Usare Azure Machine Learning in una rete virtuale di Azure
Suggerimento
È possibile usare reti virtuali gestite di Azure Machine Learning anziché i passaggi descritti in questo articolo. Con una rete virtuale gestita, Azure Machine Learning gestisce il processo di isolamento della rete per l'area di lavoro e gli ambienti di calcolo gestito. È anche possibile aggiungere endpoint privati per le risorse necessarie per l'area di lavoro, ad esempio l'account di archiviazione di Azure. Per altre informazioni, vedere Isolamento rete gestita dell'area di lavoro.
Questo articolo illustra come usare Azure Machine Learning Studio in una rete virtuale. Lo studio include funzionalità come AutoML, la finestra di progettazione e l'etichettatura dei dati.
Alcune funzionalità dello studio sono disabilitate per impostazione predefinita in una rete virtuale. Per riabilitare queste funzionalità, è necessario abilitare l'identità gestita per gli account di archiviazione che si intende usare in studio.
Le operazioni seguenti sono disabilitate per impostazione predefinita in una rete virtuale:
- Visualizzazione in anteprima dei dati in Studio.
- Visualizzazione dei dati nella finestra di progettazione.
- Distribuzione di un modello nella finestra di progettazione.
- Invio di un esperimento di Machine Learning automatizzato.
- Avvio di un progetto di etichettatura.
Lo studio supporta la lettura dei dati dai tipi di archivio dati seguenti in una rete virtuale:
- Account di archiviazione di Azure (BLOB e file)
- Azure Data Lake Storage Gen1
- Azure Data Lake Storage Gen2
- database SQL di Azure
In questo articolo vengono illustrate le operazioni seguenti:
- Concedere allo studio l'accesso ai dati archiviati all'interno di una rete virtuale.
- Accedere allo studio da una risorsa all'interno di una rete virtuale.
- Comprendere in che modo lo studio influisce sulla sicurezza dell'archiviazione.
Prerequisiti
Leggere la panoramica della sicurezza di rete per comprendere gli scenari di rete virtuale e l'architettura comuni.
Una rete virtuale e una subnet preesistenti da usare.
Un'area di lavoro di Azure Machine Learning esistente con un endpoint privato.
Un account di archiviazione di Azure esistente ha aggiunto la rete virtuale.
Un'area di lavoro di Azure Machine Learning esistente con un endpoint privato.
Un account di archiviazione di Azure esistente ha aggiunto la rete virtuale.
- Per informazioni su come creare un'area di lavoro sicura, vedere Esercitazione: Creare un'area di lavoro sicura, Modello Bicep o Terraform template (Modello Terraform).
Limiti
Account di archiviazione di Azure
Quando l'account di archiviazione si trova nella rete virtuale, esistono requisiti di convalida aggiuntivi per l'uso di Studio:
- Se l'account di archiviazione usa un endpoint servizio, l'endpoint privato dell'area di lavoro e l'endpoint servizio di archiviazione devono trovarsi nella medesima subnet della rete virtuale.
- Se l'account di archiviazione usa un endpoint privato, l'endpoint privato dell'area di lavoro e l'endpoint privato di archiviazione devono trovarsi nella medesima rete virtuale. In questo caso, possono trovarsi in subnet diverse.
Pipeline di esempio della finestra di progettazione
Si è verificato un problema noto per cui gli utenti non possono eseguire una pipeline di esempio nella home page della finestra di progettazione. Questo problema si verifica perché il set di dati di esempio usato nella pipeline di esempio è un set di dati globale di Azure. Non è possibile accedervi da un ambiente di rete virtuale.
Per risolvere questo problema, usare un'area di lavoro pubblica per eseguire la pipeline di esempio. In alternativa, sostituire il set di dati di esempio con il proprio set di dati nell'area di lavoro all'interno di una rete virtuale.
Archivio dati: account di archiviazione di Azure
Usare la procedura seguente per abilitare l'accesso ai dati archiviati nell'archiviazione BLOB e file di Azure:
Suggerimento
Il primo passaggio non è necessario per l'account di archiviazione predefinito per l'area di lavoro. Tutti gli altri passaggi sono necessari per qualsiasi account di archiviazione dietro la rete virtuale e usato dall'area di lavoro, incluso l'account di archiviazione predefinito.
Se l'account di archiviazione è di archiviazione predefinita per l'area di lavoro, ignorare questo passaggio. Se non è l'impostazione predefinita, concedere all'identità gestita dell'area di lavoro il ruolo Lettore dati BLOB di archiviazione per l'account di archiviazione di Azure in modo che possa leggere i dati dall'archiviazione BLOB.
Per altre informazioni, vedere il ruolo predefinito Lettore dati BLOB.
Concedere all’identità utente di Azure il ruolo lettore dei dati BLOB di archiviazione per l'account di archiviazione di Azure. Lo studio usa l'identità per accedere ai dati all'archiviazione BLOB, anche se l'identità gestita dell'area di lavoro ha il ruolo Lettore.
Per altre informazioni, vedere il ruolo predefinito Lettore dati BLOB.
Concedere all'identità gestita dell'area di lavoro il ruolo Lettore per gli endpoint privati di archiviazione. Se il servizio di archiviazione usa un endpoint privato, concedere all'utente l'accesso come Lettore delle identità gestite dell'area di lavoro all'endpoint privato. L'identità gestita dell'area di lavoro in Microsoft Entra ID ha lo stesso nome dell'area di lavoro di Azure Machine Learning. Per i tipi di archiviazione BLOB e file è necessario un endpoint privato.
Suggerimento
L'account di archiviazione potrebbe avere più endpoint privati. Ad esempio, un account di archiviazione potrebbe avere un endpoint privato separato per BLOB, file e dfs (Azure Data Lake Storage Gen2). Aggiungere l'identità gestita a tutti questi endpoint.
Per altre informazioni, vedere il ruolo predefinito Lettore.
Abilitare l'autenticazione dell'identità gestita per gli account di archiviazione predefiniti. Ogni area di lavoro di Azure Machine Learning ha due account di archiviazione predefiniti, un account di archiviazione BLOB predefinito e un account di archivio file predefinito. Entrambi vengono definiti quando si crea l'area di lavoro. È anche possibile impostare nuove impostazioni predefinite nella pagina di gestione dell'archivio dati.

La tabella seguente descrive il motivo per cui viene usata l'autenticazione dell'identità gestita per gli account di archiviazione predefiniti dell'area di lavoro.
Account di archiviazione Note Archiviazione BLOB predefinita dell'area di lavoro Archivia gli asset del modello dalla finestra di progettazione. Abilitare l'autenticazione dell'identità gestita in questo account di archiviazione per distribuire i modelli nella finestra di progettazione. Se l'autenticazione dell'identità gestita è disabilitata, l'identità dell'utente viene usata per accedere ai dati archiviati nel BLOB.
È possibile visualizzare ed eseguire una pipeline di progettazione se usa un archivio dati non predefinito configurato per l'uso dell'identità gestita. Tuttavia, se si tenta di distribuire un modello sottoposto a training senza l'identità gestita abilitata nell'archivio dati predefinito, la distribuzione ha esito negativo indipendentemente dagli altri archivi dati in uso.Archivio file predefinito dell'area di lavoro Archivia gli asset dell'esperimento AutoML. Abilitare l'autenticazione dell'identità gestita in questo account di archiviazione per inviare esperimenti AutoML. Configurare gli archivi dati per l'uso dell'autenticazione dell'identità gestita. Dopo aver aggiunto un account di archiviazione di Azure alla rete virtuale con un endpoint di servizio o un endpoint privato, è necessario configurare l'archivio dati in modo da usare l'autenticazione dell'identità gestita. In questo modo, lo studio può accedere ai dati nell'account di archiviazione.
Azure Machine Learning usa archivio dati per connettersi agli account di archiviazione. Quando si crea un nuovo archivio dati, seguire questa procedura per configurare un archivio dati per l'uso dell'autenticazione con identità gestita:
In Studio selezionare Archivi dati.
Per creare un nuovo archivio dati, selezionare + Crea.
Nelle impostazioni dell'archivio dati attivare l'opzione Usa identità gestita dell'area di lavoro per l'anteprima dei dati e la profilatura in Azure Machine Learning Studio.
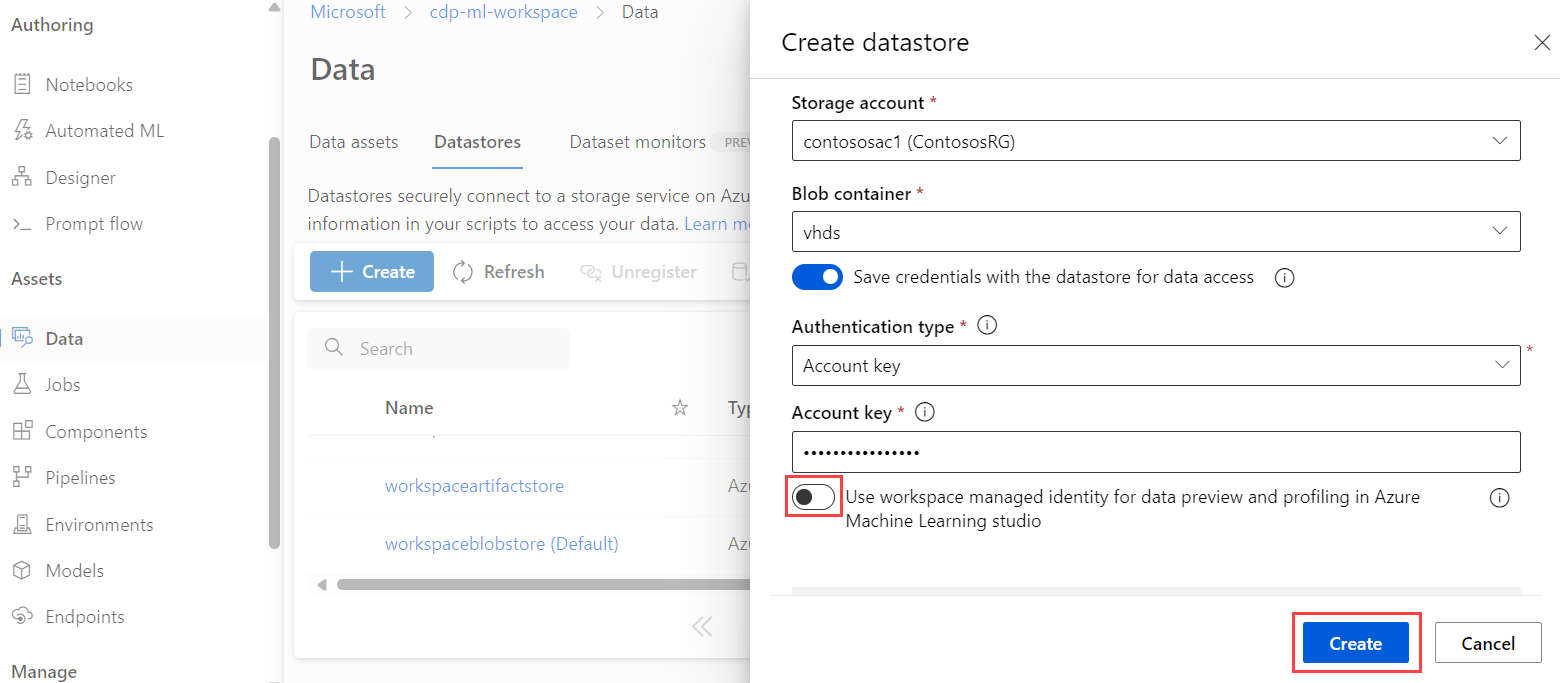
Nelle impostazioni di rete per l'account di archiviazione di Azure, aggiungere il
Microsoft.MachineLearningService/workspacestipo di risorsa e impostare il nome dell'istanza sull'area di lavoro.
Questi passaggi aggiungono l'identità gestita dell'area di lavoro come lettore al nuovo servizio di archiviazione usando il controllo degli accessi in base al ruolo di Azure. L'accesso con autorizzazioni di lettura consente all'area di lavoro di visualizzare la risorsa, ma non di apportare modifiche.


Archivio dati: Azure Data Lake Storage Gen1
Quando si usa Azure Data Lake Storage Gen1 come archivio dati, è possibile usare solo elenchi di controllo di accesso in stile POSIX. È possibile assegnare all'identità gestita dell'area di lavoro l'accesso alle risorse come a qualsiasi altra entità di sicurezza. Per altre informazioni, vedere Controllo di accesso in Azure Data Lake Storage Gen1.
Archivio dati: Azure Data Lake Storage Gen2
Quando si usa Azure Data Lake Storage Gen2 come archivio dati, è possibile usare elenchi di controllo degli accessi in base al ruolo di Azure ed elenchi di controllo di accesso in stile POSIX (ACL) per controllare l'accesso ai dati all'interno di una rete virtuale.
Per usare il controllo degli accessi in base al ruolo di Azure, seguire la procedura descritta nella sezione Archivio dati: Account di archiviazione di Azure di questo articolo. Data Lake Storage Gen2 si basa su Archiviazione di Azure, quindi si applicano gli stessi passaggi quando si usa il controllo degli accessi in base al ruolo di Azure.
Per usare gli elenchi di controllo di accesso, l'identità gestita dell'area di lavoro può essere assegnata come qualsiasi altra entità di sicurezza. Per altre informazioni, vedere Elenchi di controllo di accesso in file e directory.
Archivio dati: database SQL di Azure
Per accedere ai dati archiviati in un database SQL di Azure con un'identità gestita, è necessario creare un utente SQL contenuto, mappato all'identità gestita. Per altre informazioni sulla creazione di un utente da un provider esterno, vedere Creare utenti indipendenti mappati alle identità di Microsoft Entra.
Dopo aver creato un utente indipendente di SQL, concedere le autorizzazioni usando il comando GRANT T-SQL.
Output del componente intermedio
Quando si usa l'output intermedio del componente della finestra di progettazione di Azure Machine Learning, è possibile specificare il percorso di output per qualsiasi componente nella finestra di progettazione. Usare questo output per archiviare set di dati intermedi in un percorso separato per scopi di sicurezza, registrazione o controllo. Per specificare l'output, seguire questa procedura:
- Selezionare il componente di cui si desidera specificare l'output.
- Nel riquadro delle impostazioni del componente selezionare Impostazioni output.
- Specificare l'archivio dati che si vuole usare per ogni output del componente.
Assicurarsi di avere accesso agli account di archiviazione intermedi nella rete virtuale. In caso contrario, la pipeline ha esito negativo.
Abilitare l'autenticazione dell'identità gestita per consentire agli account di archiviazione intermedi di visualizzare i dati di output.
Accedere allo studio da una risorsa all'interno della rete virtuale
Se si accede allo studio da una risorsa all'interno di una rete virtuale, ad esempio un'istanza di calcolo o una macchina virtuale, è necessario consentire il traffico in uscita dalla rete virtuale allo studio.
Ad esempio, se si usano gruppi di sicurezza di rete (NSG) per limitare il traffico in uscita, aggiungere una regola a una destinazione tag del servizio di AzureFrontDoor.Frontend.
Impostazioni del firewall
Alcuni servizi di archiviazione, ad esempio l'account di archiviazione di Azure, dispongono di impostazioni del firewall applicabili all'endpoint pubblico per tale istanza del servizio specifica. In genere questa impostazione consente di consentire/impedire l'accesso da indirizzi IP specifici dalla rete Internet pubblica. Questo non è supportato quando si usa Azure Machine Learning Studio. È supportato quando si usa Azure Machine Learning SDK o l'interfaccia della riga di comando.
Suggerimento
Azure Machine Learning Studio è supportato quando si usa il servizio Firewall di Azure. Per ulteriori informazioni, consultare Configurare il traffico di rete in ingresso e in uscita.
Contenuto correlato
Il presente articolo fa parte di una serie di articoli sulla protezione del flusso di lavoro di Azure Machine Learning. Vedi gli altri articoli di questa serie: