Monitorare gli endpoint online
Azure Machine Learning usa l'integrazione con Monitoraggio di Azure per tenere traccia e monitorare le metriche e i log per gli endpoint online. È possibile visualizzare le metriche nei grafici, confrontare tra endpoint e distribuzioni, aggiungere ai dashboard del portale di Azure, configurare avvisi, eseguire query dalle tabelle di log e eseguire il push dei log alle destinazioni supportate. È anche possibile usare Application Insights per analizzare gli eventi dai contenitori utente.
Metriche: per le metriche a livello di endpoint, ad esempio latenza delle richieste, richieste al minuto, nuove connessioni al secondo e byte di rete, è possibile eseguire il drill-down per visualizzare i dettagli a livello di distribuzione o di stato. Per le metriche a livello di distribuzione, ad esempio l'utilizzo della CPU/GPU e l'utilizzo della memoria o del disco, è anche possibile eseguire il drill-down a livello di istanza. Monitoraggio di Azure consente di tenere traccia di queste metriche nei grafici e di configurare dashboard e avvisi per un'ulteriore analisi.
Log: è possibile inviare le metriche all'area di lavoro Log Analytics in cui è possibile eseguire query sui log usando la sintassi di query Kusto. È anche possibile inviare metriche agli account di Archiviazione di Azure e/o a Hub eventi per un'ulteriore elaborazione. Inoltre, è possibile usare tabelle di log dedicate per gli eventi correlati agli endpoint online, il traffico e i log della console (contenitori). La query Kusto consente l'analisi complessa e l’unione di più tabelle.
Application Insights: gli ambienti curati includono l'integrazione con Application Insights ed è possibile abilitarla o disabilitarla quando si crea una distribuzione online. Le metriche e i log predefiniti vengono inviati ad Application Insights ed è possibile usare le funzionalità predefinite di Application Insights, come le metriche attive, la ricerca di transazioni, gli errori e le prestazioni per ulteriori analisi.
In questo articolo viene spiegato come:
- Scegliere il metodo corretto per visualizzare e tenere traccia delle metriche e dei log
- Visualizzare le metriche per l'endpoint online
- Creare un dashboard per le metriche
- Creare un avviso per la metrica
- Visualizzare i log per l'endpoint online
- Usare Application Insights per tenere traccia delle metriche e dei log
Prerequisiti
- Distribuire un endpoint online di Azure Machine Learning.
- È necessario avere almeno l'accesso in lettura nell'endpoint.
Metrica
È possibile visualizzare le pagine delle metriche per gli endpoint o le distribuzioni online nel portale di Azure. Un modo semplice per accedere a queste pagine delle metriche è costituito dai collegamenti disponibili nell'interfaccia utente studio di Azure Machine Learning, in particolare nella scheda Dettagli della pagina di un endpoint. Questi collegamenti consentono di passare alla pagina esatta delle metriche nel portale di Azure per l'endpoint o la distribuzione. In alternativa, è anche possibile accedere al portale di Azure per cercare l'endpoint o la distribuzione nella pagina delle metriche.
Per accedere alle pagine delle metriche tramite i collegamenti disponibili in Studio:
Passare ad Azure Machine Learning Studio.
Nella barra di spostamento a sinistra selezionare la pagina Endpoint.
Selezionare un endpoint facendo clic sul relativo nome.
Selezionare Visualizza metriche nella sezione Attributi dell'endpoint per aprire la pagina delle metriche dell'endpoint nel portale di Azure.
Selezionare Visualizza metriche nella sezione relativa a ogni distribuzione disponibile per aprire la pagina delle metriche della distribuzione nel portale di Azure.
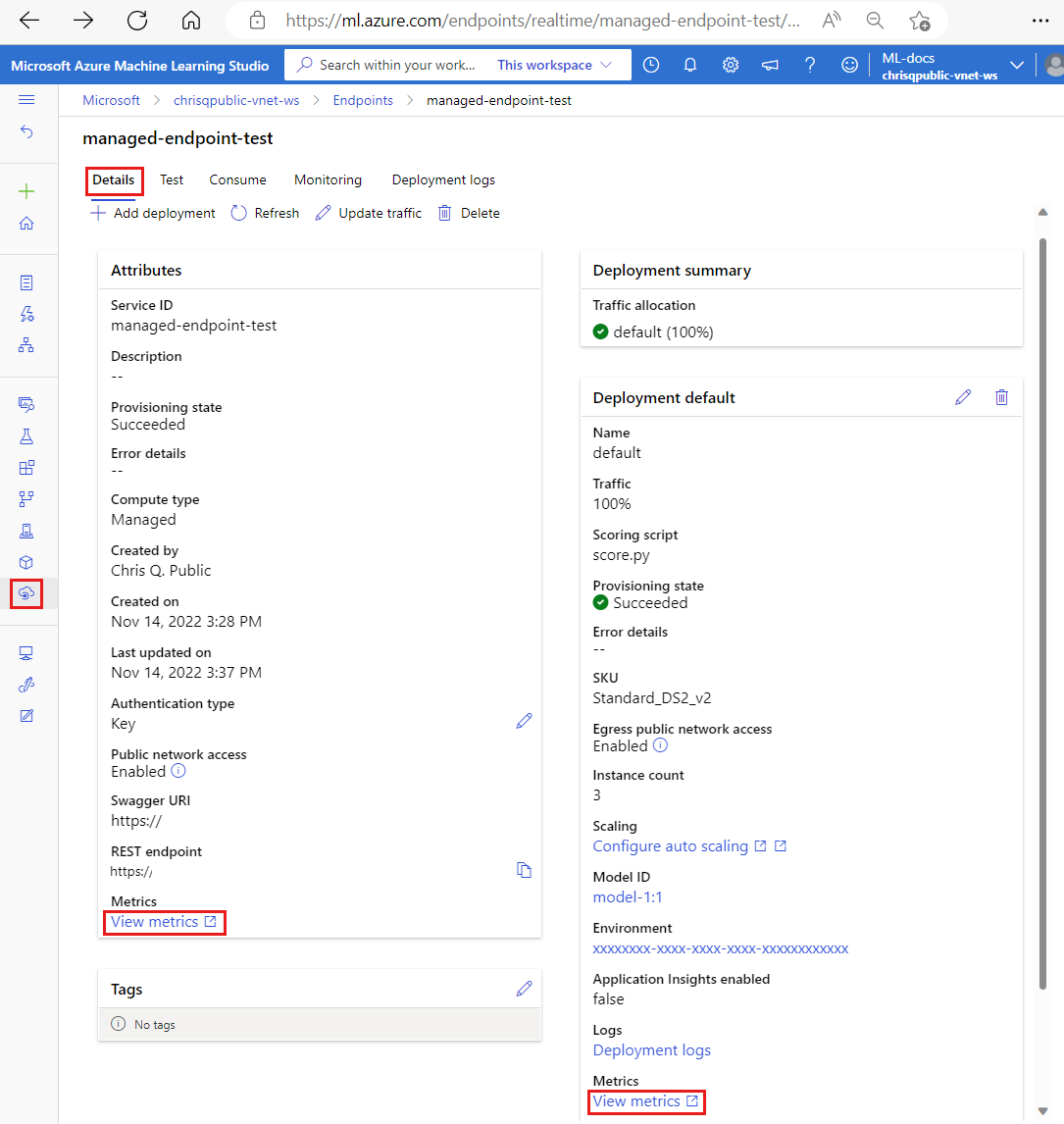

Per accedere alle metriche direttamente dal portale di Azure:
Accedere al portale di Azure.
Passare all'endpoint online o alla risorsa di distribuzione.
Gli endpoint e le distribuzioni online sono risorse di Azure Resource Manager (ARM) che sono disponibili passando al proprio gruppo di risorse proprietario. Cercare i tipi di risorse endpoint online di Machine Learning e distribuzione online di Machine Learning.
Nella colonna a sinistra selezionare Metriche.
Metriche disponibili
A seconda della risorsa selezionata, le metriche visualizzate saranno diverse. Le metriche hanno un ambito diverso per gli endpoint online e le distribuzioni online.
Metriche nell'ambito dell'endpoint
Categoria: Traffico
| Metric | Nome nell'API REST | Unità | Aggregazione | Dimensioni | Intervalli di tempo | Esportazione DS |
|---|---|---|---|---|---|---|
| Connessioni attive Numero totale di connessioni TCP simultanee attive dai client. |
ConnectionsActive |
Conteggio | Media | <none> | PT1M | No |
| Errori di raccolta dati al minuto Numero di eventi di raccolta dati eliminati al minuto. |
DataCollectionErrorsPerMinute |
Conteggio | Minimo, Massimo, Medio | deployment, reason, type |
PT1M | No |
| Eventi di raccolta dati al minuto Numero di eventi di raccolta dati elaborati al minuto. |
DataCollectionEventsPerMinute |
Conteggio | Minimo, Massimo, Medio | deployment, type |
PT1M | No |
| Byte di rete Byte al secondo serviti per l'endpoint. |
NetworkBytes |
Byte al secondo | Media | <none> | PT1M | No |
| Nuove connessioni al secondo Numero medio di nuove connessioni TCP al secondo stabilite dai client. |
NewConnectionsPerSecond |
Conteggio al secondo | Media | <none> | PT1M | No |
| Latenza delle richieste Intervallo di tempo completo impiegato in media per rispondere a una richiesta in millisecondi |
RequestLatency |
Millisecondi | Media | deployment |
PT1M | Sì |
| Latenza delle richieste P50 Latenza media della richiesta P50 aggregata da tutti i valori di latenza delle richieste raccolti nel periodo di tempo selezionato |
RequestLatency_P50 |
Millisecondi | Media | deployment |
PT1M | Sì |
| Latenza delle richieste P90 Latenza media della richiesta P90 aggregata da tutti i valori di latenza delle richieste raccolti nel periodo di tempo selezionato |
RequestLatency_P90 |
Millisecondi | Media | deployment |
PT1M | Sì |
| Latenza delle richieste P95 Latenza media della richiesta P95 aggregata da tutti i valori di latenza delle richieste raccolti nel periodo di tempo selezionato |
RequestLatency_P95 |
Millisecondi | Media | deployment |
PT1M | Sì |
| Latenza delle richieste P99 Latenza media della richiesta P99 aggregata da tutti i valori di latenza delle richieste raccolti nel periodo di tempo selezionato |
RequestLatency_P99 |
Millisecondi | Media | deployment |
PT1M | Sì |
| Richieste al minuto Numero di richieste inviate all'endpoint online entro un minuto |
RequestsPerMinute |
Conteggio | Media | deployment, statusCode, statusCodeClassmodelStatusCode |
PT1M | No |
Limitazione della larghezza di banda
La larghezza di banda verrà limitata se i limiti di quota vengono superati per gli endpoint onlinegestiti. Per altre informazioni sui limiti, vedere l'articolo sui limiti per gli endpoint online. Per determinare se le richieste sono limitate:
- Monitorare la metrica "Byte di rete"
- I trailer di risposta avranno i campi:
ms-azureml-bandwidth-request-delay-msems-azureml-bandwidth-response-delay-ms. I valori dei campi sono i ritardi, in millisecondi, della limitazione della larghezza di banda.
Per altre informazioni, vedere Problemi relativi al limite di larghezza di banda.
Metriche nell'ambito della distribuzione
Categoria: Risorsa
| Metric | Nome nell'API REST | Unità | Aggregazione | Dimensioni | Intervalli di tempo | Esportazione DS |
|---|---|---|---|---|---|---|
| Percentuale utilizzo memoria CPU Percentuale di utilizzo della memoria in un'istanza. L'utilizzo viene segnalato a intervalli di un minuto. |
CpuMemoryUtilizationPercentage |
Percentuale | Minimo, Massimo, Medio | instanceId |
PT1M | Sì |
| Percentuale utilizzo CPU Percentuale di utilizzo della CPU in un'istanza. L'utilizzo viene segnalato a intervalli di un minuto. |
CpuUtilizationPercentage |
Percentuale | Minimo, Massimo, Medio | instanceId |
PT1M | Sì |
| Errori di raccolta dati al minuto Numero di eventi di raccolta dati eliminati al minuto. |
DataCollectionErrorsPerMinute |
Conteggio | Minimo, Massimo, Medio | instanceId, reason, type |
PT1M | No |
| Eventi di raccolta dati al minuto Numero di eventi di raccolta dati elaborati al minuto. |
DataCollectionEventsPerMinute |
Conteggio | Minimo, Massimo, Medio | instanceId, type |
PT1M | No |
| Capacità di distribuzione Numero di istanze nella distribuzione. |
DeploymentCapacity |
Conteggio | Minimo, Massimo, Medio | instanceId, State |
PT1M | No |
| Utilizzo del disco Percentuale di utilizzo del disco in un'istanza. L'utilizzo viene segnalato a intervalli di un minuto. |
DiskUtilization |
Percentuale | Minimo, Massimo, Medio | instanceId, disk |
PT1M | Sì |
| Energia GPU in Joules Energia dell'intervallo in Joules in un nodo GPU. L'energia viene segnalata a intervalli di un minuto. |
GpuEnergyJoules |
Conteggio | Minimo, Massimo, Medio | instanceId |
PT1M | No |
| Percentuale utilizzo memoria GPU Percentuale di utilizzo della memoria GPU in un'istanza. L'utilizzo viene segnalato a intervalli di un minuto. |
GpuMemoryUtilizationPercentage |
Percentuale | Minimo, Massimo, Medio | instanceId |
PT1M | Sì |
| Percentuale utilizzo GPU Percentuale di utilizzo della GPU in un'istanza. L'utilizzo viene segnalato a intervalli di un minuto. |
GpuUtilizationPercentage |
Percentuale | Minimo, Massimo, Medio | instanceId |
PT1M | Sì |
Categoria: Traffico
| Metric | Nome nell'API REST | Unità | Aggregazione | Dimensioni | Intervalli di tempo | Esportazione DS |
|---|---|---|---|---|---|---|
| Latenza delle richieste P50 Latenza media della richiesta P50 aggregata da tutti i valori di latenza delle richieste raccolti nel periodo di tempo selezionato |
RequestLatency_P50 |
Millisecondi | Media | <none> | PT1M | Sì |
| Latenza delle richieste P90 Latenza media della richiesta P90 aggregata da tutti i valori di latenza delle richieste raccolti nel periodo di tempo selezionato |
RequestLatency_P90 |
Millisecondi | Media | <none> | PT1M | Sì |
| Latenza delle richieste P95 Latenza media della richiesta P95 aggregata da tutti i valori di latenza delle richieste raccolti nel periodo di tempo selezionato |
RequestLatency_P95 |
Millisecondi | Media | <none> | PT1M | Sì |
| Latenza delle richieste P99 Latenza media della richiesta P99 aggregata da tutti i valori di latenza delle richieste raccolti nel periodo di tempo selezionato |
RequestLatency_P99 |
Millisecondi | Media | <none> | PT1M | Sì |
| Richieste al minuto Numero di richieste inviate alla distribuzione online entro un minuto |
RequestsPerMinute |
Conteggio | Media | envoy_response_code |
PT1M | No |
Creare dashboard e avvisi
Monitoraggio di Azure consente di creare dashboard e avvisi, in base alle metriche.
Creare dashboard e visualizzare query
È possibile creare dashboard personalizzati e visualizzare le metriche da più origini nel portale di Azure, incluse le metriche per l'endpoint online. Per altre informazioni sulla creazione di dashboard e la visualizzazione di query, vedere Dashboard che usano dati di log e Dashboard che usano i dati dell'applicazione.
Creare avvisi
È anche possibile creare avvisi personalizzati per notificare aggiornamenti importanti dello stato all'endpoint online:
In alto a destra nella pagina delle metriche selezionare Nuova regola di avviso.

Selezionare un nome di condizione da specificare quando deve essere attivato l'avviso.
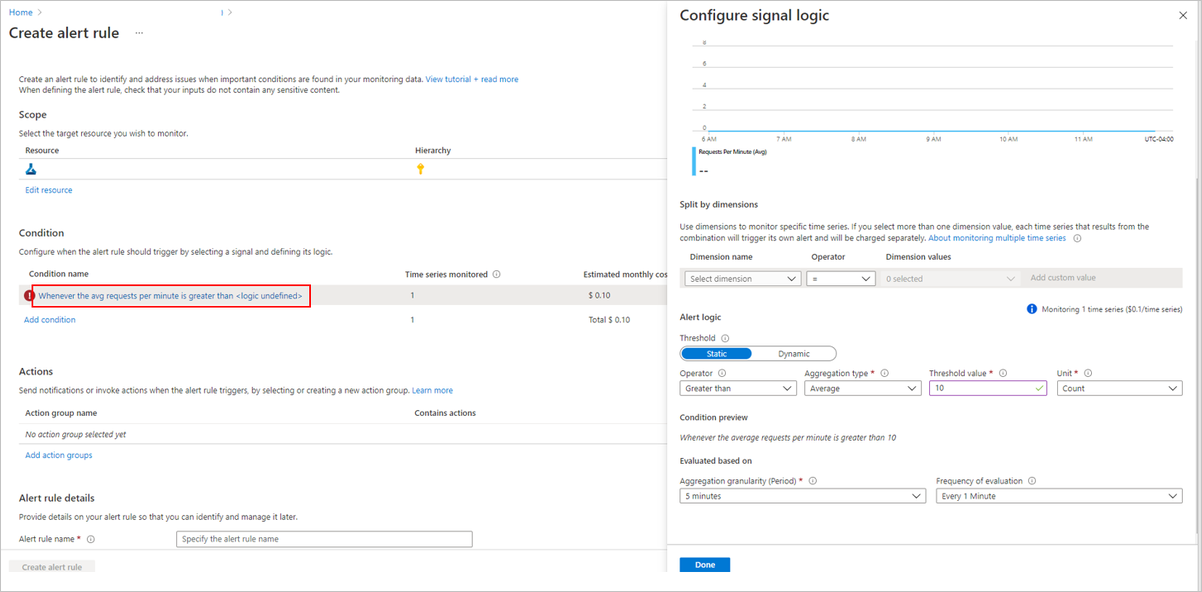
Selezionare Aggiungi gruppi di azioni >Crea gruppi di azioni per specificare cosa deve accadere quando viene attivato l'avviso.
Scegliere Crea regola di avviso per completare la creazione dell'avviso.


Per altre informazioni, vedere Creare regole di avviso di Monitoraggio di Azure.
Abilitare la scalabilità automatica in base alle metriche
È possibile abilitare la scalabilità automatica delle distribuzioni usando le metriche usando l'interfaccia utente o il codice. Quando si usa il codice (interfaccia della riga di comando o SDK), è possibile usare gli ID metrica elencati nella tabella delle metriche disponibili in condizione per attivare la scalabilità automatica. Per altre informazioni, vedere Ridimensionamento automatico degli endpoint online.
Registri
Sono disponibili tre log che possono essere abilitati per gli endpoint online:
AmlOnlineEndpointTrafficLog: è possibile scegliere di abilitare i log del traffico se si desidera controllare le informazioni della richiesta. Di seguito sono riportati alcuni casi:
Se la risposta non è 200, controllare il valore della colonna "ResponseCodeReason" per vedere cosa è successo. Controllare anche il motivo nella sezione "Codici di stato HTTPS" dell'articolo Risolvere i problemi degli endpoint online.
È possibile controllare il codice di risposta e il motivo della risposta del modello dalla colonna "ModelStatusCode" e "ModelStatusReason".
Si vuole controllare la durata della richiesta, ad esempio la durata totale, la durata della richiesta/risposta e il ritardo causato dalla limitazione di rete. È possibile controllarla dai log per visualizzare i dettagli della latenza.
Se si vuole verificare il numero di richieste o richieste non riuscite di recente. È anche possibile abilitare i log.
AmlOnlineEndpointConsoleLog: contiene i log restituiti dai contenitori alla console. Di seguito sono riportati alcuni casi:
Se l'avvio del contenitore non riesce, il log della console può essere utile per il debug.
Monitorare il comportamento del contenitore e assicurarsi che tutte le richieste siano gestite correttamente.
Scrivere gli ID delle richieste nel log della console. Unendo l'ID delle richieste, AmlOnlineEndpointConsoleLog e AmlOnlineEndpointTrafficLog nell'area di lavoro Log Analytics, è possibile tracciare una richiesta dal punto di ingresso di rete di un endpoint online al contenitore.
È anche possibile usare questo log per l'analisi delle prestazioni per determinare il tempo impiegato dal modello per elaborare ogni richiesta.
AmlOnlineEndpointEventLog: contiene informazioni sull'evento relative al ciclo di vita del contenitore. Attualmente vengono fornite informazioni sui seguenti tipi di eventi:
Nome Message Backoff Il riavvio del backoff non è riuscito nel contenitore Pull completato Immagine del contenitore "<IMAGE_NAME>" già presente nel computer Terminazione Probe di attività del server di inferenza del contenitore non riuscito, verrà riavviato Data di creazione Creazione del fetcher immagine del contenitore Data di creazione Creazione del server di inferenza del contenitore Data di creazione Creazione del montaggio del modello del contenitore LivenessProbeFailed Probe di attività non riuscito: <FAILURE_CONTENT> ReadinessProbeFailed Probe di idoneità non riuscito: <FAILURE_CONTENT> Avviato Avvio del fetcher immagine del contenitore Avviato Avvio del server di inferenza del contenitore Avviato Avvio del montaggio del modello del contenitore Terminazione Arresto del server di inferenza del contenitore Terminazione Arresto del montaggio del modello di contenitore
Come abilitare/disabilitare i log
Importante
La registrazione usa Azure Log Analytics. Se attualmente non si ha un'area di lavoro Log Analytics, è possibile crearne una usando la procedura descritta in Creare un'area di lavoro Log Analytics nel portale di Azure.
Nel portale di Azurepassare al gruppo di risorse che contiene l'endpoint e quindi selezionarlo.
Nella sezioneMonitoraggio a sinistra della pagina selezionare Impostazioni di diagnostica e quindi Aggiungi impostazioni.
Selezionare le categorie di log da abilitare, selezionare Invia all'area di lavoro Log Analyticse quindi selezionare l'area di lavoro Log Analytics da usare. Immettere infine un nome di impostazione diagnostica e selezionare Salva.
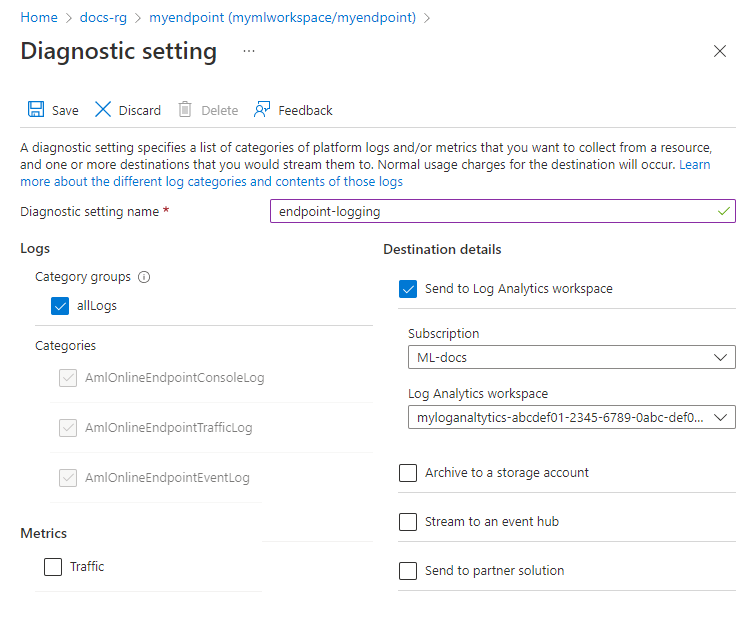
Importante
L'abilitazione della connessione all'area di lavoro Log Analytics potrebbe richiedere fino a un'ora. Attendere un'ora prima di continuare con i passaggi successivi.
Inviare richieste di assegnazione dei punteggi all'endpoint. Questa attività deve creare voci nei log.
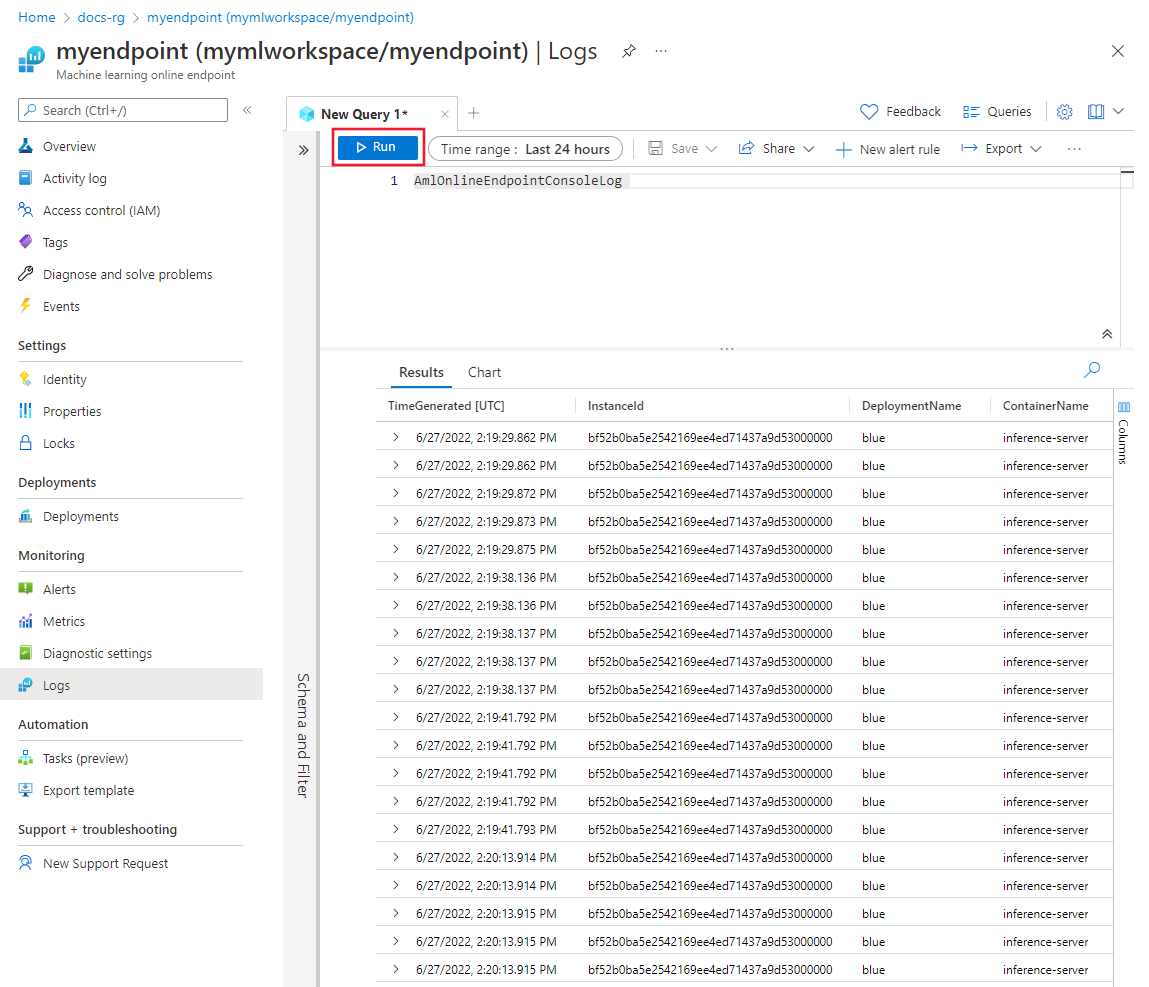
Nelle proprietà dell'endpoint online o nell'area di lavoro Log Analytics selezionare Log a sinistra della schermata.
Chiudere la finestra di dialogoQuery che si apre automaticamente e quindi fare doppio clic su AmlOnlineEndpointConsoleLog. Se l'opzione non è visualizzata, usare il campo Cerca.
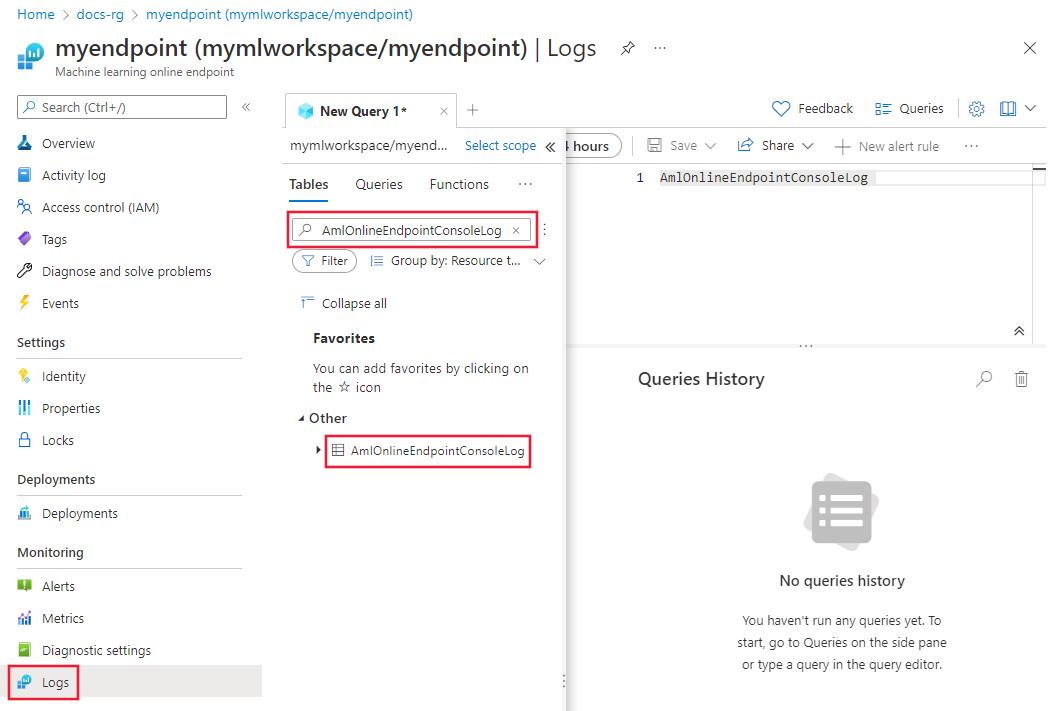
Selezionare Esegui.
Query di esempio
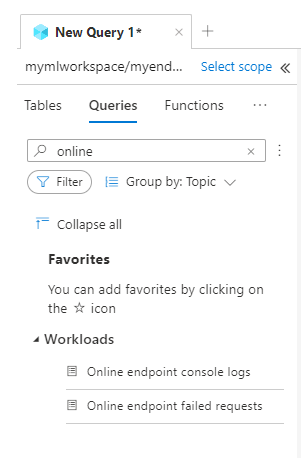
È possibile trovare query di esempio nella scheda Query durante la visualizzazione dei log. Cercare Endpoint online per trovare query di esempio.
Dettagli di righe e colonne
Le tabelle seguenti forniscono informazioni dettagliate sui dati archiviati in ogni log:
AmlOnlineEndpointTrafficLog
| Proprietà | Descrizione |
|---|---|
| metodo | Metodo richiesto dal client. |
| Percorso | Percorso richiesto dal client. |
| SubscriptionId | ID sottoscrizione di Machine Learning dell'endpoint online. |
| AzureMLWorkspaceId | ID dell'area di lavoro di Machine Learning dell'endpoint online. |
| AzureMLWorkspaceName | Nome dell'area di lavoro di Machine Learning dell'endpoint online. |
| EndpointName | Nome dell'endpoint online. |
| DeploymentName | Nome della distribuzione online. |
| Protocollo | Protocollo della richiesta. |
| ResponseCode | Codice di risposta finale restituito al client. |
| ResponseCodeReason | Motivo del codice di risposta finale restituito al client. |
| ModelStatusCode | Codice di stato della risposta dal modello. |
| ModelStatusReason | Motivo dello stato della risposta dal modello. |
| RequestPayloadSize | Byte totali ricevuti dal client. |
| ResponsePayloadSize | Byte totali inviati al client. |
| UserAgent | Intestazione utente-agente della richiesta, inclusi i commenti ma troncati a un massimo di 70 caratteri. |
| XRequestId | ID richiesta generato da Azure Machine Learning per la traccia interna. |
| XMSClientRequestId | ID di traccia generato dal client. |
| TotalDurationMs | Durata in millisecondi dall'ora di inizio della richiesta all'ultimo byte di risposta inviato al client. Se il client è disconnesso, misura dall'ora di inizio all'ora di disconnessione del client. |
| RequestDurationMs | Durata in millisecondi dall'ora di inizio della richiesta all'ultimo byte della richiesta ricevuta dal client. |
| ResponseDurationMs | Durata in millisecondi dall'ora di inizio della richiesta al primo byte di risposta letto dal modello. |
| RequestThrottlingDelayMs | Ritardo in millisecondi nel trasferimento dei dati della richiesta a causa della limitazione di rete. |
| ResponseThrottlingDelayMs | Ritardo in millisecondi nel trasferimento dei dati di risposta a causa della limitazione della rete. |
AmlOnlineEndpointConsoleLog
| Proprietà | Descrizione |
|---|---|
| TimeGenerated | Il timestamp (UTC) relativo alla data e all'ora in cui è stato generato il log. |
| OperationName | L'operazione associata al record del log. |
| InstanceId | ID dell'istanza che ha generato questo record di log. |
| DeploymentName | Nome della distribuzione associata al record di log. |
| ContainerName | Nome del contenitore in cui è stato generato il log. |
| Message | Contenuto del log. |
AmlOnlineEndpointEventLog
| Proprietà | Descrizione |
|---|---|
| TimeGenerated | Il timestamp (UTC) relativo alla data e all'ora in cui è stato generato il log. |
| OperationName | L'operazione associata al record del log. |
| InstanceId | ID dell'istanza che ha generato questo record di log. |
| DeploymentName | Nome della distribuzione associata al record di log. |
| Nome | Nome dell'evento. |
| Message | Contenuto dell'evento. |
Utilizzo di Application Insights
Gli ambienti curati includono l'integrazione con Application Insights ed è possibile abilitare o disabilitare questa integrazione quando si crea una distribuzione online. Le metriche e i log predefiniti vengono inviati ad Application Insights ed è possibile usare le funzionalità predefinite di Application Insights, come le metriche attive, la ricerca di transazioni, gli errori e le prestazioni per ulteriori analisi.
Per altre informazioni, vedere Panoramica di Application Insights.
In Studio è possibile usare la scheda Monitoraggio nella pagina di un endpoint online per visualizzare grafici di monitoraggio attività di alto livello per l'endpoint online gestito. Per usare la scheda del monitoraggio, è necessario selezionareAbilita la raccolta di dati e diagnostica di Application Insights quando si crea l'endpoint.

Contenuto correlato
- Informazioni su come visualizzare i costi per l'endpoint distribuito.
- Altre informazioni su Esplora metriche.