Classificazione semantica in Azure AI Search
In Azure AI Search, il classificatore semantico è una funzionalità che migliora notevolmente la pertinenza della ricerca usando i modelli di comprensione del linguaggio di Microsoft per riclassificare i risultati della ricerca. Questo articolo è un'introduzione di alto livello per comprendere i comportamenti e i vantaggi del classificatore semantico.
Il classificatore semantico è una funzionalità Premium, fatturata in base all'utilizzo. Questo articolo è consigliato per ottenere informazioni generali ma, se si preferisce iniziare subito, seguire questa procedura.
Nota
Il classificatore semantico non usa l'intelligenza artificiale generativa o i vettori. Se si cercano vettori e ricerche di somiglianza, vedere Ricerca vettoriale in Ricerca di intelligenza artificiale di Azure per informazioni dettagliate.
Che cos'è la classificazione semantica?
Il classificatore semantico è una raccolta di funzionalità lato query che migliorano la qualità di un risultato di ricerca iniziale con classificazione BM25 o RRF per le query basate su testo, per le query vettoriali e quelle ibride. Quando la si abilita nel servizio di ricerca, la classificazione semantica estende la pipeline di esecuzione delle query in due modi:
Prima di tutto, aggiunge la classificazione secondaria su un set di risultati iniziale con punteggio BM25 o RRF (Reciprocal Rank Fusion). Questa classificazione secondaria usa modelli di Deep Learning multilingue adattati da Microsoft Bing per promuovere i risultati più rilevanti in modo semantico.
In secondo luogo, estrae e restituisce sottotitoli e risposte nella risposta, di cui è possibile eseguire il rendering in una pagina di ricerca per migliorare l'esperienza di ricerca dell'utente.
Ecco le funzionalità del riclassificatore semantico.
| Funzionalità | Descrizione |
|---|---|
| Classifica L2 | Usa il contesto o il significato semantico di una query per calcolare un nuovo punteggio di pertinenza sui risultati pre-classificati. |
| Didascalie semantiche ed evidenziazioni | Estrae frasi ed espressioni parola per parola da campi che riepilogano meglio il contenuto, con evidenziazioni sui passaggi chiave per facilitare l'analisi. Le didascalie che riepilogano un risultato sono utili quando i singoli campi di contenuto sono troppo densi per la pagina dei risultati della ricerca. Il testo evidenziato eleva i termini e le frasi più rilevanti in modo che gli utenti possano determinare rapidamente il motivo per cui una corrispondenza è stata considerata rilevante. |
| Risposte semantiche | Una sottostruttura facoltativa e aggiuntiva restituita da una query semantica. Fornisce una risposta diretta a una query simile a una domanda. Richiede che un documento disponga di testo con le caratteristiche di una risposta. |
Funzionamento del classificatore semantico
Il classificatore semantico genera una query e risultati per i modelli di comprensione del linguaggio ospitati da Microsoft e analizza le corrispondenze migliori.
La figura seguente illustra il concetto. Si consideri il termine "capitale". Ha significati diversi a seconda che il contesto sia finanziario, legale, geografico o grammaticale. Grazie alla comprensione del linguaggio, il classificatore semantico può rilevare il contesto e promuovere i risultati che soddisfano la finalità della query.
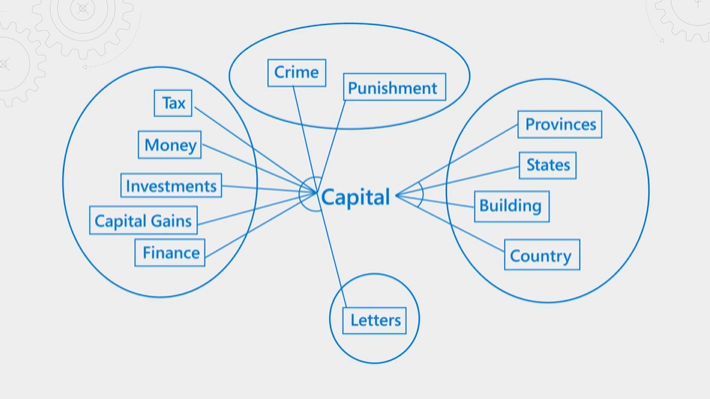
La classificazione semantica utilizza molte risorse ma impiega anche molto tempo. Per completare l'elaborazione all'interno della latenza prevista di un'operazione di query, gli input al classificatore semantico vengono consolidati e ridotti in modo che il passaggio di riclassificazione possa essere completato il più rapidamente possibile.
La classificazione semantica prevede tre passaggi:
- Raccogliere e riepilogare gli input
- Assegnare un punteggio ai risultati usando il classificatore semantico
- Fornire un output che contiene risultati, didascalie e risposte a cui è stato assegnato nuovamente un punteggio
Come vengono raccolti e riepilogati gli input
Nella classificazione semantica, il sottosistema di query passa i risultati della ricerca come input ai modelli di riepilogo e classificazione. Poiché i modelli di classificazione hanno vincoli di dimensione di input e richiedono un utilizzo intensivo dell'elaborazione, i risultati della ricerca devono essere ridimensionati e strutturati (riepilogati) per una gestione efficiente.
Il classificatore semantico inizia con un risultato con classificazione BM25 da una query di testo o con un risultato con classificazione RRF da una query ibrida o vettoriale. Solo i campi di testo vengono usati nell'esercizio di riclassificazione e solo i primi 50 risultati avanzano alla classificazione semantica, anche se i risultati ne includono più di 50. In genere, i campi usati nella classificazione semantica sono informativi e descrittivi.
Per ogni documento nel risultato della ricerca, il modello di riepilogo accetta fino a 2.000 token, dove un token è di circa 10 caratteri. Gli input vengono assemblati dai campi "title", "keyword" e "content" elencati nella configurazione semantica.
Le stringhe eccessivamente lunghe vengono tagliate per garantire che la lunghezza complessiva soddisfi i requisiti di input del passaggio di riepilogo. Questo esercizio di taglio è il motivo per cui è importante aggiungere campi alla configurazione semantica in ordine di priorità. Se sono presenti documenti di dimensioni molto grandi con campi pieni di testo, qualsiasi elemento dopo il limite massimo viene ignorato.
Campo semantico Limite di token "title" 128 token "keywords 128 token "content" token rimanenti L'output di riepilogo è una stringa di riepilogo per ogni documento, composta dalle informazioni più rilevanti di ogni campo. Le stringhe di riepilogo vengono inviate al classificatore per l'assegnazione dei punteggi e ai modelli di comprensione della lettura automatica per sottotitoli e risposte.
A partire da novembre 2024, la lunghezza massima di ogni stringa di riepilogo generata passata al ranker semantico è di 2.048 token. In precedenza, erano 256 token.
Come viene ottenuto il punteggio della classificazione
L'assegnazione dei punteggi viene eseguita sulla didascalia e su qualsiasi altro contenuto della stringa di riepilogo che riempie la lunghezza del token di 2.048.
Le didascalie vengono valutate per pertinenza concettuale e semantica rispetto alla query fornita.
A ogni documento viene assegnato un @search.rerankerScore in base alla pertinenza semantica del documento per la query specificata. I punteggi vanno da 4 a 0 (alto e basso), dove un punteggio più alto indica una rilevanza maggiore.
Punteggio significato 4.0 Il documento è estremamente rilevante e risponde completamente alla domanda, anche se il passaggio potrebbe contenere testo aggiuntivo non correlato alla domanda. 3.0 Il documento è rilevante ma non contiene dettagli che lo renderebbero completo. 2.0 Il documento è piuttosto rilevante; risponde alla domanda parzialmente o solo ad alcuni aspetti. 1.0 Il documento è correlato alla domanda e risponde a una piccola parte di essa. 0.0 Il documento è irrilevante. Le corrispondenze vengono elencate in ordine decrescente in base al punteggio e incluse nel payload della risposta alla query. Il payload include risposte, testo normale e didascalie evidenziate e tutti i campi contrassegnati come recuperabili o specificati in una determinata clausola.
Nota
Per una determinata query, le distribuzioni di @search.rerankerScore possono presentare lievi variazioni a causa delle condizioni a livello di infrastruttura. Gli aggiornamenti del modello di classificazione sono noti anche per influire sulla distribuzione. Per questi motivi, se si scrive codice personalizzato per le soglie minime o si imposta la proprietà soglia per le query vettoriali e ibride, non rendere i limiti troppo granulari.
Output del classificatore semantico
Da ciascuna stringa di riepilogo, i modelli di comprensione di lettura computer trovano i passaggi più rappresentativi.
Gli output sono:
Una didascalia semantica per il documento. Ogni didascalia è disponibile in una versione di testo normale e in una versione di evidenziazione ed è spesso inferiore a 200 parole per ogni documento.
Una risposta semantica facoltativa, presupponendo che sia stato specificato il parametro
answers, che la query sia stata posta come domanda e che nella stringa lunga sia presente un passaggio che fornisce una risposta probabile alla domanda.
Le didascalie e le risposte sono sempre copiate parola per parola dall'indice. In questo flusso di lavoro non esiste alcun modello di intelligenza artificiale generativa che crea o compone nuovi contenuti.
Funzionalità e limitazioni semantiche
Il classificatore semantico è una tecnologia più recente, quindi è importante capire ciò che può e non può fare. Cosa può fare:
Alzare di livello le corrispondenze che sono semanticamente più vicine alla finalità della query originale.
Trovare le stringhe da usare come didascalie e risposte. Le didascalie e le risposte vengono restituite nella risposta e possono essere visualizzate in una pagina dei risultati della ricerca.
Il classificatore semantico non può eseguire di nuovo la query sull'intero corpus per trovare risultati semanticamente rilevanti. La classificazione semantica classifica il set di risultati esistente, costituito dai primi 50 risultati come segnati dall'algoritmo di classificazione predefinito. Inoltre, il classificatore semantico non può creare nuove informazioni o stringhe. I sottotitoli e le risposte vengono estratti parola per parola dal contenuto, quindi se i risultati non includono testo simile a una risposta, i modelli linguistici non ne produrranno uno.
Anche se la classificazione semantica non è utile in ogni scenario, alcuni contenuti possono trarre vantaggio in modo significativo dalle sue funzionalità. I modelli linguistici nel classificatore semantico funzionano meglio sul contenuto ricercabile, ricco di informazioni e strutturato come prosa. Una knowledge base, la documentazione online o i documenti che contengono contenuto descrittivo possono sfruttare al meglio le funzionalità del classificatore semantico.
La tecnologia sottostante proviene da Bing e Microsoft Research e si integra nell'infrastruttura di Azure AI Search come funzionalità aggiuntiva. Per altre informazioni sugli investimenti di ricerca e intelligenza artificiale che supportano il classificatore semantico, vedere Come l'IA di Bing sta migliorando Azure AI Search (Blog di ricerca Microsoft).
Il video seguente offre una panoramica delle funzionalità.
Disponibilità e prezzi
Il classificatore semantico è disponibile nei servizi di ricerca nei livelli Basic e superiore, a seconda della disponibilità a livello di area.
Quando si abilita il classificatore semantico, scegliere un piano tariffario per la funzionalità:
- Con volumi di query inferiori (inferiori a 1.000 mensili), la classificazione semantica è gratuita.
- In volumi di query superiori scegliere il piano tariffario standard.
La pagina Prezzi di Azure AI Search mostra la tariffa di fatturazione per valute e intervalli diversi.
Gli addebiti per il classificatore semantico vengono effettuati quando le richieste di query includono queryType=semantic e la stringa di ricerca non è vuota (ad esempio, search=pet friendly hotels in New York). Se la stringa di ricerca è vuota (search=*), non viene addebitato alcun costo, anche se queryType è impostato su semantico.
Come iniziare a usare il classificatore semantico
Accedere al portale di Azure per verificare se il servizio di ricerca sia Basic o un livello superiore.
Abilitare il classificatore semantico e scegliere un piano tariffario.
Configurare il classificatore semantico in un indice di ricerca.
Configurare le query per restituire didascalie semantiche ed evidenziazioni.