Configurare Hub eventi di Azure e endpoint del flusso di dati Kafka
Importante
Questa pagina include istruzioni per la gestione dei componenti di Operazioni IoT di Azure usando i manifesti di distribuzione kubernetes, disponibile in anteprima. Questa funzionalità viene fornita con diverse limitazioni e non deve essere usata per i carichi di lavoro di produzione.
Vedere le condizioni per l'utilizzo supplementari per le anteprime di Microsoft Azure per termini legali aggiuntivi che si applicano a funzionalità di Azure in versione beta, in anteprima o in altro modo non ancora disponibili a livello generale.
Per configurare la comunicazione bidirezionale tra le operazioni IoT di Azure e i broker Apache Kafka, è possibile configurare un endpoint del flusso di dati. Questa configurazione consente di specificare l'endpoint, Transport Layer Security (TLS), l'autenticazione e altre impostazioni.
Prerequisiti
- Istanza delle operazioni di Azure IoT
Hub eventi di Azure
Hub eventi di Azure è compatibile con il protocollo Kafka e può essere usato con i flussi di dati con alcune limitazioni.
Creare uno spazio dei nomi e un hub eventi Hub eventi di Azure
Creare prima di tutto uno spazio dei nomi Hub eventi di Azure abilitato per Kafka
Creare quindi un hub eventi nello spazio dei nomi . Ogni singolo hub eventi corrisponde a un argomento Kafka. È possibile creare più hub eventi nello stesso spazio dei nomi per rappresentare più argomenti Kafka.
Assegnare l'autorizzazione all'identità gestita
Per configurare un endpoint del flusso di dati per Hub eventi di Azure, è consigliabile usare un'identità gestita assegnata dall'utente o assegnata dal sistema. Questo approccio è sicuro ed elimina la necessità di gestire manualmente le credenziali.
Dopo aver creato lo spazio dei nomi e l'hub eventi Hub eventi di Azure, è necessario assegnare un ruolo all'identità gestita di Operazioni IoT di Azure che concede l'autorizzazione per inviare o ricevere messaggi all'hub eventi.
Se si usa l'identità gestita assegnata dal sistema, in portale di Azure passare all'istanza di Operazioni IoT di Azure e selezionare Panoramica. Copiare il nome dell'estensione elencata dopo l'estensione Azure IoT Operations Arc. Ad esempio, azure-iot-operations-xxxx7. L'identità gestita assegnata dal sistema è disponibile usando lo stesso nome dell'estensione Azure IoT Operations Arc.
Passare quindi allo spazio dei nomi >di Hub eventi Controllo di accesso (IAM)>Aggiungi assegnazione di ruolo.
- Nella scheda Ruolo selezionare un ruolo appropriato, ad esempio
Azure Event Hubs Data SenderoAzure Event Hubs Data Receiver. In questo modo l'identità gestita ha le autorizzazioni necessarie per inviare o ricevere messaggi per tutti gli hub eventi nello spazio dei nomi. Per altre informazioni, vedere Autenticare un'applicazione con Microsoft Entra ID per accedere alle risorse di Hub eventi. - Nella scheda Membri :
- Se si usa l'identità gestita assegnata dal sistema, per Assegna accesso a, selezionare l'opzione Utente, gruppo o entità servizio, quindi selezionare + Seleziona membri e cercare il nome dell'estensione Azure IoT Operations Arc.
- Se si usa l'identità gestita assegnata dall'utente, per Assegna accesso a, selezionare l'opzione Identità gestita, quindi selezionare + Seleziona membri e cercare l'identità gestita assegnata dall'utente configurata per le connessioni cloud.
Creare un endpoint del flusso di dati per Hub eventi di Azure
Dopo aver configurato lo spazio dei nomi Hub eventi di Azure e l'hub eventi, è possibile creare un endpoint del flusso di dati per lo spazio dei nomi abilitato per Kafka Hub eventi di Azure.
Nell'esperienza operativa selezionare la scheda Endpoint flusso di dati.
In Crea nuovo endpoint del flusso di dati selezionare Hub eventi di Azure> Nuovo.
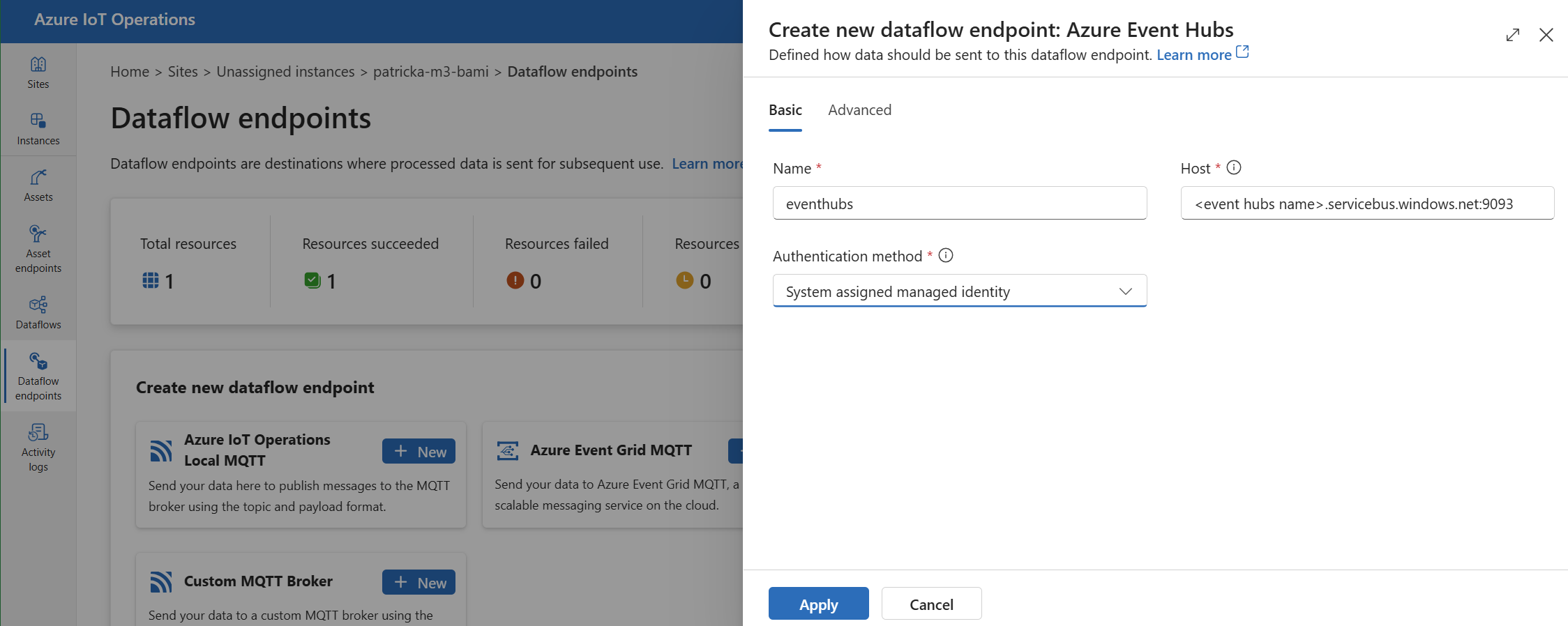
Immettere le impostazioni seguenti per l'endpoint:
Impostazione Description Nome Nome dell'endpoint del flusso di dati. Host Nome host del broker Kafka nel formato <NAMESPACE>.servicebus.windows.net:9093. Includere il numero9093di porta nell'impostazione host per Hub eventi.Metodo di autenticazione Metodo utilizzato per l'autenticazione. È consigliabile scegliere Identità gestita assegnata dal sistema o Identità gestita assegnata dall'utente. Selezionare Applica per effettuare il provisioning dell'endpoint.
Nota
L'argomento Kafka, o un singolo hub eventi, viene configurato in un secondo momento quando si crea il flusso di dati. L'argomento Kafka è la destinazione per i messaggi del flusso di dati.
Usare stringa di connessione per l'autenticazione in Hub eventi
Importante
Per usare il portale dell'esperienza operativa per gestire i segreti, le operazioni IoT di Azure devono prima essere abilitate con impostazioni sicure configurando un insieme di credenziali delle chiavi di Azure e abilitando le identità del carico di lavoro. Per altre informazioni, vedere Abilitare le impostazioni sicure nella distribuzione di Operazioni IoT di Azure.
Nella pagina Delle impostazioni dell'endpoint del flusso di dati dell'esperienza operativa selezionare la scheda Basic e quindi scegliere SasL del metodo>di autenticazione.
Immettere le impostazioni seguenti per l'endpoint:
| Impostazione | Descrizione |
|---|---|
| Tipo SASL | Scegliere Plain. |
| Nome segreto sincronizzato | Immettere un nome del segreto Kubernetes che contiene il stringa di connessione. |
| Riferimento al nome utente o segreto del token | Riferimento al nome utente o al segreto del token usato per l'autenticazione SASL. Selezionarlo dall'elenco Key Vault o crearne uno nuovo. Il valore deve essere $ConnectionString. |
| Informazioni di riferimento sulla password del segreto del token | Riferimento alla password o al segreto del token usato per l'autenticazione SASL. Selezionarlo dall'elenco Key Vault o crearne uno nuovo. Il valore deve essere nel formato .Endpoint=sb://<NAMESPACE>.servicebus.windows.net/;SharedAccessKeyName=<KEY-NAME>;SharedAccessKey=<KEY> |
Dopo aver selezionato Aggiungi riferimento, se si seleziona Crea nuovo, immettere le impostazioni seguenti:
| Impostazione | Descrizione |
|---|---|
| Nome segreto | Nome del segreto in Azure Key Vault. Selezionare un nome facile da ricordare per selezionare il segreto in un secondo momento dall'elenco. |
| Valore segreto | Per il nome utente immettere $ConnectionString. Per la password, immettere il stringa di connessione nel formato Endpoint=sb://<NAMESPACE>.servicebus.windows.net/;SharedAccessKeyName=<KEY-NAME>;SharedAccessKey=<KEY>. |
| Impostare la data di attivazione | Se attivata, data in cui il segreto diventa attivo. |
| Impostare la data di scadenza | Se attivata, data di scadenza del segreto. |
Per altre informazioni sui segreti, vedere Creare e gestire segreti nelle operazioni IoT di Azure.
Limiti
Hub eventi di Azure non supporta tutti i tipi di compressione supportati da Kafka. Attualmente è supportata solo la compressione GZIP nei livelli premium e dedicati Hub eventi di Azure. L'uso di altri tipi di compressione potrebbe causare errori.
Broker Kafka personalizzati
Per configurare un endpoint del flusso di dati per broker Kafka non hub eventi, impostare l'host, TLS, l'autenticazione e altre impostazioni in base alle esigenze.
Nell'esperienza operativa selezionare la scheda Endpoint flusso di dati.
In Create new dataflow endpoint (Crea nuovo endpoint del flusso di dati) selezionare Custom Kafka Broker New (Nuovo broker>Kafka personalizzato).
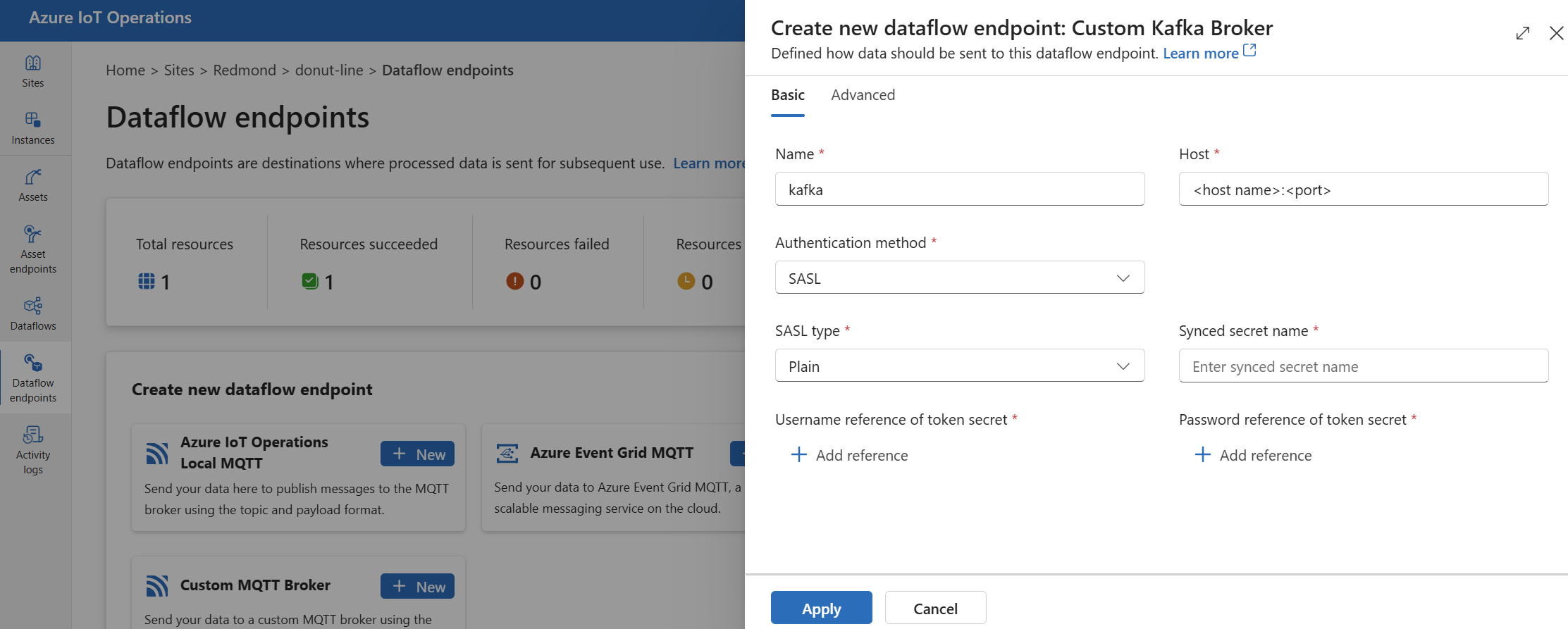
Immettere le impostazioni seguenti per l'endpoint:
Impostazione Description Nome Nome dell'endpoint del flusso di dati. Host Nome host del broker Kafka nel formato <Kafka-broker-host>:xxxx. Includere il numero di porta nell'impostazione host.Metodo di autenticazione Metodo utilizzato per l'autenticazione. Scegliere SASL. Tipo SASL Tipo di autenticazione SASL. Scegliere Plain, ScramSha256 o ScramSha512. Obbligatorio se si usa SASL. Nome segreto sincronizzato Nome del segreto. Obbligatorio se si usa SASL. Riferimento al nome utente del segreto del token Riferimento al nome utente nel segreto del token SASL. Obbligatorio se si usa SASL. Selezionare Applica per effettuare il provisioning dell'endpoint.
Nota
Attualmente, l'esperienza operativa non supporta l'uso di un endpoint del flusso di dati Kafka come origine. È possibile creare un flusso di dati con un endpoint del flusso di dati Kafka di origine usando Kubernetes o Bicep.
Per personalizzare le impostazioni dell'endpoint, usare le sezioni seguenti per altre informazioni.
Metodi di autenticazione disponibili
Per gli endpoint del flusso di dati del broker Kafka sono disponibili i metodi di autenticazione seguenti.
Identità gestita assegnata dal sistema
Prima di configurare l'endpoint del flusso di dati, assegnare un ruolo all'identità gestita di Operazioni IoT di Azure che concede l'autorizzazione per connettersi al broker Kafka:
- In portale di Azure passare all'istanza di Operazioni IoT di Azure e selezionare Panoramica.
- Copiare il nome dell'estensione elencata dopo l'estensione Azure IoT Operations Arc. Ad esempio, azure-iot-operations-xxxx7.
- Passare alla risorsa cloud necessaria per concedere le autorizzazioni. Ad esempio, passare allo spazio dei nomi >di Hub eventi Controllo di accesso (IAM)>Aggiungi assegnazione di ruolo.
- Nella scheda Ruolo selezionare un ruolo appropriato.
- Nella scheda Membri , per Assegna accesso a, selezionare l'opzione Utente, gruppo o entità servizio, quindi selezionare + Seleziona membri e cercare l'identità gestita di Operazioni IoT di Azure. Ad esempio, azure-iot-operations-xxxx7.
Configurare quindi l'endpoint del flusso di dati con le impostazioni di identità gestite assegnate dal sistema.
Nella pagina Delle impostazioni dell'endpoint del flusso di dati dell'esperienza operativa selezionare la scheda Basic e quindi scegliere Metodo di>autenticazione Identità gestita assegnata dal sistema.
Questa configurazione crea un'identità gestita con il gruppo di destinatari predefinito, che corrisponde al valore host dello spazio dei nomi di Hub eventi sotto forma di https://<NAMESPACE>.servicebus.windows.net. Tuttavia, se è necessario eseguire l'override del gruppo di destinatari predefinito, è possibile impostare il audience campo sul valore desiderato.
Non supportato nell'esperienza operativa.
Identità gestita assegnata dall'utente
Per usare l'identità gestita assegnata dall'utente per l'autenticazione, è prima necessario distribuire le operazioni IoT di Azure con impostazioni sicure abilitate. È quindi necessario configurare un'identità gestita assegnata dall'utente per le connessioni cloud. Per altre informazioni, vedere Abilitare le impostazioni sicure nella distribuzione di Operazioni IoT di Azure.
Prima di configurare l'endpoint del flusso di dati, assegnare un ruolo all'identità gestita assegnata dall'utente che concede l'autorizzazione per connettersi al broker Kafka:
- In portale di Azure passare alla risorsa cloud necessaria per concedere le autorizzazioni. Ad esempio, passare allo spazio dei nomi >Griglia di eventi Controllo di accesso (IAM)>Aggiungi assegnazione di ruolo.
- Nella scheda Ruolo selezionare un ruolo appropriato.
- Nella scheda Membri selezionare l'opzione Identità gestita per Assegnare l'accesso, quindi selezionare + Seleziona membri e cercare l'identità gestita assegnata dall'utente.
Configurare quindi l'endpoint del flusso di dati con le impostazioni di identità gestite assegnate dall'utente.
Nella pagina Delle impostazioni dell'endpoint del flusso di dati dell'esperienza operativa selezionare la scheda Basic e quindi scegliere Metodo di autenticazione>Identità gestita assegnata dall'utente.
In questo caso, l'ambito è il gruppo di destinatari dell'identità gestita. Il valore predefinito è uguale al valore host dello spazio dei nomi di Hub eventi sotto forma di https://<NAMESPACE>.servicebus.windows.net. Tuttavia, se è necessario eseguire l'override del gruppo di destinatari predefinito, è possibile impostare il campo ambito sul valore desiderato usando Bicep o Kubernetes.
SASL
Per usare SASL per l'autenticazione, specificare il metodo di autenticazione SASL e configurare il tipo SASL e un riferimento segreto con il nome del segreto che contiene il token SASL.
Nella pagina Delle impostazioni dell'endpoint del flusso di dati dell'esperienza operativa selezionare la scheda Basic e quindi scegliere SasL del metodo>di autenticazione.
Immettere le impostazioni seguenti per l'endpoint:
| Impostazione | Descrizione |
|---|---|
| Tipo SASL | Tipo di autenticazione SASL da usare. I tipi supportati sono Plain, ScramSha256e ScramSha512. |
| Nome segreto sincronizzato | Nome del segreto Kubernetes che contiene il token SASL. |
| Riferimento al nome utente o segreto del token | Riferimento al nome utente o al segreto del token usato per l'autenticazione SASL. |
| Informazioni di riferimento sulla password del segreto del token | Riferimento alla password o al segreto del token usato per l'autenticazione SASL. |
I tipi SASL supportati sono:
PlainScramSha256ScramSha512
Il segreto deve trovarsi nello stesso spazio dei nomi dell'endpoint del flusso di dati Kafka. Il segreto deve avere il token SASL come coppia chiave-valore.
Anonimo
Per usare l'autenticazione anonima, aggiornare la sezione di autenticazione delle impostazioni Kafka per usare il metodo Anonimo.
Nella pagina Delle impostazioni dell'endpoint del flusso di dati dell'esperienza operativa selezionare la scheda Basic e quindi scegliere Metodo di autenticazione>Nessuno.
Impostazioni avanzate
È possibile impostare impostazioni avanzate per l'endpoint del flusso di dati Kafka, ad esempio TLS, certificato CA attendibile, impostazioni di messaggistica Kafka, invio in batch e CloudEvents. È possibile impostare queste impostazioni nella scheda Del portale avanzato dell'endpoint del flusso di dati o nella risorsa endpoint del flusso di dati.
Nell'esperienza operativa selezionare la scheda Avanzate per l'endpoint del flusso di dati.
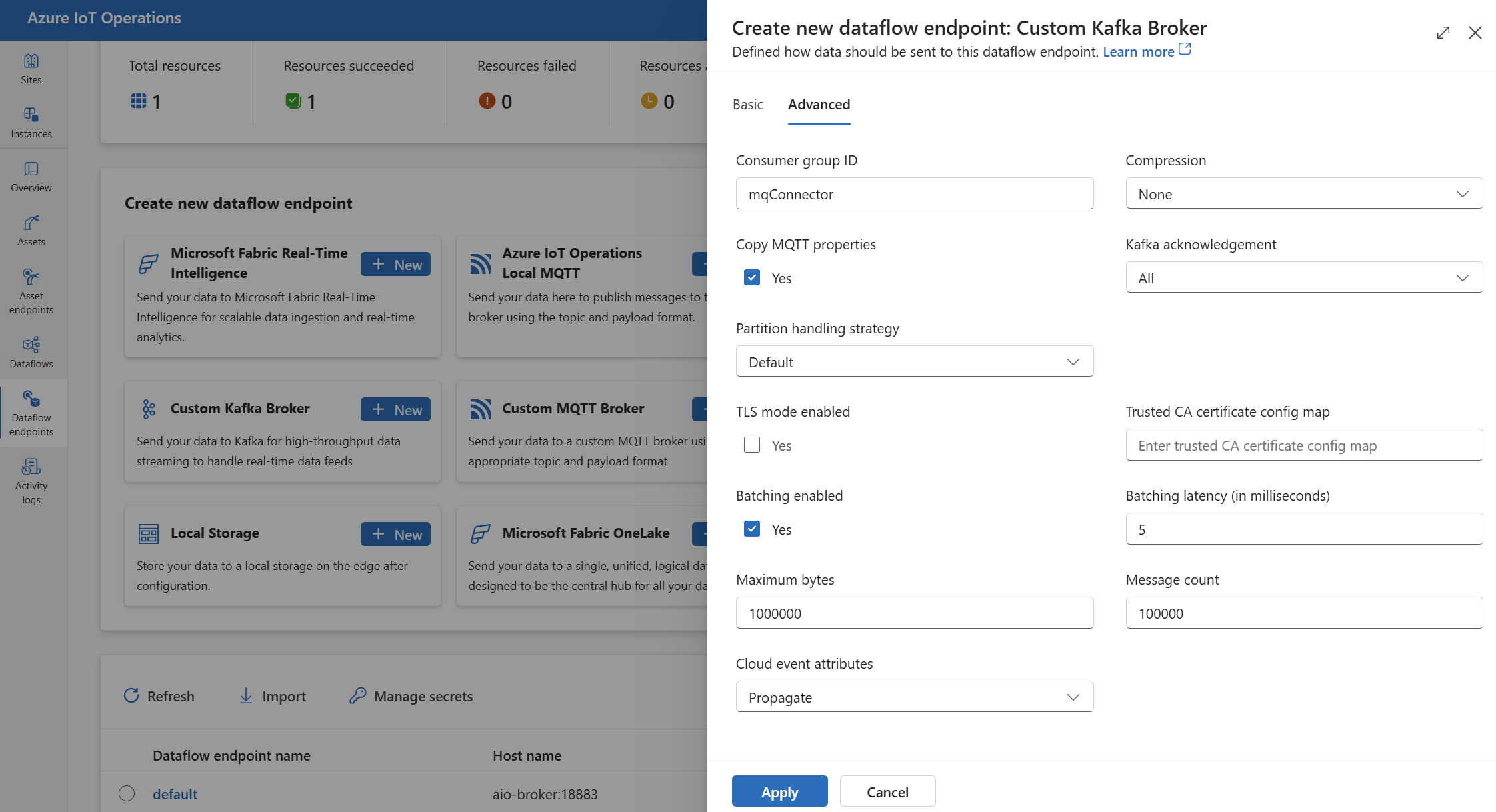
Impostazioni di TLS
Modalità TLS
Per abilitare o disabilitare TLS per l'endpoint Kafka, aggiornare l'impostazione mode nelle impostazioni TLS.
Nella pagina Delle impostazioni dell'endpoint del flusso di dati dell'esperienza operativa selezionare la scheda Avanzate e quindi usare la casella di controllo accanto alla modalità TLS abilitata.
La modalità TLS può essere impostata su Enabled o Disabled. Se la modalità è impostata su Enabled, il flusso di dati usa una connessione sicura al broker Kafka. Se la modalità è impostata su Disabled, il flusso di dati usa una connessione non sicura al broker Kafka.
Certificato CA attendibile
Configurare il certificato CA attendibile per l'endpoint Kafka per stabilire una connessione sicura al broker Kafka. Questa impostazione è importante se il broker Kafka usa un certificato autofirmato o un certificato firmato da una CA personalizzata non considerata attendibile per impostazione predefinita.
Nella pagina Delle impostazioni dell'endpoint del flusso di dati dell'esperienza operativa selezionare la scheda Avanzate e quindi usare il campo Mappa configurazione certificato CA attendibile per specificare l'oggetto ConfigMap contenente il certificato CA attendibile.
Questo ConfigMap deve contenere il certificato della CA in formato PEM. ConfigMap deve trovarsi nello stesso spazio dei nomi della risorsa del flusso di dati Kafka. Ad esempio:
kubectl create configmap client-ca-configmap --from-file root_ca.crt -n azure-iot-operations
Suggerimento
Quando ci si connette a Hub eventi di Azure, il certificato della CA non è necessario perché il servizio Hub eventi usa un certificato firmato da una CA pubblica considerata attendibile per impostazione predefinita.
ID gruppo di consumer
L'ID del gruppo di consumer viene usato per identificare il gruppo di consumer usato dal flusso di dati per leggere i messaggi dall'argomento Kafka. L'ID del gruppo di consumer deve essere univoco all'interno del broker Kafka.
Importante
Quando l'endpoint Kafka viene usato come origine, è necessario l'ID del gruppo di consumer. In caso contrario, il flusso di dati non può leggere i messaggi dall'argomento Kafka e viene visualizzato un errore "Gli endpoint di origine del tipo Kafka devono avere un consumerGroupId definito".
Nella pagina Delle impostazioni dell'endpoint del flusso di dati dell'esperienza operativa selezionare la scheda Avanzate e quindi usare il campo ID gruppo consumer per specificare l'ID del gruppo di consumer.
Questa impostazione ha effetto solo se l'endpoint viene usato come origine, ovvero il flusso di dati è un consumer.
Compressione
Il campo di compressione abilita la compressione per i messaggi inviati agli argomenti Kafka. La compressione consente di ridurre la larghezza di banda di rete e lo spazio di archiviazione necessario per il trasferimento dei dati. Tuttavia, la compressione aggiunge anche un sovraccarico e una latenza al processo. I tipi di compressione supportati sono elencati nella tabella seguente.
| valore | Descrizione |
|---|---|
None |
Non viene applicata alcuna compressione o invio in batch. Nessuno è il valore predefinito se non viene specificata alcuna compressione. |
Gzip |
Vengono applicati la compressione e l'invio in batch GZIP. GZIP è un algoritmo di compressione per utilizzo generico che offre un buon equilibrio tra rapporto di compressione e velocità. Attualmente è supportata solo la compressione GZIP nei livelli premium e dedicati Hub eventi di Azure. |
Snappy |
Vengono applicati la compressione snappy e l'invio in batch. Snappy è un algoritmo di compressione veloce che offre un rapporto di compressione moderato e velocità. Questa modalità di compressione non è supportata da Hub eventi di Azure. |
Lz4 |
Vengono applicati la compressione e l'invio in batch LZ4. LZ4 è un algoritmo di compressione veloce che offre un rapporto di compressione basso e una velocità elevata. Questa modalità di compressione non è supportata da Hub eventi di Azure. |
Per configurare la compressione:
Nella pagina Impostazioni endpoint flusso di dati dell'esperienza operativa selezionare la scheda Avanzate e quindi usare il campo Compressione per specificare il tipo di compressione.
Questa impostazione ha effetto solo se l'endpoint viene usato come destinazione in cui il flusso di dati è un producer.
Batch
Oltre alla compressione, è anche possibile configurare l'invio in batch per i messaggi prima di inviarli agli argomenti Kafka. L'invio in batch consente di raggruppare più messaggi e comprimerli come singola unità, migliorando così l'efficienza di compressione e riducendo il sovraccarico di rete.
| Campo | Descrizione | Richiesto |
|---|---|---|
mode |
Può essere Enabled o Disabled. Il valore predefinito è Enabled dovuto al fatto che Kafka non ha una nozione di messaggistica senza problemi . Se impostato su Disabled, l'invio in batch viene ridotto a icona per creare un batch con un singolo messaggio ogni volta. |
No |
latencyMs |
Intervallo di tempo massimo in millisecondi che i messaggi possono essere memorizzati nel buffer prima dell'invio. Se viene raggiunto questo intervallo, tutti i messaggi memorizzati nel buffer vengono inviati come batch, indipendentemente dal numero o dalla loro dimensione. Se non è impostato, il valore predefinito è 5. | No |
maxMessages |
Numero massimo di messaggi che possono essere memorizzati nel buffer prima dell'invio. Se viene raggiunto questo numero, tutti i messaggi memorizzati nel buffer vengono inviati come batch, indipendentemente dalla dimensione o dalla durata del buffer. Se non è impostato, il valore predefinito è 100000. | No |
maxBytes |
Dimensioni massime in byte che possono essere memorizzate nel buffer prima dell'invio. Se viene raggiunta questa dimensione, tutti i messaggi memorizzati nel buffer vengono inviati come batch, indipendentemente dal numero o dalla durata del buffer. Il valore predefinito è 1000000 (1 MB). | No |
Ad esempio, se si impostano i messaggi latencym su 1000, maxMessages su 100 e maxBytes su 1024, i messaggi vengono inviati quando sono presenti 100 messaggi nel buffer o quando sono presenti 1.024 byte nel buffer o quando sono trascorsi 1.000 millisecondi dall'ultimo invio, a ogni occorrenza.
Per configurare l'invio in batch:
Nella pagina Delle impostazioni dell'endpoint del flusso di dati dell'esperienza operativa selezionare la scheda Avanzate e quindi usare il campo Batch abilitato per abilitare l'invio in batch. Usare i campi Latenza batch, Numero massimo di byte e Conteggio messaggi per specificare le impostazioni di invio in batch.
Questa impostazione ha effetto solo se l'endpoint viene usato come destinazione in cui il flusso di dati è un producer.
Strategia di gestione delle partizioni
La strategia di gestione delle partizioni controlla il modo in cui i messaggi vengono assegnati alle partizioni Kafka durante l'invio agli argomenti Kafka. Le partizioni Kafka sono segmenti logici di un argomento Kafka che consentono l'elaborazione parallela e la tolleranza di errore. Ogni messaggio in un argomento Kafka ha una partizione e un offset, che vengono usati per identificare e ordinare i messaggi.
Questa impostazione ha effetto solo se l'endpoint viene usato come destinazione in cui il flusso di dati è un producer.
Per impostazione predefinita, un flusso di dati assegna messaggi a partizioni casuali, usando un algoritmo round robin. Tuttavia, è possibile usare strategie diverse per assegnare messaggi alle partizioni in base ad alcuni criteri, ad esempio il nome dell'argomento MQTT o una proprietà del messaggio MQTT. Ciò consente di ottenere un migliore bilanciamento del carico, località dei dati o ordinamento dei messaggi.
| valore | Descrizione |
|---|---|
Default |
Assegna messaggi a partizioni casuali, usando un algoritmo round robin. Questo è il valore predefinito se non viene specificata alcuna strategia. |
Static |
Assegna messaggi a un numero di partizione fisso derivato dall'ID istanza del flusso di dati. Ciò significa che ogni istanza del flusso di dati invia messaggi a una partizione diversa. Ciò consente di ottenere un migliore bilanciamento del carico e località dei dati. |
Topic |
Usa il nome dell'argomento MQTT dall'origine del flusso di dati come chiave per il partizionamento. Ciò significa che i messaggi con lo stesso nome dell'argomento MQTT vengono inviati alla stessa partizione. Ciò consente di ottenere un ordinamento dei messaggi e una località dei dati migliori. |
Property |
Usa una proprietà del messaggio MQTT dall'origine del flusso di dati come chiave per il partizionamento. Specificare il nome della proprietà nel partitionKeyProperty campo . Ciò significa che i messaggi con lo stesso valore della proprietà vengono inviati alla stessa partizione. Ciò consente di ottenere un ordinamento dei messaggi e una località dei dati migliori in base a un criterio personalizzato. |
Ad esempio, se si imposta la strategia di gestione delle partizioni su Property e la proprietà della chiave di partizione su device-id, i messaggi con la stessa proprietà vengono inviati alla stessa device-id partizione.
Per configurare la strategia di gestione delle partizioni:
Nella pagina impostazioni dell'endpoint del flusso di dati dell'esperienza operativa selezionare la scheda Avanzate e quindi usare il campo Strategia di gestione delle partizioni per specificare la strategia di gestione delle partizioni. Utilizzare il campo Proprietà chiave di partizione per specificare la proprietà utilizzata per il partizionamento se la strategia è impostata su Property.
Riconoscimenti Kafka
I riconoscimenti Kafka (ack) vengono usati per controllare la durabilità e la coerenza dei messaggi inviati agli argomenti Kafka. Quando un producer invia un messaggio a un argomento Kafka, può richiedere diversi livelli di riconoscimenti dal broker Kafka per assicurarsi che il messaggio venga scritto correttamente nell'argomento e replicato nel cluster Kafka.
Questa impostazione ha effetto solo se l'endpoint viene usato come destinazione, ovvero il flusso di dati è un producer.
| valore | Descrizione |
|---|---|
None |
Il flusso di dati non attende alcun riconoscimento dal broker Kafka. Questa impostazione è l'opzione più veloce ma meno durevole. |
All |
Il flusso di dati attende che il messaggio venga scritto nella partizione leader e in tutte le partizioni di follower. Questa impostazione è l'opzione più lenta ma più durevole. Questa impostazione è anche l'opzione predefinita |
One |
Il flusso di dati attende che il messaggio venga scritto nella partizione leader e almeno una partizione follower. |
Zero |
Il flusso di dati attende che il messaggio venga scritto nella partizione leader, ma non attende alcun riconoscimento dai follower. Questo è più veloce ma One meno durevole. |
Ad esempio, se si imposta il riconoscimento Kafka su All, il flusso di dati attende che il messaggio venga scritto nella partizione leader e in tutte le partizioni di follower prima di inviare il messaggio successivo.
Per configurare i riconoscimenti Kafka:
Nella pagina delle impostazioni dell'endpoint del flusso di dati dell'esperienza operativa selezionare la scheda Avanzate e quindi usare il campo Riconoscimento Kafka per specificare il livello di riconoscimento Kafka.
Questa impostazione ha effetto solo se l'endpoint viene usato come destinazione in cui il flusso di dati è un producer.
Copiare le proprietà MQTT
Per impostazione predefinita, l'impostazione delle proprietà MQTT di copia è abilitata. Queste proprietà utente includono valori come subject, che archivia il nome dell'asset che invia il messaggio.
Nella pagina Delle impostazioni dell'endpoint del flusso di dati dell'esperienza operativa selezionare la scheda Avanzate e quindi usare la casella di controllo accanto al campo Copy MQTT properties (Copia proprietà MQTT) per abilitare o disabilitare la copia delle proprietà MQTT.
Le sezioni seguenti descrivono come le proprietà MQTT vengono convertite in intestazioni utente Kafka e viceversa quando l'impostazione è abilitata.
L'endpoint Kafka è una destinazione
Quando un endpoint Kafka è una destinazione del flusso di dati, tutte le proprietà definite dalla specifica MQTT v5 vengono convertite nelle intestazioni utente Kafka. Ad esempio, un messaggio MQTT v5 con "Tipo di contenuto" inoltrato a Kafka si traduce nell'intestazione "Content Type":{specifiedValue}utente Kafka . Le regole simili si applicano ad altre proprietà MQTT predefinite, definite nella tabella seguente.
| MQTT, proprietà | Comportamento tradotto |
|---|---|
| Indicatore del formato del payload | Chiave: "Indicatore formato payload" Valore: "0" (Payload è byte) o "1" (Payload è UTF-8) |
| Argomento di risposta | Chiave: "Argomento di risposta" Valore: copia dell'argomento della risposta dal messaggio originale. |
| Intervallo di scadenza del messaggio | Chiave: "Intervallo di scadenza messaggio" Valore: rappresentazione UTF-8 del numero di secondi prima della scadenza del messaggio. Per altri dettagli, vedere Proprietà Intervallo scadenza messaggi. |
| Dati di correlazione: | Chiave: "Dati di correlazione" Valore: copia dei dati di correlazione dal messaggio originale. A differenza di molte proprietà MQTT v5 con codifica UTF-8, i dati di correlazione possono essere dati arbitrari. |
| Content Type: | Chiave: "Tipo di contenuto" Valore: copia del tipo di contenuto dal messaggio originale. |
Le coppie chiave chiave della proprietà utente MQTT v5 vengono convertite direttamente in intestazioni utente Kafka. Se un'intestazione utente in un messaggio ha lo stesso nome di una proprietà MQTT predefinita (ad esempio, un'intestazione utente denominata "Dati di correlazione"), se inoltrare il valore della proprietà della specifica MQTT v5 o la proprietà utente non è definita.
I flussi di dati non ricevono mai queste proprietà da un broker MQTT. Di conseguenza, un flusso di dati non li inoltra mai:
- Alias dell'argomento
- Identificatori di sottoscrizione
Proprietà Message Expiry Interval
L'intervallo di scadenza del messaggio specifica per quanto tempo un messaggio può rimanere in un broker MQTT prima di essere rimosso.
Quando un flusso di dati riceve un messaggio MQTT con l'intervallo di scadenza del messaggio specificato, è possibile:
- Registra l'ora di ricezione del messaggio.
- Prima che il messaggio venga generato nella destinazione, l'ora viene sottratta dal messaggio dall'intervallo di scadenza originale.
- Se il messaggio non è scaduto (l'operazione precedente è > 0), il messaggio viene generato nella destinazione e contiene l'ora di scadenza del messaggio aggiornata.
- Se il messaggio è scaduto (l'operazione precedente è <= 0), il messaggio non viene generato dalla destinazione.
Esempi:
- Un flusso di dati riceve un messaggio MQTT con intervallo di scadenza messaggio = 3600 secondi. La destinazione corrispondente è temporaneamente disconnessa, ma è in grado di riconnettersi. 1.000 secondi passano prima che questo messaggio MQTT venga inviato alla destinazione. In questo caso, il messaggio di destinazione ha l'intervallo di scadenza del messaggio impostato su 2600 (3600 - 1000) secondi.
- Il flusso di dati riceve un messaggio MQTT con intervallo di scadenza del messaggio = 3600 secondi. La destinazione corrispondente è temporaneamente disconnessa, ma è in grado di riconnettersi. In questo caso, tuttavia, la riconnessione richiede 4.000 secondi. Il messaggio è scaduto e il flusso di dati non inoltra questo messaggio alla destinazione.
L'endpoint Kafka è un'origine del flusso di dati
Nota
Si verifica un problema noto quando si usa l'endpoint di Hub eventi come origine del flusso di dati in cui l'intestazione Kafka viene danneggiata come tradotta in MQTT. Ciò si verifica solo se si usa l'hub eventi anche se il client dell'hub eventi che usa AMQP sotto le quinte. Ad esempio, "foo"="bar", il "foo" viene convertito, ma il valore diventa "\xa1\x03bar".
Quando un endpoint Kafka è un'origine del flusso di dati, le intestazioni utente Kafka vengono convertite in proprietà MQTT v5. Nella tabella seguente viene descritto il modo in cui le intestazioni utente Kafka vengono convertite in proprietà MQTT v5.
| Intestazione Kafka | Comportamento tradotto |
|---|---|
| Chiave | Chiave: "Key" Valore: copia della chiave dal messaggio originale. |
| Timestamp: | Chiave: "Timestamp" Valore: codifica UTF-8 di Kafka Timestamp, ovvero numero di millisecondi dall'epoca Unix. |
Coppie chiave/valore dell'intestazione utente Kafka, purché siano tutte codificate in UTF-8, vengono convertite direttamente in proprietà chiave/valore utente MQTT.
UTF-8/ Mancata corrispondenza binaria
MQTT v5 può supportare solo le proprietà basate su UTF-8. Se il flusso di dati riceve un messaggio Kafka che contiene una o più intestazioni non UTF-8, il flusso di dati:
- Rimuovere la proprietà o le proprietà che causano un'offesa.
- Inoltrare il resto del messaggio, seguendo le regole precedenti.
Le applicazioni che richiedono il trasferimento binario nelle intestazioni di origine Kafka => le proprietà della destinazione MQTT devono prima codificarle in UTF-8, ad esempio tramite Base64.
>=64 KB proprietà non corrispondenti
Le proprietà MQTT v5 devono essere inferiori a 64 KB. Se il flusso di dati riceve un messaggio Kafka che contiene una o più intestazioni = >64 KB, il flusso di dati:
- Rimuovere la proprietà o le proprietà che causano un'offesa.
- Inoltrare il resto del messaggio, seguendo le regole precedenti.
Conversione delle proprietà quando si usano Hub eventi e producer che usano AMQP
Se si dispone di un client che inoltra messaggi a un endpoint dell'origine del flusso di dati Kafka, eseguendo una delle azioni seguenti:
- Invio di messaggi a Hub eventi tramite librerie client come Azure.Messaging.EventHubs
- Uso diretto di AMQP
Esistono sfumature di traduzione delle proprietà da tenere presenti.
È consigliabile eseguire una delle operazioni seguenti:
- Evitare l'invio di proprietà
- Se è necessario inviare proprietà, inviare valori codificati come UTF-8.
Quando Hub eventi converte le proprietà da AMQP a Kafka, include i tipi codificati AMQP sottostanti nel messaggio. Per altre informazioni sul comportamento, vedere Scambio di eventi tra consumer e producer che usano protocolli diversi.
Nell'esempio di codice seguente quando l'endpoint del flusso di dati riceve il valore "foo":"bar", riceve la proprietà come <0xA1 0x03 "bar">.
using global::Azure.Messaging.EventHubs;
using global::Azure.Messaging.EventHubs.Producer;
var propertyEventBody = new BinaryData("payload");
var propertyEventData = new EventData(propertyEventBody)
{
Properties =
{
{"foo", "bar"},
}
};
var propertyEventAdded = eventBatch.TryAdd(propertyEventData);
await producerClient.SendAsync(eventBatch);
L'endpoint del flusso di dati non può inoltrare la proprietà <0xA1 0x03 "bar"> payload a un messaggio MQTT perché i dati non sono UTF-8. Tuttavia, se si specifica una stringa UTF-8, l'endpoint del flusso di dati converte la stringa prima dell'invio a MQTT. Se si usa una stringa UTF-8, il messaggio MQTT avrà "foo":"bar" come proprietà utente.
Vengono convertite solo le intestazioni UTF-8. Ad esempio, dato lo scenario seguente in cui la proprietà è impostata come float:
Properties =
{
{"float-value", 11.9 },
}
L'endpoint del flusso di dati elimina i pacchetti che contengono il "float-value" campo .
Non tutte le proprietà dei dati dell'evento, inclusa propertyEventData.correlationId, vengono inoltrate. Per altre informazioni, vedere Proprietà utente evento,
CloudEvents
CloudEvents è un modo per descrivere i dati degli eventi in modo comune. Le impostazioni cloudEvents vengono usate per inviare o ricevere messaggi nel formato CloudEvents. È possibile usare CloudEvents per architetture basate su eventi in cui servizi diversi devono comunicare tra loro nello stesso provider di servizi cloud o diversi.
Le CloudEventAttributes opzioni sono Propagate oCreateOrRemap.
Nella pagina Delle impostazioni dell'endpoint del flusso di dati dell'esperienza operativa selezionare la scheda Avanzate e quindi usare il campo Attributi evento cloud per specificare l'impostazione CloudEvents.
Le sezioni seguenti descrivono in che modo le proprietà CloudEvent vengono propagate o create e ricreate e mappate.
Impostazione di propagazione
Le proprietà CloudEvent vengono passate per i messaggi che contengono le proprietà necessarie. Se il messaggio non contiene le proprietà necessarie, il messaggio viene passato così come è. Se sono presenti le proprietà necessarie, viene aggiunto un ce_ prefisso al nome della proprietà CloudEvent.
| Nome | Obbligatorio | Valore di esempio | Nome output | Valore di output |
|---|---|---|---|---|
specversion |
Sì | 1.0 |
ce-specversion |
Passato come è |
type |
Sì | ms.aio.telemetry |
ce-type |
Passato come è |
source |
Sì | aio://mycluster/myoven |
ce-source |
Passato come è |
id |
Sì | A234-1234-1234 |
ce-id |
Passato come è |
subject |
No | aio/myoven/telemetry/temperature |
ce-subject |
Passato come è |
time |
No | 2018-04-05T17:31:00Z |
ce-time |
Passato così come è. Non è riformulare. |
datacontenttype |
No | application/json |
ce-datacontenttype |
Modificato nel tipo di contenuto dei dati di output dopo la fase di trasformazione facoltativa. |
dataschema |
No | sr://fabrikam-schemas/123123123234234234234234#1.0.0 |
ce-dataschema |
Se nella configurazione della trasformazione viene assegnato uno schema di trasformazione dei dati di output, dataschema viene modificato nello schema di output. |
Impostazione CreateOrRemap
Le proprietà CloudEvent vengono passate per i messaggi che contengono le proprietà necessarie. Se il messaggio non contiene le proprietà necessarie, le proprietà vengono generate.
| Nome | Obbligatorio | Nome output | Valore generato se mancante |
|---|---|---|---|
specversion |
Sì | ce-specversion |
1.0 |
type |
Sì | ce-type |
ms.aio-dataflow.telemetry |
source |
Sì | ce-source |
aio://<target-name> |
id |
Sì | ce-id |
UUID generato nel client di destinazione |
subject |
No | ce-subject |
Argomento di output in cui viene inviato il messaggio |
time |
No | ce-time |
Generato come RFC 3339 nel client di destinazione |
datacontenttype |
No | ce-datacontenttype |
Modifica del tipo di contenuto dei dati di output dopo la fase di trasformazione facoltativa |
dataschema |
No | ce-dataschema |
Schema definito nel Registro di sistema dello schema |
Passaggi successivi
Per altre informazioni sui flussi di dati, vedere Creare un flusso di dati.