo script avvia il proxy REST HBase sulla porta 8090 nei server di area.
#! /bin/bash THIS_MACHINE=`hostname` if [[ $THIS_MACHINE != wn* ]] then printf 'Script to be executed only on worker nodes' exit 0 fi RESULT=`pgrep -f RESTServer` if [[ -z $RESULT ]] then echo "Applying mitigation; starting REST Server" sudo python /usr/lib/python2.7/dist-packages/hdinsight_hbrest/HbaseRestAgent.py else echo "REST server already running" exit 0 fiImpostare la variabile di ambiente per semplicità d'uso. Modificare i comandi seguenti sostituendo
MYPASSWORDcon la password di accesso del cluster. SostituireMYCLUSTERNAMEcon il nome del cluster HBase e quindi immettere i comandi.export PASSWORD='MYPASSWORD' export CLUSTER_NAME=MYCLUSTERNAMEUsare il comando seguente per ottenere l'elenco delle tabelle HBase esistenti:
curl -u admin:$PASSWORD \ -G https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Usare il comando seguente per creare una nuova tabella HBase con famiglie di due colonne:
curl -u admin:$PASSWORD \ -X PUT "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/schema" \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -d "{\"@name\":\"Contact1\",\"ColumnSchema\":[{\"name\":\"Personal\"},{\"name\":\"Office\"}]}" \ -vLo schema viene fornito nel formato JSON.
Usare il comando seguente per inserire alcuni dati:
curl -u admin:$PASSWORD \ -X PUT "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/false-row-key" \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -d "{\"Row\":[{\"key\":\"MTAwMA==\",\"Cell\": [{\"column\":\"UGVyc29uYWw6TmFtZQ==\", \"$\":\"Sm9obiBEb2xl\"}]}]}" \ -vÈ necessario applicare la codifica Base 64 ai valori specificati nell'opzione -d. Nell'esempio:
MTAwMA==: 1000
UGVyc29uYWw6TmFtZQ==: Personal: Name
Sm9obiBEb2xl: John Dole
false-row-key consente di inserire più valori in batch.
Usare il comando seguente per ottenere una riga:
curl -u admin:$PASSWORD \ GET "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/1000" \ -H "Accept: application/json" \ -v
Nota
L'analisi tramite l'endpoint del cluster non è ancora supportata.
Per altre informazioni sulle API REST HBase, vedere la Apache HBase Reference Guide(Guida di riferimento di Apache HBase).
Nota
Thrift non è supportato da HBase in HDInsight.
Quando si usa Curl o qualsiasi altra comunicazione REST con WebHCat, è necessario autenticare le richieste specificando il nome utente e la password per l'amministratore del cluster HDInsight. È anche necessario specificare il nome del cluster come parte dell'URI (Uniform Resource Identifier) usato per inviare le richieste al server:
curl -u <UserName>:<Password> \
-G https://<ClusterName>.azurehdinsight.net/templeton/v1/status
Verrà visualizzato un messaggio simile alla risposta seguente:
{"status":"ok","version":"v1"}
Controllare lo stato del cluster
HBase in HDInsight viene fornito con un'interfaccia utente Web per il monitoraggio dei cluster. Usando l’interfaccia Web è possibile richiedere statistiche o informazioni sulle aree.
Per accedere all'interfaccia utente master HBase
Accedere all'interfaccia utente Web Ambari all'indirizzo
https://CLUSTERNAME.azurehdinsight.net, doveCLUSTERNAMEè il nome del cluster HBase.Selezionare HBase dal menu a sinistra.
Selezionare Collegamenti rapidi nella parte superiore della pagina, scegliere il collegamento del nodo Zookeeper attivo e quindi selezionare HBase Master UI (Interfaccia utente HBase Master). L'interfaccia utente viene aperta in un'altra scheda del browser:
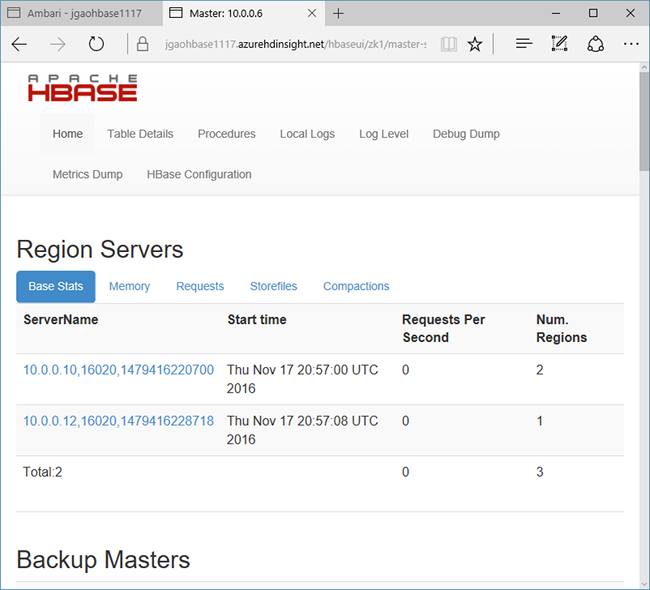
L'interfaccia utente master HBase contiene le sezioni seguenti:
- server di zona
- master di backup
- tabelle
- attività
- attributi di software
Ricreazione del cluster
Dopo l'eliminazione di un cluster HBase, è possibile creare un altro cluster HBase usando lo stesso contenitore BLOB predefinito. Il nuovo cluster seleziona le tabelle HBase create nel cluster originale. Per evitare incoerenze, è tuttavia consigliabile disabilitare le tabelle HBase prima di eliminare il cluster.
È possibile usare il comando HBase disable 'Contacts'.
Pulire le risorse
Se non si intende continuare a usare questa applicazione, eliminare il cluster HBase creato con i passaggi seguenti:
- Accedere al portale di Azure.
- Nella casella Ricerca in alto digitare HDInsight.
- Selezionare Cluster HDInsight in Servizi.
- Nell'elenco di cluster HDInsight visualizzato, fare clic su ... accanto al cluster creato per questa esercitazione.
- Fare clic su Elimina. Fare clic su Sì.
Passaggi successivi
In questa esercitazione si è appreso come creare un cluster Apache HBase. Si è anche visto come creare tabelle e visualizzare i dati in tali tabelle dalla shell HBase, come usare una query Hive sui dati nelle tabelle HBase E come usare l'API REST C# di HBase per creare una tabella HBase e recuperare i dati dalla tabella. Per altre informazioni, vedere: