Kernel per Jupyter Notebook nei cluster Apache Spark in Azure HDInsight
I cluster HDInsight Spark forniscono kernel che è possibile usare con Jupyter Notebook in Apache Spark per testare le applicazioni. Un kernel è un programma che esegue e interpreta il codice. I tre kernel sono:
- PySpark (per le applicazioni scritte in Python2) (Applicabile solo per i cluster versione Spark 2.4)
- PySpark3 (per le applicazioni scritte in Python3)
- Spark (per le applicazioni scritte in Scala)
In questo articolo viene illustrato come usare questi kernel e i vantaggi che ne derivano.
Prerequisiti
Un cluster Apache Spark in HDInsight. Per istruzioni, vedere l'articolo dedicato alla creazione di cluster Apache Spark in Azure HDInsight.
Creare Jupyter Notebook in HDInsight Spark
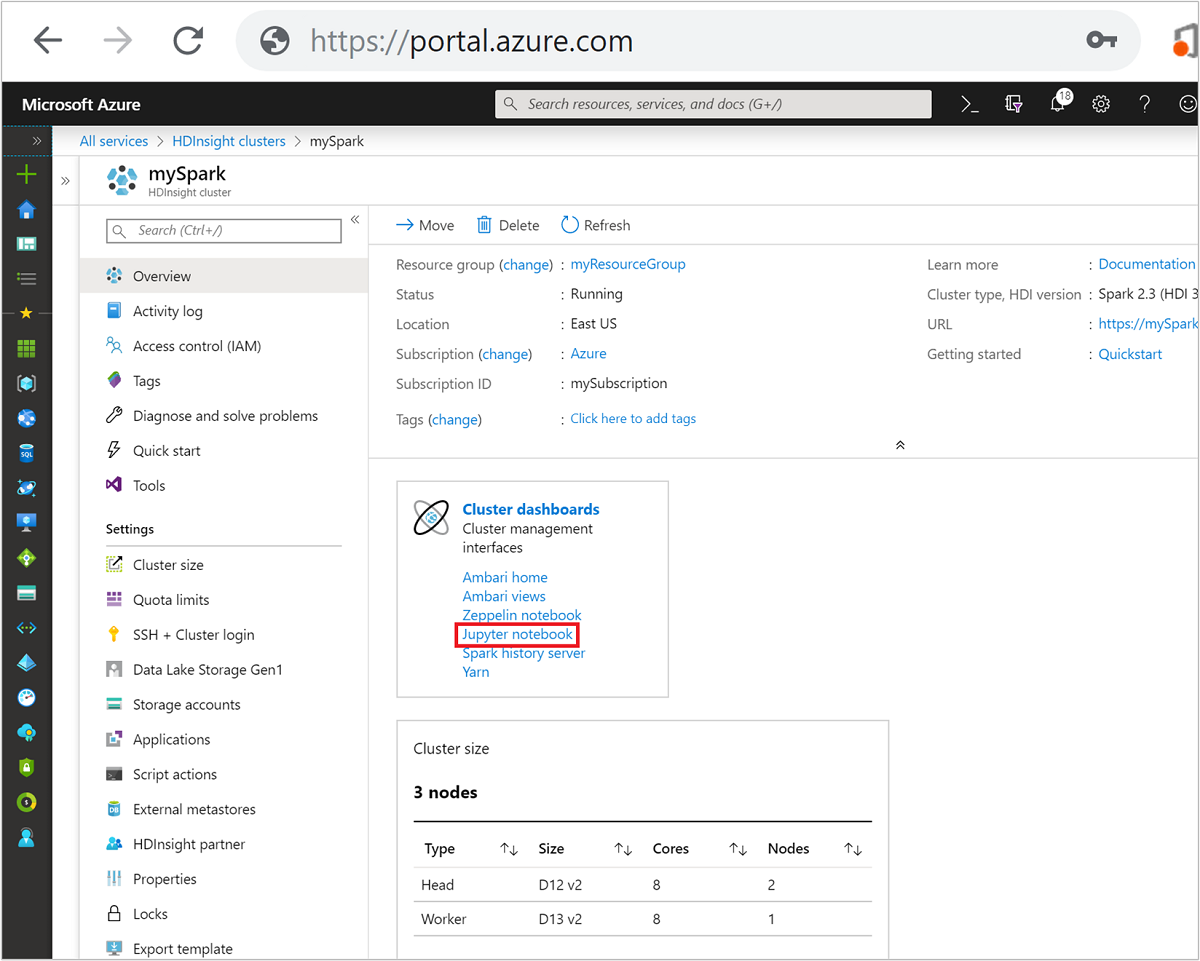
Selezionare il proprio cluster Spark nel portale di Azure. Per le istruzioni vedere la sezione su come elencare e visualizzare i cluster. Si apre la visualizzazione Panoramica.
Dalla visualizzazione Panoramica, nella casella Dashboard del cluster, selezionare Jupyter Notebook. Se richiesto, immettere le credenziali per il cluster.
Nota
È anche possibile accedere Jupyter Notebook nel cluster Spark aprendo l'URL seguente nel proprio browser. Sostituire CLUSTERNAME con il nome del cluster:
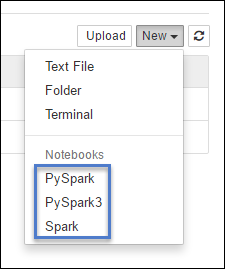
https://CLUSTERNAME.azurehdinsight.net/jupyterSelezionare Nuovo e quindi Pyspark, PySpark3 o Spark per creare un notebook. Usare il kernel Spark per applicazioni Scala, il kernel PySpark per applicazioni Python2 e il kernel PySpark3 per applicazioni Python3.
Nota
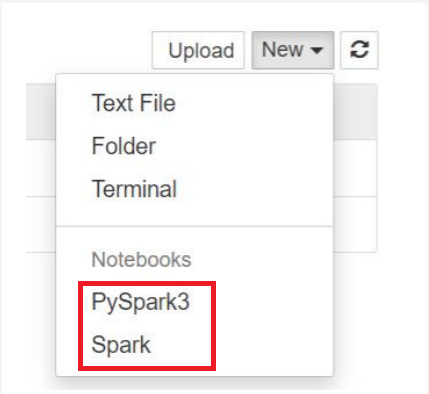
Per Spark 3.1, saranno disponibili solo PySpark3o Spark.
- Verrà aperto un notebook con il kernel selezionato.
Vantaggi offerti dall'uso dei kernel
Ecco alcuni vantaggi associati all'uso dei nuovi kernel con Jupyter Notebook nei cluster HDInsight Spark.
Contesti predefiniti. Con il kernel PySpark, PySpark3 o Spark non è necessario impostare i contesti Spark o Hive in modo esplicito prima di iniziare a usare le applicazioni. Questi contesti sono disponibili per impostazione predefinita. Questi contesti sono:
sc : per il contesto Spark
sqlContext : per il contesto Hive
Quindi non è necessario eseguire istruzioni simili alle seguenti per impostare i contesti:
sc = SparkContext('yarn-client') sqlContext = HiveContext(sc)È possibile invece usare direttamente i contesti preimpostati nell'applicazione.
Celle magic. Il kernel PySpark offre alcuni "magic" predefiniti. Si tratta di comandi speciali che è possibile chiamare con
%%, ad esempio%%MAGIC<args>. Il comando magic deve essere la prima parola di una cella di codice e consente di generare più righe di contenuto. La parola magic deve essere la prima della cella. L'aggiunta di qualsiasi elemento prima del comando magic, anche un commento, causa un errore. Per altre informazioni sui magic, vedere questa pagina.La tabella seguente elenca i diversi magic disponibili tramite i kernel.
Magic Esempio Descrizione help %%helpGenera una tabella di tutti i magic disponibili con esempi e descrizioni info %%infoVisualizza informazioni sulla sessione per l'endpoint Livy corrente CONFIGURA %%configure -f{"executorMemory": "1000M","executorCores": 4}Configura i parametri per la creazione di una sessione. Il flag di forzatura ( -f) è obbligatorio se è già stata creata una sessione, affinché tale sessione venga eliminata e ricreata. Visitare la pagina relativa al corpo della richiesta POST/sessions di Livy per un elenco dei parametri validi. I parametri devono essere passati come una stringa JSON e devono essere nella riga successiva al magic, come illustrato nella colonna di esempio.sql %%sql -o <variable name>
SHOW TABLESEsegue una query Hive su sqlContext. Se viene passato il parametro -o, il risultato della query viene salvato in modo permanente nel contesto Python %%local come frame di dati Pandas .local %%locala=1Tutto il codice presente nelle righe successive viene eseguito localmente. Il codice deve essere codice Python2 valido indipendentemente dal kernel in uso. Anche se durante la creazione del notebook si è selezionato il kernel PySpark3 o Spark, se si usa il magic %%localin una cella, tale cella deve contenere solo codice Python2 valido.log %%logsVisualizza i log per la sessione Livy corrente. eliminare %%delete -f -s <session number>Elimina una sessione specifica dell'endpoint Livy corrente. Non è possibile eliminare la sessione avviata per il kernel stesso. cleanup %%cleanup -fElimina tutte le sessioni per l'endpoint Livy corrente, inclusa quella del notebook. Il flag di forzatura -f è obbligatorio. Nota
Oltre ai magic aggiunti dal kernel PySpark, è possibile anche usare i magic IPython incorporati, tra cui
%%sh. È possibile usare il magic%%shper eseguire script e il blocco del codice nel nodo head del cluster.Visualizzazione automatica. Il kernel Pyspark visualizza automaticamente l'output delle query Hive e SQL. È possibile scegliere tra diversi tipi di visualizzazione, inclusi Table, Pie, Line, Area e Bar.
Parametri supportati con il magic %%sql
Il magic %%sql supporta parametri diversi che è possibile usare per controllare la tipologia di output che si riceve quando si eseguono query. La tabella seguente elenca l'output.
| Parametro | Esempio | Descrizione |
|---|---|---|
| -o | -o <VARIABLE NAME> |
Usare questo parametro per salvare in modo permanente il risultato della query nel contesto Python %%local come frame di dati Pandas . Il nome della variabile del frame di dati è il nome della variabile specificato. |
| -q | -q |
Usare questo parametro per disattivare le visualizzazioni per la cella. Se non si vuole visualizzare automaticamente il contenuto di una cella ma solo acquisirlo come un frame di dati, usare -q -o <VARIABLE>. Se si vogliono disattivare le visualizzazioni senza acquisire i risultati, ad esempio per l'esecuzione di una query SQL come un'istruzione CREATE TABLE, usare -q senza specificare un argomento -o. |
| -m | -m <METHOD> |
Dove METHOD è take o sample. L'impostazione predefinita è take. Se il metodo è take, il kernel sceglie gli elementi dall'inizio del set di dati dei risultati specificato da MAXROWS, descritto più avanti in questa tabella. Se il metodo è sample, il kernel campiona in modo casuale gli elementi del set di dati in base al parametro -r descritto di seguito in questa tabella. |
| -r | -r <FRACTION> |
Qui FRACTION è un numero a virgola mobile compreso tra 0,0 e 1,0. Se il metodo di campionamento per la query SQL è sample, il kernel campiona automaticamente in modo casuale la frazione specificata degli elementi del set di risultati. Se si esegue una query SQL con gli argomenti -m sample -r 0.01, ad esempio, viene campionato in modo casuale l'1% delle righe dei risultati. |
| -n | -n <MAXROWS> |
MAXROWS è un valore intero. Il kernel limita il numero di righe di output a MAXROWS. Se MAXROWS è un numero negativo, ad esempio -1, il numero di righe nel set di risultati non è limitato. |
Esempio:
%%sql -q -m sample -r 0.1 -n 500 -o query2
SELECT * FROM hivesampletable
L'istruzione precedente esegue le azioni seguenti:
- Seleziona tutti i record da hivesampletable.
- Poiché viene usato -q, disattiva la visualizzazione automatica.
- Dal momento che si usa
-m sample -r 0.1 -n 500, campiona in modo casuale il 10% delle righe di hivesampletable e limita la dimensione del set di risultati a 500 righe. - Infine, poiché è stato usato
-o query2, salva anche l'oputput in un frame di dati denominato query2.
Considerazioni per l'uso dei nuovi kernel
Indipendentemente dal kernel usato, se si lasciano i notebook in esecuzione vengono utilizzate risorse del cluster. Con questi kernel, poiché i contesti sono preimpostati, l'uscita dai notebook non termina il contesto. Le risorse del cluster quindi continuano a essere in uso. È consigliabile usare l'opzione Chiudi e interrompi dal menu file del notebook al termine dell'uso del notebook. Questa chiusura elimina il contesto e quindi esce dal notebook.
Dove sono archiviati i notebook
Se il cluster usa Archiviazione di Azure come account di archiviazione predefinito, i Jupyter Notebook vengono salvati nell'account di archiviazione nella cartella /HdiNotebooks. I notebook, i file di testo e le cartelle che si creano da Jupyter sono accessibili dall'account di archiviazione. Se si usa Jupyter per creare una cartella myfolder e un notebook myfolder/mynotebook.ipynb, ad esempio, è possibile accedere al notebook in /HdiNotebooks/myfolder/mynotebook.ipynb all'interno dell'account di archiviazione. Analogamente, se si carica un notebook direttamente nell'account di archiviazione in /HdiNotebooks/mynotebook1.ipynb, il notebook è visibile anche da Jupyter. I notebook vengono conservati nell'account di archiviazione anche dopo l'eliminazione del cluster.
Nota
I cluster HDInsight con Azure Data Lake Storage come spazio di archiviazione predefinito non archiviano i notebook nello spazio di archiviazione associato.
La modalità di salvataggio dei notebook nell'account di archiviazione è compatibile con Apache Hadoop HDFS. Se si esegue SSH nel cluster, è possibile usare i comandi di gestione dei file seguenti:
| Comando | Descrizione |
|---|---|
hdfs dfs -ls /HdiNotebooks |
# Elencare tutti gli elementi nella directory radice: tutto ciò che in questa directory è visibile a Jupyter dalla home page |
hdfs dfs –copyToLocal /HdiNotebooks |
# Scaricare il contenuto della cartella HdiNotebooks |
hdfs dfs –copyFromLocal example.ipynb /HdiNotebooks |
# Caricare un notebook example.ipynb nella cartella radice in modo che sia visibile da Jupyter |
Indipendentemente dal fatto che il cluster usi Archiviazione di Azure o Azure Data Lake Storage come account di archiviazione predefinito, i notebook vengono salvati anche nel nodo head del cluster in /var/lib/jupyter.
Browser supportati
Jupyter Notebook nei cluster HDInsight Spark sono supportati solo su Google Chrome.
Suggerimenti
I nuovi kernel sono ancora in una fase iniziale e si evolveranno nel tempo. Le API potrebbero quindi cambiare man mano che tali kernel maturano. Sono graditi commenti e suggerimenti in merito all'uso di questi nuovi kernel. Saranno molto utili feedback per la progettazione della versione finale di questi kernel. È possibile inserire commenti/feedback nella sezione Commenti in fondo a questo articolo.