Esercitazione: Indicizzare BLOB Markdown annidati da Archiviazione di Azure usando REST
Nota
Questa funzionalità è attualmente in anteprima pubblica. Questa anteprima viene messa a disposizione senza contratto di servizio e non è consigliata per i carichi di lavoro di produzione. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate. Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
Ricerca di intelligenza artificiale di Azure può indicizzare documenti e matrici Markdown in Archiviazione BLOB di Azure usando un indicizzatore che sa come leggere i dati markdown.
Questa esercitazione illustra come indicizzare i file Markdown indicizzati usando la oneToMany modalità di analisi Markdown. Usa un client REST e le API REST per la ricerca per eseguire le attività seguenti:
- Configurare dati di esempio e configurare un'origine dati
azureblob - Creare un indice di Azure AI Search in cui includere contenuto ricercabile
- Creare ed eseguire un indicizzatore per leggere il contenitore ed estrarre contenuto ricercabile
- Eseguire una ricerca nell'indice che appena creato
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Prerequisiti
Visual Studio Code con un client REST.
Azure AI Search. Creare o trovare una risorsa di Azure AI Search esistente nella sottoscrizione corrente.
Nota
È possibile usare il servizio gratuito per questa esercitazione. Un servizio di ricerca gratuito consente di usare solo tre indici, tre indicizzatori e tre origini dati. Questa esercitazione crea un elemento per ogni tipo. Prima di iniziare, assicurarsi che lo spazio nel servizio sia sufficiente per accettare le nuove risorse.
Creare un documento Markdown
Copiare e incollare il markdown seguente in un file denominato sample_markdown.md. I dati di esempio sono un singolo file Markdown contenente vari elementi Markdown. È stato scelto un file Markdown per rimanere al di sotto dei limiti di archiviazione del livello gratuito.
# Project Documentation
## Introduction
This document provides a complete overview of the **Markdown Features** used within this project. The following sections demonstrate the richness of Markdown formatting, with examples of lists, tables, links, images, blockquotes, inline styles, and more.
---
## Table of Contents
1. [Headers](#headers)
2. [Introduction](#introduction)
3. [Basic Text Formatting](#basic-text-formatting)
4. [Lists](#lists)
5. [Blockquotes](#blockquotes)
6. [Images](#images)
7. [Links](#links)
8. [Tables](#tables)
9. [Code Blocks and Inline Code](#code-blocks-and-inline-code)
10. [Horizontal Rules](#horizontal-rules)
11. [Inline Elements](#inline-elements)
12. [Escaping Characters](#escaping-characters)
13. [HTML Elements](#html-elements)
14. [Emojis](#emojis)
15. [Footnotes](#footnotes)
16. [Task Lists](#task-lists)
17. [Conclusion](#conclusion)
---
## Headers
Markdown supports six levels of headers. Use `#` to create headers:
"# Project Documentation" at the top of the document is an example of an h1 header.
"## Headers" above is an example of an h2 header.
### h3 example
#### h4 example
##### h5 example
###### h6 example
This is an example of content underneath a header.
## Basic Text Formatting
You can apply various styles to your text:
- **Bold**: Use double asterisks or underscores: `**bold**` or `__bold__`.
- *Italic*: Use single asterisks or underscores: `*italic*` or `_italic_`.
- ~~Strikethrough~~: Use double tildes: `~~strikethrough~~`.
## Lists
### Ordered List
1. First item
2. Second item
3. Third item
### Unordered List
- Item A
- Item B
- Item C
### Nested List
1. Parent item
- Child item
- Child item
## Blockquotes
> This is a blockquote.
> Blockquotes are great for emphasizing important information.
>> Nested blockquotes are also possible!
## Images

## Links
[Visit Markdown Guide](https://www.markdownguide.org)
## Tables
| Syntax | Description | Example |
|-------------|-------------|---------------|
| Header | Title | Header Cell |
| Paragraph | Text block | Row Content |
## Code Blocks and Inline Code
### Inline Code
Use backticks to create `inline code`.
### Code Block
```javascript
// JavaScript example
function greet(name) {
console.log(`Hello, ${name}!`);
}
greet('World');
```
## Horizontal Rules
Use three or more dashes or underscores to create a horizontal rule.
---
___
## Inline Elements
Sometimes, it’s useful to include `inline code` to highlight code-like content.
You can also emphasize text like *this* or make it **bold**.
## Escaping Characters
To render special Markdown characters, use backslashes:
- \*Asterisks\*
- \#Hashes\#
- \[Brackets\]
## HTML Elements
You can mix HTML tags with Markdown:
<table>
<tr>
<th>HTML Table</th>
<th>With Markdown</th>
</tr>
<tr>
<td>Row 1</td>
<td>Data 1</td>
</tr>
</table>
## Emojis
Markdown supports some basic emojis:
- :smile: 😄
- :rocket: 🚀
- :checkered_flag: 🏁
## Footnotes
This is an example of a footnote[^1]. Footnotes allow you to add notes without cluttering the main text.
[^1]: This is the content of the footnote.
## Task Lists
- [x] Complete the introduction
- [ ] Add more examples
- [ ] Review the document
## Conclusion
Markdown is a lightweight yet powerful tool for writing documentation. It supports a variety of formatting options while maintaining simplicity and readability.
Thank you for reviewing this example!
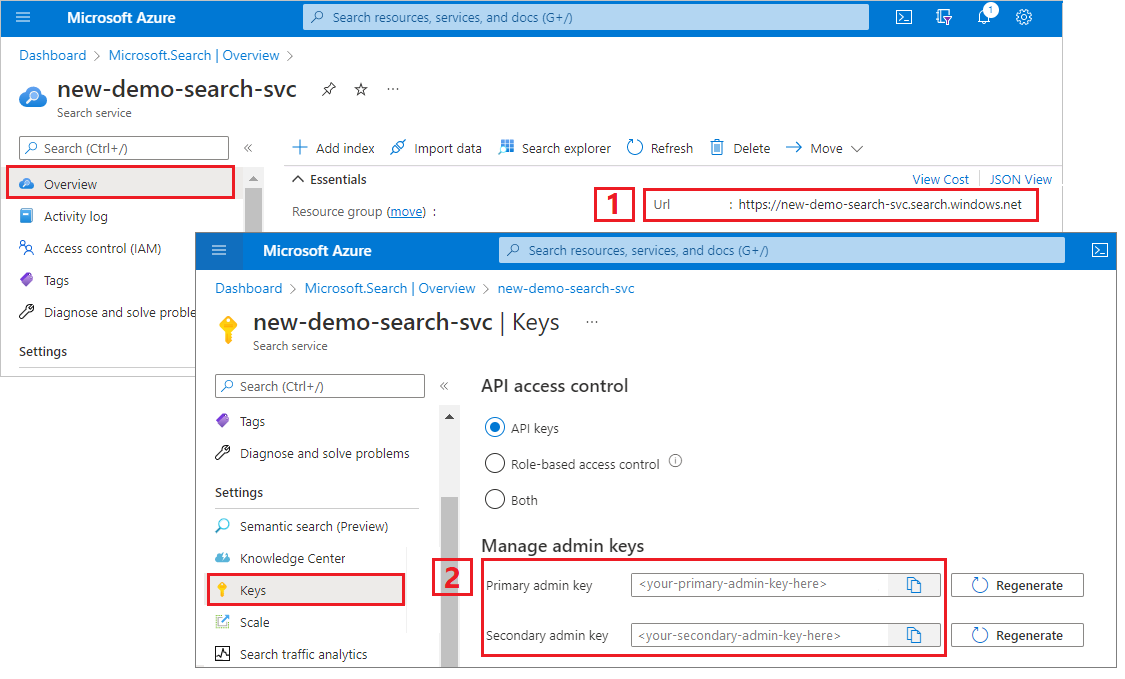
Copiare l'URL del servizio di ricerca e la chiave API
Per questa esercitazione, le connessioni ad Azure AI Search richiedono un endpoint e una chiave API. È possibile ottenere questi valori dal portale di Azure. Per metodi di connessione alternativi, vedere Identità gestite.
Accedere al portale di Azure, passare alla pagina Panoramica del servizio di ricerca e quindi copiare l'URL. Un endpoint di esempio potrebbe essere simile a
https://mydemo.search.windows.net.In Impostazioni>Chiavi, copiare una chiave amministratore. Le chiavi amministratore vengono usate per aggiungere, modificare ed eliminare oggetti. Sono disponibili due chiavi amministratore intercambiabili. Copiarne una.
Configurare il file REST
Avviare Visual Studio Code e creare un nuovo file.
Specificare i valori per le variabili usate nella richiesta:
@baseUrl = PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERE @storageConnectionString = PUT-YOUR-STORAGE-CONNECTION-STRING-HERE @blobContainer = PUT-YOUR-CONTAINER-NAME-HERESalvare il file usando un'estensione
.resto.http.
Per informazioni sul client REST, vedere Avvio rapido: ricerca di testo tramite REST.
Creare un'origine dati
Creare un'origine dati (REST) crea una connessione all'origine dati che specifica i dati da indicizzare.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name" : "sample-markdown-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
Inviare la richiesta. La risposta dovrebbe essere simile alla seguente:
HTTP/1.1 201 Created
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
ETag: "0x8DCF52E926A3C76"
Location: https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net:443/datasources('sample-markdown-ds')?api-version=2024-11-01-preview
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 0714c187-217e-4d35-928a-5069251e5cba
elapsed-time: 204
Date: Fri, 25 Oct 2024 19:52:35 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/$metadata#datasources/$entity",
"@odata.etag": "\"0x8DCF52E926A3C76\"",
"name": "sample-markdown-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": null
},
"container": {
"name": "markdown-container",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null,
"identity": null
}
Creare un indice
Creare un indice (REST) crea un indice di ricerca nel servizio di ricerca. Un indice specifica tutti i campi e i relativi attributi.
Nell'analisi uno-a-molti, il documento di ricerca definisce il lato "molti" della relazione. I campi specificati nell'indice determinano la struttura del documento di ricerca.
Sono necessari solo campi per gli elementi Markdown supportati dal parser. Questi campi sono:
content: stringa contenente il markdown non elaborato trovato in una posizione specifica, in base ai metadati dell'intestazione in quel punto del documento.sections: oggetto che contiene campi secondari per i metadati dell'intestazione fino al livello di intestazione desiderato. Ad esempio, quandomarkdownHeaderDepthè impostato suh3, contiene campih1stringa ,h2eh3. Questi campi vengono indicizzati eseguendo il mirroring di questa struttura nell'indice o tramite mapping dei campi nel formato/sections/h1,sections/h2e così via. Per esempi di contesto, vedere configurazioni dell'indice e dell'indicizzatore negli esempi seguenti. I sottocampi contenuti sono:h1- Stringa contenente il valore dell'intestazione h1. Stringa vuota se non impostata a questo punto del documento.- (Facoltativo)
h2- Stringa contenente il valore dell'intestazione h2. Stringa vuota se non impostata a questo punto del documento. - (Facoltativo)
h3- Stringa contenente il valore dell'intestazione h3. Stringa vuota se non impostata a questo punto del documento. - (Facoltativo)
h4- Stringa contenente il valore dell'intestazione h4. Stringa vuota se non impostata a questo punto del documento. - (Facoltativo)
h5- Stringa contenente il valore dell'intestazione h5. Stringa vuota se non impostata a questo punto del documento. - (Facoltativo)
h6- Stringa contenente il valore dell'intestazione h6. Stringa vuota se non impostata a questo punto del documento.
ordinal_position: valore intero che indica la posizione della sezione all'interno della gerarchia del documento. Questo campo viene usato per ordinare le sezioni nella sequenza originale come appaiono nel documento, a partire da una posizione ordinale di 1 e incrementando in sequenza per ogni blocco di contenuto.
Questa implementazione sfrutta i mapping dei campi nell'indicizzatore per eseguire il mapping dal contenuto arricchito all'indice. Per altre informazioni sulla struttura di documenti uno-a-molti analizzata, vedere BLOB markdown dell'indice.
Questo esempio fornisce esempi di come indicizzare i dati con e senza mapping dei campi. In questo caso, si sa che h1 contiene il titolo del documento, in modo che sia possibile eseguirne il mapping a un campo denominato title. Verranno inoltre mappati i h2 campi e h3 rispettivamente a h2_subheader e h3_subheader . I content campi e ordinal_position non richiedono alcun mapping perché vengono estratti direttamente da Markdown nei campi che usano tali nomi. Per un esempio di schema di indice completo che non richiede mapping dei campi, vedere la fine di questa sezione.
### Create an index
POST {{baseUrl}}/indexes?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "sample-markdown-index",
"fields": [
{"name": "id", "type": "Edm.String", "key": true, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "content", "type": "Edm.String", "key": false, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "title", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h2_subheader", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h3_subheader", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "ordinal_position", "type": "Edm.Int32", "searchable": false, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
}
Schema dell'indice in una configurazione senza mapping dei campi
I mapping dei campi consentono di modificare e filtrare il contenuto arricchito per adattarsi alla forma di indice desiderata, ma è sufficiente prendere direttamente il contenuto arricchito. In tal caso, lo schema sarà simile al seguente:
{
"name": "sample-markdown-index",
"fields": [
{"name": "id", "type": "Edm.String", "key": true, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "content", "type": "Edm.String", "key": false, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "sections",
"type": "Edm.ComplexType",
"fields": [
{"name": "h1", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h2", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h3", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
},
{"name": "ordinal_position", "type": "Edm.Int32", "searchable": false, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
}
Per ribadire, sono presenti sottocampi fino all'oggetto h3 sezioni perché markdownHeaderDepth è impostato su h3.
Se si sceglie di usare questo schema, assicurarsi di modificare le richieste successive di conseguenza. Ciò richiederà la rimozione dei mapping dei campi dalla configurazione dell'indicizzatore e l'aggiornamento delle query di ricerca per usare i nomi dei campi corrispondenti.
Creare ed eseguire un indicizzatore
Creare un indicizzatore crea un indicizzatore nel servizio di ricerca. Un indicizzatore si connette all'origine dati, ai carichi e ai dati dell'indice, oltre a fornire facoltativamente una pianificazione per l'automatizzazione dell'aggiornamento dei dati.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "sample-markdown-indexer",
"dataSourceName": "sample-markdown-ds",
"targetIndexName": "sample-markdown-index",
"parameters" : {
"configuration": {
"parsingMode": "markdown",
"markdownParsingSubmode": "oneToMany",
"markdownHeaderDepth": "h3"
}
},
"fieldMappings" : [
{
"sourceFieldName": "/sections/h1",
"targetFieldName": "title",
"mappingFunction": null
}
]
}
Punti principali:
L'indicizzatore analizzerà solo le intestazioni fino a
h3. Tutte le intestazioni di livello inferiore (h4,h5,h6) verranno considerate come testo normale e visualizzate nelcontentcampo. Ecco perché i mapping di indice e campo esistono solo fino a una profondità dih3.I
contentcampi eordinal_positionnon richiedono alcun mapping dei campi perché esistono con tali nomi nel contenuto arricchito.
Esegui query
È possibile iniziare a eseguire ricerche subito dopo aver caricato il primo documento.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"count": true
}
Inviare la richiesta. Si tratta di una query di ricerca full-text non specificata che restituisce tutti i campi contrassegnati come recuperabili nell'indice, insieme al numero di documenti. La risposta dovrebbe essere simile alla seguente:
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 6b94e605-55e8-47a5-ae15-834f926ddd14
elapsed-time: 77
Date: Fri, 25 Oct 2024 20:22:58 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 22,
"value": [
<22 search documents here>
]
}
Aggiungere un parametro search per la ricerca in una stringa.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "h4",
"count": true,
}
Inviare la richiesta. La risposta dovrebbe essere simile alla seguente:
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: ec5d03f1-e3e7-472f-9396-7ff8e3782105
elapsed-time: 52
Date: Fri, 25 Oct 2024 20:26:29 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 1,
"value": [
{
"@search.score": 0.8744742,
"section_id": "aHR0cHM6Ly9hcmphZ2Fubmpma2ZpbGVzLmJsb2IuY29yZS53aW5kb3dzLm5ldC9tYXJrZG93bi10dXRvcmlhbC9zYW1wbGVfbWFya2Rvd24ubWQ7NA2",
"content": "#### h4 example\r\n##### h5 example\r\n###### h6 example\r\nThis is an example of content underneath a header.\r\n",
"title": "Project Documentation",
"h2_subheader": "Headers",
"h3_subheader": "h3 example",
"ordinal_position": 4
}
]
}
Punti principali:
markdownHeaderDepthPoiché è impostato suh3, leh4intestazioni ,h5eh6vengono considerate come testo non crittografato, quindi vengono visualizzate nelcontentcampo .La posizione ordinale qui è
4. Questo contenuto viene visualizzato quarto tra le 22 sezioni di contenuto totali.
Aggiungere un parametro select per limitare i risultati a un minor numero di campi. Aggiungere un oggetto filter per restringere ulteriormente la ricerca.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "Markdown",
"count": true,
"select": "title, content, h2_subheader",
"filter": "h2_subheader eq 'Conclusion'"
}
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: a6f9bd46-a064-4e28-818f-ea077618014b
elapsed-time: 35
Date: Fri, 25 Oct 2024 20:36:10 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 1,
"value": [
{
"@search.score": 1.1029507,
"content": "Markdown is a lightweight yet powerful tool for writing documentation. It supports a variety of formatting options while maintaining simplicity and readability.\r\n\r\nThank you for reviewing this example!",
"title": "Project Documentation",
"h2_subheader": "Conclusion"
}
]
}
Per quanto riguarda i filtri, è anche possibile usare gli operatori logici (and, or e not) e gli operatori di confronto (eq, ne, gt, lt, ge e le). Per i confronti tra stringhe viene fatta distinzione tra maiuscole e minuscole. Per altre informazioni ed esempi, vedere Creare una query.
Nota
Il parametro $filter funziona solo nei campi contrassegnati come filtrabili al momento della creazione dell'indice.
Reimpostare ed eseguire di nuovo
Gli indicizzatori possono essere reimpostati, cancellando la cronologia di esecuzione, consentendo una riesecuzione completa. Le richieste GET seguenti sono per la reimpostazione, seguite da una riesecuzione.
### Reset the indexer
POST {{baseUrl}}/indexers/sample-markdown-indexer/reset?api-version=2024-11-01-preview HTTP/1.1
api-key: {{apiKey}}
### Run the indexer
POST {{baseUrl}}/indexers/sample-markdown-indexer/run?api-version=2024-11-01-preview HTTP/1.1
api-key: {{apiKey}}
### Check indexer status
GET {{baseUrl}}/indexers/sample-markdown-indexer/status?api-version=2024-11-01-preview HTTP/1.1
api-key: {{apiKey}}
Pulire le risorse
Quando si lavora nella propria sottoscrizione, alla fine di un progetto è opportuno rimuovere le risorse che non sono più necessarie. Le risorse che rimangono in esecuzione hanno un costo. È possibile eliminare risorse singole oppure gruppi di risorse per eliminare l'intero set di risorse.
È possibile usare il portale di Azure per eliminare indici, indicizzatori e origini dati.
Passaggi successivi
Ora che si ha familiarità con le nozioni di base dell'indicizzazione BLOB di Azure, si esaminerà in dettaglio la configurazione dell'indicizzatore per i BLOB Markdown in Archiviazione di Azure.