Fasi di migrazione da Oracle a Database di Azure per PostgreSQL
Una migrazione end-to-end completa da Oracle ad Azure Postgres richiede un'attenta esecuzione di diversi passaggi chiave e fasi di migrazione. Queste attività cardine sono tutte strettamente correlate ed essenziali per una migrazione completa e riuscita.
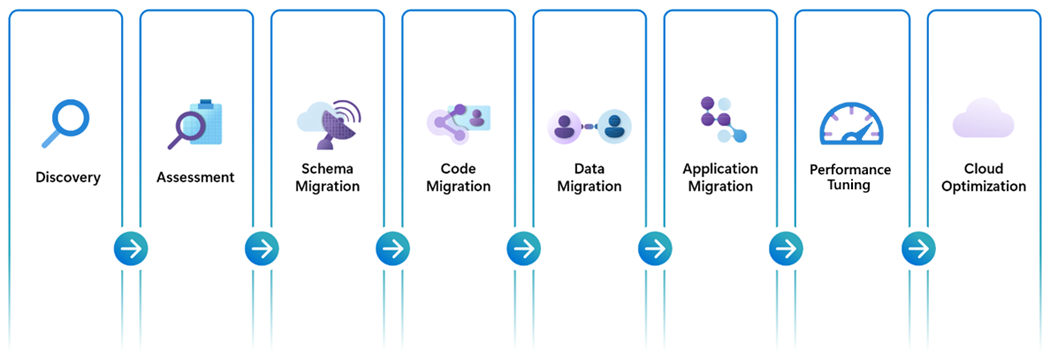
Individuazione
La maggior parte dei clienti ha già familiarità con le quantità e le posizioni delle istanze del database Oracle (in particolare i costi di licenza associati), ma per completezza questa fase viene evidenziata come punto di partenza importante nella migrazione. La fase di individuazione è una fase ideale per determinare l'ambito appropriato delle attività di migrazione. Si dispone di un ambiente "farm" del server di database Oracle che richiede decine, centinaia o persino migliaia di database di cui eseguire la migrazione? Si sta valutando una migrazione su larga scala seguendo un approccio "migration factory"? L'ambiente è invece più adatto per la migrazione end-to-end di un singolo database insieme a una modernizzazione parallela di tutti i client connessi prima di passare al database successivo nell'elenco di migrazione? In entrambi i casi, un inventario aggiornato e completo è un prerequisito critico e la fase di individuazione garantisce la preparazione per il successo.
Valutazioni
Le valutazioni incapsulano molti tipi diversi di operazioni esplorative basate su stima che sono definite singolarmente dalle loro caratteristiche uniche. Alcune valutazioni sono progettate per stimare e classificare la complessità del lavoro e delle risorse coinvolte nella migrazione degli oggetti di database e in base a fattori quali il numero di oggetti (potenzialmente anche esplorando il numero di righe di codice) che richiedono attenzione da un esperto di materia. In alternativa, altri tipi di valutazioni esplorano la struttura e le dimensioni dei dati sottostanti e forniscono indicazioni sulla quantità di tempo necessaria per eseguire completamente la migrazione dei dati nell'ambiente di destinazione. Un altro tipo di valutazione è tuttavia strutturato per garantire che le risorse di Azure Postgres di destinazione siano ridimensionate in modo appropriato per supportare la configurazione di calcolo, memoria, IOPS e rete necessaria per gestire i dati. Una delle valutazioni più importanti che devono essere incluse per garantire il successo della migrazione è una revisione approfondita e una considerazione completa di tutti i client connessi e l'ambito che comprende tutte le applicazioni dipendenti. Per riepilogare, quando si preparano le valutazioni della migrazione, assicurarsi di valutare tutti gli aspetti della migrazione del database, tra cui:
- Schema del database/quantità di conversione del codice e complessità
- Dimensioni e scalabilità del database
- Requisiti operativi delle risorse del database
- Migrazione del codice dell'applicazione client
L'accuratezza della valutazione sarà strettamente legata agli strumenti e alle piattaforme di servizio sottostanti specifici coinvolti nell'esecuzione e nel completamento dei passaggi successivi della migrazione. È quindi importante considerare che esistono diversi fattori che possono influire sull'accuratezza di queste stime di valutazione e i risultati segnalati sono direttamente correlati agli strumenti sottostanti utilizzati nella valutazione della migrazione. È necessario prestare attenzione per evitare di interpolare gli output di stima da strumenti diversi o combinati durante la revisione e l'incorporamento degli output di valutazione nei piani di migrazione.
Per altre informazioni, vedere il playbook per la migrazione da Oracle ad Azure Postgres
Migrazione dello schema del database
Le definizioni di dati strutturati sono una delle caratteristiche distintive dei motori di database transazionali e una base essenziale per una piattaforma dati ben progettata. Assicurarsi che le strutture di dati e le definizioni dei tipi di dati Oracle univoche vengano mappate correttamente alle rispettive tabelle all'interno di Azure Postgres è un requisito fondamentale per il successo complessivo della migrazione. Sebbene tutti i database transazionali condividano molte analogie, esistono differenze tra le tabelle di dati e i tipi di dati delle colonne ed è necessario prestare attenzione per assicurarsi che i dati non vengano accidentalmente persi, troncati o sconvolti a causa di definizioni di dati non corrispondenti. I tipi di dati numerici, i tipi di dati di data/ora e i tipi di dati basati su testo sono solo alcuni esempi di aree da esaminare attentamente quando si sviluppano mapping di dati corrispondenti per la migrazione.
Per altre informazioni ed esempi delle differenze tra i tipi di dati Oracle e Postgres, vedere il playbook di migrazione da Oracle ad Azure Postgres
Migrazione del codice del database
La migrazione del codice del database si riferisce al processo di conversione del codice di database scritto per Oracle per essere compatibile con il motore di database Postgres, mantenendo al tempo stesso le funzionalità originali e le caratteristiche delle prestazioni esistenti. Questo processo comporta la conversione di query PL/SQL Oracle, stored procedure, funzioni, trigger e altri oggetti di database conformi a Postgres PL/pgSQL. Fortunatamente, i dialetti procedurali PL/PGSQL di Oracle e PL/pgSQL di Oracle condividono molte analogie e questo è in genere il fattore iniziale che molte organizzazioni identificano quando si seleziona Postgres come la soluzione migliore per le migrazioni di database Oracle. Esistono tuttavia alcune differenze e distinzioni univoche tra le due lingue di database che devono essere considerate. Le aree di attenzione includono: parole chiave e sintassi specifiche del database, gestione delle eccezioni, funzioni predefinite, tipi di dati e incremento della sequenza.
In molti casi, l'ecosistema di estensioni Postgres può essere un potente alleato per semplificare il processo di migrazione del codice. Ad esempio, l'estensione "Funzioni Oracle per PostgreSQL" (orafce) fornisce un set di funzioni e pacchetti di compatibilità Oracle predefiniti che possono ridurre la necessità di riscrivere parti della codebase che si basano su e fare riferimento a queste funzioni Oracle. L'uso di questo approccio basato sulla compatibilità durante la migrazione del codice Oracle a PostgreSQL offre vantaggi significativi in termini di riduzione della complessità, del tempo e del costo del processo di migrazione mantenendo la logica e le funzionalità originali delle definizioni del database di origine, garantisce coerenza nei risultati e migliora la produttività degli sviluppatori. Tutti questi vantaggi si aggiungono a una migrazione del codice semplificata e più efficiente a PostgreSQL.
Per altre informazioni ed esempi delle differenze tra le funzioni predefinite di Oracle e Postgres e gli operatori logici, vedere il playbook oracle per la migrazione ad Azure Postgres
Migrazione dati
Nell'ambiente odierno basato sui dati, i dati sono probabilmente l'asset più prezioso. Le risorse dati influenzano sempre più ogni aspetto delle operazioni aziendali informate e del processo decisionale strategico. È quindi particolarmente importante che le pipeline di migrazione dei dati funzionino in modo efficiente e rapido, siano completamente coerenti e verificabili e infine completate correttamente.
La strategia di migrazione dei dati deve essere considerata attentamente per determinare se gli approcci "offline" o "live" sono applicabili all'ambiente in uso. Ogni strategia di migrazione dei dati ha una propria combinazione di vantaggi e considerazioni e la scelta tra le operazioni "offline" e "in tempo reale" dipende dai requisiti e dai vincoli specifici dell'ambiente. Le migrazioni "offline", ad esempio, possono essere più semplici e meno complesse delle migrazioni "in tempo reale", ma le migrazioni "offline" comportano tempi di inattività per il periodo di tempo necessario per eseguire completamente la migrazione dei dati al database di destinazione. Le migrazioni "in tempo reale" offrono un tempo di inattività minimo, ma implicano maggiore complessità e infrastruttura per supervisionare il caricamento iniziale dei dati di riempimento e la successiva sincronizzazione dei dati delle modifiche che potrebbero essersi verificate dall'inizio della migrazione dei dati. Un'attenta pianificazione, una valutazione approfondita dei requisiti aziendali e la considerazione dei fattori critici specifici del team garantiranno la possibilità di prendere una decisione informata completamente allineata alle esigenze di migrazione dei dati.
Migrazione del codice dell'applicazione
Anche se le applicazioni esterne possono essere considerate tecnicamente esterne al dominio delle responsabilità di migrazione del team di database, l'aggiornamento e la modernizzazione della connettività del database alle applicazioni client è una fase essenziale e strettamente correlata al successo complessivo del percorso di migrazione del database. Come per le altre fasi della migrazione, l'impegno e la complessità associati correlati alla correzione della compatibilità della piattaforma dell'applicazione client dipendono dalle circostanze specifiche dell'ambiente. Le applicazioni client sono sviluppate da terze parti? In tal caso, è importante assicurarsi che il prodotto software sia certificato per supportare la piattaforma di database Postgres. Le applicazioni interne usano tecnologie di mapping relazionali a oggetti, ad esempio Hibernate o Entity Framework? In alcuni casi, una piccola configurazione o modifica del file può essere tutto ciò che è necessario. Viceversa, se si dispone di quantità significative di query e istruzioni di database incorporate all'interno del codice, potrebbe essere necessario allocare più tempo per esaminare, modificare e convalidare in modo appropriato le modifiche al codice.
In alternativa, esistono provider di soluzioni partner che offrono nuovi approcci in grado di tradurre le operazioni legacy dei database client in tempo reale. Questi servizi proxy forniscono un'astrazione sui livelli del database che separano efficacemente le applicazioni da eventuali dipendenze del linguaggio specifiche del database.
In molti casi, la decisione può incorporare una combinazione di più strategie e approcci ibridi impiegati collettivamente per i rispettivi punti di forza e capacità combinate. La distribuzione di un livello di conversione del database in tempo reale consente ai team di ri-distribuire rapidamente le applicazioni client, fornendo ai software engineer e agli sviluppatori una pianificazione appropriata in tempo e risorse per effettuare il refactoring delle dipendenze specifiche del database per supportare le operazioni native di Postgres.
Importante
Ognuna di queste scelte è accompagnata da particolari set di considerazioni e vantaggi ed è essenziale che i team esaminino attentamente ognuno di questi approcci per determinare il percorso strategico ideale.
Convalida della migrazione
Quando si esegue la migrazione da Oracle a PostgreSQL, garantire l'integrità dei dati e la coerenza logica sono entrambi fondamentali. La convalida della migrazione svolge un ruolo fondamentale in questo processo, perché implica la verifica che i dati trasferiti dal database Oracle di origine siano accurati e completi nel sistema PostgreSQL di destinazione. Questo passaggio è essenziale non solo per mantenere la attendibilità dei dati, ma anche per confermare che il processo di migrazione non ha introdotto errori o discrepanze. I controlli di convalida possono includere il confronto dei conteggi delle tabelle, la verifica dei tipi di dati e delle strutture, il confronto dei valori delle colonne a livello di riga e la garanzia che le query complesse produno risultati coerenti in entrambi i database. Inoltre, è necessario prestare particolare attenzione durante la gestione delle differenze nel modo in cui i due sistemi di database gestiscono i dati, ad esempio le variazioni nei formati di data e ora, la codifica dei caratteri e la gestione dei valori Null.
Ciò comporta in genere la configurazione di script di convalida automatizzati in grado di confrontare i set di dati in entrambi i database ed evidenziare eventuali anomalie. Gli strumenti e i framework progettati per il confronto dei dati possono essere sfruttati per semplificare questo processo. La convalida post-migrazione deve essere un processo iterativo, con più controlli eseguiti in varie fasi della migrazione per rilevare i problemi in anticipo e ridurre al minimo il rischio di danneggiamento dei dati. Assegnando priorità alla convalida dei dati, le organizzazioni possono passare in modo sicuro da Oracle a PostgreSQL, sapendo che i dati rimangono affidabili e interattivi.
Ottimizzazione delle prestazioni
Le prestazioni sono generalmente considerate una delle caratteristiche più tangibili e importanti che determinano la percezione e l'usabilità della piattaforma. Garantire che la migrazione sia sia accurata che efficiente è fondamentale per ottenere successo e non può essere trascurata. In particolare, le prestazioni delle query vengono spesso considerate l'indicatore più critico della configurazione ottimale del database e vengono comunemente usate come test di litmus da parte degli utenti per determinare lo stato di integrità dell'ambiente.
Fortunatamente, la piattaforma Azure incorpora in modo nativo gli strumenti e le funzionalità necessari per monitorare i punti di prestazioni in un'ampia gamma di metriche, tra cui scalabilità, efficienza e, forse, più importante, velocità. Queste funzionalità di prestazioni intelligenti funzionano a portata di mano con le risorse di monitoraggio di Postgres per semplificare i processi di ottimizzazione e, in molti casi, automatizzare questi passaggi per adattare e regolare automaticamente in base alle esigenze. Gli strumenti di Azure seguenti possono garantire che i sistemi di database funzionino a livelli ottimali.
Archivio query
Query Store per Azure Postgres funge da base per le funzionalità di monitoraggio. Query Store tiene traccia delle statistiche e delle metriche operative del database Postgres, incluse le query, i piani di spiegazione associati, l'utilizzo delle risorse e la tempistica del carico di lavoro. Questi punti dati possono individuare query a esecuzione prolungata, query che utilizzano la maggior parte delle risorse, le query eseguite più di frequente, un numero eccessivo di tabelle e molti altri facet operativi del database. Queste informazioni consentono di dedicare meno tempo alla risoluzione dei problemi identificando rapidamente eventuali operazioni o aree che richiedono attenzione. Query Store offre una visualizzazione completa delle prestazioni complessive del carico di lavoro identificando:
- Query a esecuzione prolungata e modalità di modifica nel tempo.
- Tipi di attesa che interessano tali query.
- Informazioni dettagliate sulle query di database principali per chiamate (conteggio esecuzioni), per utilizzo dei dati, per operazioni di I/O al secondo e utilizzo temporaneo dei file (potenziali candidati di ottimizzazione per i miglioramenti delle prestazioni).
- Eseguire il drill-down dei dettagli di una query per visualizzare l'ID query e la cronologia dell'utilizzo delle risorse.
- Informazioni più approfondite sull'utilizzo complessivo delle risorse dei database.
Ottimizzazione dell'indice
L'ottimizzazione degli indici è una funzionalità di Database di Azure per PostgreSQL server flessibile che può migliorare automaticamente le prestazioni del carico di lavoro analizzando le query rilevate e fornendo raccomandazioni sugli indici. È integrato in modo nativo in Database di Azure per PostgreSQL server flessibile e si basa sulle funzionalità di Query Store. L'ottimizzazione dell'indice analizza i carichi di lavoro rilevati da Query Store e produce raccomandazioni sugli indici per migliorare le prestazioni del carico di lavoro analizzato o per eliminare indici duplicati o inutilizzati. Questa operazione viene eseguita in tre modi unici:
- Identificare quali indici sono utili da creare, perché potrebbero migliorare significativamente le query analizzate durante una sessione di ottimizzazione dell'indice.
- Identificare gli indici che sono duplicati identici e che possono essere eliminati per ridurre l'impatto che la loro esistenza e manutenzione ha sulle prestazioni complessive del sistema.
- Identificare gli indici non utilizzati in un periodo configurabile e che potrebbero essere candidati all’eliminazione.
Ottimizzazione intelligente
L'ottimizzazione intelligente è un processo continuo di monitoraggio e analisi che non solo apprende le caratteristiche del carico di lavoro, ma tiene traccia del carico corrente e dell'utilizzo delle risorse, ad esempio CPU o IOPS. Non disturba le normali operazioni del carico di lavoro dell'applicazione. Il processo consente al database di regolare dinamicamente il carico di lavoro rilevando il rapporto di software bloat corrente, le prestazioni di scrittura e l'efficienza del checkpoint nell'istanza. Con queste informazioni dettagliate, l'ottimizzazione intelligente distribuisce azioni di ottimizzazione che migliorano le prestazioni del carico di lavoro ed evitano potenziali insidie. Questa funzionalità include due funzioni di ottimizzazione automatica:
- Ottimizzazione autovacuum: questa funzione tiene traccia del rapporto di software bloat e regola le impostazioni autovacuum di conseguenza. Influisce sull'utilizzo delle risorse corrente e stimato per evitare interruzioni del carico di lavoro.
- Ottimizzazione scritture: questa funzione monitora il volume e i modelli delle operazioni di scrittura e modifica i parametri che influiscono sulle prestazioni di scrittura. Queste regolazioni migliorano sia le prestazioni del sistema che l'affidabilità, per evitare in modo proattivo potenziali complicazioni.
Suggerimento
Altre informazioni sull'applicazione di prestazioni intelligenti per ottimizzare le piattaforme Postgres di Azure.
Ottimizzazione del cloud
L'ottimizzazione del nuovo ambiente di database postgres di Azure indica il culmine di tutto l'incredibile lavoro e il duro lavoro che ha portato il team ad arrivare a questo punto chiave. L'ottimizzazione del cloud può essere una nuova responsabilità, soprattutto quando proviene da un ambiente di database locale o legacy. La piattaforma cloud di Azure introduce un nuovo e avanzato set di funzionalità di scalabilità preziose e all'avanguardia che consentono al team di "comporre" l'allocazione precisa di risorse, funzionalità ed efficienza dei costi per soddisfare le esigenze dell'organizzazione oggi e ben avanti in futuro. L'ottimizzazione del cloud è un processo continuo di perfezionamento continuo per l'ambiente, come illustrato attraverso le lenti delle procedure consigliate associate al framework ben progettato da Microsoft: ottimizzazione dei costi, eccellenza operativa, efficienza delle prestazioni, affidabilità e sicurezza.
L'ottimizzazione dei costi è una combinazione di ridimensionamento corretto delle risorse, applicazione di strategie per la gestione dei costi e un utilizzo efficiente delle risorse.
L'eccellenza operativa include l'adozione dell'automazione per distribuzioni, monitoraggio e scalabilità e riduce l'errore aumentando l'efficienza.
L'efficienza delle prestazioni garantisce di scegliere le risorse appropriate per soddisfare i requisiti senza provisioning eccessivo, applicando al tempo stesso le procedure consigliate per la scalabilità per gestire carichi variabili in modo efficiente durante i periodi operativi di picco.
L'affidabilità guida verso sistemi a disponibilità elevata e a tolleranza di errore con meccanismi di ridondanza e failover per ridurre al minimo i tempi di inattività e strategie di ripristino di emergenza per l'implementazione di piani di ripristino affidabili, incluse le procedure di backup e ripristino.
La sicurezza sottolinea l'importanza di protocolli di identità avanzati e procedure di gestione degli accessi, ad esempio l'accesso con privilegi minimi, l'autenticazione senza password e il controllo degli accessi in base al ruolo. La protezione dei dati e la crittografia assicurano che i dati sensibili siano protetti sia inattivi che in transito. La sicurezza include anche strumenti e procedure consigliate per il rilevamento delle minacce e risposte automatizzate per affrontare tempestivamente gli eventi imprevisti di sicurezza. La conformità garantisce che l'ambiente sia conforme agli standard e alle normative del settore.
Per altre informazioni sui cinque pilastri delle linee guida e nozioni fondamentali sull'implementazione dell'ottimizzazione cloud, visitare il centro Azure Well-Architected Framework (WAF).
Per assicurarsi che questi pilastri siano allineati alla distribuzione di Azure Postgres, vedere la Guida al servizio Azure Well-Architected Framework per PostgreSQL.