Scegliere un linguaggio di programmazione per il passaggio successivo. Le librerie client Azure.Search.Documents sono disponibili negli SDK di Azure per .NET, Python, Java e JavaScript/Typescript.
Compilare un'applicazione console usando la libreria client Azure.Search.Documents per creare, caricare ed eseguire query su un indice di ricerca.
In alternativa è possibile scaricare il codice sorgente per iniziare con un progetto finito oppure seguire questi passaggi per crearne uno.
Configurazione dell'ambiente
Avviare Visual Studio e creare un nuovo progetto per un'app console.
In Strumenti>Gestione pacchetti NuGet, selezionare Gestisci pacchetti NuGet per la soluzione.
Selezionare Sfoglia.
Cercare il pacchetto Azure.Search.Documents e selezionare la versione 11.0 o successiva.
Selezionare Installa per aggiungere l'assembly al progetto e alla soluzione.
Creare un client di ricerca
In Program.cs modificare lo spazio dei nomi in AzureSearch.SDK.Quickstart.v11 e quindi aggiungere le direttive using seguenti.
using Azure;
using Azure.Search.Documents;
using Azure.Search.Documents.Indexes;
using Azure.Search.Documents.Indexes.Models;
using Azure.Search.Documents.Models;
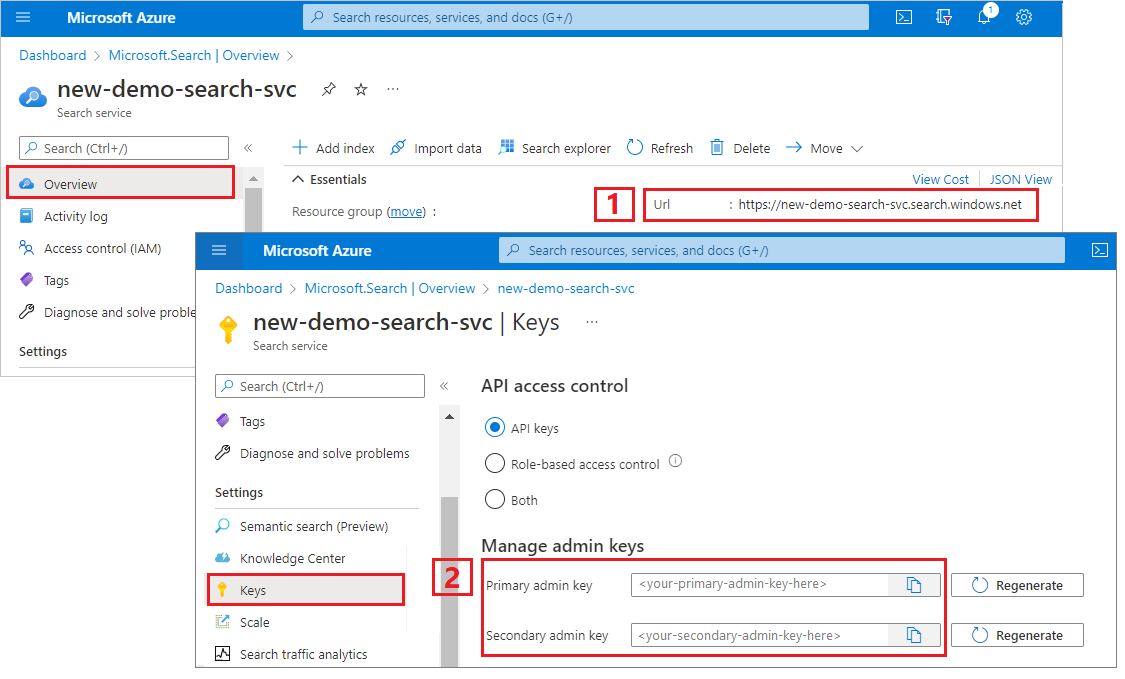
Copiare il codice seguente per creare due client. SearchIndexClient crea l'indice, mentre SearchClient carica un indice esistente ed esegue query su di esso. Per entrambi è necessario l'endpoint di servizio e una chiave API amministratore per l'autenticazione con diritti di creazione/eliminazione.
Poiché il codice compila automaticamente l'URI, specificare solo il nome del servizio di ricerca nella serviceName proprietà .
static void Main(string[] args)
{
string serviceName = "<your-search-service-name>";
string apiKey = "<your-search-service-admin-api-key>";
string indexName = "hotels-quickstart";
// Create a SearchIndexClient to send create/delete index commands
Uri serviceEndpoint = new Uri($"https://{serviceName}.search.windows.net/");
AzureKeyCredential credential = new AzureKeyCredential(apiKey);
SearchIndexClient adminClient = new SearchIndexClient(serviceEndpoint, credential);
// Create a SearchClient to load and query documents
SearchClient srchclient = new SearchClient(serviceEndpoint, indexName, credential);
. . .
}
Creare un indice
Questa guida di avvio rapido compila un indice di hotel in cui si caricheranno i dati relativi agli hotel su cui si eseguiranno query. In questo passaggio definire i campi dell'indice. Ogni definizione di campo include un nome, un tipo di dati e gli attributi che determinano come viene usato il campo.
In questo esempio, i metodi sincroni della libreria Azure.Search.Documents vengono usati per semplicità e leggibilità. Per scenari di produzione, tuttavia, è consigliabile usare metodi asincroni per mantenere la scalabilità e la reattività dell'app. Ad esempio, usare CreateIndexAsync invece di CreateIndex.
Aggiungere una definizione di classe vuota al progetto: Hotel.cs
Copiare il codice seguente in Hotel.cs per definire la struttura di un documento di hotel. Gli attributi nel campo ne determinano in che modo è usato in un'applicazione. L'attributo IsFilterable, ad esempio, deve essere assegnato a ogni campo che supporta un'espressione filtro.
using System;
using System.Text.Json.Serialization;
using Azure.Search.Documents.Indexes;
using Azure.Search.Documents.Indexes.Models;
namespace AzureSearch.Quickstart
{
public partial class Hotel
{
[SimpleField(IsKey = true, IsFilterable = true)]
public string HotelId { get; set; }
[SearchableField(IsSortable = true)]
public string HotelName { get; set; }
[SearchableField(AnalyzerName = LexicalAnalyzerName.Values.EnLucene)]
public string Description { get; set; }
[SearchableField(AnalyzerName = LexicalAnalyzerName.Values.FrLucene)]
[JsonPropertyName("Description_fr")]
public string DescriptionFr { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public string Category { get; set; }
[SearchableField(IsFilterable = true, IsFacetable = true)]
public string[] Tags { get; set; }
[SimpleField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public bool? ParkingIncluded { get; set; }
[SimpleField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public DateTimeOffset? LastRenovationDate { get; set; }
[SimpleField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public double? Rating { get; set; }
[SearchableField]
public Address Address { get; set; }
}
}
Nella libreria client Azure.Search.Documents è possibile usare SearchableField e SimpleField per semplificare le definizioni dei campi. Entrambi derivano da un oggetto SearchField e possono semplificare il codice:
SimpleField può essere di qualsiasi tipo di dati, non è mai ricercabile (viene ignorato per le query di ricerca full-text) ed è recuperabile (non è nascosto). Altri attributi sono disattivati per impostazione predefinita, ma possono essere attivati. Si potrebbe usare un oggetto SimpleField per gli ID di documento o i campi usati solo in filtri, facet o profili di punteggio. In tal caso, assicurarsi di applicare tutti gli attributi necessari per lo scenario, ad esempio IsKey = true per un ID documento. Per altre informazioni, vedere SimpleFieldAttribute.cs nel codice sorgente.
SearchableField deve essere una stringa ed è sempre ricercabile e recuperabile. Altri attributi sono disattivati per impostazione predefinita, ma possono essere attivati. Poiché questo tipo di campo è ricercabile, supporta i sinonimi e tutte le proprietà dell'analizzatore. Per altre informazioni, vedere SearchableFieldAttribute.cs nel codice sorgente.
Sia che si usi l'API SearchField di base o uno dei modelli di supporto, è necessario abilitare in modo esplicito gli attributi di filtro, facet e ordinamento. Ad esempio, IsFilterable, IsSortable e IsFacetable devono essere attribuiti in modo esplicito, come illustrato nell'esempio precedente.
Aggiungere una seconda definizione di classe vuota al progetto: Indirizzo.cs. Copiare il codice seguente nella classe.
using Azure.Search.Documents.Indexes;
namespace AzureSearch.Quickstart
{
public partial class Address
{
[SearchableField(IsFilterable = true)]
public string StreetAddress { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public string City { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public string StateProvince { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public string PostalCode { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true, IsFacetable = true)]
public string Country { get; set; }
}
}
Creare altre due classi: Hotel.Methods.cs e Address.Methods.cs per ToString() le sostituzioni. Queste classi vengono usate per visualizzare i risultati della ricerca nell'output della console. Questo articolo non fornisce il contenuto di tali classi ma è possibile copiare il codice dai file in GitHub.
In Program.cs creare un oggetto SearchIndex, quindi chiamare il metodo CreateIndex per esprimere l'indice nel servizio di ricerca. L'indice include anche un oggetto SearchSuggester per abilitare il completamento automatico nei campi specificati.
// Create hotels-quickstart index
private static void CreateIndex(string indexName, SearchIndexClient adminClient)
{
FieldBuilder fieldBuilder = new FieldBuilder();
var searchFields = fieldBuilder.Build(typeof(Hotel));
var definition = new SearchIndex(indexName, searchFields);
var suggester = new SearchSuggester("sg", new[] { "HotelName", "Category", "Address/City", "Address/StateProvince" });
definition.Suggesters.Add(suggester);
adminClient.CreateOrUpdateIndex(definition);
}
Caricare i documenti
Azure AI Search esegue ricerche sul contenuto archiviato nel servizio. In questo passaggio si caricheranno documenti JSON conformi all'indice di hotel appena creato.
In Azure AI Search i documenti di ricerca sono strutture di dati che costituiscono sia l'input per l'indicizzazione che l'output restituito dalle query. In quanto ottenuti da un'origine dati esterna, gli input dei documenti possono essere righe in un database, BLOB nell'archiviazione BLOB o documenti JSON nel disco. Per brevità, in questo esempio i documenti JSON per i quattro alberghi verranno incorporati nel codice stesso.
Quando si caricano i documenti, è necessario usare un oggetto IndexDocumentsBatch. Un oggetto IndexDocumentsBatch contiene una raccolta di Azioni, ognuna delle quali contiene un documento e una proprietà che indicano ad Azure AI Search quale azione eseguire (caricare, unire, eliminare e mergeOrUpload).
In Program.cs creare una matrice di documenti e azioni di indice e quindi passarla a IndexDocumentsBatch. I documenti seguenti sono conformi all'indice hotels-quickstart, come definito dalla classe hotel.
// Upload documents in a single Upload request.
private static void UploadDocuments(SearchClient searchClient)
{
IndexDocumentsBatch<Hotel> batch = IndexDocumentsBatch.Create(
IndexDocumentsAction.Upload(
new Hotel()
{
HotelId = "1",
HotelName = "Stay-Kay City Hotel",
Description = "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.",
DescriptionFr = "L'hôtel est idéalement situé sur la principale artère commerciale de la ville en plein cœur de New York. A quelques minutes se trouve la place du temps et le centre historique de la ville, ainsi que d'autres lieux d'intérêt qui font de New York l'une des villes les plus attractives et cosmopolites de l'Amérique.",
Category = "Boutique",
Tags = new[] { "pool", "air conditioning", "concierge" },
ParkingIncluded = false,
LastRenovationDate = new DateTimeOffset(1970, 1, 18, 0, 0, 0, TimeSpan.Zero),
Rating = 3.6,
Address = new Address()
{
StreetAddress = "677 5th Ave",
City = "New York",
StateProvince = "NY",
PostalCode = "10022",
Country = "USA"
}
}),
IndexDocumentsAction.Upload(
new Hotel()
{
HotelId = "2",
HotelName = "Old Century Hotel",
Description = "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts.",
DescriptionFr = "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
Category = "Boutique",
Tags = new[] { "pool", "free wifi", "concierge" },
ParkingIncluded = false,
LastRenovationDate = new DateTimeOffset(1979, 2, 18, 0, 0, 0, TimeSpan.Zero),
Rating = 3.60,
Address = new Address()
{
StreetAddress = "140 University Town Center Dr",
City = "Sarasota",
StateProvince = "FL",
PostalCode = "34243",
Country = "USA"
}
}),
IndexDocumentsAction.Upload(
new Hotel()
{
HotelId = "3",
HotelName = "Gastronomic Landscape Hotel",
Description = "The Hotel stands out for its gastronomic excellence under the management of William Dough, who advises on and oversees all of the Hotel’s restaurant services.",
DescriptionFr = "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
Category = "Resort and Spa",
Tags = new[] { "air conditioning", "bar", "continental breakfast" },
ParkingIncluded = true,
LastRenovationDate = new DateTimeOffset(2015, 9, 20, 0, 0, 0, TimeSpan.Zero),
Rating = 4.80,
Address = new Address()
{
StreetAddress = "3393 Peachtree Rd",
City = "Atlanta",
StateProvince = "GA",
PostalCode = "30326",
Country = "USA"
}
}),
IndexDocumentsAction.Upload(
new Hotel()
{
HotelId = "4",
HotelName = "Sublime Palace Hotel",
Description = "Sublime Palace Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Palace is part of a lovingly restored 1800 palace.",
DescriptionFr = "Le Sublime Palace Hotel est situé au coeur du centre historique de sublime dans un quartier extrêmement animé et vivant, à courte distance de marche des sites et monuments de la ville et est entouré par l'extraordinaire beauté des églises, des bâtiments, des commerces et Monuments. Sublime Palace fait partie d'un Palace 1800 restauré avec amour.",
Category = "Boutique",
Tags = new[] { "concierge", "view", "24-hour front desk service" },
ParkingIncluded = true,
LastRenovationDate = new DateTimeOffset(1960, 2, 06, 0, 0, 0, TimeSpan.Zero),
Rating = 4.60,
Address = new Address()
{
StreetAddress = "7400 San Pedro Ave",
City = "San Antonio",
StateProvince = "TX",
PostalCode = "78216",
Country = "USA"
}
})
);
try
{
IndexDocumentsResult result = searchClient.IndexDocuments(batch);
}
catch (Exception)
{
// If for some reason any documents are dropped during indexing, you can compensate by delaying and
// retrying. This simple demo just logs the failed document keys and continues.
Console.WriteLine("Failed to index some of the documents: {0}");
}
}
Dopo aver inizializzato l'oggetto IndexDocumentsBatch, è possibile inviarlo all'indice chiamando IndexDocuments nell'oggetto SearchClient.
Aggiungere le righe seguenti a Main(). Il caricamento dei documenti viene eseguito tramite SearchClient, ma l'operazione richiede anche diritti di amministratore per il servizio, che è in genere associato a SearchIndexClient. Un modo per configurare questa operazione consiste nel ottenere SearchClient tramite SearchIndexClient (adminClient in questo esempio).
SearchClient ingesterClient = adminClient.GetSearchClient(indexName);
// Load documents
Console.WriteLine("{0}", "Uploading documents...\n");
UploadDocuments(ingesterClient);
Dato che si tratta di un'app console che esegue tutti i comandi in sequenza, aggiungere un tempo di attesa di 2 secondi tra l'indicizzazione e le query.
// Wait 2 seconds for indexing to complete before starting queries (for demo and console-app purposes only)
Console.WriteLine("Waiting for indexing...\n");
System.Threading.Thread.Sleep(2000);
Il ritardo di due secondi compensa l'indicizzazione, che è asincrona, in modo che tutti i documenti possano essere indicizzati prima dell'esecuzione delle query. La scrittura di codice in un ritardo è in genere necessaria solo in applicazioni di esempio, test e demo.
Eseguire la ricerca in un indice
È possibile ottenere risultati della query subito dopo l'indicizzazione del primo documento, ma per il test effettivo dell'indice è necessario attendere il completamento dell'indicizzazione di tutti i documenti.
In questa sezione vengono aggiunte elementi di funzionalità, ovvero la logica di query e i risultati. Per le query usare il metodo Search. Questo metodo accetta il testo da cercare (stringa di query) e altre opzioni.
La classe SearchResults rappresenta i risultati.
In Program.cs creare un WriteDocuments metodo che stampa i risultati della ricerca nella console.
// Write search results to console
private static void WriteDocuments(SearchResults<Hotel> searchResults)
{
foreach (SearchResult<Hotel> result in searchResults.GetResults())
{
Console.WriteLine(result.Document);
}
Console.WriteLine();
}
private static void WriteDocuments(AutocompleteResults autoResults)
{
foreach (AutocompleteItem result in autoResults.Results)
{
Console.WriteLine(result.Text);
}
Console.WriteLine();
}
Creare un metodo RunQueries per eseguire le query e restituire i risultati. I risultati sono oggetti Hotel. Questo esempio mostra la firma del metodo e la prima query. Questa query illustra il parametro Select e consente di comporre il risultato usando i campi selezionati dal documento.
// Run queries, use WriteDocuments to print output
private static void RunQueries(SearchClient srchclient)
{
SearchOptions options;
SearchResults<Hotel> response;
// Query 1
Console.WriteLine("Query #1: Search on empty term '*' to return all documents, showing a subset of fields...\n");
options = new SearchOptions()
{
IncludeTotalCount = true,
Filter = "",
OrderBy = { "" }
};
options.Select.Add("HotelId");
options.Select.Add("HotelName");
options.Select.Add("Address/City");
response = srchclient.Search<Hotel>("*", options);
WriteDocuments(response);
Nella seconda query cercare un termine, aggiungere un filtro che seleziona i documenti in cui Rating è maggiore di 4 e quindi ordinare in base a Rating in ordine decrescente. Un filtro è un'espressione booleana che viene valutata sui campi IsFilterable di un indice. Le query di filtro includono o escludono valori. Di conseguenza, a una query di filtro non è associato alcun punteggio della rilevanza.
// Query 2
Console.WriteLine("Query #2: Search on 'hotels', filter on 'Rating gt 4', sort by Rating in descending order...\n");
options = new SearchOptions()
{
Filter = "Rating gt 4",
OrderBy = { "Rating desc" }
};
options.Select.Add("HotelId");
options.Select.Add("HotelName");
options.Select.Add("Rating");
response = srchclient.Search<Hotel>("hotels", options);
WriteDocuments(response);
La terza query illustra searchFields, che si usa per impostare l'ambito di un'operazione di ricerca full-text su specifici campi.
// Query 3
Console.WriteLine("Query #3: Limit search to specific fields (pool in Tags field)...\n");
options = new SearchOptions()
{
SearchFields = { "Tags" }
};
options.Select.Add("HotelId");
options.Select.Add("HotelName");
options.Select.Add("Tags");
response = srchclient.Search<Hotel>("pool", options);
WriteDocuments(response);
La quarta query illustra facets, che può essere usata per strutturare una struttura di spostamento in base a facet.
// Query 4
Console.WriteLine("Query #4: Facet on 'Category'...\n");
options = new SearchOptions()
{
Filter = ""
};
options.Facets.Add("Category");
options.Select.Add("HotelId");
options.Select.Add("HotelName");
options.Select.Add("Category");
response = srchclient.Search<Hotel>("*", options);
WriteDocuments(response);
La quinta query restituisce un documento specifico. Una ricerca di documenti è una risposta tipica all'evento OnClick in un set di risultati.
// Query 5
Console.WriteLine("Query #5: Look up a specific document...\n");
Response<Hotel> lookupResponse;
lookupResponse = srchclient.GetDocument<Hotel>("3");
Console.WriteLine(lookupResponse.Value.HotelId);
L'ultima query mostra la sintassi per il completamento automatico, simulando un input utente parziale di sa che risolve due possibili corrispondenze nei campi di origine associati al suggerimento definito nell'indice.
// Query 6
Console.WriteLine("Query #6: Call Autocomplete on HotelName that starts with 'sa'...\n");
var autoresponse = srchclient.Autocomplete("sa", "sg");
WriteDocuments(autoresponse);
Aggiunta di RunQueries a Main().
// Call the RunQueries method to invoke a series of queries
Console.WriteLine("Starting queries...\n");
RunQueries(srchclient);
// End the program
Console.WriteLine("{0}", "Complete. Press any key to end this program...\n");
Console.ReadKey();
Le query precedenti mostrano più modi per trovare termini corrispondenti in una query: ricerca full-text, filtri e completamento automatico.
La ricerca full-text e i filtri vengono eseguiti con il metodo SearchClient.Search. Una query di ricerca può essere passata nella stringa searchText, mentre un'espressione filtro può essere passata nella proprietà Filter della classe SearchOptions. Per filtrare senza eseguire ricerche, passare soltanto "*" per il parametro searchText del metodo Search. Per eseguire una ricerca senza filtrare, lasciare la proprietà Filter non impostata oppure non passare un'istanza di SearchOptions.
Eseguire il programma
Premere F5 per ricompilare l'app ed eseguire l'intero programma.
L'output include i messaggi restituiti da Console.WriteLine, con l'aggiunta di informazioni sulle query e i risultati.
Usare un Jupyter Notebook e la libreria azure-search-documents in Azure SDK per Python, per creare, caricare ed eseguire query su un indice di ricerca.
In alternativa, è possibile scaricare ed eseguire un notebook completato.
Configurazione dell'ambiente
Usare Visual Studio Code con l'estensione Python o un IDE equivalente con Python 3.10 o versione successiva.
Per questo avvio rapido è consigliabile usare un ambiente virtuale:
Avviare Visual Studio Code.
Aprire il riquadro comandi (CTRL+MAIUSC+P).
Cercare Python: Crea ambiente.
Selezionare Venv.
Selezionare un interprete Python. Scegliere la versione 3.10 o successiva.
La configurazione può richiedere alcuni minuti. Se si verificano problemi, vedere Ambienti Python in VS Code.
Installare i pacchetti e impostare le variabili
Installare i pacchetti, inclusi azure-search-documents.
! pip install azure-search-documents==11.6.0b1 --quiet
! pip install azure-identity --quiet
! pip install python-dotenv --quiet
Specificare l'endpoint e la chiave API per il servizio:
search_endpoint: str = "PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE"
search_api_key: str = "PUT-YOUR-SEARCH-SERVICE-ADMIN-API-KEY-HERE"
index_name: str = "hotels-quickstart"
Creare un indice
from azure.core.credentials import AzureKeyCredential
credential = AzureKeyCredential(search_api_key)
from azure.search.documents.indexes import SearchIndexClient
from azure.search.documents import SearchClient
from azure.search.documents.indexes.models import (
ComplexField,
SimpleField,
SearchFieldDataType,
SearchableField,
SearchIndex
)
# Create a search schema
index_client = SearchIndexClient(
endpoint=search_endpoint, credential=credential)
fields = [
SimpleField(name="HotelId", type=SearchFieldDataType.String, key=True),
SearchableField(name="HotelName", type=SearchFieldDataType.String, sortable=True),
SearchableField(name="Description", type=SearchFieldDataType.String, analyzer_name="en.lucene"),
SearchableField(name="Description_fr", type=SearchFieldDataType.String, analyzer_name="fr.lucene"),
SearchableField(name="Category", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),
SearchableField(name="Tags", collection=True, type=SearchFieldDataType.String, facetable=True, filterable=True),
SimpleField(name="ParkingIncluded", type=SearchFieldDataType.Boolean, facetable=True, filterable=True, sortable=True),
SimpleField(name="LastRenovationDate", type=SearchFieldDataType.DateTimeOffset, facetable=True, filterable=True, sortable=True),
SimpleField(name="Rating", type=SearchFieldDataType.Double, facetable=True, filterable=True, sortable=True),
ComplexField(name="Address", fields=[
SearchableField(name="StreetAddress", type=SearchFieldDataType.String),
SearchableField(name="City", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),
SearchableField(name="StateProvince", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),
SearchableField(name="PostalCode", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),
SearchableField(name="Country", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),
])
]
scoring_profiles = []
suggester = [{'name': 'sg', 'source_fields': ['Tags', 'Address/City', 'Address/Country']}]
# Create the search index
index = SearchIndex(name=index_name, fields=fields, suggesters=suggester, scoring_profiles=scoring_profiles)
result = index_client.create_or_update_index(index)
print(f' {result.name} created')
Creare un payload di documenti
Usare un'azione di indice per il tipo di operazione, ad esempio upload o merge-and-upload. I documenti provengono dall'esempio HotelsData su GitHub.
# Create a documents payload
documents = [
{
"@search.action": "upload",
"HotelId": "1",
"HotelName": "Stay-Kay City Hotel",
"Description": "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.",
"Description_fr": "L'hôtel est idéalement situé sur la principale artère commerciale de la ville en plein cœur de New York. A quelques minutes se trouve la place du temps et le centre historique de la ville, ainsi que d'autres lieux d'intérêt qui font de New York l'une des villes les plus attractives et cosmopolites de l'Amérique.",
"Category": "Boutique",
"Tags": [ "pool", "air conditioning", "concierge" ],
"ParkingIncluded": "false",
"LastRenovationDate": "1970-01-18T00:00:00Z",
"Rating": 3.60,
"Address": {
"StreetAddress": "677 5th Ave",
"City": "New York",
"StateProvince": "NY",
"PostalCode": "10022",
"Country": "USA"
}
},
{
"@search.action": "upload",
"HotelId": "2",
"HotelName": "Old Century Hotel",
"Description": "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Boutique",
"Tags": [ "pool", "free wifi", "concierge" ],
"ParkingIncluded": "false",
"LastRenovationDate": "1979-02-18T00:00:00Z",
"Rating": 3.60,
"Address": {
"StreetAddress": "140 University Town Center Dr",
"City": "Sarasota",
"StateProvince": "FL",
"PostalCode": "34243",
"Country": "USA"
}
},
{
"@search.action": "upload",
"HotelId": "3",
"HotelName": "Gastronomic Landscape Hotel",
"Description": "The Hotel stands out for its gastronomic excellence under the management of William Dough, who advises on and oversees all of the Hotel's restaurant services.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Resort and Spa",
"Tags": [ "air conditioning", "bar", "continental breakfast" ],
"ParkingIncluded": "true",
"LastRenovationDate": "2015-09-20T00:00:00Z",
"Rating": 4.80,
"Address": {
"StreetAddress": "3393 Peachtree Rd",
"City": "Atlanta",
"StateProvince": "GA",
"PostalCode": "30326",
"Country": "USA"
}
},
{
"@search.action": "upload",
"HotelId": "4",
"HotelName": "Sublime Palace Hotel",
"Description": "Sublime Palace Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Palace is part of a lovingly restored 1800 palace.",
"Description_fr": "Le Sublime Palace Hotel est situé au coeur du centre historique de sublime dans un quartier extrêmement animé et vivant, à courte distance de marche des sites et monuments de la ville et est entouré par l'extraordinaire beauté des églises, des bâtiments, des commerces et Monuments. Sublime Palace fait partie d'un Palace 1800 restauré avec amour.",
"Category": "Boutique",
"Tags": [ "concierge", "view", "24-hour front desk service" ],
"ParkingIncluded": "true",
"LastRenovationDate": "1960-02-06T00:00:00Z",
"Rating": 4.60,
"Address": {
"StreetAddress": "7400 San Pedro Ave",
"City": "San Antonio",
"StateProvince": "TX",
"PostalCode": "78216",
"Country": "USA"
}
}
]
Carica documenti
# Upload documents to the index
search_client = SearchClient(endpoint=search_endpoint,
index_name=index_name,
credential=credential)
try:
result = search_client.upload_documents(documents=documents)
print("Upload of new document succeeded: {}".format(result[0].succeeded))
except Exception as ex:
print (ex.message)
index_client = SearchIndexClient(
endpoint=search_endpoint, credential=credential)
Eseguire la prima query
Usare il metodo di ricerca della classe search.client.
Questo esempio esegue una ricerca vuota (search=*), restituendo un elenco non classificato (con punteggio di ricerca uguale a 1.0) di documenti arbitrari. Non essendoci criteri, nei risultati vengono inclusi tutti i documenti.
# Run an empty query (returns selected fields, all documents)
results = search_client.search(query_type='simple',
search_text="*" ,
select='HotelName,Description',
include_total_count=True)
print ('Total Documents Matching Query:', results.get_count())
for result in results:
print(result["@search.score"])
print(result["HotelName"])
print(f"Description: {result['Description']}")
Eseguire una query di termine
La query successiva aggiunge parole intere all'espressione di ricerca ("wifi"). Questa query specifica che i risultati devono contenere solo i campi inclusi nell'istruzione select. Limitando i campi restituiti, è possibile ridurre la quantità di dati inviati tramite rete e di conseguenza la latenza della ricerca.
results = search_client.search(query_type='simple',
search_text="wifi" ,
select='HotelName,Description,Tags',
include_total_count=True)
print ('Total Documents Matching Query:', results.get_count())
for result in results:
print(result["@search.score"])
print(result["HotelName"])
print(f"Description: {result['Description']}")
Aggiungi un filtro
Aggiungere un'espressione di filtro per restituire solo gli hotel con una valutazione maggiore di quattro, in ordine decrescente.
# Add a filter
results = search_client.search(
search_text="hotels",
select='HotelId,HotelName,Rating',
filter='Rating gt 4',
order_by='Rating desc')
for result in results:
print("{}: {} - {} rating".format(result["HotelId"], result["HotelName"], result["Rating"]))
Aggiungere l'ambito del campo
Aggiungere search_fields per definire l’ambito di esecuzione di query in campi specifici.
# Add search_fields to scope query matching to the HotelName field
results = search_client.search(
search_text="sublime",
search_fields=['HotelName'],
select='HotelId,HotelName')
for result in results:
print("{}: {}".format(result["HotelId"], result["HotelName"]))
Aggiungere facet
I facet vengono generati per le corrispondenze positive trovate nei risultati della ricerca. Non esistono corrispondenze pari a zero. Se i risultati della ricerca non includono il termine wifi, wifi non viene visualizzato nella struttura di spostamento in base a facet.
# Return facets
results = search_client.search(search_text="*", facets=["Category"])
facets = results.get_facets()
for facet in facets["Category"]:
print(" {}".format(facet))
Cerca un documento
Restituire un documento in base alla relativa chiave. Questa operazione è utile se si vuole fornire il drill-through quando un utente seleziona un elemento in un risultato della ricerca.
# Look up a specific document by ID
result = search_client.get_document(key="3")
print("Details for hotel '3' are:")
print("Name: {}".format(result["HotelName"]))
print("Rating: {}".format(result["Rating"]))
print("Category: {}".format(result["Category"]))
Aggiungere il completamento automatico
Completamento automatico può fornire potenziali corrispondenze quando l'utente digita nella casella di ricerca.
Completamento automatico usa uno strumento suggerimenti (sg) per sapere quali campi contengono potenziali corrispondenze alle richieste dello strumento suggerimenti. In questo Avvio rapido, questi campi sono Tags, Address/City e Address/Country.
Per simulare il completamento automatico, passare le lettere sa come stringa parziale. Il metodo di completamento automatico di SearchClient restituisce le possibile corrispondenze del termine.
# Autocomplete a query
search_suggestion = 'sa'
results = search_client.autocomplete(
search_text=search_suggestion,
suggester_name="sg",
mode='twoTerms')
print("Autocomplete for:", search_suggestion)
for result in results:
print (result['text'])
Compilare un'applicazione console Java usando la libreria Azure.Search.Documents per creare, caricare ed eseguire query su un indice di ricerca.
In alternativa è possibile scaricare il codice sorgente per iniziare con un progetto finito oppure seguire questi passaggi per crearne uno.
Configurazione dell'ambiente
Usare gli strumenti seguenti per creare questa guida introduttiva.
Creare il progetto
Avviare Visual Studio Code.
Aprire il riquadro comandi usando CTRL+MAIUSC+P. Cercare Creare un progetto Java.

Selezionare Maven.
Selezionare maven-archetype-quickstart.
Selezionare la versione più recente, attualmente è 1.4.

Come ID gruppo, immettere azure.search.sample.
Come ID artefatto, azuresearchquickstart.

Selezionare la cartella in cui creare il progetto.
Completare la creazione del progetto nel terminale integrato. Premere INVIO per accettare il valore predefinito per "1.0-SNAPSHOT" e quindi digitare "y" per confermare le proprietà per il progetto.
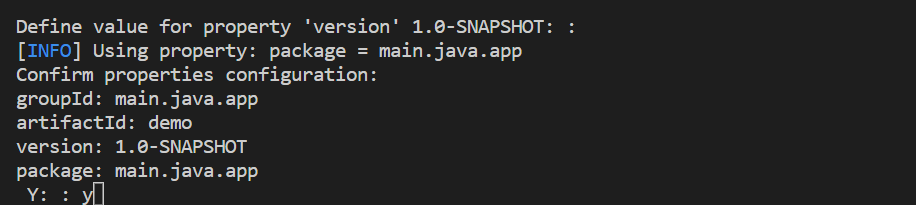
Aprire la cartella in cui è stato creato il progetto.
Specificare le dipendenze di Maven
Aprire il file pom.xml e aggiungere le dipendenze seguenti.
<dependencies>
<dependency>
<groupId>com.azure</groupId>
<artifactId>azure-search-documents</artifactId>
<version>11.7.3</version>
</dependency>
<dependency>
<groupId>com.azure</groupId>
<artifactId>azure-core</artifactId>
<version>1.53.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
</dependencies>
Modificare la versione Java del compilatore in 11.
<maven.compiler.source>1.11</maven.compiler.source>
<maven.compiler.target>1.11</maven.compiler.target>
Creare un client di ricerca
Aprire la classe App in src, main, java, azure, cercare, campione. Aggiungere le direttive di importazione seguenti.
import java.util.Arrays;
import java.util.ArrayList;
import java.time.OffsetDateTime;
import java.time.ZoneOffset;
import java.time.LocalDateTime;
import java.time.LocalDate;
import java.time.LocalTime;
import com.azure.core.credential.AzureKeyCredential;
import com.azure.core.util.Context;
import com.azure.search.documents.SearchClient;
import com.azure.search.documents.SearchClientBuilder;
import com.azure.search.documents.models.SearchOptions;
import com.azure.search.documents.indexes.SearchIndexClient;
import com.azure.search.documents.indexes.SearchIndexClientBuilder;
import com.azure.search.documents.indexes.models.IndexDocumentsBatch;
import com.azure.search.documents.indexes.models.SearchIndex;
import com.azure.search.documents.indexes.models.SearchSuggester;
import com.azure.search.documents.util.AutocompletePagedIterable;
import com.azure.search.documents.util.SearchPagedIterable;
L'esempio seguente include i segnaposto per un nome del servizio di ricerca, una chiave API amministratore che concede le autorizzazioni di creazione ed eliminazione, e il nome dell'indice. Sostituire i valori validi per tutti e tre i segnaposto. Creare due client: SearchIndexClient crea l'indice, mentre SearchClient carica un indice esistente ed esegue query su un indice esistente. Per entrambi è necessario l'endpoint di servizio e una chiave API amministratore per l'autenticazione con diritti di creazione ed eliminazione.
public static void main(String[] args) {
var searchServiceEndpoint = "<YOUR-SEARCH-SERVICE-URL>";
var adminKey = new AzureKeyCredential("<YOUR-SEARCH-SERVICE-ADMIN-KEY>");
String indexName = "<YOUR-SEARCH-INDEX-NAME>";
SearchIndexClient searchIndexClient = new SearchIndexClientBuilder()
.endpoint(searchServiceEndpoint)
.credential(adminKey)
.buildClient();
SearchClient searchClient = new SearchClientBuilder()
.endpoint(searchServiceEndpoint)
.credential(adminKey)
.indexName(indexName)
.buildClient();
}
Creare un indice
Questa guida di avvio rapido compila un indice di hotel in cui si caricheranno i dati relativi agli hotel su cui si eseguiranno query. In questo passaggio definire i campi dell'indice. Ogni definizione di campo include un nome, un tipo di dati e gli attributi che determinano come viene usato il campo.
In questo esempio, per una maggiore leggibilità e semplicità vengono usati i metodi sincroni della libreria azure.search.documents. Per scenari di produzione, tuttavia, è consigliabile usare metodi asincroni per mantenere la scalabilità e la reattività dell'app. Ad esempio anziché SearchClient si userebbe SearchAsyncClient.
Aggiungere una definizione di classe vuota al progetto: Hotel.java
Copiare il codice seguente in Hotel.java per definire la struttura di un documento di hotel. Gli attributi nel campo ne determinano in che modo è usato in un'applicazione. Ad esempio, l'annotazione IsFilterable deve essere assegnata a ogni campo che supporta un'espressione di filtro
// Copyright (c) Microsoft Corporation. All rights reserved.
// Licensed under the MIT License.
package azure.search.sample;
import com.azure.search.documents.indexes.SearchableField;
import com.azure.search.documents.indexes.SimpleField;
import com.fasterxml.jackson.annotation.JsonInclude;
import com.fasterxml.jackson.annotation.JsonProperty;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.annotation.JsonInclude.Include;
import java.time.OffsetDateTime;
/**
* Model class representing a hotel.
*/
@JsonInclude(Include.NON_NULL)
public class Hotel {
/**
* Hotel ID
*/
@JsonProperty("HotelId")
@SimpleField(isKey = true)
public String hotelId;
/**
* Hotel name
*/
@JsonProperty("HotelName")
@SearchableField(isSortable = true)
public String hotelName;
/**
* Description
*/
@JsonProperty("Description")
@SearchableField(analyzerName = "en.microsoft")
public String description;
/**
* French description
*/
@JsonProperty("DescriptionFr")
@SearchableField(analyzerName = "fr.lucene")
public String descriptionFr;
/**
* Category
*/
@JsonProperty("Category")
@SearchableField(isFilterable = true, isSortable = true, isFacetable = true)
public String category;
/**
* Tags
*/
@JsonProperty("Tags")
@SearchableField(isFilterable = true, isFacetable = true)
public String[] tags;
/**
* Whether parking is included
*/
@JsonProperty("ParkingIncluded")
@SimpleField(isFilterable = true, isSortable = true, isFacetable = true)
public Boolean parkingIncluded;
/**
* Last renovation time
*/
@JsonProperty("LastRenovationDate")
@SimpleField(isFilterable = true, isSortable = true, isFacetable = true)
public OffsetDateTime lastRenovationDate;
/**
* Rating
*/
@JsonProperty("Rating")
@SimpleField(isFilterable = true, isSortable = true, isFacetable = true)
public Double rating;
/**
* Address
*/
@JsonProperty("Address")
public Address address;
@Override
public String toString()
{
try
{
return new ObjectMapper().writeValueAsString(this);
}
catch (JsonProcessingException e)
{
e.printStackTrace();
return "";
}
}
}
Nella libreria client Azure.Search.Documents è possibile usare SearchableField e SimpleField per semplificare le definizioni dei campi.
SimpleField può essere di qualsiasi tipo di dati, non è mai ricercabile (viene ignorato per le query di ricerca full-text) ed è recuperabile (non è nascosto). Altri attributi sono disattivati per impostazione predefinita, ma possono essere attivati. Si potrebbe usare un oggetto SimpleField per gli ID di documento o i campi usati solo in filtri, facet o profili di punteggio. In tal caso, assicurarsi di applicare gli attributi necessari per lo scenario, ad esempio IsKey = true per un ID documento.SearchableField deve essere una stringa ed è sempre ricercabile e recuperabile. Altri attributi sono disattivati per impostazione predefinita, ma possono essere attivati. Poiché questo tipo di campo è ricercabile, supporta i sinonimi e tutte le proprietà dell'analizzatore.
Sia che si usi l'API SearchField di base o uno dei modelli di supporto, è necessario abilitare in modo esplicito gli attributi di filtro, facet e ordinamento. Ad esempio, isFilterable, isSortablee isFacetable devono essere attribuiti in modo esplicito, come illustrato nell'esempio precedente.
Aggiungere una seconda definizione di classe vuota al progetto: Address.java. Copiare il codice seguente nella classe.
// Copyright (c) Microsoft Corporation. All rights reserved.
// Licensed under the MIT License.
package azure.search.sample;
import com.azure.search.documents.indexes.SearchableField;
import com.fasterxml.jackson.annotation.JsonInclude;
import com.fasterxml.jackson.annotation.JsonProperty;
import com.fasterxml.jackson.annotation.JsonInclude.Include;
/**
* Model class representing an address.
*/
@JsonInclude(Include.NON_NULL)
public class Address {
/**
* Street address
*/
@JsonProperty("StreetAddress")
@SearchableField
public String streetAddress;
/**
* City
*/
@JsonProperty("City")
@SearchableField(isFilterable = true, isSortable = true, isFacetable = true)
public String city;
/**
* State or province
*/
@JsonProperty("StateProvince")
@SearchableField(isFilterable = true, isSortable = true, isFacetable = true)
public String stateProvince;
/**
* Postal code
*/
@JsonProperty("PostalCode")
@SearchableField(isFilterable = true, isSortable = true, isFacetable = true)
public String postalCode;
/**
* Country
*/
@JsonProperty("Country")
@SearchableField(isFilterable = true, isSortable = true, isFacetable = true)
public String country;
}
In App.javacreare un SearchIndex oggetto nel main metodo e quindi chiamare il createOrUpdateIndex metodo per creare l'indice nel servizio di ricerca. L'indice include anche un SearchSuggester per abilitare il completamento automatico nei campi specificati.
// Create Search Index for Hotel model
searchIndexClient.createOrUpdateIndex(
new SearchIndex(indexName, SearchIndexClient.buildSearchFields(Hotel.class, null))
.setSuggesters(new SearchSuggester("sg", Arrays.asList("HotelName"))));
Caricare i documenti
Azure AI Search esegue ricerche sul contenuto archiviato nel servizio. In questo passaggio si caricheranno documenti JSON conformi all'indice di hotel appena creato.
In Azure AI Search i documenti di ricerca sono strutture di dati che costituiscono sia l'input per l'indicizzazione che l'output restituito dalle query. In quanto ottenuti da un'origine dati esterna, gli input dei documenti possono essere righe in un database, BLOB nell'archiviazione BLOB o documenti JSON nel disco. Per brevità, in questo esempio i documenti JSON per i quattro alberghi verranno incorporati nel codice stesso.
Quando si caricano i documenti, è necessario usare un oggetto IndexDocumentsBatch. Un oggetto IndexDocumentsBatch contiene una raccolta di IndexActions, ognuna delle quali contiene un documento e una proprietà che indicano ad Azure AI Search quale azione eseguire (caricare, unire, eliminare e mergeOrUpload).
In App.javacreare documenti e azioni di indice e quindi passarli a IndexDocumentsBatch. I documenti seguenti sono conformi all'indice hotels-quickstart, come definito dalla classe hotel.
// Upload documents in a single Upload request.
private static void uploadDocuments(SearchClient searchClient)
{
var hotelList = new ArrayList<Hotel>();
var hotel = new Hotel();
hotel.hotelId = "1";
hotel.hotelName = "Stay-Kay City Hotel";
hotel.description = "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.";
hotel.descriptionFr = "L'hôtel est idéalement situé sur la principale artère commerciale de la ville en plein cœur de New York. A quelques minutes se trouve la place du temps et le centre historique de la ville, ainsi que d'autres lieux d'intérêt qui font de New York l'une des villes les plus attractives et cosmopolites de l'Amérique.";
hotel.category = "Boutique";
hotel.tags = new String[] { "pool", "air conditioning", "concierge" };
hotel.parkingIncluded = false;
hotel.lastRenovationDate = OffsetDateTime.of(LocalDateTime.of(LocalDate.of(1970, 1, 18), LocalTime.of(0, 0)), ZoneOffset.UTC);
hotel.rating = 3.6;
hotel.address = new Address();
hotel.address.streetAddress = "677 5th Ave";
hotel.address.city = "New York";
hotel.address.stateProvince = "NY";
hotel.address.postalCode = "10022";
hotel.address.country = "USA";
hotelList.add(hotel);
hotel = new Hotel();
hotel.hotelId = "2";
hotel.hotelName = "Old Century Hotel";
hotel.description = "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts.";
hotel.descriptionFr = "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.";
hotel.category = "Boutique";
hotel.tags = new String[] { "pool", "free wifi", "concierge" };
hotel.parkingIncluded = false;
hotel.lastRenovationDate = OffsetDateTime.of(LocalDateTime.of(LocalDate.of(1979, 2, 18), LocalTime.of(0, 0)), ZoneOffset.UTC);
hotel.rating = 3.60;
hotel.address = new Address();
hotel.address.streetAddress = "140 University Town Center Dr";
hotel.address.city = "Sarasota";
hotel.address.stateProvince = "FL";
hotel.address.postalCode = "34243";
hotel.address.country = "USA";
hotelList.add(hotel);
hotel = new Hotel();
hotel.hotelId = "3";
hotel.hotelName = "Gastronomic Landscape Hotel";
hotel.description = "The Hotel stands out for its gastronomic excellence under the management of William Dough, who advises on and oversees all of the Hotel’s restaurant services.";
hotel.descriptionFr = "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.";
hotel.category = "Resort and Spa";
hotel.tags = new String[] { "air conditioning", "bar", "continental breakfast" };
hotel.parkingIncluded = true;
hotel.lastRenovationDate = OffsetDateTime.of(LocalDateTime.of(LocalDate.of(2015, 9, 20), LocalTime.of(0, 0)), ZoneOffset.UTC);
hotel.rating = 4.80;
hotel.address = new Address();
hotel.address.streetAddress = "3393 Peachtree Rd";
hotel.address.city = "Atlanta";
hotel.address.stateProvince = "GA";
hotel.address.postalCode = "30326";
hotel.address.country = "USA";
hotelList.add(hotel);
hotel = new Hotel();
hotel.hotelId = "4";
hotel.hotelName = "Sublime Palace Hotel";
hotel.description = "Sublime Palace Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Palace is part of a lovingly restored 1800 palace.";
hotel.descriptionFr = "Le Sublime Palace Hotel est situé au coeur du centre historique de sublime dans un quartier extrêmement animé et vivant, à courte distance de marche des sites et monuments de la ville et est entouré par l'extraordinaire beauté des églises, des bâtiments, des commerces et Monuments. Sublime Palace fait partie d'un Palace 1800 restauré avec amour.";
hotel.category = "Boutique";
hotel.tags = new String[] { "concierge", "view", "24-hour front desk service" };
hotel.parkingIncluded = true;
hotel.lastRenovationDate = OffsetDateTime.of(LocalDateTime.of(LocalDate.of(1960, 2, 06), LocalTime.of(0, 0)), ZoneOffset.UTC);
hotel.rating = 4.60;
hotel.address = new Address();
hotel.address.streetAddress = "7400 San Pedro Ave";
hotel.address.city = "San Antonio";
hotel.address.stateProvince = "TX";
hotel.address.postalCode = "78216";
hotel.address.country = "USA";
hotelList.add(hotel);
var batch = new IndexDocumentsBatch<Hotel>();
batch.addMergeOrUploadActions(hotelList);
try
{
searchClient.indexDocuments(batch);
}
catch (Exception e)
{
e.printStackTrace();
// If for some reason any documents are dropped during indexing, you can compensate by delaying and
// retrying. This simple demo just logs failure and continues
System.err.println("Failed to index some of the documents");
}
}
Dopo aver inizializzato l'oggetto IndexDocumentsBatch, è possibile inviarlo all'indice chiamando indexDocuments sull'oggetto SearchClient.
Aggiungere le righe seguenti a Main(). Il caricamento dei documenti è eseguito usando SearchClient.
// Upload sample hotel documents to the Search Index
uploadDocuments(searchClient);
Dato che si tratta di un'app console che esegue tutti i comandi in sequenza, aggiungere un tempo di attesa di 2 secondi tra l'indicizzazione e le query.
// Wait 2 seconds for indexing to complete before starting queries (for demo and console-app purposes only)
System.out.println("Waiting for indexing...\n");
try
{
Thread.sleep(2000);
}
catch (InterruptedException e)
{
}
Il ritardo di due secondi compensa l'indicizzazione, che è asincrona, in modo che tutti i documenti possano essere indicizzati prima dell'esecuzione delle query. La scrittura di codice in un ritardo è in genere necessaria solo in applicazioni di esempio, test e demo.
Eseguire la ricerca in un indice
È possibile ottenere risultati della query subito dopo l'indicizzazione del primo documento, ma per il test effettivo dell'indice è necessario attendere il completamento dell'indicizzazione di tutti i documenti.
In questa sezione vengono aggiunte elementi di funzionalità, ovvero la logica di query e i risultati. Per le query usare il metodo Search. Questo metodo accetta il testo da cercare (stringa di query) e altre opzioni.
In App.javacreare un WriteDocuments metodo che stampa i risultati della ricerca nella console.
// Write search results to console
private static void WriteSearchResults(SearchPagedIterable searchResults)
{
searchResults.iterator().forEachRemaining(result ->
{
Hotel hotel = result.getDocument(Hotel.class);
System.out.println(hotel);
});
System.out.println();
}
// Write autocomplete results to console
private static void WriteAutocompleteResults(AutocompletePagedIterable autocompleteResults)
{
autocompleteResults.iterator().forEachRemaining(result ->
{
String text = result.getText();
System.out.println(text);
});
System.out.println();
}
Creare un metodo RunQueries per eseguire le query e restituire i risultati. I risultati sono oggetti Hotel. Questo esempio mostra la firma del metodo e la prima query. Questa query illustra il parametro Select e consente di comporre il risultato usando i campi selezionati dal documento.
// Run queries, use WriteDocuments to print output
private static void RunQueries(SearchClient searchClient)
{
// Query 1
System.out.println("Query #1: Search on empty term '*' to return all documents, showing a subset of fields...\n");
SearchOptions options = new SearchOptions();
options.setIncludeTotalCount(true);
options.setFilter("");
options.setOrderBy("");
options.setSelect("HotelId", "HotelName", "Address/City");
WriteSearchResults(searchClient.search("*", options, Context.NONE));
}
Nella seconda query cercare un termine, aggiungere un filtro che seleziona i documenti in cui Rating è maggiore di 4 e quindi ordinare in base a Rating in ordine decrescente. Filtro è un'espressione booleana che viene valutata in base ai campi isFilterable in un indice. Le query di filtro includono o escludono valori. Di conseguenza, a una query di filtro non è associato alcun punteggio della rilevanza.
// Query 2
System.out.println("Query #2: Search on 'hotels', filter on 'Rating gt 4', sort by Rating in descending order...\n");
options = new SearchOptions();
options.setFilter("Rating gt 4");
options.setOrderBy("Rating desc");
options.setSelect("HotelId", "HotelName", "Rating");
WriteSearchResults(searchClient.search("hotels", options, Context.NONE));
La terza query illustra searchFields, che si usa per impostare l'ambito di un'operazione di ricerca full-text su specifici campi.
// Query 3
System.out.println("Query #3: Limit search to specific fields (pool in Tags field)...\n");
options = new SearchOptions();
options.setSearchFields("Tags");
options.setSelect("HotelId", "HotelName", "Tags");
WriteSearchResults(searchClient.search("pool", options, Context.NONE));
La quarta query illustra facets, che può essere usata per strutturare una struttura di spostamento in base a facet.
// Query 4
System.out.println("Query #4: Facet on 'Category'...\n");
options = new SearchOptions();
options.setFilter("");
options.setFacets("Category");
options.setSelect("HotelId", "HotelName", "Category");
WriteSearchResults(searchClient.search("*", options, Context.NONE));
La quinta query restituisce un documento specifico.
// Query 5
System.out.println("Query #5: Look up a specific document...\n");
Hotel lookupResponse = searchClient.getDocument("3", Hotel.class);
System.out.println(lookupResponse.hotelId);
System.out.println();
L'ultima query mostra la sintassi per il completamento automatico, simulando un input utente parziale di s che risolve due possibili corrispondenze nell'oggetto sourceFields associato al suggerimento definito nell'indice.
// Query 6
System.out.println("Query #6: Call Autocomplete on HotelName that starts with 's'...\n");
WriteAutocompleteResults(searchClient.autocomplete("s", "sg"));
Aggiunta di RunQueries a Main().
// Call the RunQueries method to invoke a series of queries
System.out.println("Starting queries...\n");
RunQueries(searchClient);
// End the program
System.out.println("Complete.\n");
Le query precedenti mostrano più modi per trovare termini corrispondenti in una query: ricerca full-text, filtri e completamento automatico.
La ricerca full-text e i filtri vengono eseguiti con il metodo SearchClient.search. Una query di ricerca può essere passata nella stringa searchText, mentre un'espressione di filtro può essere passata nella proprietà filter della classe SearchOptions. Per filtrare senza eseguire ricerche, passare semplicemente "*" per il parametro searchText del metodo search. Per eseguire una ricerca senza filtrare, lasciare la proprietà filter non impostata oppure non passare un'istanza di SearchOptions.
Eseguire il programma
Premere F5 per ricompilare l'app ed eseguire il programma completo.
L'output include i messaggi di System.out.println, con l'aggiunta di informazioni e risultati delle query.
Compilare un'applicazione Node.js usando la libreria @azure/search-documents per creare, caricare ed eseguire query su un indice di ricerca.
In alternativa è possibile scaricare il codice sorgente per iniziare con un progetto finito oppure seguire questi passaggi per crearne uno.
Configurazione dell'ambiente
Per creare questo avvio rapido sono stati usati gli strumenti seguenti.
Creare il progetto
Avviare Visual Studio Code.
Aprire il riquadro comandi usando CTRL+MAIUSC+P e aprire il terminale integrato.
Creare una directory di sviluppo, assegnandogli il nome di avvio rapido:
mkdir quickstart
cd quickstart
Inizializzare un progetto vuoto con npm eseguendo il comando seguente. Per inizializzare completamente il progetto, premere INVIO più volte per accettare i valori predefiniti, ad eccezione della licenza, che è necessario impostare su MIT.
npm init
Installare @azure/search-documents, JavaScript/TypeScript SDK per Azure AI Search.
npm install @azure/search-documents
Installare dotenv, usato per importare le variabili di ambiente, ad esempio il nome del servizio di ricerca e la chiave API.
npm install dotenv
Passare alla directory di avvio rapido, quindi verificare di aver configurato il progetto e le relative dipendenze verificando che il file di package.json sia simile al codice JSON seguente:
{
"name": "quickstart",
"version": "1.0.0",
"description": "Azure AI Search Quickstart",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [
"Azure",
"Search"
],
"author": "Your Name",
"license": "MIT",
"dependencies": {
"@azure/search-documents": "^11.3.0",
"dotenv": "^16.0.2"
}
}
Creare un file con estensione env in cui inserire i parametri del servizio di ricerca:
SEARCH_API_KEY=<YOUR-SEARCH-ADMIN-API-KEY>
SEARCH_API_ENDPOINT=<YOUR-SEARCH-SERVICE-URL>
Sostituire il YOUR-SEARCH-SERVICE-URL valore con il nome dell'URL dell'endpoint del servizio di ricerca. Sostituire <YOUR-SEARCH-ADMIN-API-KEY> con la chiave di amministrazione registrata in precedenza.
Creare il file index.js
Verrà quindi creato un file index.js , ovvero il file principale che ospita il codice.
All'inizio del file importare la libreria @azure/search-documents:
const { SearchIndexClient, SearchClient, AzureKeyCredential, odata } = require("@azure/search-documents");
Indicare quindi al pacchetto dotenv di leggere i parametri del file env come segue:
// Load the .env file if it exists
require("dotenv").config();
// Getting endpoint and apiKey from .env file
const endpoint = process.env.SEARCH_API_ENDPOINT || "";
const apiKey = process.env.SEARCH_API_KEY || "";
Una volta configurate le importazioni e le variabili di ambiente, è possibile definire la funzione main.
Le funzionalità nell'SDK sono per la maggior parte asincrone, quindi la funzione main deve essere async. Sotto la funzione main si includerà anche un main().catch() per rilevare e registrare gli eventuali errori riscontrati:
async function main() {
console.log(`Running Azure AI Search JavaScript quickstart...`);
if (!endpoint || !apiKey) {
console.log("Make sure to set valid values for endpoint and apiKey with proper authorization.");
return;
}
// remaining quickstart code will go here
}
main().catch((err) => {
console.error("The sample encountered an error:", err);
});
A questo punto è possibile creare un indice.
Creare un indice
Creare un file hotels_quickstart_index.json. Questo file definisce il funzionamento di Azure AI Search con i documenti che verranno caricati nel passaggio successivo. Ogni campo verrà identificato da un elemento name e avrà un elemento type specifico. Ogni campo dispone anche di una serie di attributi di indice che specificano se Azure AI Search può eseguire ricerche, applicare filtri, eseguire l'ordinamento e applicare facet nel campo. Quasi tutti i campi sono tipi di dati semplici, ma alcuni come AddressType sono tipi complessi che consentono di creare strutture di dati avanzate nell'indice. Per altre informazioni sui tipi di dati supportati e sugli attributi di indice descritti, vedere Creare un indice (REST).
Aggiungere il contenuto seguente per hotels_quickstart_index.json o scaricare il file.
{
"name": "hotels-quickstart",
"fields": [
{
"name": "HotelId",
"type": "Edm.String",
"key": true,
"filterable": true
},
{
"name": "HotelName",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": true,
"facetable": false
},
{
"name": "Description",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"analyzerName": "en.lucene"
},
{
"name": "Description_fr",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"analyzerName": "fr.lucene"
},
{
"name": "Category",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Tags",
"type": "Collection(Edm.String)",
"searchable": true,
"filterable": true,
"sortable": false,
"facetable": true
},
{
"name": "ParkingIncluded",
"type": "Edm.Boolean",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "LastRenovationDate",
"type": "Edm.DateTimeOffset",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Rating",
"type": "Edm.Double",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Address",
"type": "Edm.ComplexType",
"fields": [
{
"name": "StreetAddress",
"type": "Edm.String",
"filterable": false,
"sortable": false,
"facetable": false,
"searchable": true
},
{
"name": "City",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "StateProvince",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "PostalCode",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Country",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
}
]
}
],
"suggesters": [
{
"name": "sg",
"searchMode": "analyzingInfixMatching",
"sourceFields": [
"HotelName"
]
}
]
}
Una volta configurata la definizione dell'indice, importare hotels_quickstart_index.json all'inizio di index.js in modo che la funzione main possa accedere alla definizione dell'indice.
const indexDefinition = require('./hotels_quickstart_index.json');
All'interno della funzione main creare quindi un SearchIndexClient, che viene usato per creare e gestire gli indici per Azure AI Search.
const indexClient = new SearchIndexClient(endpoint, new AzureKeyCredential(apiKey));
A questo punto eliminare l'indice, se esiste già. Questa operazione è una procedura comune per il codice di test/demo.
A questo scopo occorre definire una funzione semplice che tenta di eliminare l'indice.
async function deleteIndexIfExists(indexClient, indexName) {
try {
await indexClient.deleteIndex(indexName);
console.log('Deleting index...');
} catch {
console.log('Index does not exist yet.');
}
}
Per eseguire la funzione, estrarre il nome dell'indice dalla definizione dell'indice e quindi passare indexName insieme a indexClient alla funzione deleteIndexIfExists().
const indexName = indexDefinition["name"];
console.log('Checking if index exists...');
await deleteIndexIfExists(indexClient, indexName);
A questo punto è possibile creare l'indice con il metodo createIndex().
console.log('Creating index...');
let index = await indexClient.createIndex(indexDefinition);
console.log(`Index named ${index.name} has been created.`);
Eseguire l'esempio
Si è ora pronti per eseguire l'esempio. Eseguire il comando seguente in una finestra del terminale:
node index.js
Se è stato scaricato il codice sorgente e non sono ancora stati installati i pacchetti necessari, eseguire prima npm install.
Verrà visualizzata una serie di messaggi che descrivono le azioni eseguite dal programma.
Aprire la finestra Panoramica del servizio di ricerca nel portale di Azure. Selezionare la scheda Indici. Verrà visualizzata una schermata simile al seguente esempio:
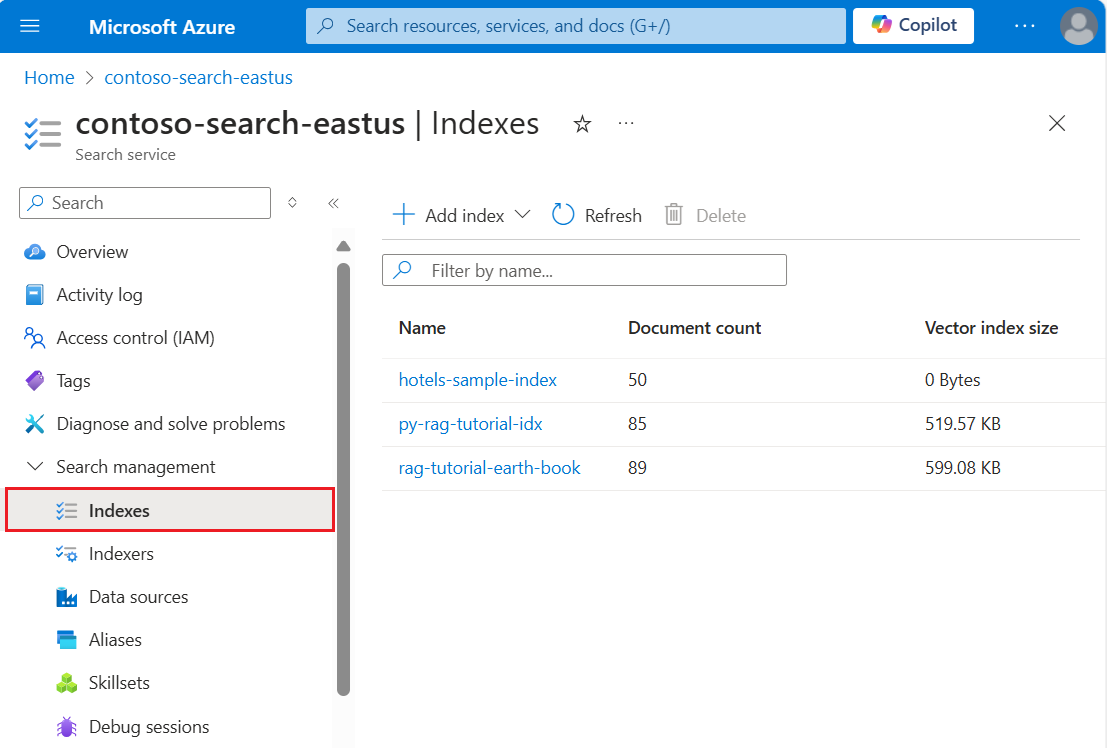
Nel passaggio successivo verranno aggiunti dati all'indice.
Caricare i documenti
In Azure AI Search i documenti sono strutture dei dati che costituiscono sia l'input per l'indicizzazione che l'output restituito dalle query. È possibile eseguire il push di questi dati nell'indice oppure usare un indicizzatore. In questo caso si eseguirà il push dei documenti nell'indice a livello di codice.
Gli input dei documenti possono essere righe in un database, BLOB nell'archiviazione BLOB o, come in questo esempio, documenti JSON nel disco. È possibile scaricare hotels.json o creare il proprio file hotels.json con il contenuto seguente:
{
"value": [
{
"HotelId": "1",
"HotelName": "Stay-Kay City Hotel",
"Description": "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.",
"Description_fr": "L'hôtel est idéalement situé sur la principale artère commerciale de la ville en plein cœur de New York. A quelques minutes se trouve la place du temps et le centre historique de la ville, ainsi que d'autres lieux d'intérêt qui font de New York l'une des villes les plus attractives et cosmopolites de l'Amérique.",
"Category": "Boutique",
"Tags": ["pool", "air conditioning", "concierge"],
"ParkingIncluded": false,
"LastRenovationDate": "1970-01-18T00:00:00Z",
"Rating": 3.6,
"Address": {
"StreetAddress": "677 5th Ave",
"City": "New York",
"StateProvince": "NY",
"PostalCode": "10022"
}
},
{
"HotelId": "2",
"HotelName": "Old Century Hotel",
"Description": "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Boutique",
"Tags": ["pool", "free wifi", "concierge"],
"ParkingIncluded": "false",
"LastRenovationDate": "1979-02-18T00:00:00Z",
"Rating": 3.6,
"Address": {
"StreetAddress": "140 University Town Center Dr",
"City": "Sarasota",
"StateProvince": "FL",
"PostalCode": "34243"
}
},
{
"HotelId": "3",
"HotelName": "Gastronomic Landscape Hotel",
"Description": "The Hotel stands out for its gastronomic excellence under the management of William Dough, who advises on and oversees all of the Hotel’s restaurant services.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Resort and Spa",
"Tags": ["air conditioning", "bar", "continental breakfast"],
"ParkingIncluded": "true",
"LastRenovationDate": "2015-09-20T00:00:00Z",
"Rating": 4.8,
"Address": {
"StreetAddress": "3393 Peachtree Rd",
"City": "Atlanta",
"StateProvince": "GA",
"PostalCode": "30326"
}
},
{
"HotelId": "4",
"HotelName": "Sublime Palace Hotel",
"Description": "Sublime Palace Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Palace is part of a lovingly restored 1800 palace.",
"Description_fr": "Le Sublime Palace Hotel est situé au coeur du centre historique de sublime dans un quartier extrêmement animé et vivant, à courte distance de marche des sites et monuments de la ville et est entouré par l'extraordinaire beauté des églises, des bâtiments, des commerces et Monuments. Sublime Palace fait partie d'un Palace 1800 restauré avec amour.",
"Category": "Boutique",
"Tags": ["concierge", "view", "24-hour front desk service"],
"ParkingIncluded": true,
"LastRenovationDate": "1960-02-06T00:00:00Z",
"Rating": 4.6,
"Address": {
"StreetAddress": "7400 San Pedro Ave",
"City": "San Antonio",
"StateProvince": "TX",
"PostalCode": "78216"
}
}
]
}
Analogamente a quanto fatto con , indexDefinitionè necessario importare hotels.json anche nella parte superiore di index.js in modo che i dati possano essere accessibili nella funzione principale.
const hotelData = require('./hotels.json');
Per indicizzare i dati nell'indice di ricerca, è ora necessario creare un SearchClient. Mentre SearchIndexClient viene usato per creare e gestire un indice, SearchClient viene usato per caricare i documenti ed eseguire query sull'indice.
Esistono due modi per creare un elemento SearchClient. La prima opzione consiste nel creare un SearchClient da zero:
const searchClient = new SearchClient(endpoint, indexName, new AzureKeyCredential(apiKey));
In alternativa, è possibile usare il metodo getSearchClient() di SearchIndexClient per creare SearchClient:
const searchClient = indexClient.getSearchClient(indexName);
Una volta definito il client, caricare i documenti nell'indice di ricerca. In questo caso viene usato il mergeOrUploadDocuments() metodo , che carica i documenti o li unisce a un documento esistente se esiste già un documento con la stessa chiave.
console.log('Uploading documents...');
let indexDocumentsResult = await searchClient.mergeOrUploadDocuments(hotelData['value']);
console.log(`Index operations succeeded: ${JSON.stringify(indexDocumentsResult.results[0].succeeded)}`);
Eseguire di nuovo il programma con node index.js. Verrà visualizzato un set di messaggi leggermente diverso rispetto a quanto visualizzato nel passaggio 1. Questa volta l'indice esiste e dovrebbe quindi essere visualizzato un messaggio relativo alla sua eliminazione prima che l'app crei il nuovo indice e vi inserisca i dati.
Prima di eseguire le query nel passaggio successivo, occorre definire una funzione che indichi al programma di attendere un secondo. Questa operazione viene eseguita solo a scopo di test/dimostrativo per assicurarsi che l'indicizzazione venga completata e che i documenti siano disponibili nell'indice per le query.
function sleep(ms) {
var d = new Date();
var d2 = null;
do {
d2 = new Date();
} while (d2 - d < ms);
}
Per indicare al programma di attendere un secondo, chiamare la funzione sleep come riportato di seguito:
sleep(1000);
Eseguire la ricerca in un indice
Dopo aver creato un indice e aver caricato i documenti, è possibile iniziare a inviare query all'indice. In questa sezione vengono inviate cinque query diverse all'indice di ricerca per illustrare diverse funzionalità di query disponibili.
Le query vengono scritte in una sendQueries() funzione chiamata nella funzione main come indicato di seguito:
await sendQueries(searchClient);
Le query vengono inviate usando il metodo search() di searchClient. Il primo parametro è il testo della ricerca, mentre il secondo parametro specifica le opzioni di ricerca.
La prima query cerca *, che equivale alla ricerca di tutti gli elementi, e seleziona tre dei campi nell'indice. È consigliabile select solo i campi necessari, in quanto il pull di dati non necessari può aggiungere latenza alle query.
Per searchOptions questa query è includeTotalCount impostato anche su true, che restituisce il numero di risultati corrispondenti trovati.
async function sendQueries(searchClient) {
console.log('Query #1 - search everything:');
let searchOptions = {
includeTotalCount: true,
select: ["HotelId", "HotelName", "Rating"]
};
let searchResults = await searchClient.search("*", searchOptions);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
console.log(`Result count: ${searchResults.count}`);
// remaining queries go here
}
Anche le query rimanenti riportate di seguito dovrebbero essere aggiunte alla funzione sendQueries(). Qui sono separate per migliorare la leggibilità.
Nella query successiva viene specificato il termine di ricerca "wifi" e viene incluso anche un filtro per restituire solo i risultati in cui lo stato è uguale a 'FL'. I risultati sono inoltre ordinati in base al Rating dell'hotel.
console.log('Query #2 - Search with filter, orderBy, and select:');
let state = 'FL';
searchOptions = {
filter: odata`Address/StateProvince eq ${state}`,
orderBy: ["Rating desc"],
select: ["HotelId", "HotelName", "Rating"]
};
searchResults = await searchClient.search("wifi", searchOptions);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
La ricerca viene quindi limitata a un singolo campo ricercabile con il parametro searchFields. Questo approccio è un'ottima opzione per rendere la query più efficiente, se si è interessati solo alle corrispondenze in determinati campi.
console.log('Query #3 - Limit searchFields:');
searchOptions = {
select: ["HotelId", "HotelName", "Rating"],
searchFields: ["HotelName"]
};
searchResults = await searchClient.search("Sublime Palace", searchOptions);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
console.log();
Un'altra opzione comune da includere in una query è facets. I facet consentono di creare filtri nell'interfaccia utente per consentire agli utenti di individuare più facilmente i valori che possono filtrare.
console.log('Query #4 - Use facets:');
searchOptions = {
facets: ["Category"],
select: ["HotelId", "HotelName", "Rating"],
searchFields: ["HotelName"]
};
searchResults = await searchClient.search("*", searchOptions);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
La query finale usa il metodo getDocument() di searchClient. Questo consente di recuperare in modo efficiente un documento in base alla relativa chiave.
console.log('Query #5 - Lookup document:');
let documentResult = await searchClient.getDocument(key='3')
console.log(`HotelId: ${documentResult.HotelId}; HotelName: ${documentResult.HotelName}`)
Eseguire l'esempio
Eseguire il programma usando node index.js. Oltre ai passaggi precedenti, le query vengono ora inviate e i risultati scritti nella console.
Compilare un'applicazione Node.js usando la libreria @azure/search-documents per creare, caricare ed eseguire query su un indice di ricerca.
In alternativa è possibile scaricare il codice sorgente per iniziare con un progetto finito oppure seguire questi passaggi per crearne uno.
Configurazione dell'ambiente
Per creare questo avvio rapido sono stati usati gli strumenti seguenti.
Creare il progetto
Avviare Visual Studio Code.
Aprire il riquadro comandi usando CTRL+MAIUSC+P e aprire il terminale integrato.
Creare una directory di sviluppo, assegnandogli il nome di avvio rapido:
mkdir quickstart
cd quickstart
Inizializzare un progetto vuoto con npm eseguendo il comando seguente. Per inizializzare completamente il progetto, premere INVIO più volte per accettare i valori predefiniti, ad eccezione della licenza, che è necessario impostare su MIT.
npm init
Installare @azure/search-documents, JavaScript/TypeScript SDK per Azure AI Search.
npm install @azure/search-documents
Installare dotenv, usato per importare le variabili di ambiente, ad esempio il nome del servizio di ricerca e la chiave API.
npm install dotenv
Passare alla directory di avvio rapido, quindi verificare di aver configurato il progetto e le relative dipendenze verificando che il file di package.json sia simile al codice JSON seguente:
{
"name": "quickstart",
"version": "1.0.0",
"description": "Azure AI Search Quickstart",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [
"Azure",
"Search"
],
"author": "Your Name",
"license": "MIT",
"dependencies": {
"@azure/search-documents": "^12.1.0",
"dotenv": "^16.4.5"
}
}
Creare un file con estensione env in cui inserire i parametri del servizio di ricerca:
SEARCH_API_KEY=<YOUR-SEARCH-ADMIN-API-KEY>
SEARCH_API_ENDPOINT=<YOUR-SEARCH-SERVICE-URL>
Sostituire il YOUR-SEARCH-SERVICE-URL valore con il nome dell'URL dell'endpoint del servizio di ricerca. Sostituire <YOUR-SEARCH-ADMIN-API-KEY> con la chiave di amministrazione registrata in precedenza.
Creare il file index.ts
Verrà quindi creato un file index.ts , ovvero il file principale che ospita il codice.
All'inizio del file importare la libreria @azure/search-documents:
import {
AzureKeyCredential,
ComplexField,
odata,
SearchClient,
SearchFieldArray,
SearchIndex,
SearchIndexClient,
SearchSuggester,
SimpleField
} from "@azure/search-documents";
Indicare quindi al pacchetto dotenv di leggere i parametri del file env come segue:
// Load the .env file if it exists
import dotenv from 'dotenv';
dotenv.config();
// Getting endpoint and apiKey from .env file
const endpoint = process.env.SEARCH_API_ENDPOINT || "";
const apiKey = process.env.SEARCH_API_KEY || "";
Una volta configurate le importazioni e le variabili di ambiente, è possibile definire la funzione main.
Le funzionalità nell'SDK sono per la maggior parte asincrone, quindi la funzione main deve essere async. Sotto la funzione main si includerà anche un main().catch() per rilevare e registrare gli eventuali errori riscontrati:
async function main() {
console.log(`Running Azure AI Search JavaScript quickstart...`);
if (!endpoint || !apiKey) {
console.log("Make sure to set valid values for endpoint and apiKey with proper authorization.");
return;
}
// remaining quickstart code will go here
}
main().catch((err) => {
console.error("The sample encountered an error:", err);
});
A questo punto è possibile creare un indice.
Creare un indice
Creare un file hotels_quickstart_index.json. Questo file definisce il funzionamento di Azure AI Search con i documenti che verranno caricati nel passaggio successivo. Ogni campo verrà identificato da un elemento name e avrà un elemento type specifico. Ogni campo dispone anche di una serie di attributi di indice che specificano se Azure AI Search può eseguire ricerche, applicare filtri, eseguire l'ordinamento e applicare facet nel campo. Quasi tutti i campi sono tipi di dati semplici, ma alcuni come AddressType sono tipi complessi che consentono di creare strutture di dati avanzate nell'indice. Per altre informazioni sui tipi di dati supportati e sugli attributi di indice descritti, vedere Creare un indice (REST).
Aggiungere il contenuto seguente per hotels_quickstart_index.json o scaricare il file.
{
"name": "hotels-quickstart",
"fields": [
{
"name": "HotelId",
"type": "Edm.String",
"key": true,
"filterable": true
},
{
"name": "HotelName",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": true,
"facetable": false
},
{
"name": "Description",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"analyzerName": "en.lucene"
},
{
"name": "Description_fr",
"type": "Edm.String",
"searchable": true,
"filterable": false,
"sortable": false,
"facetable": false,
"analyzerName": "fr.lucene"
},
{
"name": "Category",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Tags",
"type": "Collection(Edm.String)",
"searchable": true,
"filterable": true,
"sortable": false,
"facetable": true
},
{
"name": "ParkingIncluded",
"type": "Edm.Boolean",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "LastRenovationDate",
"type": "Edm.DateTimeOffset",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Rating",
"type": "Edm.Double",
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Address",
"type": "Edm.ComplexType",
"fields": [
{
"name": "StreetAddress",
"type": "Edm.String",
"filterable": false,
"sortable": false,
"facetable": false,
"searchable": true
},
{
"name": "City",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "StateProvince",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "PostalCode",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
},
{
"name": "Country",
"type": "Edm.String",
"searchable": true,
"filterable": true,
"sortable": true,
"facetable": true
}
]
}
],
"suggesters": [
{
"name": "sg",
"searchMode": "analyzingInfixMatching",
"sourceFields": [
"HotelName"
]
}
]
}
Una volta configurata la definizione dell'indice, importare hotels_quickstart_index.json all'inizio di index.ts in modo che la funzione main possa accedere alla definizione dell'indice.
// Importing the index definition and sample data
import indexDefinition from './hotels_quickstart_index.json';
interface HotelIndexDefinition {
name: string;
fields: SimpleField[] | ComplexField[];
suggesters: SearchSuggester[];
};
const hotelIndexDefinition: HotelIndexDefinition = indexDefinition as HotelIndexDefinition;
All'interno della funzione main creare quindi un SearchIndexClient, che viene usato per creare e gestire gli indici per Azure AI Search.
const indexClient = new SearchIndexClient(endpoint, new AzureKeyCredential(apiKey));
A questo punto eliminare l'indice, se esiste già. Questa operazione è una procedura comune per il codice di test/demo.
A questo scopo occorre definire una funzione semplice che tenta di eliminare l'indice.
async function deleteIndexIfExists(indexClient: SearchIndexClient, indexName: string): Promise<void> {
try {
await indexClient.deleteIndex(indexName);
console.log('Deleting index...');
} catch {
console.log('Index does not exist yet.');
}
}
Per eseguire la funzione, estrarre il nome dell'indice dalla definizione dell'indice e quindi passare indexName insieme a indexClient alla funzione deleteIndexIfExists().
// Getting the name of the index from the index definition
const indexName: string = hotelIndexDefinition.name;
console.log('Checking if index exists...');
await deleteIndexIfExists(indexClient, indexName);
A questo punto è possibile creare l'indice con il metodo createIndex().
console.log('Creating index...');
let index = await indexClient.createIndex(hotelIndexDefinition);
console.log(`Index named ${index.name} has been created.`);
Eseguire l'esempio
Si è ora pronti per compilare ed eseguire l'esempio. Usare una finestra del terminale per eseguire i comandi seguenti al fine di compilare l'origine con tsc, quindi eseguire l'origine con node:
tsc
node index.ts
Se è stato scaricato il codice sorgente e non sono ancora stati installati i pacchetti necessari, eseguire prima npm install.
Verrà visualizzata una serie di messaggi che descrivono le azioni eseguite dal programma.
Aprire la finestra Panoramica del servizio di ricerca nel portale di Azure. Selezionare la scheda Indici. Verrà visualizzata una schermata simile al seguente esempio:
Nel passaggio successivo verranno aggiunti dati all'indice.
Caricare i documenti
In Azure AI Search i documenti sono strutture dei dati che costituiscono sia l'input per l'indicizzazione che l'output restituito dalle query. È possibile eseguire il push di questi dati nell'indice oppure usare un indicizzatore. In questo caso si eseguirà il push dei documenti nell'indice a livello di codice.
Gli input dei documenti possono essere righe in un database, BLOB nell'archiviazione BLOB o, come in questo esempio, documenti JSON nel disco. È possibile scaricare hotels.json o creare il proprio file hotels.json con il contenuto seguente:
{
"value": [
{
"HotelId": "1",
"HotelName": "Stay-Kay City Hotel",
"Description": "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.",
"Description_fr": "L'hôtel est idéalement situé sur la principale artère commerciale de la ville en plein cœur de New York. A quelques minutes se trouve la place du temps et le centre historique de la ville, ainsi que d'autres lieux d'intérêt qui font de New York l'une des villes les plus attractives et cosmopolites de l'Amérique.",
"Category": "Boutique",
"Tags": ["pool", "air conditioning", "concierge"],
"ParkingIncluded": false,
"LastRenovationDate": "1970-01-18T00:00:00Z",
"Rating": 3.6,
"Address": {
"StreetAddress": "677 5th Ave",
"City": "New York",
"StateProvince": "NY",
"PostalCode": "10022"
}
},
{
"HotelId": "2",
"HotelName": "Old Century Hotel",
"Description": "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Boutique",
"Tags": ["pool", "free wifi", "concierge"],
"ParkingIncluded": "false",
"LastRenovationDate": "1979-02-18T00:00:00Z",
"Rating": 3.6,
"Address": {
"StreetAddress": "140 University Town Center Dr",
"City": "Sarasota",
"StateProvince": "FL",
"PostalCode": "34243"
}
},
{
"HotelId": "3",
"HotelName": "Gastronomic Landscape Hotel",
"Description": "The Hotel stands out for its gastronomic excellence under the management of William Dough, who advises on and oversees all of the Hotel’s restaurant services.",
"Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.",
"Category": "Resort and Spa",
"Tags": ["air conditioning", "bar", "continental breakfast"],
"ParkingIncluded": "true",
"LastRenovationDate": "2015-09-20T00:00:00Z",
"Rating": 4.8,
"Address": {
"StreetAddress": "3393 Peachtree Rd",
"City": "Atlanta",
"StateProvince": "GA",
"PostalCode": "30326"
}
},
{
"HotelId": "4",
"HotelName": "Sublime Palace Hotel",
"Description": "Sublime Palace Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Palace is part of a lovingly restored 1800 palace.",
"Description_fr": "Le Sublime Palace Hotel est situé au coeur du centre historique de sublime dans un quartier extrêmement animé et vivant, à courte distance de marche des sites et monuments de la ville et est entouré par l'extraordinaire beauté des églises, des bâtiments, des commerces et Monuments. Sublime Palace fait partie d'un Palace 1800 restauré avec amour.",
"Category": "Boutique",
"Tags": ["concierge", "view", "24-hour front desk service"],
"ParkingIncluded": true,
"LastRenovationDate": "1960-02-06T00:00:00Z",
"Rating": 4.6,
"Address": {
"StreetAddress": "7400 San Pedro Ave",
"City": "San Antonio",
"StateProvince": "TX",
"PostalCode": "78216"
}
}
]
}
Analogamente a quanto è stato fatto con indexDefinition, occorre anche importare hotels.json all'inizio del file index.ts in modo che i dati siano accessibili nella funzione main.
import hotelData from './hotels.json';
interface Hotel {
HotelId: string;
HotelName: string;
Description: string;
Description_fr: string;
Category: string;
Tags: string[];
ParkingIncluded: string | boolean;
LastRenovationDate: string;
Rating: number;
Address: {
StreetAddress: string;
City: string;
StateProvince: string;
PostalCode: string;
};
};
const hotels: Hotel[] = hotelData["value"];
Per indicizzare i dati nell'indice di ricerca, è ora necessario creare un SearchClient. Mentre SearchIndexClient viene usato per creare e gestire un indice, SearchClient viene usato per caricare i documenti ed eseguire query sull'indice.
Esistono due modi per creare un elemento SearchClient. La prima opzione consiste nel creare un SearchClient da zero:
const searchClient = new SearchClient<Hotel>(endpoint, indexName, new AzureKeyCredential(apiKey));
In alternativa, è possibile usare il metodo getSearchClient() di SearchIndexClient per creare SearchClient:
const searchClient = indexClient.getSearchClient<Hotel>(indexName);
Una volta definito il client, caricare i documenti nell'indice di ricerca. In questo caso viene usato il mergeOrUploadDocuments() metodo , che carica i documenti o li unisce a un documento esistente se esiste già un documento con la stessa chiave. Verificare quindi che l'operazione sia andata a buon fine perché almeno il primo documento esiste.
console.log("Uploading documents...");
const indexDocumentsResult = await searchClient.mergeOrUploadDocuments(hotels);
console.log(`Index operations succeeded: ${JSON.stringify(indexDocumentsResult.results[0].succeeded)}`);
Eseguire di nuovo il programma con tsc && node index.ts. Verrà visualizzato un set di messaggi leggermente diverso rispetto a quanto visualizzato nel passaggio 1. Questa volta l'indice esiste e dovrebbe quindi essere visualizzato un messaggio relativo alla sua eliminazione prima che l'app crei il nuovo indice e vi inserisca i dati.
Prima di eseguire le query nel passaggio successivo, occorre definire una funzione che indichi al programma di attendere un secondo. Questa operazione viene eseguita solo a scopo di test/dimostrativo per assicurarsi che l'indicizzazione venga completata e che i documenti siano disponibili nell'indice per le query.
function sleep(ms: number): Promise<void> {
return new Promise((resolve) => setTimeout(resolve, ms));
}
Per fare in modo che il programma attenda un secondo, chiamare la sleep funzione :
sleep(1000);
Eseguire la ricerca in un indice
Dopo aver creato un indice e aver caricato i documenti, è possibile iniziare a inviare query all'indice. In questa sezione vengono inviate cinque query diverse all'indice di ricerca per illustrare diverse funzionalità di query disponibili.
Le query vengono scritte in una sendQueries() funzione chiamata nella funzione main come indicato di seguito:
await sendQueries(searchClient);
Le query vengono inviate usando il metodo search() di searchClient. Il primo parametro è il testo della ricerca, mentre il secondo parametro specifica le opzioni di ricerca.
La prima query cerca *, che equivale alla ricerca di tutti gli elementi, e seleziona tre dei campi nell'indice. È consigliabile select solo i campi necessari, in quanto il pull di dati non necessari può aggiungere latenza alle query.
searchOptions per questa query contiene anche includeTotalCount impostato su true, che restituirà il numero di risultati corrispondenti trovati.
async function sendQueries(
searchClient: SearchClient<Hotel>
): Promise<void> {
// Query 1
console.log('Query #1 - search everything:');
const selectFields: SearchFieldArray<Hotel> = [
"HotelId",
"HotelName",
"Rating",
];
const searchOptions1 = {
includeTotalCount: true,
select: selectFields
};
let searchResults = await searchClient.search("*", searchOptions1);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
console.log(`Result count: ${searchResults.count}`);
// remaining queries go here
}
Anche le query rimanenti riportate di seguito dovrebbero essere aggiunte alla funzione sendQueries(). Qui sono separate per migliorare la leggibilità.
Nella query successiva viene specificato il termine di ricerca "wifi" e viene incluso anche un filtro per restituire solo i risultati in cui lo stato è uguale a 'FL'. I risultati sono inoltre ordinati in base al Rating dell'hotel.
console.log('Query #2 - search with filter, orderBy, and select:');
let state = 'FL';
const searchOptions2 = {
filter: odata`Address/StateProvince eq ${state}`,
orderBy: ["Rating desc"],
select: selectFields
};
searchResults = await searchClient.search("wifi", searchOptions2);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
La ricerca viene quindi limitata a un singolo campo ricercabile con il parametro searchFields. Questo approccio è un'ottima opzione per rendere la query più efficiente, se si è interessati solo alle corrispondenze in determinati campi.
console.log('Query #3 - limit searchFields:');
const searchOptions3 = {
select: selectFields,
searchFields: ["HotelName"] as const
};
searchResults = await searchClient.search("Sublime Palace", searchOptions3);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
Un'altra opzione comune da includere in una query è facets. I facet consentono di fornire il drill-down autoindirizzato dai risultati nella propria interfaccia utente. I risultati dei facet possono essere trasformati in caselle di controllo nel riquadro dei risultati.
console.log('Query #4 - limit searchFields and use facets:');
const searchOptions4 = {
facets: ["Category"],
select: selectFields,
searchFields: ["HotelName"] as const
};
searchResults = await searchClient.search("*", searchOptions4);
for await (const result of searchResults.results) {
console.log(`${JSON.stringify(result.document)}`);
}
La query finale usa il metodo getDocument() di searchClient. Questo consente di recuperare in modo efficiente un documento in base alla relativa chiave.
console.log('Query #5 - Lookup document:');
let documentResult = await searchClient.getDocument('3')
console.log(`HotelId: ${documentResult.HotelId}; HotelName: ${documentResult.HotelName}`)
Eseguire nuovamente l'esempio campione
Compilare ed eseguire il programma con tsc && node index.ts. Oltre ai passaggi precedenti, le query vengono ora inviate e i risultati scritti nella console.
Quando si lavora nella propria sottoscrizione, al termine di un progetto è buona norma determinare se le risorse create sono ancora necessarie. Le risorse che rimangono in esecuzione hanno un costo. È possibile eliminare risorse singole oppure gruppi di risorse per eliminare l'intero set di risorse.
Se si usa un servizio gratuito, tenere presente che il numero di indicizzatori e origini dati è limitato a tre. È possibile eliminare singoli elementi nel portale di Azure per rimanere al di sotto del limite.
In questo Avvio rapido è stata eseguita una serie di attività per creare un indice, caricarvi documenti ed eseguire query. In diverse fasi sono state adottate delle scorciatoie per semplificare il codice e renderlo più leggibile e comprensibile. Ora che si ha familiarità con i concetti di base, provare un'esercitazione che chiama le API di Azure AI Search in un'app Web.