Disponibilità elevata di IBN DB2 LUW in macchine virtuali di Azure su Red Hat Enterprise Linux Server
IBM Db2 per Linux, UNIX e Windows (LUW) nella configurazione della disponibilità elevata e del ripristino di emergenza (HADR) è costituito da un nodo che esegue un'istanza di database primaria e almeno un nodo che esegue un'istanza di database secondaria. Le modifiche apportate all'istanza di database primaria vengono replicate in un'istanza di database secondaria in modo sincrono o asincrono, a seconda della configurazione.
Nota
Questo articolo contiene riferimenti a termini che Microsoft non usa più. Quando questi termini verranno rimossi dal software, verranno rimossi da questo articolo.
Questo articolo descrive come distribuire e configurare le macchine virtuali di Azure, installare il framework del cluster e installare IBM Db2 LUW con la configurazione HADR.
L'articolo non illustra come installare e configurare IBM Db2 LUW con l'installazione di HADR o del software SAP. Per facilitare l'esecuzione di queste attività, vengono forniti riferimenti ai manuali di installazione di SAP e IBM. Questo articolo è incentrato su parti specifiche dell'ambiente Azure.
Le versioni di IBM Db2 supportate sono 10.5 e successive, come documentato nella nota SAP 1928533.
Prima di iniziare un'installazione, vedere le note e la documentazione SAP seguenti:
| Nota SAP | Descrizione |
|---|---|
| 1928533 | Applicazioni SAP in Azure: prodotti supportati e tipi di macchine virtuali di Azure |
| 2015553 | SAP in Azure: prerequisiti del supporto |
| 2178632 | Metriche chiave del monitoraggio per SAP in Azure |
| 2191498 | SAP in Linux con Azure: monitoraggio avanzato |
| 2243692 | Linux in una macchina virtuale di Azure (IaaS): problemi delle licenze SAP |
| 2002167 | Red Hat Enterprise Linux 7. x: installazione e aggiornamento |
| 2694118 | Componente aggiuntivo a disponibilità elevata di Red Hat Enterprise Linux in Azure |
| 1999351 | Risoluzione dei problemi del monitoraggio avanzato di Azure per SAP |
| 2233094 | DB6: informazioni aggiuntive sulle applicazioni SAP in Azure che usano IBM Db2 per Linux, UNIX e Windows |
| 1612105 | DB6: domande frequenti su Db2 con HADR |
Panoramica
Per ottenere la disponibilità elevata, IBM Db2 LUW con HADR viene installato in almeno due macchine virtuali di Azure, distribuite in un set di scalabilità di macchine virtuali con orchestrazione flessibile tra le zone di disponibilità o in un set di disponibilità.
Nella grafica seguente viene mostrata una configurazione di due macchine virtuali di Azure del server di database. Entrambe le macchine virtuali di Azure del server di database hanno una propria risorsa di archiviazione collegata e sono attive e in esecuzione. In HADR, un'istanza di database in una delle macchine virtuali di Azure ha il ruolo di istanza primaria. Tutti i client sono connessi all’istanza primaria. Tutte le modifiche apportate alle transazioni del database vengono mantenute in locale nel log delle transazioni di Db2. Poiché i record del log delle transazioni sono persistenti in locale, vengono trasferiti tramite TCP/IP all'istanza di database nel secondo server di database, nel server di standby o nell'istanza di standby. L'istanza di standby aggiorna il database locale eseguendo il roll forward dei record del log delle transazioni trasferiti. In questo modo, il server standby resta sincronizzato con il server primario.
HADR è solo una funzionalità di replica. Non ha la funzione di rilevamento degli errori e né di acquisizione o failover automatici. Un'acquisizione o un trasferimento al server di standby deve essere avviato manualmente da un amministratore di database. Per ottenere le funzioni automatiche di rilevamento degli errori e acquisizione, è possibile usare la funzionalità di clustering di Linux Pacemaker. Pacemaker monitora le due istanze del server di database. Quando l'istanza del server di database primaria si arresta in modo anomalo, Pacemaker avvia un'acquisizione HADR automatica dal server di standby. Pacemaker garantisce anche che l'indirizzo IP virtuale sia assegnato al nuovo server primario.
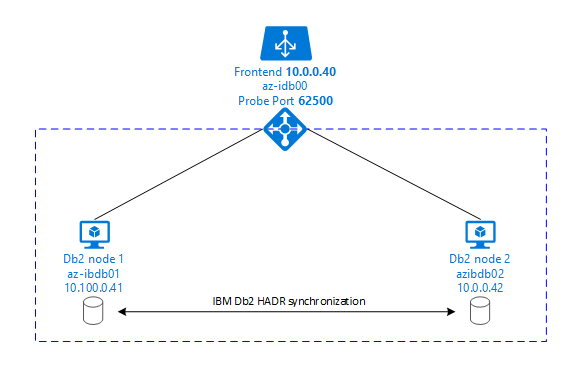
Per fare in modo che i server applicazioni SAP si connettano al database primario, sono necessari un nome host virtuale e un indirizzo IP virtuale. Dopo un failover, i server applicazioni SAP si connettono alla nuova istanza di database primaria. In un ambiente Azure è necessario un servizio di bilanciamento del carico di Azure per usare un indirizzo IP virtuale nel modo richiesto da HADR di IBM Db2.
Per illustrare al meglio il modo in cui IBM Db2 LUW con HADR e Pacemaker si adatta a una configurazione del sistema SAP a disponibilità elevata, l'immagine seguente presenta una panoramica di una configurazione a disponibilità elevata di un sistema SAP basato sul database IBM Db2. Questo articolo illustra solo IBM Db2, ma fornisce riferimenti ad altri articoli su come configurare altri componenti di un sistema SAP.
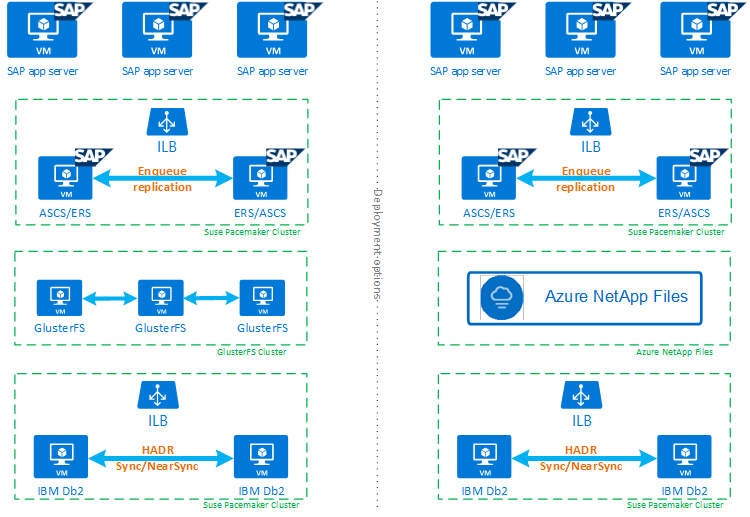
Panoramica generale dei passaggi necessari
Per distribuire una configurazione di IBM Db2, è necessario seguire questa procedura:
- Pianificare l'ambiente.
- Distribuire le macchine virtuali.
- Aggiornare RHEL Linux e configurare i file system.
- Installare e configurare Pacemaker.
- Configurare cluster glusterfs o Azure NetApp Files
- Installare ASCS/ERS in un cluster separato.
- Installare il database IBM Db2 con l'opzione Distribuito/Disponibilità elevata (SWPM).
- Installare e creare un nodo e un'istanza di database secondari e configurare HADR.
- Verificare che HADR funzioni.
- Applicare la configurazione di Pacemaker per controllare IBM Db2.
- Configurare Azure Load Balancer.
- Installare i server applicazioni primari e con finestre di dialogo.
- Controllare e adattare la configurazione dei server applicazioni SAP.
- Eseguire test di failover e acquisizione.
Pianificare l'infrastruttura di Azure per l'hosting di IBM Db2 LUW con HADR
Completare il processo di pianificazione prima di eseguire la distribuzione. La pianificazione crea le basi per la distribuzione di una configurazione di Db2 con HADR in Azure. Gli elementi chiave che devono far parte della pianificazione per IMB Db2 LUW (database parte dell'ambiente SAP) sono elencati nella tabella seguente:
| Argomento | Descrizione breve |
|---|---|
| Definire i gruppi di risorse di Azure | Gruppi di risorse in cui si esegue la distribuzione di macchina virtuale, rete virtuale, Azure Load Balancer e altre risorse. Può essere nuovo o esistente. |
| Definizione della subnet/rete virtuale | In cui vengono distribuite le macchine virtuali per IBM Db2 e Azure Load Balancer. Possono essere esistenti o appena creati. |
| Macchine virtuali che ospitano IBM Db2 LUW | Dimensioni della macchina virtuale, archiviazione, rete, indirizzo IP. |
| Nome host virtuale e IP virtuale per il database IBM Db2 | L'indirizzo IP virtuale o il nome host vengono usati per la connessione dei server applicazioni SAP. db-virt-hostname, db-virt-ip. |
| Isolamento tramite Azure | Metodo per evitare situazioni di split brain viene evitato. |
| Azure Load Balancer | Utilizzo del servizio Standard (scelta consigliata), porta probe per il database Db2 (si consiglia la porta 62500) porta probe. |
| Risoluzione dei nomi | Funzionamento della risoluzione dei nomi nell'ambiente. Il servizio DNS è altamente consigliato. È possibile usare il file host locale. |
Per altre informazioni su Linux Pacemaker in Azure, vedere Configurazione di Pacemaker su Red Hat Enterprise Linux in Azure.
Importante
Per Db2 versione 11.5.6 e successive è consigliabile la soluzione integrata che usa Pacemaker di IBM.
Distribuzione in Red Hat Enterprise Linux
L'agente di risorse per IBM Db2 LUW è incluso in Red Hat Enterprise Linux con componenti aggiuntivi a disponibilità elevata. Per la configurazione descritta in questo documento, è consigliabile usare Red Hat Enterprise Linux per SAP. Azure Marketplace contiene un'immagine per Red Hat Enterprise Linux 7.4 per SAP o versione successiva che è possibile usare per distribuire nuove macchine virtuali di Azure. Tenere presente i vari modelli di supporto o di servizio offerti da Red Hat tramite Azure Marketplace quando si sceglie un'immagine della macchina virtuale nel marketplace della macchina virtuale Azure.
Host: aggiornamenti del DNS
Creare un elenco di tutti i nomi host, inclusi i nomi host virtuali e aggiornare i server DNS per abilitare l'indirizzo IP corretto per la risoluzione dei nomi host. Se un server DNS non esiste o non è possibile aggiornare e creare voci DNS, è necessario usare i file host locali delle singole macchine virtuali che partecipano a questo scenario. Se si usano voci di file host, assicurarsi che le voci vengano applicate a tutte le macchine virtuali nell'ambiente del sistema SAP. È tuttavia consigliabile usare il DNS che, idealmente, si estende in Azure
Distribuzione manuale
Assicurarsi che il sistema operativo selezionato sia supportato da IBM/SAP per IBM Db2 LUW. L'elenco delle versioni del sistema operativo supportate per le macchine virtuali di Azure e le versioni di Db2 è disponibile nella nota SAP 1928533. L'elenco delle versioni del sistema operativo in base alla singola versione di Db2 è disponibile nel documento Product Availability Matrix di SAP. È consigliabile usare almeno Red Hat Enterprise Linux 7.4 per SAP a causa di miglioramenti delle prestazioni correlati ad Azure in questa o nelle versioni successive di Red Hat Enterprise Linux.
- Creare o selezionare un gruppo di risorse.
- Creare o selezionare una rete virtuale e una subnet.
- Scegliere un tipo di distribuzione appropriato per le macchine virtuali SAP. In genere, un set di scalabilità di macchine virtuali con orchestrazione flessibile.
- Creare la macchina virtuale 1.
- Usare l'immagine Red Hat Enterprise Linux per SAP in Azure Marketplace.
- Selezionare il set di scalabilità, la zona di disponibilità o il set di disponibilità creato nel passaggio 3.
- Creare la macchina virtuale 2.
- Usare l'immagine Red Hat Enterprise Linux per SAP in Azure Marketplace.
- Selezionare il set di scalabilità, la zona di disponibilità o il set di disponibilità creato nel passaggio 3 (non la stessa zona del passaggio 4).
- Aggiungere i dischi dati alle macchine virtuali e successivamente consultare le raccomandazioni sulla configurazione del file system nell'articolo Distribuzione DBMS per IBM Db2 di macchine virtuali di Azure per un carico di lavoro SAP.
Installare IBM Db2 LUW e l'ambiente SAP
Prima di avviare l'installazione di un ambiente SAP basato su IBM Db2 LUW, vedere la documentazione seguente:
- Documentazione di Azure.
- Documentazione SAP.
- Documentazione IBM.
I collegamenti a questa documentazione sono disponibili nella sezione introduttiva di questo articolo.
Controllare i manuali di installazione SAP sull'installazione di applicazioni basate su NetWeaver in IBM Db2 LUW. È possibile trovare le guide nel portale della guida SAP usando lo strumento di ricerca della guida all'installazione SAP.
È possibile ridurre il numero di guide visualizzate nel portale impostando i filtri seguenti:
- Voglio: installare un nuovo sistema.
- Database personale: IBM Db2 per Linux, Unix e Windows.
- Altri filtri per le versioni di SAP NetWeaver, la configurazione dello stack o il sistema operativo.
Regole del firewall Red Hat
Red Hat Enterprise Linux ha il firewall abilitato per impostazione predefinita.
#Allow access to SWPM tool. Rule is not permanent.
sudo firewall-cmd --add-port=4237/tcp
Hint di installazione per la configurazione di IBM Db2 LUW con HADR
Per configurare l'istanza primaria del database IBM Db2 LUW:
- Usare l'opzione per High availability o Distributed.
- Installare SAP ASCS/ERS e l'istanza di database.
- Eseguire un backup del database appena installato.
Importante
Annotare il valore di "Database Communication port" impostato durante l'installazione. Il numero di porta deve essere lo stesso per entrambe le istanze del database.
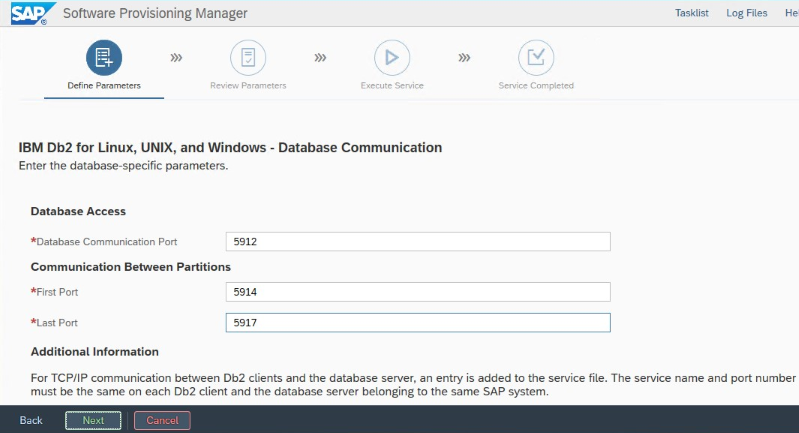
Impostazioni di IBM Db2 HADR per Azure
Quando si usa un agente di isolamento Pacemaker per Azure, impostare i parametri seguenti:
- Durata della finestra HADR peer (secondi) (HADR_PEER_WINDOW) = 240
- Valore di timeout HADR (HADR_TIMEOUT) = 45
È consigliabile usare i parametri precedenti in base ai test iniziali di failover/acquisizione. È obbligatorio verificare che il failover e l'acquisizione funzionino correttamente con queste impostazioni dei parametri. Poiché le singole configurazioni possono variare, i parametri potrebbero richiedere modifiche.
Nota
Specifico per IBM Db2 con configurazione di HADR con avvio normale: l'istanza di database secondaria o standby deve essere attiva e in esecuzione prima di poter avviare l'istanza di database primaria.
Nota
Per l'installazione e la configurazione specifica di Azure e Pacemaker: durante la procedura di installazione tramite SAP Software Provisioning Manager, viene posta una domanda esplicita sulla disponibilità elevata per IBM Db2 LUW:
- Non selezionare IBM Db2 pureScale.
- Non selezionare Install IBM Tivoli System Automation for Multiplatforms.
- Non selezionare Generate cluster configuration files.
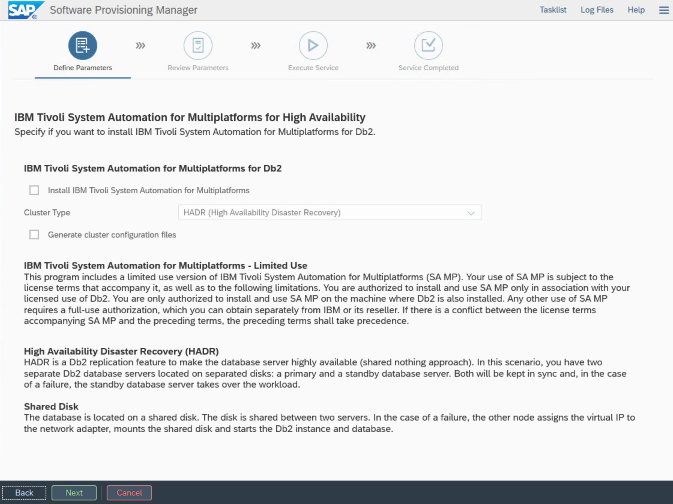
Per configurare il server di database Standby usando la procedura di copia omogenea del sistema SAP, eseguire questi passaggi:
- Selezionare l'opzione System copy >Target systems>Distributed>Database instance.
- Come metodo di copia, selezionare Homogeneous System in modo da poter usare il backup per ripristinare un backup nell'istanza del server di standby.
- Quando si raggiunge il passaggio di uscita per ripristinare il database per la copia di sistema omogenea, uscire dal programma di installazione. Ripristinare il database da un backup dell'host primario. Tutte le fasi di installazione successive sono già state eseguite nel server di database primario.
Regole del firewall Red Hat per DB2 HADR
Aggiungere regole del firewall per consentire il funzionamento del traffico verso DB2 e tra DB2 per HADR:
- Porta di comunicazione del database. Se si usano partizioni, aggiungere anche queste porte.
- Porta HADR (valore del parametro DB2 HADR_LOCAL_SVC).
- Porta probe di Azure.
sudo firewall-cmd --add-port=<port>/tcp --permanent
sudo firewall-cmd --reload
Controllo di HADR IBM Db2
A scopo dimostrativo e per le procedure descritte in questo articolo, il SID del database è ID2.
Dopo aver configurato HADR e quando lo stato è PEER e CONNECTED nei nodi primario e di standby, eseguire il controllo seguente:
Execute command as db2<sid> db2pd -hadr -db <SID>
#Primary output:
Database Member 0 -- Database ID2 -- Active -- Up 1 days 15:45:23 -- Date 2019-06-25-10.55.25.349375
HADR_ROLE = PRIMARY
REPLAY_TYPE = PHYSICAL
HADR_SYNCMODE = NEARSYNC
STANDBY_ID = 1
LOG_STREAM_ID = 0
HADR_STATE = PEER
HADR_FLAGS =
PRIMARY_MEMBER_HOST = az-idb01
PRIMARY_INSTANCE = db2id2
PRIMARY_MEMBER = 0
STANDBY_MEMBER_HOST = az-idb02
STANDBY_INSTANCE = db2id2
STANDBY_MEMBER = 0
HADR_CONNECT_STATUS = CONNECTED
HADR_CONNECT_STATUS_TIME = 06/25/2019 10:55:05.076494 (1561460105)
HEARTBEAT_INTERVAL(seconds) = 7
HEARTBEAT_MISSED = 5
HEARTBEAT_EXPECTED = 52
HADR_TIMEOUT(seconds) = 30
TIME_SINCE_LAST_RECV(seconds) = 5
PEER_WAIT_LIMIT(seconds) = 0
LOG_HADR_WAIT_CUR(seconds) = 0.000
LOG_HADR_WAIT_RECENT_AVG(seconds) = 598.000027
LOG_HADR_WAIT_ACCUMULATED(seconds) = 598.000
LOG_HADR_WAIT_COUNT = 1
SOCK_SEND_BUF_REQUESTED,ACTUAL(bytes) = 0, 46080
SOCK_RECV_BUF_REQUESTED,ACTUAL(bytes) = 0, 369280
PRIMARY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
STANDBY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
HADR_LOG_GAP(bytes) = 132242668
STANDBY_REPLAY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
STANDBY_RECV_REPLAY_GAP(bytes) = 0
PRIMARY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_REPLAY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_RECV_BUF_SIZE(pages) = 2048
STANDBY_RECV_BUF_PERCENT = 0
STANDBY_SPOOL_LIMIT(pages) = 1000
STANDBY_SPOOL_PERCENT = 0
STANDBY_ERROR_TIME = NULL
PEER_WINDOW(seconds) = 300
PEER_WINDOW_END = 06/25/2019 11:12:03.000000 (1561461123)
READS_ON_STANDBY_ENABLED = N
#Secondary output:
Database Member 0 -- Database ID2 -- Standby -- Up 1 days 15:45:18 -- Date 2019-06-25-10.56.19.820474
HADR_ROLE = STANDBY
REPLAY_TYPE = PHYSICAL
HADR_SYNCMODE = NEARSYNC
STANDBY_ID = 0
LOG_STREAM_ID = 0
HADR_STATE = PEER
HADR_FLAGS =
PRIMARY_MEMBER_HOST = az-idb01
PRIMARY_INSTANCE = db2id2
PRIMARY_MEMBER = 0
STANDBY_MEMBER_HOST = az-idb02
STANDBY_INSTANCE = db2id2
STANDBY_MEMBER = 0
HADR_CONNECT_STATUS = CONNECTED
HADR_CONNECT_STATUS_TIME = 06/25/2019 10:55:05.078116 (1561460105)
HEARTBEAT_INTERVAL(seconds) = 7
HEARTBEAT_MISSED = 0
HEARTBEAT_EXPECTED = 10
HADR_TIMEOUT(seconds) = 30
TIME_SINCE_LAST_RECV(seconds) = 1
PEER_WAIT_LIMIT(seconds) = 0
LOG_HADR_WAIT_CUR(seconds) = 0.000
LOG_HADR_WAIT_RECENT_AVG(seconds) = 598.000027
LOG_HADR_WAIT_ACCUMULATED(seconds) = 598.000
LOG_HADR_WAIT_COUNT = 1
SOCK_SEND_BUF_REQUESTED,ACTUAL(bytes) = 0, 46080
SOCK_RECV_BUF_REQUESTED,ACTUAL(bytes) = 0, 367360
PRIMARY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
STANDBY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
HADR_LOG_GAP(bytes) = 0
STANDBY_REPLAY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
STANDBY_RECV_REPLAY_GAP(bytes) = 0
PRIMARY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_REPLAY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_RECV_BUF_SIZE(pages) = 2048
STANDBY_RECV_BUF_PERCENT = 0
STANDBY_SPOOL_LIMIT(pages) = 1000
STANDBY_SPOOL_PERCENT = 0
STANDBY_ERROR_TIME = NULL
PEER_WINDOW(seconds) = 1000
PEER_WINDOW_END = 06/25/2019 11:12:59.000000 (1561461179)
READS_ON_STANDBY_ENABLED = N
Configurare Azure Load Balancer
Durante la configurazione della macchina virtuale, è possibile creare o selezionare il servizio di bilanciamento del carico esistente nella sezione Rete. Seguire questa procedura per configurare il servizio di bilanciamento del carico standard per la configurazione a disponibilità elevata del database DB2.
Seguire la procedura descritta in Creare il servizio di bilanciamento del carico per configurare un servizio di bilanciamento del carico standard per un sistema SAP a disponibilità elevata usando il portale di Azure. Durante la configurazione del servizio di bilanciamento del carico, considerare i punti seguenti:
- Configurazione IP front-end: creare un indirizzo IP front-end. Selezionare la stessa rete virtuale e il nome della subnet delle macchine virtuali di database.
- Pool back-end: creare un pool back-end e aggiungere macchine virtuali di database.
- Regole in ingresso: creare una regola di bilanciamento del carico. Seguire la stessa procedura per entrambe le regole di bilanciamento del carico.
- Indirizzo IP front-end: selezionare un indirizzo IP front-end.
- Pool back-end: selezionare un pool back-end.
- Porte a disponibilità elevata: selezionare questa opzione.
- Protocollo: selezionare TCP.
- Probe di integrità: creare un probe di integrità con i dettagli seguenti:
- Protocollo: selezionare TCP.
- Porta: ad esempio, 625<instance-no.>.
- Intervallo: immettere 5.
- Soglia probe: immettere 2.
- Timeout di inattività (minuti): immettere 30.
- Abilita IP mobile: selezionare questa opzione.
Nota
La proprietà di configurazione del probe di integrità numberOfProbes, altrimenti nota come soglia non integra nel portale, non viene rispettata. Per controllare il numero di probe consecutivi riusciti o non riusciti, impostare la proprietà probeThreshold su 2. Non è attualmente possibile impostare questa proprietà usando il portale di Azure, quindi usare l'interfaccia della riga di comando di Azure o il comando di PowerShell.
Nota
Se vengono inserite macchine virtuali senza indirizzi IP pubblici nel pool back-end di un'istanza di Load Balancer Standard interno ad Azure (nessun indirizzo IP pubblico), non è presente alcuna connettività Internet in uscita, a meno che non venga eseguita un’altra configurazione per consentire il routing a endpoint pubblici. Per maggiori informazioni su come ottenere la connettività in uscita, vedere Connettività degli endpoint pubblici per le macchine virtuali usando Load Balancer Standard di Azure negli scenari a disponibilità elevata SAP.
Importante
Non abilitare i timestamp TCP nelle macchine virtuali di Azure che si trovano dietro Azure Load Balancer. Se si abilitano i timestamp TCP, i probe di integrità potrebbero avere esito negativo. Impostare il parametro net.ipv4.tcp_timestamps su 0. Per altre informazioni, vedere Probe di integrità di Load Balancer.
[A] Aggiungere una regola del firewall per la porta probe:
sudo firewall-cmd --add-port=<probe-port>/tcp --permanent
sudo firewall-cmd --reload
Creare il cluster Pacemaker
Per creare un cluster Pacemaker di base per questo server IBM Db2, vedere Configurazione di Pacemaker su Red Hat Enterprise Linux in Azure.
Configurazione di Db2 Pacemaker
Quando si usa Pacemaker per il failover automatico in caso di errore del nodo, è necessario configurare di conseguenza le istanze di Db2 e Pacemaker. Questa sezione descrive questo tipo di configurazione.
Gli elementi seguenti sono preceduti da uno degli elementi seguenti:
- [A]: applicabile a tutti i nodi
- [1]: applicabile solo al nodo 1
- [1]: applicabile solo al nodo 2
[A] Prerequisito per la configurazione di Pacemaker:
Arrestare entrambi i server di database con l'utente db2<sid> con db2stop.
Modificare l'ambiente della shell per l'utente db2<sid> in /bin/ksh:
# Install korn shell: sudo yum install ksh # Change users shell: sudo usermod -s /bin/ksh db2<sid>
Configurazione di Pacemaker
[1] Configurazione di Pacemaker specifica per IBM Db2 HADR:
# Put Pacemaker into maintenance mode sudo pcs property set maintenance-mode=true[1] Creare risorse IBM Db2:
Se si compila un cluster in RHEL 7.x, assicurarsi di aggiornare il pacchetto di agenti di risorse alla versione
resource-agents-4.1.1-61.el7_9.15o versione successiva. Usare i comandi seguenti per creare le risorse del cluster:# Replace bold strings with your instance name db2sid, database SID, and virtual IP address/Azure Load Balancer. sudo pcs resource create Db2_HADR_ID2 db2 instance='db2id2' dblist='ID2' master meta notify=true resource-stickiness=5000 #Configure resource stickiness and correct cluster notifications for master resource sudo pcs resource update Db2_HADR_ID2-master meta notify=true resource-stickiness=5000 # Configure virtual IP - same as Azure Load Balancer IP sudo pcs resource create vip_db2id2_ID2 IPaddr2 ip='10.100.0.40' # Configure probe port for Azure load Balancer sudo pcs resource create nc_db2id2_ID2 azure-lb port=62500 #Create a group for ip and Azure loadbalancer probe port sudo pcs resource group add g_ipnc_db2id2_ID2 vip_db2id2_ID2 nc_db2id2_ID2 #Create colocation constrain - keep Db2 HADR Master and Group on same node sudo pcs constraint colocation add g_ipnc_db2id2_ID2 with master Db2_HADR_ID2-master #Create start order constrain sudo pcs constraint order promote Db2_HADR_ID2-master then g_ipnc_db2id2_ID2Se si compila un cluster in RHEL 8.x, assicurarsi di aggiornare il pacchetto di agenti di risorse alla versione
resource-agents-4.1.1-93.el8o versione successiva. Per informazioni dettagliate, vedere Red Hat KBAdb2risorsa con HADR non viene promosso con statoPRIMARY/REMOTE_CATCHUP_PENDING/CONNECTED. Usare i comandi seguenti per creare le risorse del cluster:# Replace bold strings with your instance name db2sid, database SID, and virtual IP address/Azure Load Balancer. sudo pcs resource create Db2_HADR_ID2 db2 instance='db2id2' dblist='ID2' promotable meta notify=true resource-stickiness=5000 #Configure resource stickiness and correct cluster notifications for master resource sudo pcs resource update Db2_HADR_ID2-clone meta notify=true resource-stickiness=5000 # Configure virtual IP - same as Azure Load Balancer IP sudo pcs resource create vip_db2id2_ID2 IPaddr2 ip='10.100.0.40' # Configure probe port for Azure load Balancer sudo pcs resource create nc_db2id2_ID2 azure-lb port=62500 #Create a group for ip and Azure loadbalancer probe port sudo pcs resource group add g_ipnc_db2id2_ID2 vip_db2id2_ID2 nc_db2id2_ID2 #Create colocation constrain - keep Db2 HADR Master and Group on same node sudo pcs constraint colocation add g_ipnc_db2id2_ID2 with master Db2_HADR_ID2-clone #Create start order constrain sudo pcs constraint order promote Db2_HADR_ID2-clone then g_ipnc_db2id2_ID2[1] Avviare le risorse IBM Db2:
Mettere Pacemaker in modalità Fuori manutenzione.
# Put Pacemaker out of maintenance-mode - that start IBM Db2 sudo pcs property set maintenance-mode=false[1] Assicurarsi che lo stato del cluster sia corretto e che tutte le risorse siano avviate. Non è importante il nodo su cui sono in esecuzione le risorse.
sudo pcs status 2 nodes configured 5 resources configured Online: [ az-idb01 az-idb02 ] Full list of resources: rsc_st_azure (stonith:fence_azure_arm): Started az-idb01 Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2] Masters: [ az-idb01 ] Slaves: [ az-idb02 ] Resource Group: g_ipnc_db2id2_ID2 vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb01 nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb01 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
Importante
È necessario gestire l'istanza Db2 di Pacemaker in cluster usando gli strumenti di Pacemaker. Se si usano comandi db2, ad esempio db2stop, Pacemaker rileva l'azione come errore della risorsa. Se si esegue la manutenzione, è possibile inserire i nodi o le risorse in modalità di manutenzione. Pacemaker sospende le risorse di monitoraggio ed è quindi possibile usare i normali comandi di amministrazione db2.
Apportare modifiche ai profili SAP per usare l'indirizzo IP virtuale per la connessione
Per connettersi all'istanza primaria della configurazione HADR, il livello dell'applicazione SAP deve usare l'indirizzo IP virtuale definito e configurato per Azure Load Balancer. Sono necessarie le modifiche seguenti:
/sapmnt/<SID>/profile/DEFAULT.PFL
SAPDBHOST = db-virt-hostname
j2ee/dbhost = db-virt-hostname
/sapmnt/<SID>/global/db6/db2cli.ini
Hostname=db-virt-hostname
Installare i server applicazioni primari e con finestre di dialogo
Quando si installano server applicazioni primari e con finestre di dialogo in una configurazione Db2 HADR, usare il nome host virtuale scelto per la configurazione.
Se l'installazione è stata eseguita prima di creare la configurazione Db2 HADR, apportare le modifiche come descritto nella sezione precedente e come indicato di seguito per gli stack Java di SAP.
Controllo dell'URL JDBC per i sistemi stack ABAP+Java o Java
Usare lo strumento di configurazione J2EE per controllare o aggiornare l'URL JDBC. Poiché lo strumento di configurazione J2EE è uno strumento grafico, è necessario che sia installato il server X:
Accedere al server applicazioni primario dell'istanza di J2EE ed eseguire:
sudo /usr/sap/*SID*/*Instance*/j2ee/configtool/configtool.shNel riquadro sinistro scegliere archivio di sicurezza.
Nella cornice destra scegliere il tasto
jdbc/pool/\<SAPSID>/url.Modificare il nome host nell'URL JDBC impostando il nome host virtuale.
jdbc:db2://db-virt-hostname:5912/TSP:deferPrepares=0Selezionare Aggiungi.
Per salvare le modifiche, selezionare l'icona del disco in alto a sinistra.
Chiudere lo strumento di configurazione.
Riavviare l'istanza di Java.
Configurare l'archiviazione dei log per la configurazione di HADR
Per configurare l'archiviazione dei log Db2 per la configurazione di HADR, è consigliabile configurare sia il database primario che il database di standby in modo che dispongano della funzionalità di recupero automatico dei log da tutte le posizioni di archiviazione dei log. Sia il database primario che quello di standby devono essere in grado di recuperare i file di archivio dei log da tutte le posizioni di archiviazione dei log in cui una delle istanze di database potrebbe archiviare i file di log.
L'archiviazione dei log viene eseguita solo dal database primario. Se si modificano i ruoli HADR dei server di database o se si verifica un errore, il nuovo database primario è responsabile dell'archiviazione dei log. Se sono state configurate più posizioni di archiviazione dei log, i log potrebbero essere archiviati due volte. In caso di recupero locale o remoto, potrebbe anche essere necessario copiare manualmente i log archiviati dal server primario precedente nel percorso del log attivo del nuovo server primario.
È consigliabile configurare una condivisione NFS comune o GlusterFS, in cui i log vengono scritti da entrambi i nodi. La condivisione NFS o GlusterFS deve essere a disponibilità elevata.
È possibile usare le condivisioni NFS a disponibilità elevata o GlusterFS esistenti per i trasporti o per una directory del profilo. Per altre informazioni, vedi:
- GlusterFS in macchine virtuali di Azure in Red Hat Enterprise Linux per SAP NetWeaver.
- Disponibilità elevata per SAP NetWeaver su macchine virtuali di Azure su Red Hat Enterprise Linux con Azure NetApp Files per applicazioni SAP.
- Azure NetApp Files (per creare condivisioni NFS).
Testare la configurazione del cluster
Questa sezione descrive come testare la configurazione Db2 HADR. Ogni test presuppone che IBM Db2 primario sia in esecuzione nella macchina virtuale az-idb01. È necessario usare un utente con privilegi sudo o root (non consigliato).
Lo stato iniziale per tutti i test case è illustrato qui: (crm_mon -r o stato pcs)
- stato pcs è uno snapshot dello stato di Pacemaker in fase di esecuzione.
- crm_mon -r è l'output continuo dello stato di Pacemaker.
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb01
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb01 ]
Slaves: [ az-idb02 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb01
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb01
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
Lo stato originale in un sistema SAP è documentato in Transaction DBACOCKPIT > Configuration > Overview, come illustrato nell'immagine seguente:
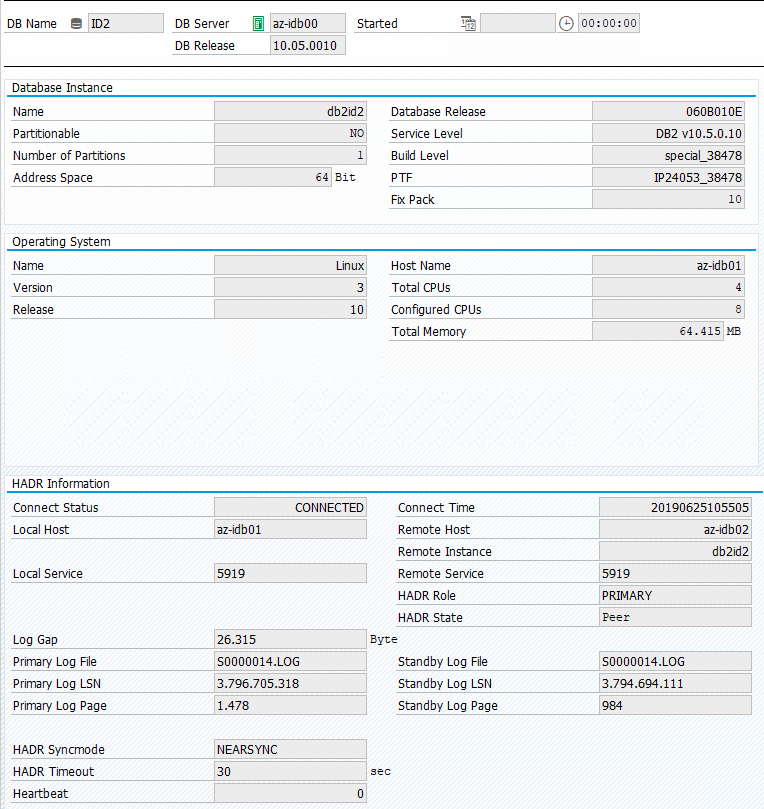
Acquisizione di test di IBM Db2
Importante
Prima di avviare il test, assicurarsi che:
In Pacemaker non ci siano azioni non riuscite (stato pcs).
Non esistano vincoli di posizione (residui del test di migrazione).
La sincronizzazione di IBM Db2 HADR funzioni. Verificare con l'utente db2<sid>.
db2pd -hadr -db <DBSID>
Eseguire la migrazione del nodo che esegue il database Db2 primario eseguendo il comando seguente:
# On RHEL 7.x
sudo pcs resource move Db2_HADR_ID2-master
# On RHEL 8.x
sudo pcs resource move Db2_HADR_ID2-clone --master
Al termine della migrazione, l'output di crm status è simile al seguente:
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb01
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
Lo stato originale in un sistema SAP è documentato in Transaction DBACOCKPIT > Configuration > Overview, come illustrato nell'immagine seguente:
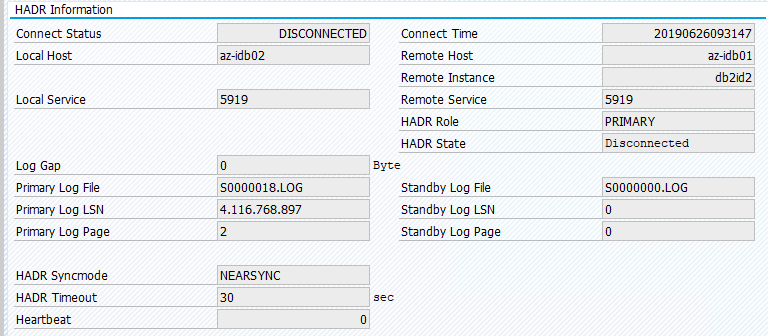
La migrazione delle risorse con "pcs resource move" crea vincoli di posizione. In questo caso, i vincoli di posizione impediscono l'esecuzione dell'istanza IBM Db2 in az-idb01. Se i vincoli di posizione non vengono eliminati, la risorsa non può eseguire il failback.
Se si rimuove il vincolo di posizione, il nodo standby verrà avviato in az-idb01.
# On RHEL 7.x
sudo pcs resource clear Db2_HADR_ID2-master
# On RHEL 8.x
sudo pcs resource clear Db2_HADR_ID2-clone
E lo stato del cluster cambia in:
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb01
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Slaves: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
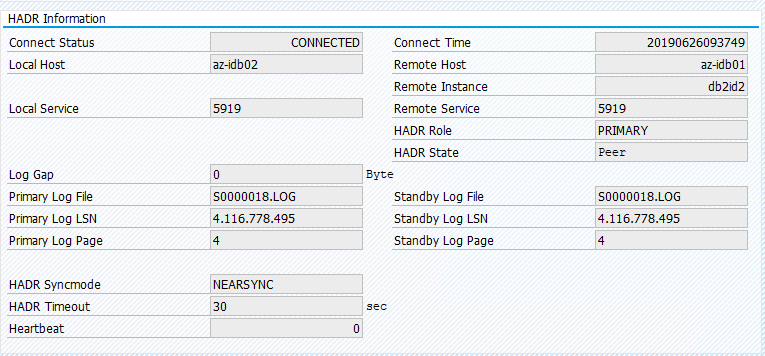
Eseguire di nuovo la migrazione della risorsa in az-idb01 e cancellare i vincoli di posizione
# On RHEL 7.x
sudo pcs resource move Db2_HADR_ID2-master az-idb01
sudo pcs resource clear Db2_HADR_ID2-master
# On RHEL 8.x
sudo pcs resource move Db2_HADR_ID2-clone --master
sudo pcs resource clear Db2_HADR_ID2-clone
- In RHEL 7.x -
pcs resource move <resource_name> <host>: crea vincoli di posizione e può causare problemi con l'acquisizione - In RHEL 8.x -
pcs resource move <resource_name> --master: crea vincoli di posizione e può causare problemi con l'acquisizione pcs resource clear <resource_name>: cancella i vincoli delle localitàpcs resource cleanup <resource_name>: cancella tutti gli errori della risorsa
Testare un'acquisizione manuale
È possibile testare un'acquisizione manuale arrestando il servizio Pacemaker nel nodo az-idb01:
systemctl stop pacemaker
stato in az-ibdb02
2 nodes configured
5 resources configured
Node az-idb01: pending
Online: [ az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
Dopo il failover, è possibile avviare nuovamente il servizio in az-idb01.
systemctl start pacemaker
Terminare il processo Db2 nel nodo che esegue il database primario HADR
#Kill main db2 process - db2sysc
[sapadmin@az-idb02 ~]$ sudo ps -ef|grep db2sysc
db2ptr 34598 34596 8 14:21 ? 00:00:07 db2sysc 0
[sapadmin@az-idb02 ~]$ sudo kill -9 34598
L'istanza Db2 ha esito negativo e Pacemaker sposterà il nodo master e segnalerà lo stato seguente:
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
Failed Actions:
* Db2_HADR_ID2_demote_0 on az-idb01 'unknown error' (1): call=49, status=complete, exitreason='none',
last-rc-change='Wed Jun 26 09:57:35 2019', queued=0ms, exec=362ms
Pacemaker riavvia l'istanza di database primaria Db2 nello stesso nodo oppure esegue il failover nel nodo che esegue l'istanza di database secondaria e viene segnalato un errore.
Terminare il processo Db2 nel nodo che esegue l'istanza di database secondaria
[sapadmin@az-idb02 ~]$ sudo ps -ef|grep db2sysc
db2id2 23144 23142 2 09:53 ? 00:00:13 db2sysc 0
[sapadmin@az-idb02 ~]$ sudo kill -9 23144
Il nodo si trova in uno stato di operazione non riuscita e viene segnalato un errore.
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb01 ]
Slaves: [ az-idb02 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb01
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb01
Failed Actions:
* Db2_HADR_ID2_monitor_20000 on az-idb02 'not running' (7): call=144, status=complete, exitreason='none',
last-rc-change='Wed Jun 26 10:02:09 2019', queued=0ms, exec=0ms
L'istanza Db2 viene riavviata nel ruolo secondario assegnato in precedenza.
Arrestare il database tramite db2stop force sul nodo che esegue l'istanza di database primario HADR
Come utente db2<sid> eseguire il comando db2stop force:
az-idb01:db2ptr> db2stop force
Errore rilevato:
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Slaves: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Stopped
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Stopped
Failed Actions:
* Db2_HADR_ID2_demote_0 on az-idb01 'unknown error' (1): call=110, status=complete, exitreason='none',
last-rc-change='Wed Jun 26 14:03:12 2019', queued=0ms, exec=355ms
L'istanza di database secondaria Db2 HADR è stata alzata di livello nel ruolo primario.
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Slaves: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
Failed Actions:
* Db2_HADR_ID2_demote_0 on az-idb01 'unknown error' (1): call=110, status=complete, exitreason='none',
last-rc-change='Wed Jun 26 14:03:12 2019', queued=0ms, exec=355ms
Arrestare in modo anomalo la macchina virtuale che esegue l'istanza di database primaria HADR con "halt"
#Linux kernel panic.
sudo echo b > /proc/sysrq-trigger
In questo caso Pacemaker rileva che il nodo che esegue l'istanza di database primaria non risponde.
2 nodes configured
5 resources configured
Node az-idb01: UNCLEAN (online)
Online: [ az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb01 ]
Slaves: [ az-idb02 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb01
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb01
Il passaggio successivo consiste nel verificare la presenza di una situazione Split brain. Dopo che il nodo integro ha determinato che il nodo che ha eseguito per ultimo l'istanza di database primaria è inattivo, viene eseguito un failover delle risorse.
2 nodes configured
5 resources configured
Online: [ az-idb02 ]
OFFLINE: [ az-idb01 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
In caso di Kernel panic, il nodo guasto verrà riavviato dall'agente di isolamento. Dopo che il nodo non riuscito è di nuovo online, è necessario avviare il cluster pacemaker tramite
sudo pcs cluster start
avvia l'istanza Db2 nel ruolo secondario.
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Slaves: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02