Introduzione all'uso dei dati DICOM nei carichi di lavoro di analisi
Questo articolo descrive come iniziare a usare i dati DICOM® nei carichi di lavoro di analisi con Azure Data Factory e Microsoft Fabric.
Prerequisiti
Prima di iniziare, completare questi passaggi:
- Creare un account di archiviazione con le funzionalità di Azure Data Lake Storage Gen2 abilitando uno spazio dei nomi gerarchico:
- Creare un contenitore per archiviare i metadati DICOM, ad esempio denominati
dicom.
- Creare un contenitore per archiviare i metadati DICOM, ad esempio denominati
- Distribuire un'istanza del servizio DICOM.
- (Facoltativo) Distribuire il servizio DICOM con Data Lake Storage per abilitare l'accesso diretto ai file DICOM.
- Creare un'istanza Data Factory:
- Abilitare un'identità gestita assegnata dal sistema.
- Creare un lakehouse in Fabric.
- Aggiungere assegnazioni di ruolo all'identità gestita assegnata dal sistema di Data Factory per il servizio DICOM e l'account di archiviazione Data Lake Storage Gen2:
- Aggiungere il ruolo lettore dati DICOM per concedere l'autorizzazione al servizio DICOM.
- Aggiungere il ruolo Collaboratore ai dati del BLOB di archiviazione per concedere l'autorizzazione all'account Data Lake Storage Gen2.
Configurare una pipeline di Data Factory per il servizio DICOM
In questo esempio viene usata una pipeline di Data Factory per scrivere attributi DICOM per istanze, serie e studi in un account di archiviazione in un formato tabella Delta.
Nel portale di Azure aprire l'istanza di Data Factory e selezionare Avvia studio per iniziare.

Creare servizi collegati
Le pipeline di Data Factory leggono da origini dati e scrivono in sink di dati, che in genere sono altri servizi di Azure. Queste connessioni ad altri servizi vengono gestite come servizi collegati.
La pipeline in questo esempio legge i dati da un servizio DICOM e ne scrive l'output in un account di archiviazione, quindi è necessario creare un servizio collegato per entrambi.
Creare un servizio collegato per il servizio DICOM
In Azure Data Factory Studio selezionare Gestisci dal menu a sinistra. In Connessioni, selezionare Servizi collegati e quindi selezionare Nuovo.

Nel riquadro Nuovo servizio collegato, cercare REST. Selezionare la sezione REST e quindi selezionare Continua.

Immettere un Nome e una Descrizione per il servizio collegato.

Nel campo URL di base, immettere l'URL del servizio per il servizio DICOM. Ad esempio, un servizio DICOM denominato
contosoclinicnell'area di lavorocontosohealthha l'URL del serviziohttps://contosohealth-contosoclinic.dicom.azurehealthcareapis.com.Per tipo di autenticazione, selezionare Identità gestita assegnata dal sistema.
Per risorsa AAD, immettere
https://dicom.healthcareapis.azure.com. Questo URL è lo stesso per tutte le istanze del servizio DICOM.Dopo aver compilato i campi obbligatori, selezionare Test connessione per assicurarsi che i ruoli dell'identità siano configurati correttamente.
Quando il test di connessione ha esito positivo, selezionare Crea.



Creare un servizio collegato per Azure Data Lake Storage Gen2
In Data Factory Studio selezionare Gestisci dal menu a sinistra. In Connessioni, selezionare Servizi collegati e quindi selezionare Nuovo.
Nel riquadro Nuovo servizio collegato, cercare Azure Data Lake Storage Gen2. Selezionare la sezione Azure Data Lake Storage Gen2 e quindi selezionare Continua.
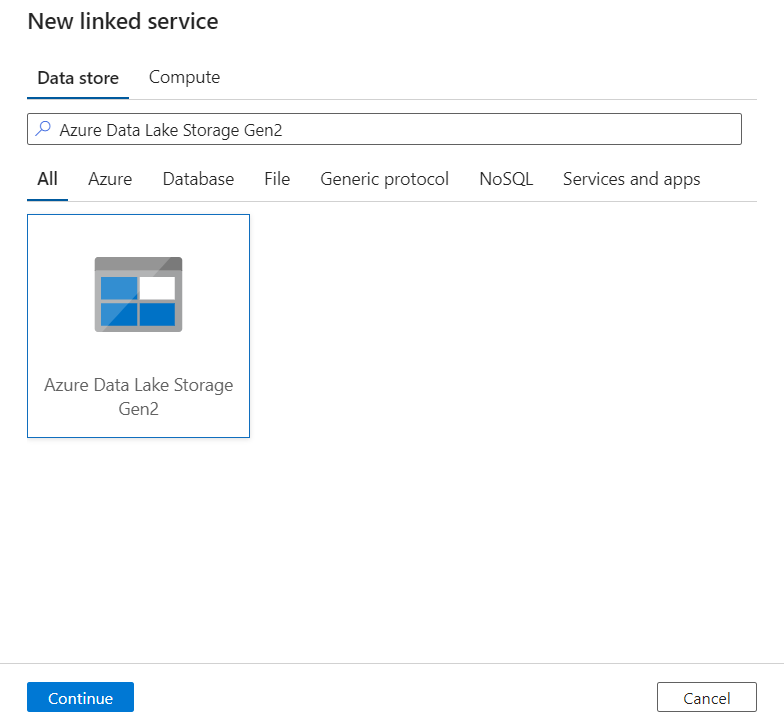
Immettere un Nome e una Descrizione per il servizio collegato.

Per tipo di autenticazione, selezionare Identità gestita assegnata dal sistema.
Immettere i dettagli dell'account di archiviazione immettendo manualmente l'URL dell'account di archiviazione. È anche possibile selezionare la sottoscrizione di Azure e l'account di archiviazione nell'elenco a discesa.
Dopo aver compilato i campi obbligatori, selezionare Test connessione per assicurarsi che i ruoli dell'identità siano configurati correttamente.
Quando il test di connessione ha esito positivo, selezionare Crea.


Creare una pipeline per i dati DICOM
Le pipeline di Data Factory sono una raccolta di attività che eseguono un'attività, ad esempio la copia dei metadati DICOM nelle tabelle Delta. Questa sezione descrive in dettaglio la creazione di una pipeline che sincronizza regolarmente i dati DICOM con le tabelle Delta man mano che i dati vengono aggiunti, aggiornati ed eliminati da un servizio DICOM.
Selezionare Autore dal menu a sinistra. Nel riquadro Risorse factory, selezionare il segno più (+) per aggiungere una nuova risorsa. Selezionare Pipeline e quindi selezionare Raccolta modelli dal menu.

Nella Raccolta modelli, cercare DICOM. Selezionare la sezione Copia Modifiche metadati DICOM Metadata in ADLS Gen2 in formato Delta e quindi selezionare Continua.
Nella sezione Input, selezionare i servizi collegati creati in precedenza per il servizio DICOM e l'account Data Lake Storage Gen2.
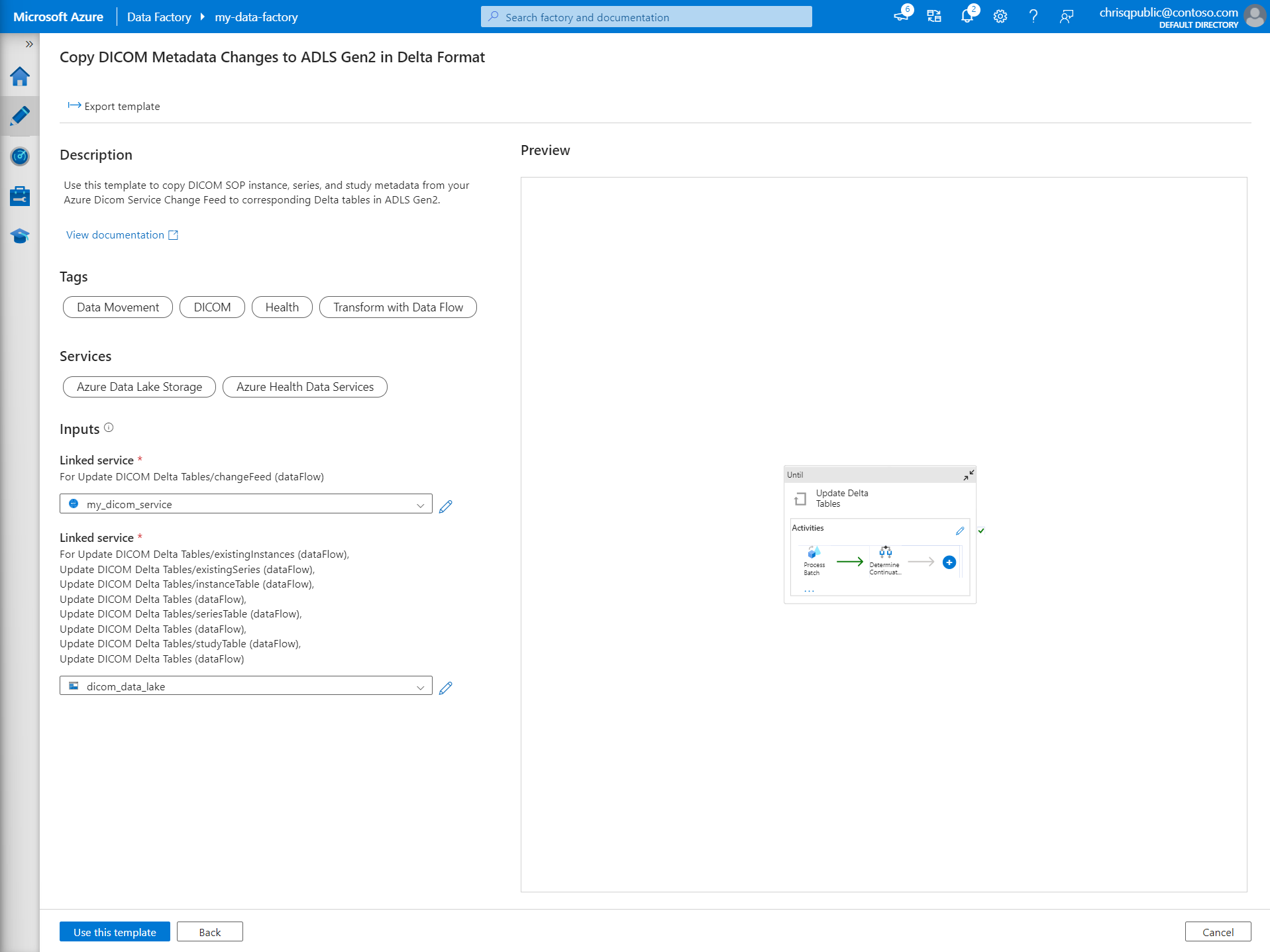
Selezionare Usa questo modello per creare la nuova pipeline.



Creare una pipeline per i dati DICOM
Se è stato creato il servizio DICOM con Azure Data Lake Storage, anziché usare il modello dalla raccolta di modelli, è necessario usare un modello personalizzato per includere un nuovo parametro fileName nella pipeline di metadati. Per configurare la pipeline, seguire questa procedura.
Scaricare il modello da GitHub. Il file modello è una cartella compressa. Non è necessario estrarre i file perché sono già caricati in formato compresso.
In Azure Data Factory, selezionare Autore dal menu a sinistra. Nel riquadro Risorse factory, selezionare il segno più (+) per aggiungere una nuova risorsa. Selezionare Pipeline e quindi selezionare Importa dal modello di pipeline.
Nella finestra Apri, selezionare il modello scaricato. Selezionare Apri.
Nella sezione Input, selezionare i servizi collegati creati per il servizio DICOM e l'account Azure Data Lake Storage Gen2.
Selezionare Usa questo modello per creare la nuova pipeline.
Pianificare una pipeline
Le pipeline vengono pianificate da trigger. Esistono diversi tipi di trigger. I trigger di pianificazione consentono l'esecuzione delle pipeline in orari specifici del giorno, ad esempio ogni ora o ogni giorno a mezzanotte. Trigger manuali pipeline di trigger su richiesta, ovvero vengono eseguiti ogni volta che si desidera.
In questo esempio, viene usato un trigger finestra a cascata per eseguire periodicamente la pipeline in base a un punto di partenza e a un intervallo di tempo regolare. Per altre informazioni sui trigger, vedere Esecuzione e trigger della pipeline in Azure Data Factory o Azure Synapse Analytics.
Creare un nuovo trigger di finestra a cascata
Selezionare Autore dal menu a sinistra. Selezionare la pipeline per il servizio DICOM e selezionare Aggiungi trigger e Nuovo/Modifica dalla barra dei menu.

Nel riquadro Aggiungi trigger, selezionare l'elenco a discesa Scegli trigger e quindi selezionare Nuovo.
Immettere un Nome e una Descrizione per il trigger.

Selezionare Finestra a cascata come Tipo.
Per configurare una pipeline che viene eseguita ogni ora, impostare Ricorrenza su 1 ora.
Espandere la sezione Avanzate e immettere un Ritardo di 15 minuti. Questa impostazione consente il completamento di tutte le operazioni in sospeso alla fine di un'ora prima dell'elaborazione.
Impostare Max concorrenza su 1 per garantire la coerenza tra le tabelle.
Selezionare OK per continuare a configurare i parametri di esecuzione del trigger.


Configurare i parametri di esecuzione del trigger
I trigger definiscono quando viene eseguita una pipeline. Includono anche parametri passati all'esecuzione della pipeline. Il modello Copia modifiche metadati DICOM in Delta definisce i parametri descritti nella tabella seguente. Se non viene specificato alcun valore durante la configurazione, viene usato il valore predefinito elencato per ogni parametro.
| Nome parametro | Descrizione | Default value |
|---|---|---|
| BatchSize | Numero massimo di modifiche da recuperare alla volta dal feed di modifiche (massimo 200) | 200 |
| ApiVersion | Versione API per il servizio DICOM di Azure (minimo 2) | 2 |
| StartTime | Ora di inizio inclusiva per le modifiche di DICOM | 0001-01-01T00:00:00Z |
| EndTime | Ora di fine esclusiva per le modifiche di DICOM | 9999-12-31T23:59:59Z |
| ContainerName | Nome del contenitore per le tabelle Delta risultanti | dicom |
| InstanceTablePath | Percorso che contiene la tabella Delta per le istanze DICOM SOP all'interno del contenitore | instance |
| SeriesTablePath | Percorso che contiene la tabella Delta per la serie DICOM all'interno del contenitore | series |
| StudyTablePath | Percorso che contiene la tabella Delta per gli studi DICOM all'interno del contenitore | study |
| RetentionHours | Conservazione massima in ore per i dati nelle tabelle Delta | 720 |
Nel riquadro Parametri di esecuzione trigger, immettere il valore ContainerName corrispondente al nome del contenitore di archiviazione creato nei prerequisiti.

Per StartTime, usare la variabile di sistema
@formatDateTime(trigger().outputs.windowStartTime).Per EndTime, usare la variabile di sistema
@formatDateTime(trigger().outputs.windowEndTime).Nota
Solo i trigger finestra a cascata supportano le variabili di sistema:
@trigger().outputs.windowStartTimee@trigger().outputs.windowEndTime.
I trigger di pianificazione usano variabili di sistema diverse:
@trigger().scheduledTimee@trigger().startTime.
Altre informazioni sul tipo di trigger.
Selezionare Salva per creare il nuovo trigger. Selezionare Pubblica per avviare il trigger in esecuzione nella pianificazione definita.



Dopo la pubblicazione, il trigger può essere attivato manualmente usando l'opzione Trigger ora. Se l'ora di inizio è stata impostata per un valore in passato, la pipeline viene avviata immediatamente.
Monitorare le esecuzioni delle pipeline
È possibile monitorare le esecuzioni attivate e le relative esecuzioni di pipeline associate nella scheda Monitoraggio. In questo caso, è possibile esplorare quando ogni pipeline è stata eseguita e il tempo necessario per l'esecuzione. È anche possibile eseguire il debug di eventuali problemi che si sono verificati.

Microsoft Fabric
Fabric è una soluzione di analisi all-in-one che si trova su Microsoft OneLake. Con l'uso di un Fabric lakehouse, è possibile gestire, strutturare e analizzare i dati in OneLake in un'unica posizione. Tutti i dati all'esterno di OneLake, scritti in Data Lake Storage Gen2, possono essere connessi a OneLake usando collegamenti per sfruttare la suite di strumenti di Fabric.
Creare collegamenti alle tabelle di metadati
Passare al lakehouse creato nei prerequisiti. Nella visualizzazione Explorer selezionare il menu con i puntini di sospensione (...) accanto alla cartella Tabelle.
Selezionare Nuovo collegamento per creare un nuovo collegamento all'account di archiviazione che contiene i dati di analisi DICOM.

Selezionare Azure Data Lake Storage Gen2 come origine per il collegamento.
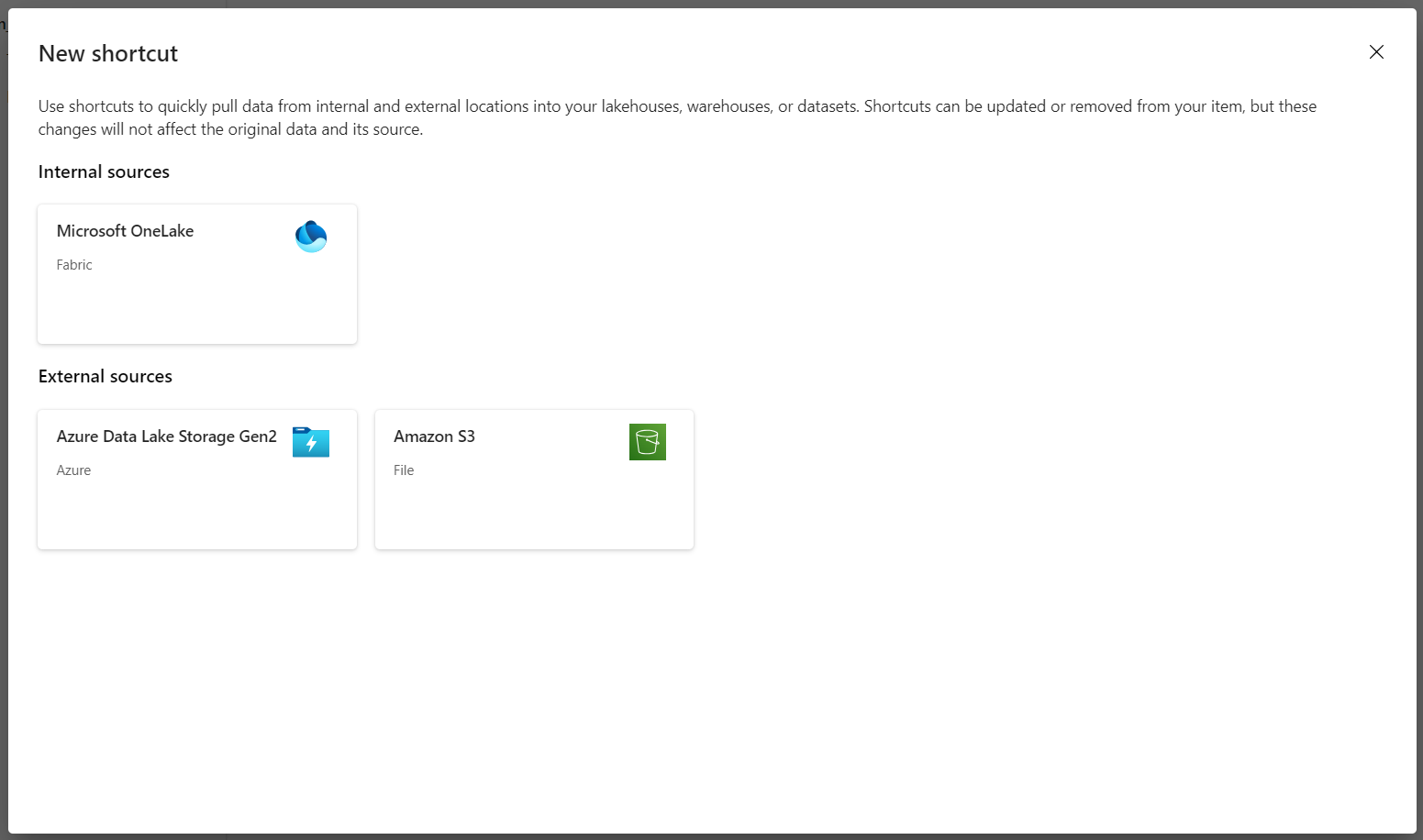
In Impostazioni di connessione, immettere l'URL usato nella sezione Servizi collegati.

Selezionare una connessione esistente o creare una nuova connessione selezionando il Tipo di autenticazione da usare.
Nota
Sono disponibili alcune opzioni per l'autenticazione tra Data Lake Storage Gen2 e Fabric. È possibile usare un account aziendale o un'entità servizio. Non è consigliabile usare chiavi dell'account o token di firma di accesso condiviso.
Selezionare Avanti.
Immettere un Nome collegamento che rappresenta i dati creati dalla pipeline di Data Factory. Ad esempio, per la tabella
instanceDelta, è probabile che il nome del collegamento sia l'istanza.Immettere il Sub Path corrispondente al parametro
ContainerNameda parametri di esecuzione configurazione e il nome della tabella per il collegamento. Ad esempio, usare/dicom/instanceper la tabella Delta con il percorsoinstancenel contenitoredicom.Selezionare Crea per creare il collegamento.
Ripetere i passaggi da 2 a 9 per aggiungere i collegamenti rimanenti alle altre tabelle Delta nell'account di archiviazione, ad esempio
seriesestudy.



Dopo aver creato i collegamenti, espandere una tabella per visualizzare i nomi e i tipi delle colonne.

Creare collegamenti ai file
Se si usa un servizio DICOM con Data Lake Storage, è anche possibile creare un collegamento ai dati del file DICOM archiviati nel data lake.
Passare al lakehouse creato nei prerequisiti. Nella visualizzazione Explorer, selezionare il menu con i puntini di sospensione (...) accanto alla cartella File.
Selezionare Nuovo collegamento per creare un nuovo collegamento all'account di archiviazione che contiene i dati DICOM.

Selezionare Azure Data Lake Storage Gen2 come origine per il collegamento.
In Impostazioni di connessione, immettere l'URL usato nella sezione Servizi collegati.
Selezionare una connessione esistente o creare una nuova connessione selezionando il Tipo di autenticazione da usare.
Selezionare Avanti.
Immettere un Nome collegamento che descrive i dati DICOM. Ad esempio, contoso-dicom-files.
Immettere il Sub Path corrispondente al nome del contenitore di archiviazione e della cartella usata dal servizio DICOM. Ad esempio, se si vuole collegare alla cartella radice, il percorso secondario sarà /dicom/AHDS. La cartella radice è sempre
AHDS, ma facoltativamente è possibile collegarsi a una cartella secondaria per un'area di lavoro specifica o un'istanza del servizio DICOM.Selezionare Crea per creare il collegamento.


Eseguire notebook
Dopo aver creato le tabelle nel lakehouse, è possibile eseguirne una query dai notebook di Fabric. È possibile creare notebook direttamente dal lakehouse selezionando Apri notebook dalla barra dei menu.
Nella pagina del notebook è possibile visualizzare il contenuto del lakehouse sul lato sinistro, incluse le tabelle appena aggiunte. Nella parte superiore della pagina selezionare la lingua per il notebook. La lingua può essere configurata anche per singole celle. Nell'esempio seguente viene utilizzata Spark SQL.
Eseguire query sulle tabelle con Spark SQL
Nell'editor di celle immettere una query Spark SQL come un'istruzione SELECT.
SELECT * from instance
Questa query seleziona tutto il contenuto della tabella instance. Quando si è pronti, selezionare Esegui cella per eseguire la query.

Dopo alcuni secondi, i risultati della query vengono visualizzati in una tabella sotto la cella, come illustrato nell'esempio seguente. Il tempo potrebbe essere maggiore se questa query Spark è la prima nella sessione perché il contesto Spark deve essere inizializzato.

Accedere ai dati dei file DICOM nei notebook
Se è stato usato un modello per creare la pipeline e creare un collegamento ai dati del file DICOM, è possibile usare la colonna filePath nella tabella instance per correlare i metadati dell'istanza ai dati del file.
SELECT sopInstanceUid, filePath from instance

Riepilogo
In questo articolo si è appreso come:
- Usare i modelli di Data Factory per creare una pipeline dal servizio DICOM in un account Data Lake Storage Gen2.
- Configurare un trigger per estrarre i metadati DICOM in base a una pianificazione oraria.
- Usare i collegamenti per connettere i dati DICOM in un account di archiviazione a un'infrastruttura lakehouse.
- Usare i notebook per eseguire query per i dati DICOM in lakehouse.
Passaggi successivi
Nota
DICOM® è il marchio registrato della National Electrical Manufacturers Association per le sue pubblicazioni Standard relative alle comunicazioni digitali delle informazioni mediche.