Usare le raccomandazioni sugli indici generate dall'ottimizzazione dell'indice in Database di Azure per PostgreSQL - Server flessibile
L'ottimizzazione dell'indice rende persistenti le raccomandazioni fornite in un set di tabelle che si trovano nello schema intelligentperformance nel database azure_sys.
Queste informazioni possono essere lette usando la compilazione della pagina del portale di Azure per questo scopo o eseguendo query per recuperare i dati da due visualizzazioni disponibili all'interno di intelligent performance del database azure_sys.
Usare le raccomandazioni sugli indici tramite il portale di Azure
Accedere al portale di Azure e selezionare il Database di Azure per il server flessibile PostgreSQL.
Selezionare Ottimizzazione dell'indice nella sezione Prestazioni intelligenti del menu.
Se la funzionalità è abilitata ma non vengono ancora generate raccomandazioni, la schermata è simile alla seguente:
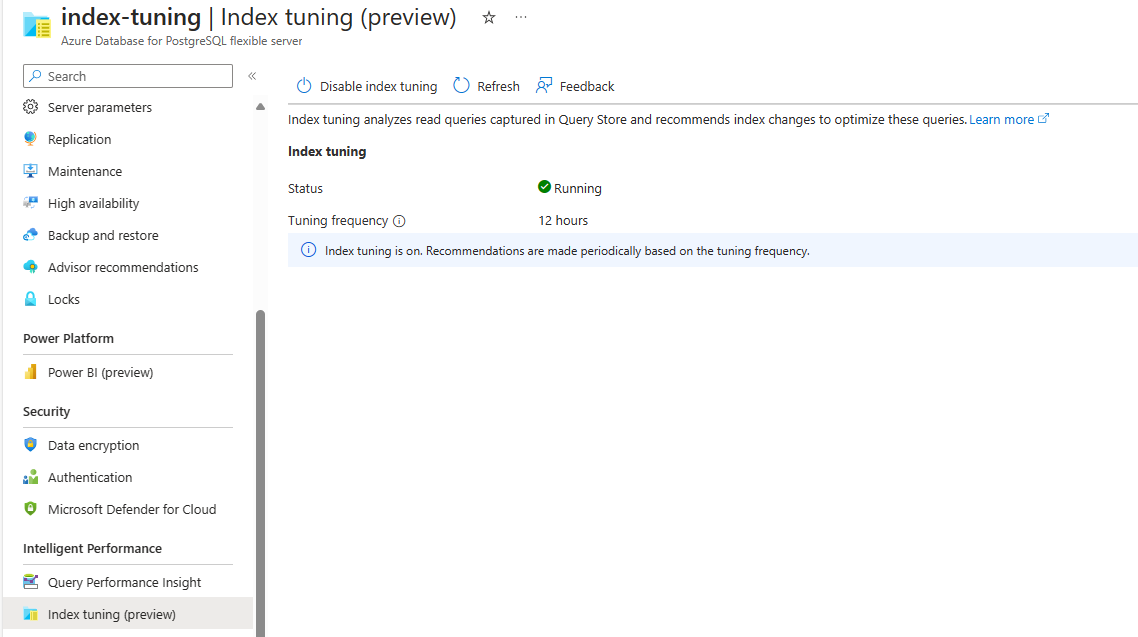
Se la funzionalità è attualmente disabilitata e non ha mai prodotto raccomandazioni in passato, la schermata sarà simile alla seguente:

Se la funzionalità è abilitata e non vengono ancora prodotte raccomandazioni, la schermata è simile alla seguente:
Se la funzionalità è disabilitata ma ha prodotto raccomandazioni, la schermata sarà simile alla seguente:

Se sono disponibili raccomandazioni, selezionare il riepilogo Visualizza raccomandazioni indice per accedere all'elenco completo:
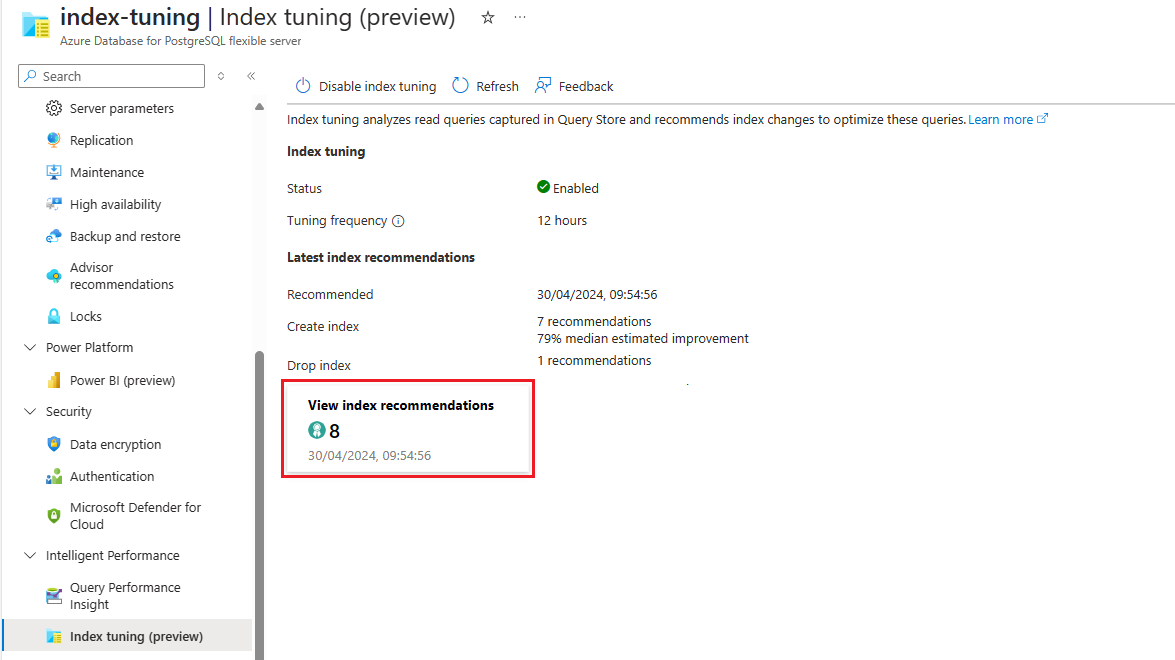
L'elenco mostra tutte le raccomandazioni disponibili con alcuni dettagli per ognuno di essi. Per impostazione predefinita, l'elenco è ordinato in base all'ultimo consigliato in ordine decrescente, che mostra le raccomandazioni più recenti nella parte superiore. Tuttavia, è possibile ordinare in base a qualsiasi altra colonna e usare la casella di filtro per ridurre l'elenco di elementi visualizzati in tali elementi i cui nomi di database, schema o tabella contengono il testo fornito:
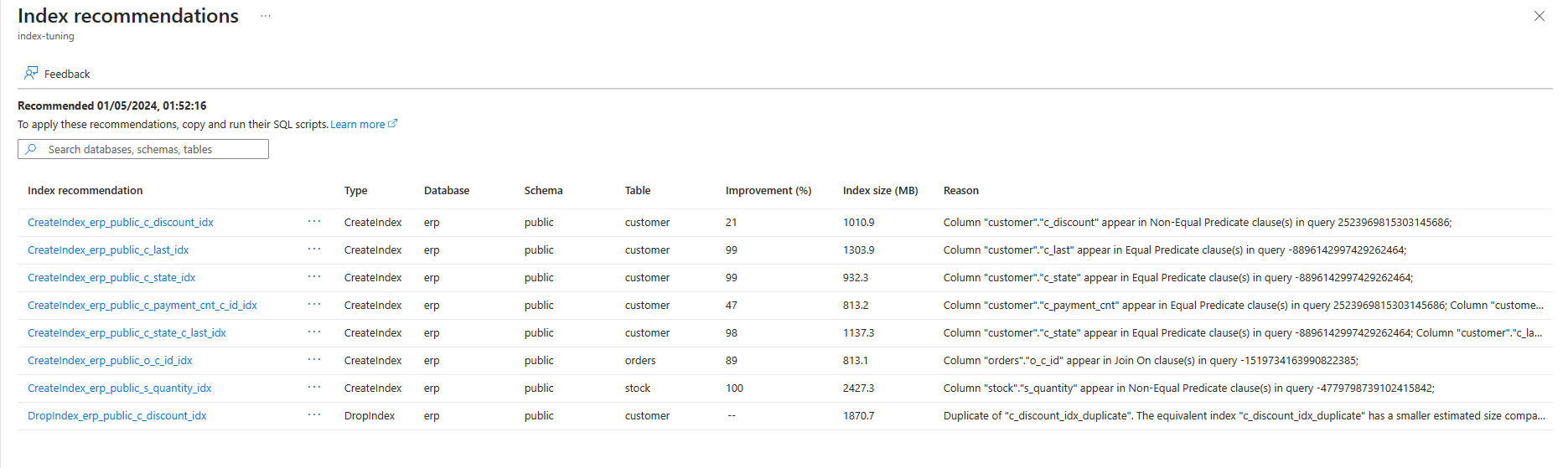
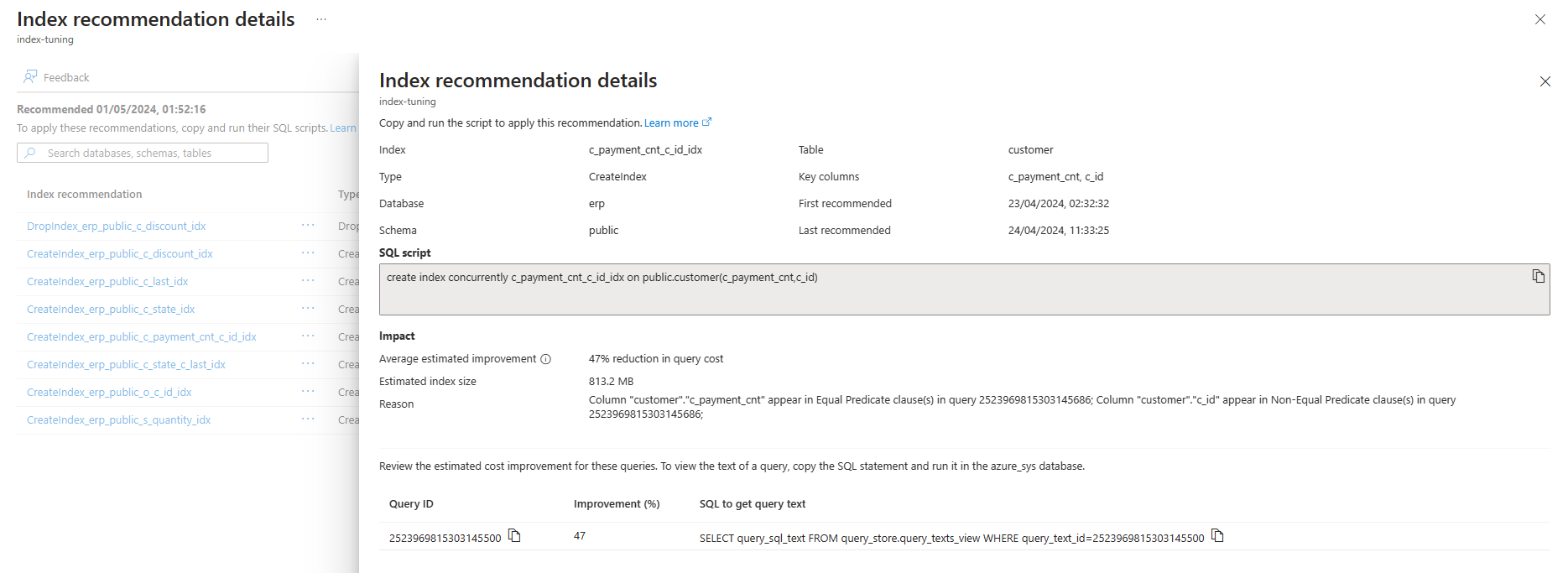
Per visualizzare altre informazioni su una raccomandazione specifica, selezionare il nome della raccomandazione e il riquadro Dettagli raccomandazione indice si apre sul lato destro dello schermo per visualizzare tutti i dettagli disponibili sulla raccomandazione:






Utilizzare le raccomandazioni sugli indici tramite viste disponibili nel database di azure_sys
- Connettersi al database
azure_sysdisponibile nel server con qualsiasi ruolo autorizzato a connettersi all'istanza. I membri del ruolopublicpossono leggere da queste visualizzazioni. - Eseguire query nella
sessionsvista per recuperare i dettagli sulle sessioni di raccomandazione. - Eseguire query sulla
recommendationsvista per recuperare le raccomandazioni generate dall'ottimizzazione dell'indice per CREATE INDEX e DROP INDEX.
Visualizzazioni
Le viste nel database azure_sys offrono un modo pratico per accedere e recuperare le raccomandazioni sugli indici generate dall'ottimizzazione dell'indice. In particolare, le viste createindexrecommendations e dropindexrecommendations contengono rispettivamente informazioni dettagliate sulle raccomandazioni CREATE INDEX e DROP INDEX. Queste viste espongono dati come l'ID sessione, il nome del database, il tipo di advisor, l'ora di avvio e arresto della sessione di ottimizzazione, l'ID raccomandazione, il tipo di raccomandazione, il motivo della raccomandazione e altri dettagli pertinenti. Eseguendo query su queste viste, gli utenti possono accedere e analizzare facilmente le raccomandazioni sugli indici generate dall'ottimizzazione dell'indice.
intelligentperformance.sessions
La sessions vista espone tutti i dettagli per tutte le sessioni di ottimizzazione dell'indice.
| nome colonna | tipo di dati | Descrizione |
|---|---|---|
| session_id | uuid | Identificatore univoco globale assegnato a ogni nuova sessione di ottimizzazione avviata. |
| database_name | varchar(64) | Nome del database nel cui contesto è stata eseguita la sessione di ottimizzazione dell'indice. |
| session_type | intelligentperformance.recommendation_type | Indica i tipi di raccomandazioni che questa sessione di ottimizzazione dell'indice può produrre. I valori possibili sono: CreateIndex, DropIndex. Le sessioni di CreateIndex tipo possono produrre raccomandazioni di CreateIndex tipo. Le sessioni di DropIndex tipo possono produrre raccomandazioni di DropIndex o ReIndex tipi. |
| run_type | intelligentperformance.recommendation_run_type | Indica il modo in cui è stata avviata la sessione. I valori possibili sono:Scheduled. Alle sessioni eseguite automaticamente in base al valore di index_tuning.analysis_interval, viene assegnato un tipo di esecuzione di Scheduled. |
| state | intelligentperformance.recommendation_state | Indica lo stato corrente della sessione. I valori possibili sono i seguenti: Error, Success, InProgress. Le sessioni di cui l'esecuzione non è riuscita vengono impostate come Error. Le sessioni che hanno completato correttamente l'esecuzione, indipendentemente dal fatto che abbiano generato o meno raccomandazioni, vengano impostate come Success. Le sessioni ancora in esecuzione vengono impostate come InProgress. |
| start_time | timestamp senza fuso orario | Timestamp in cui è stata avviata la sessione di ottimizzazione che ha prodotto questa raccomandazione. |
| stop_time | timestamp senza fuso orario | Timestamp in cui è stata avviata la sessione di ottimizzazione che ha prodotto questa raccomandazione. NULL se la sessione è in corso o è stata interrotta a causa di un errore. |
| recommendations_count | integer | Numero totale di raccomandazioni prodotte in questa sessione. |
intelligentperformance.recommendations
La recommendations vista espone tutti i dettagli per tutte le raccomandazioni generate in qualsiasi sessione di ottimizzazione i cui dati sono ancora disponibili nelle tabelle sottostanti.
| nome colonna | tipo di dati | Descrizione |
|---|---|---|
| recommendation_id | integer | Numero che identifica in modo univoco una raccomandazione nell'intero server. |
| last_known_session_id | uuid | A ogni sessione di ottimizzazione dell'indice viene assegnato un identificatore univoco globale. Il valore in questa colonna rappresenta quello della sessione che ha prodotto più di recente questa raccomandazione. |
| database_name | varchar(64) | Nome del database nel cui contesto è stato prodotto il consiglio. |
| recommendation_type | intelligentperformance.recommendation_type | Indica il tipo di raccomandazione prodotta. I valori possibili sono i seguenti: CreateIndex, DropIndex, ReIndex. |
| initial_recommended_time | timestamp senza fuso orario | Timestamp in cui è stata avviata la sessione di ottimizzazione che ha prodotto questa raccomandazione. |
| last_recommended_time | timestamp senza fuso orario | Timestamp in cui è stata avviata la sessione di ottimizzazione che ha prodotto questa raccomandazione. |
| times_recommended | integer | Timestamp in cui è stata avviata la sessione di ottimizzazione che ha prodotto questa raccomandazione. |
| reason | Testo | Motivo che giustifica il motivo per cui questa raccomandazione è stata prodotta. |
| recommendation_context | JSON | Contiene l'elenco di identificatori di query per le query interessate dalla raccomandazione, il tipo di indice consigliato, il nome dello schema e il nome della tabella in cui è consigliato l'indice, le colonne di indice, il nome dell'indice e le dimensioni stimate in byte dell'indice consigliato. |
Motivi per la creazione di raccomandazioni sugli indici
Quando l'ottimizzazione dell'indice consiglia la creazione di un indice, aggiunge almeno uno dei motivi seguenti:
| Motivo |
|---|
Column <column> appear in Join On clause(s) in query <queryId> |
Column <column> appear in Equal Predicate clause(s) in query <queryId> |
Column <column> appear in Non-Equal Predicate clause(s) in query <queryId> |
Column <column> appear in Group By clause(s) in query <queryId> |
Column <column> appear in Order By clause(s) in query <queryId> |
Motivi per eliminare le raccomandazioni sugli indici
Quando l'ottimizzazione dell'indice identifica gli indici contrassegnati come non validi, si propone di eliminarlo con il motivo seguente:
The index is invalid and the recommended recovery method is to reindex.
Per altre informazioni sui motivi e sui casi in cui gli indici sono contrassegnati come non validi, vedere la documentazione ufficiale di REINDEX in PostgreSQL.
Motivi per eliminare le raccomandazioni sugli indici
Quando l'ottimizzazione dell'indice rileva un indice inutilizzato per almeno il numero di giorni impostato in index_tuning.unused_min_period, propone di eliminarlo con il motivo seguente:
The index is unused in the past <days_unused> days.
Quando l'ottimizzazione dell'indice rileva indici duplicati, uno dei duplicati sopravvive e propone di eliminare gli indici rimanenti. Il motivo fornito ha sempre il testo iniziale seguente:
Duplicate of <surviving_duplicate>.
Seguito da un altro testo che spiega il motivo per cui ognuno dei duplicati è stato scelto per l'eliminazione:
| Motivo |
|---|
The equivalent index "<surviving_duplicate>" is a Primary key, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" is a unique index, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" is a constraint, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" is a valid index, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" has been chosen as replica identity, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" was used to cluster the table, while "<droppable_duplicate>" was not. |
The equivalent index "<surviving_duplicate>" has a smaller estimated size compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has more tuples compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has more index scans compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has been fetched more times compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has been read more times compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has a shorter length compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has a smaller oid compared to "<droppable_duplicate>". |
Se l'indice non solo è rimovibile a causa della duplicazione, ma anche per, almeno, il numero di giorni impostati in index_tuning.unused_min_period, il testo seguente viene accodato al motivo:
Also, the index is unused in the past <days_unused> days.
Applicare le raccomandazioni sugli indici
Le raccomandazioni sugli indici contengono l'istruzione SQL che è possibile eseguire per implementare la raccomandazione.
Le sezioni seguenti illustrano come ottenere questa istruzione per una raccomandazione specifica.
Dopo aver ottenuto l'istruzione, è possibile usare qualsiasi client PostgreSQL delle proprie preferenze per connettersi al server e applicare la raccomandazione.
Ottenere un'istruzione SQL tramite la pagina di ottimizzazione dell'indice in portale di Azure
Accedere al portale di Azure e selezionare il Database di Azure per il server flessibile PostgreSQL.
Selezionare Ottimizzazione dell'indice nella sezione Prestazioni intelligenti del menu.
Supponendo che l'ottimizzazione dell'indice abbia già prodotto raccomandazioni, selezionare il riepilogo Visualizza raccomandazioni sugli indici per accedere all'elenco delle raccomandazioni disponibili.
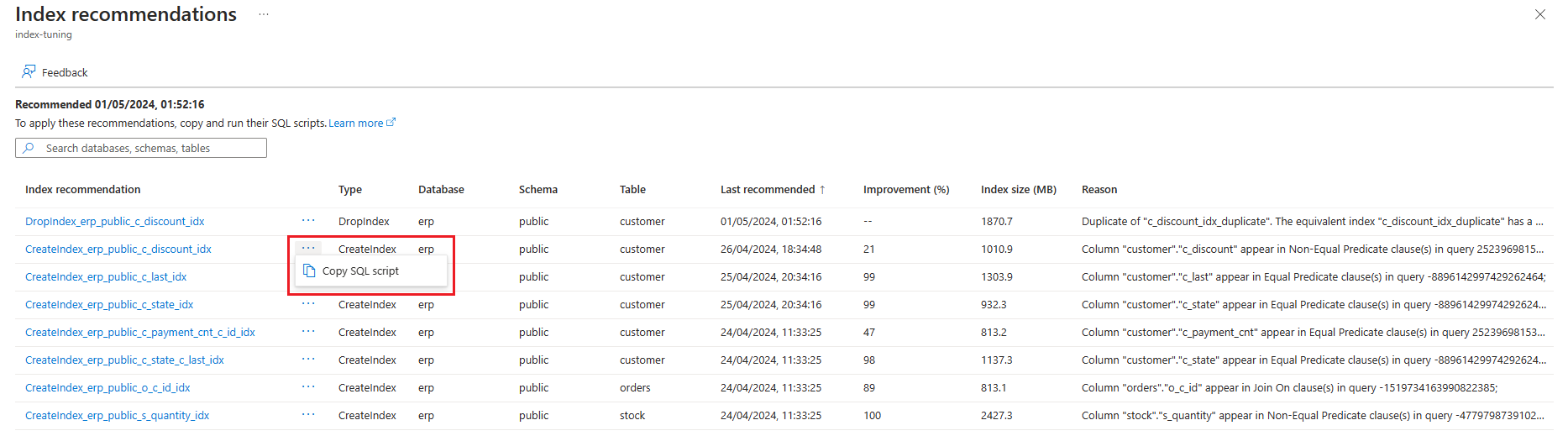
Dall'elenco di raccomandazioni:
Selezionare i puntini di sospensione a destra della raccomandazione per cui si vuole ottenere l'istruzione SQL e selezionare Copia script SQL.
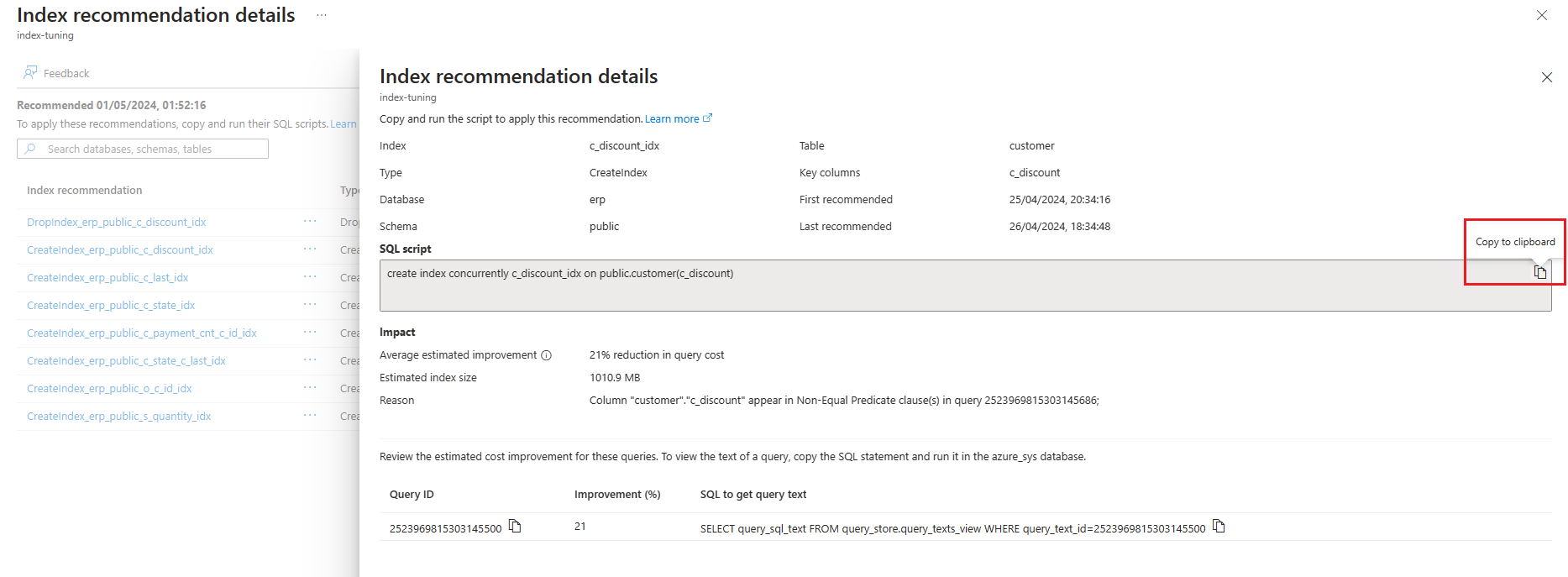
In alternativa, selezionare il nome della raccomandazione per visualizzare i dettagli della raccomandazione indice e selezionare l'icona copia negli Appunti nella casella di testo Script SQL per copiare l'istruzione SQL.

Contenuto correlato
- Ottimizzazione degli indici in Database di Azure per PostgreSQL - Server flessibile
- Configurare l'ottimizzazione degli indici in Database di Azure per PostgreSQL - Server flessibile
- Monitorare le prestazioni con Query Store
- Scenari di utilizzo per Query Store - Database di Azure per PostgreSQL - Server flessibile
- Procedure consigliate per Query Store - Database di Azure per PostgreSQL - Server flessibile
- Informazioni dettagliate prestazioni query per Database di Azure per PostgreSQL - Server flessibile