Guida introduttiva: Creare un set di competenze nel portale di Azure
In questa guida introduttiva si apprenderà come un set di competenze in Ricerca di intelligenza artificiale di Azure aggiunge il riconoscimento ottico dei caratteri (OCR), l'analisi delle immagini, il rilevamento della lingua, la traduzione testuale e il riconoscimento delle entità per generare contenuto ricercabile in un indice di ricerca.
È possibile eseguire la procedura guidata Importa dati nel portale di Azure, per applicare competenze che creano e trasformano il contenuto testuale durante l'indicizzazione. L'input è costituito dai dati non elaborati, in genere BLOB in Archiviazione di Azure. L'output è un indice ricercabile contenente testo, didascalie ed entità generate dall'intelligenza artificiale. Il contenuto generato è queryabile nella portale di Azure usando Esplora ricerche.
Per prepararsi, è necessario creare alcune risorse e caricare file di esempio prima di eseguire la procedura guidata.
Prerequisiti
Un account Azure con una sottoscrizione attiva. Creare un account gratuitamente.
Creare un servizio di ricerca di intelligenza artificiale di Azure o trovare un servizio esistente. È possibile usare un servizio gratuito per questo avvio rapido.
Un account Archiviazione di Azure con Archiviazione BLOB di Azure.
Nota
Questa guida introduttiva usa i Servizi di Azure AI per le trasformazioni di intelligenza artificiale. Poiché il carico di lavoro è molto ridotto, Servizi di Azure AI lavora dietro le quinte per offrire un'elaborazione gratuita per un massimo di 20 transazioni. È possibile completare questo esercizio senza dover creare una risorsa multiservizio di Azure per intelligenza artificiale.
Configurare i dati
Nei passaggi seguenti si configura un contenitore BLOB in Archiviazione di Azure in cui archiviare file di contenuto eterogenei.
Scaricare i dati di esempio costituiti da un piccolo set di file di tipi diversi.
Accedere al portale di Azure con il proprio account Azure.
Creare un account di Archiviazione di Azure o trovare un account esistente.
Per evitare addebiti dovuti alla larghezza di banda, scegliere la stessa area di Azure AI Search.
Scegliere Archiviazione V2 (utilizzo generico V2).
Nel portale di Azure, aprire la pagina Archiviazione di Azure e creare un contenitore. È possibile usare il livello di accesso predefinito.
In Contenitore, selezionare Carica per caricare i file di esempio. Si noti che è disponibile un'ampia gamma di tipi di contenuto, tra cui immagini e file di applicazioni che non sono disponibili per la ricerca full-text nei formati nativi.
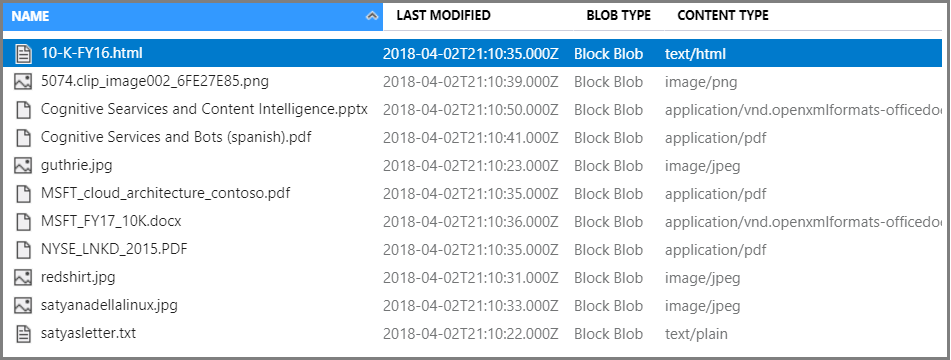
A questo punto, è possibile procedere con la procedura guidata Importa dati.
Eseguire la procedura guidata Importa dati
Accedere al portale di Azure con il proprio account Azure.
Trovare il servizio di ricerca. Nella pagina Panoramica selezionare Importa dati sulla barra dei comandi per creare contenuto ricercabile in quattro passaggi.
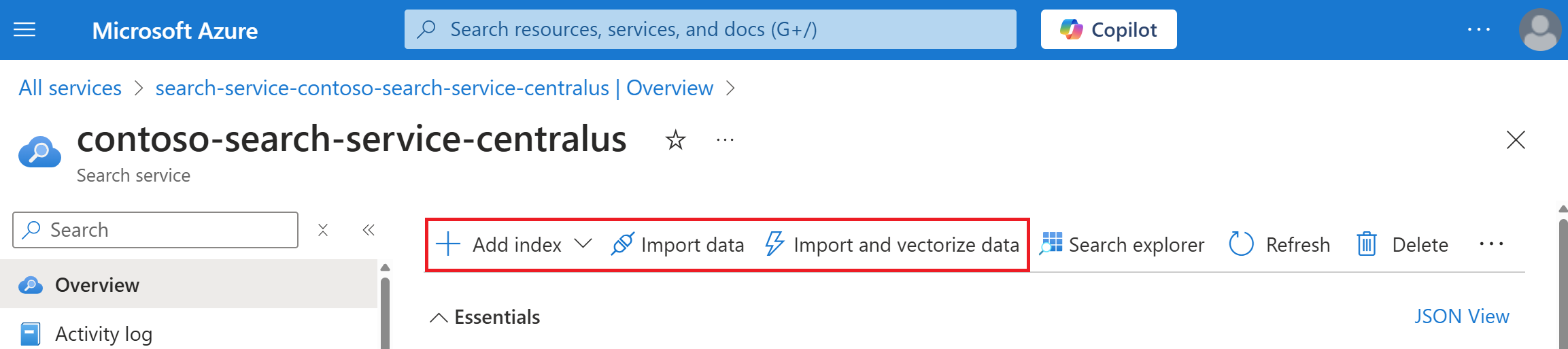
Passaggio 1: Creare un'origine dati
In Connetti ai dati, scegliere Archiviazione BLOB di Azure.
Scegliere una connessione esistente all'account di archiviazione e selezionare il contenitore creato. Assegnare un nome origine dati e utilizzare i valori predefiniti per il resto.
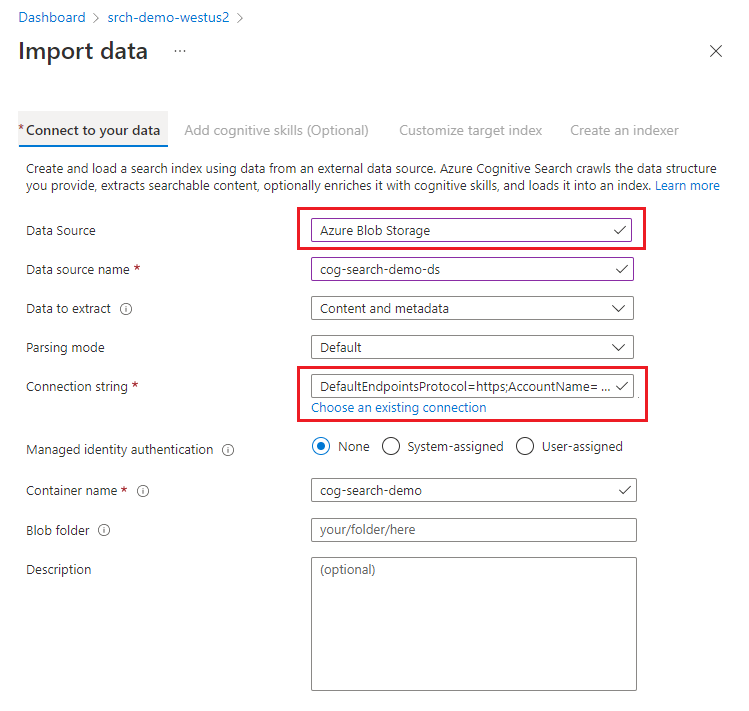
Passare alla pagina successiva.
Se viene visualizzato Errore durante il rilevamento dello schema dell'indice dall'origine dati, l'indicizzatore che supporta la procedura guidata non può connettersi all'origine dati. Molto probabilmente, l'origine dati dispone di protezioni per la sicurezza. Provare le soluzioni seguenti e quindi eseguire di nuovo la procedura guidata.
| Funzionalità di sicurezza | Soluzione |
|---|---|
| La risorsa richiede ruoli di Azure o le relative chiavi di accesso sono disabilitate | Connettersi come servizio attendibile o connettersi usando un'identità gestita |
| La risorsa si trova dietro un firewall IP | Creare una regola in ingresso per La ricerca e per l'portale di Azure |
| La risorsa richiede una connessione endpoint privato | Connettersi tramite un endpoint privato |
Passaggio 2: Aggiungere competenze cognitive
Configurare quindi l'arricchimento tramite intelligenza artificiale per richiamare OCR, l'analisi delle immagini e l'elaborazione del linguaggio naturale.
L'analisi di immagini e OCR sono disponibili per i BLOB in Archiviazione BLOB di Azure e Azure Data Lake Storage (ADLS) Gen2 e per il contenuto delle immagini in OneLake. Le immagini possono essere file autonomi o immagini incorporate in un PDF o in altri file.
Per questa guida introduttiva si usa la risorsa Gratuita dei Servizi di Azure AI. I dati di esempio sono costituiti da 14 file, quindi l'allocazione gratuita di 20 transazioni nei servizi di intelligenza artificiale di Azure è sufficiente per questa guida introduttiva.
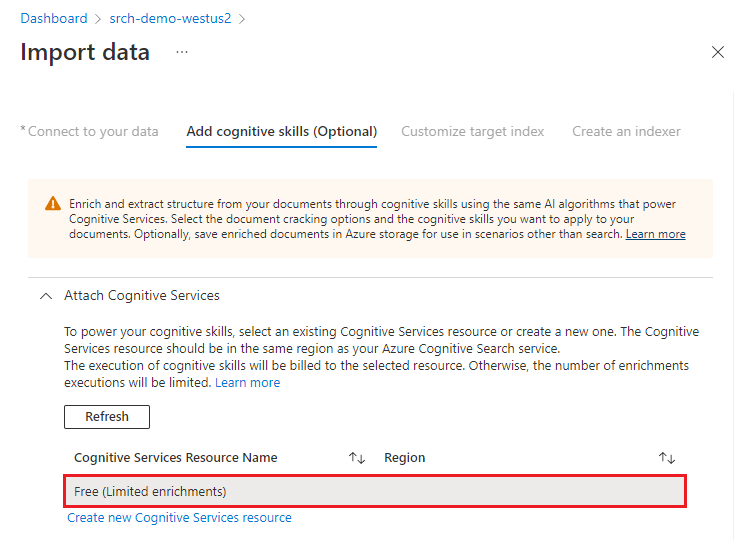
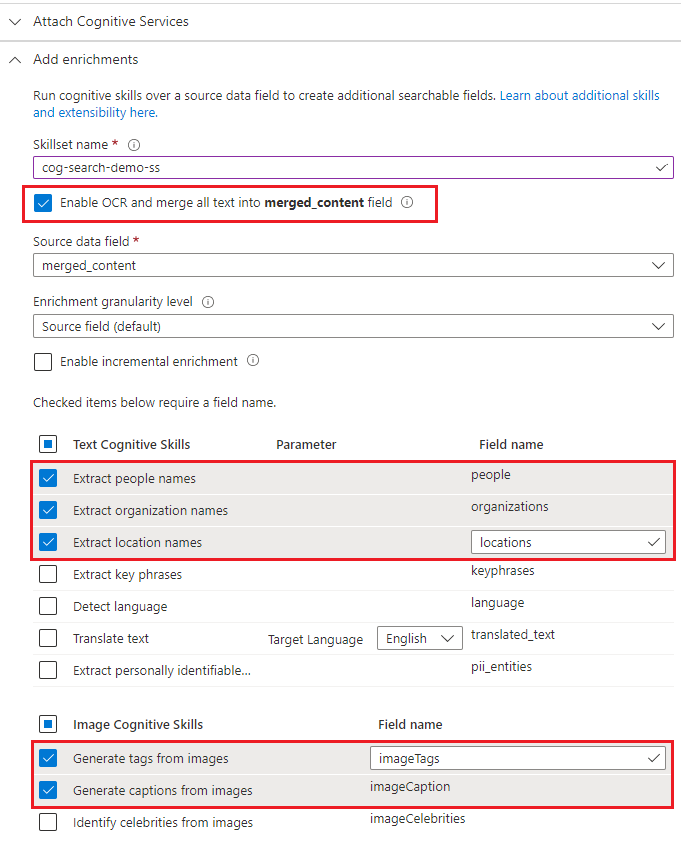
Espandere Aggiungi arricchimenti ed effettuare sei selezioni.
Abilitare OCR per aggiungere le competenze di analisi delle immagini alla pagina della procedura guidata.
Scegliere le competenze di riconoscimento entità (persone, organizzazioni e località) e di analisi delle immagini (tag, didascalie).
Passare alla pagina successiva.
Passaggio 3: Configurare l'indice
Un indice contiene il contenuto ricercabile e la procedura guidata Importa dati può in genere creare lo schema automaticamente eseguendo il campionamento dell'origine dati. In questo passaggio occorre esaminare lo schema generato e potenzialmente rivedere le impostazioni.
Per questa Guida introduttiva, la procedura guidata ha imposta valori predefiniti ragionevoli in modo efficace:
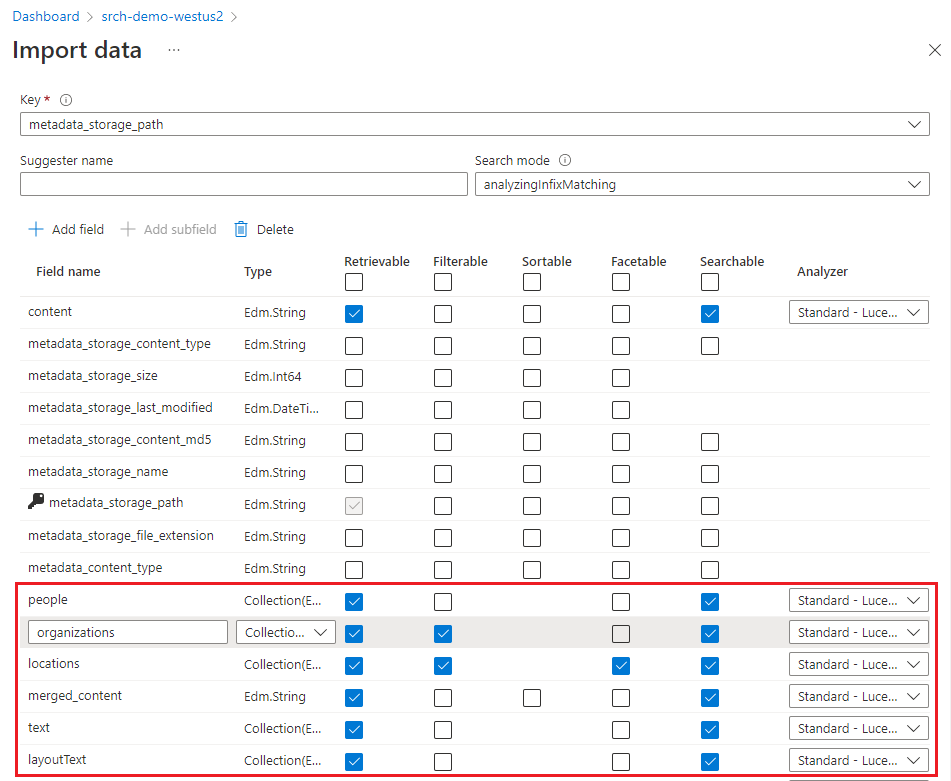
I campi predefiniti sono basati sulle proprietà dei metadati dei BLOB esistenti, oltre ai nuovi campi per l'output di arricchimento (ad esempio,
people,organizations,locations). I tipi di dati vengono dedotti dai metadati e mediante il campionamento dei dati.La chiave di documento predefinita è metadata_storage_path (selezionata perché il campo contiene valori univoci).
Gli attributi predefiniti sono Recuperabile e Ricercabile. L'attributo Ricercabile indica che è possibile eseguire ricerche full-text in un campo. L'attributo Recuperabile indica che i valori dei campi possono essere restituiti nei risultati. La procedura guidata presuppone che si voglia rendere questi campi recuperabili e ricercabili perché sono stati creati con un insieme di competenze. Selezionare Filtrabile, se si desidera utilizzare i campi in un'espressione filtro.
Contrassegnare un campo come Recuperabile non significa che il campo debba essere presente nei risultati della ricerca. È possibile controllare la composizione dei risultati della ricerca usando il parametro di query select per specificare i campi da includere.
Passare alla pagina successiva.
Passaggio 4: Configurare l'indicizzatore
L'indicizzatore guida il processo di indicizzazione. Specifica il nome dell'origine dati, l'indice di destinazione e la frequenza di esecuzione. La procedura guidata Importa dati crea diversi oggetti, incluso un indicizzatore che è possibile reimpostare ed eseguire ripetutamente.
Nella pagina Indicizzatore, accettare il nome predefinito e selezionare Una volta.
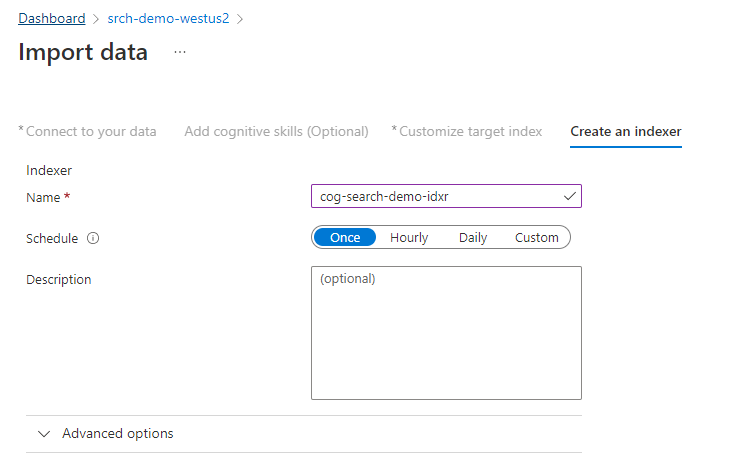
Selezionare Invia per creare e contemporaneamente eseguire l'indicizzatore.
Monitorare lo stato
Selezionare Indicizzatori nel riquadro di spostamento sinistro, per monitorare lo stato e quindi selezionare l'indicizzatore. L'indicizzazione basata sulle competenze richiede più tempo dell'indicizzazione basata su testo, in particolare OCR e analisi delle immagini.
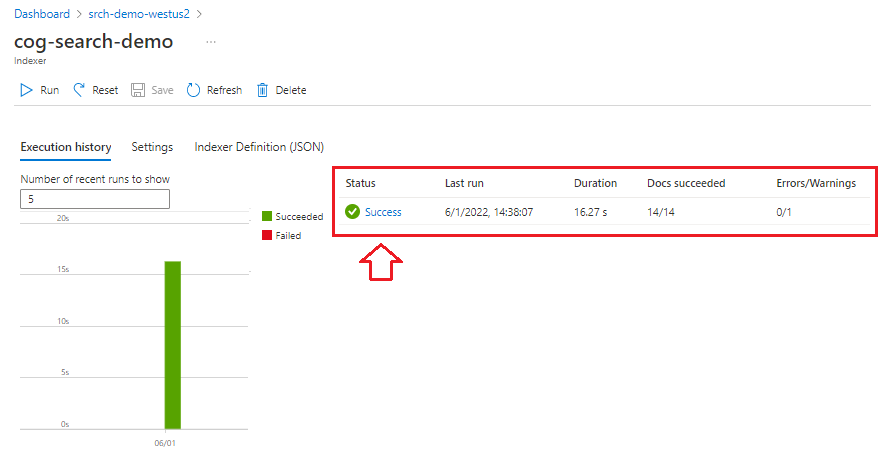
Per visualizzare i dettagli sullo stato di esecuzione, selezionare Operazione riuscita (o Operazione non riuscita) per visualizzare i dettagli dell'esecuzione.
In questa demo sono presenti alcuni avvisi: "Impossibile eseguire la competenza perché uno o più input della competenza non sono validi". Indica che un file PNG nell'origine dati non fornisce un input di testo a Riconoscimento entità. Questo avviso si verifica perché la competenza OCR upstream non riconosce alcun testo nell'immagine e pertanto non è riuscito a fornire un input di testo alla competenza riconoscimento entità downstream.
Gli avvisi sono comuni nell'esecuzione del set di competenze. Man mano che si ha familiarità con l'iterazione delle competenze sui dati, è possibile iniziare a notare i modelli e apprendere quali avvisi sono sicuri da ignorare.
Eseguire query in Esplora ricerche
Dopo aver creato un indice, usare Esplora ricerche per restituire i risultati.
A sinistra, selezionare Indici e poi l'indice. Esplora ricerche è la prima scheda.
Immettere una stringa di ricerca per una query nell'indice, ad esempio
satya nadella. La barra di ricerca accetta parole chiave, frasi racchiuse tra virgolette e operatori:"Satya Nadella" +"Bill Gates" +"Steve Ballmer"
I risultati vengono restituiti come JSON dettagliato, che può essere difficile da leggere, soprattutto in documenti di grandi dimensioni. Alcuni suggerimenti per la ricerca in questo strumento includono le tecniche seguenti:
Passare alla visualizzazione JSON per specificare i parametri risultanti dalla forma.
Aggiungere
selectper limitare i campi nei risultati.Aggiungi
countper visualizzare il numero di corrispondenze.Usare CTRL+F per cercare proprietà o termini specifici nel codice JSON.
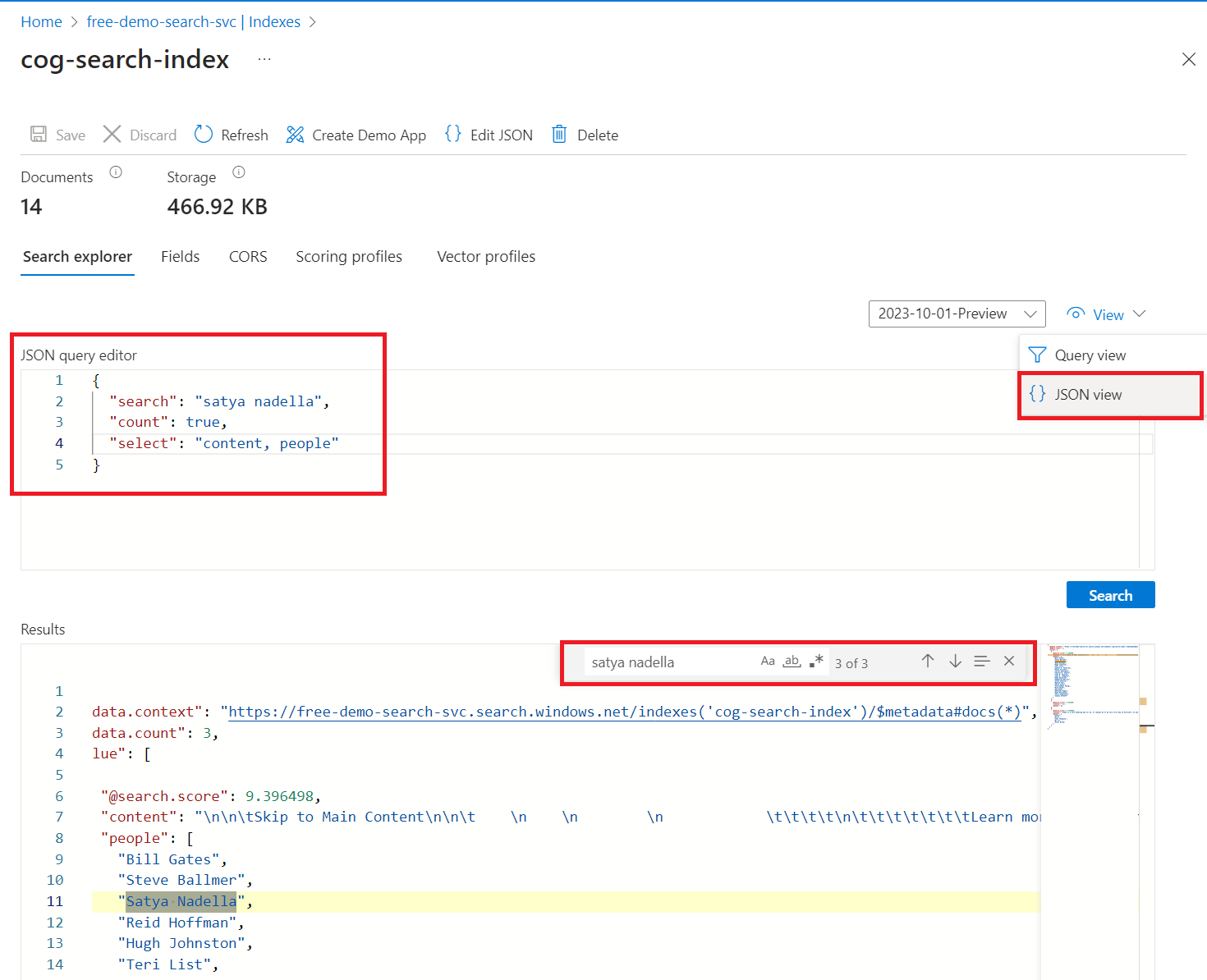
Ecco alcuni JSON che è possibile incollare nella visualizzazione:
{
"search": "\"Satya Nadella\" +\"Bill Gates\" +\"Steve Ballmer\"",
"count": true,
"select": "content, people"
}
Suggerimento
Le stringhe di query fanno distinzione tra maiuscole e minuscole. Se quindi viene visualizzato un messaggio di campo sconosciuto, controllare Campi o Definizione di indice (JSON) per verificare il nome e l'uso delle maiuscole/minuscole.
Risultati
È stato creato il primo set di competenze e sono stati appresi i passaggi di base dell'indicizzazione basata sulle competenze.
Alcuni concetti chiave che ci auguriamo siano stati raccolti includono le dipendenze. Un set di competenze è associato a un indicizzatore e gli indicizzatori sono specifici di Azure e dell'origine. Anche se in questa Guida introduttiva viene usato Archiviazione BLOB di Azure, sono possibili altre origini dati di Azure. Per altre informazioni, vedere Indicizzatori in Azure AI Search.
Un altro concetto importante è che le competenze operano sui tipi di contenuto e quando si lavora con contenuto eterogeneo, alcuni input vengono ignorati. File o campi di grandi dimensioni potrebbero inoltre superare i limiti dell'indicizzatore del livello di servizio. È quindi normale che vengano visualizzati avvisi quando si verificano questi eventi.
L'output viene indirizzato a un indice di ricerca ed esiste un mapping tra le coppie nome-valore create durante l'indicizzazione e i singoli campi dell'indice. Internamente, la procedura guidata configura un albero di arricchimento e definisce un set di competenze, stabilendo l'ordine delle operazioni e il flusso generale. Questi passaggi sono nascosti nella procedura guidata, ma quando si avvia la scrittura di codice, questi concetti diventano importanti.
Infine, si è appreso che è possibile verificare il contenuto eseguendo una query sull'indice. Infine, Azure AI Search offre un indice ricercabile, in cui è possibile eseguire una query utilizzando la sintassi di query semplice oppure completamente estesa. Un indice che contiene campi arricchiti è come qualsiasi altro. È possibile incorporare analizzatori standard o personalizzati, profili di punteggio, sinonimi, navigazione in base a facet, ricerca geografica o qualsiasi altra funzionalità di Ricerca di intelligenza artificiale di Azure.
Pulire le risorse
Quando si lavora nella propria sottoscrizione, al termine di un progetto è buona norma determinare se le risorse create sono ancora necessarie. Le risorse che rimangono in esecuzione hanno un costo. È possibile eliminare risorse singole oppure gruppi di risorse per eliminare l'intero set di risorse.
È possibile trovare e gestire le risorse nella portale di Azure, usando il collegamento Tutte le risorse o Gruppi di risorse nel riquadro di spostamento a sinistra.
Se si è usato un servizio gratuito, tenere presente che il numero di indicizzatori e origini dati è limitato a tre. È possibile eliminare singoli elementi nel portale di Azure per rimanere al di sotto del limite.
Passaggio successivo
È possibile creare set di competenze usando l'API REST portale di Azure, .NET SDK o . Per altre informazioni, provare l'API REST usando un client REST e altri dati di esempio.