Esercitazione: Creare un analizzatore personalizzato per numeri di telefono
Nelle soluzioni di ricerca, le stringhe con modelli complessi o caratteri speciali possono essere difficili usare perché l'analizzatore predefinito rimuove o interpreta erroneamente parti significative di un modello, causando un'esperienza di ricerca scadente in cui gli utenti non riescono a trovare le informazioni desiderate. I numeri di telefono sono un esempio classico di stringhe difficili da analizzare. Sono disponibili in vari formati e includono caratteri speciali che vengono ignorati dall'analizzatore predefinito.
Con i numeri di telefono come oggetto, questa esercitazione esamina attentamente i problemi dei dati basati su modelli e illustra come risolverli usando un analizzatore personalizzato. L'approccio descritto qui può essere usato così com'è per numeri di telefono o adattato per campi con le stesse caratteristiche (con caratteri speciali), ad esempio URL, messaggi di posta elettronica, codici postali e date.
In questa esercitazione, si usano un client REST e le API REST di Azure AI Search per:
- Informazioni sul problema
- Sviluppare un analizzatore personalizzato iniziale per gestire numeri di telefono
- Testare l'analizzatore personalizzato
- Eseguire l'iterazione dell'analizzatore personalizzato per migliorare ulteriormente i risultati
Prerequisiti
Per questa esercitazione sono necessari i servizi e gli strumenti seguenti.
Visual Studio Code con un client REST.
Azure AI Search. Creare o trovare una risorsa di Azure AI Search esistente nella sottoscrizione corrente. È possibile usare un servizio gratuito per questo avvio rapido.
Scaricare i file
Il codice sorgente per questa esercitazione è il file custom-analyzer.rest nel repository GitHub Azure-Samples/azure-search-rest-samples.
Copiare una chiave e un URL
Le chiamate REST in questa esercitazione richiedono un endpoint del servizio di ricerca e una chiave API amministratore. È possibile ottenere questi valori dal portale di Azure.
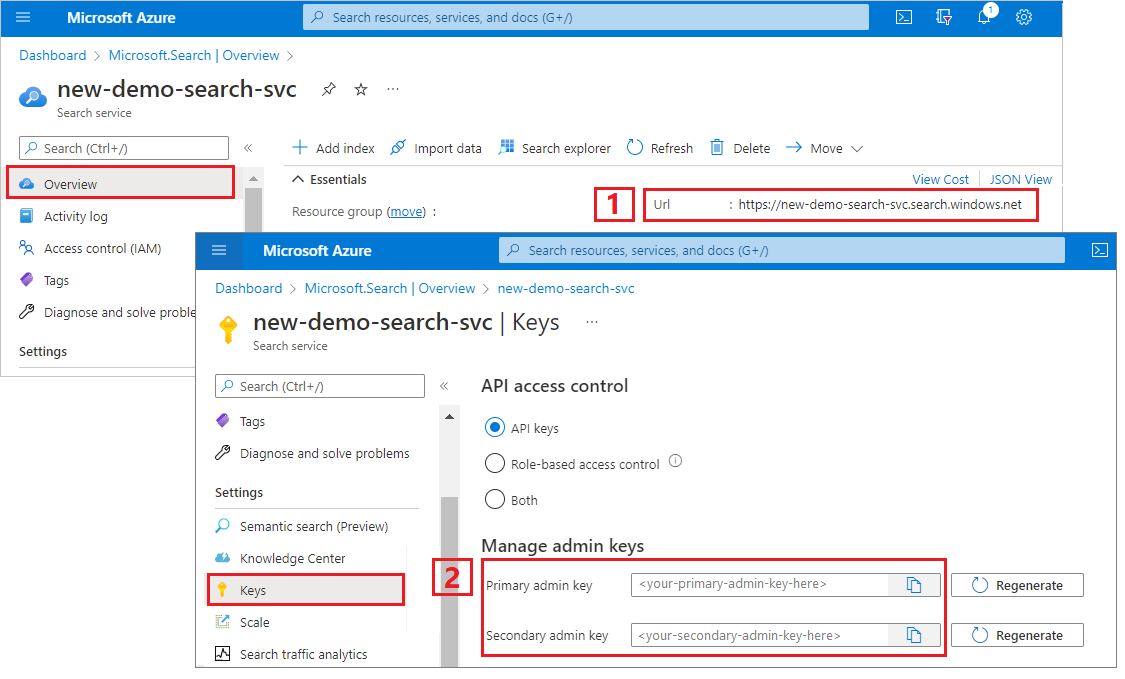
Accedere al portale di Azure, passare alla pagina Panoramica e copiare l'URL. Un endpoint di esempio potrebbe essere simile a
https://mydemo.search.windows.net.In Impostazioni>Chiavi, copiare una chiave amministratore. Le chiavi amministratore vengono usate per aggiungere, modificare ed eliminare oggetti. Sono disponibili due chiavi amministratore intercambiabili. Copiarne una.
La presenza di una chiave API valida stabilisce una relazione di trust, a livello di singole richieste, tra l'applicazione che invia la richiesta e il servizio di ricerca che la gestisce.
Creare un indice iniziale
Aprire un nuovo file di testo in Visual Studio Code.
Impostare le variabili sull'endpoint di ricerca e sulla chiave API ottenuta nel passaggio precedente.
@baseUrl = PUT-YOUR-SEARCH-SERVICE-URL-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERESalvare il file con un'estensione file
.rest.Incollare l'esempio seguente per creare un indice di piccole dimensioni denominato
phone-numbers-indexcon due campi:idephone_number. Non è ancora stato definito un analizzatore, quindi si userà l'analizzatorestandard.luceneper impostazione predefinita.### Create a new index POST {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "name": "phone-numbers-index", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "searchable": true, "filterable": false, "facetable": false, "sortable": true }, { "name": "phone_number", "type": "Edm.String", "sortable": false, "searchable": true, "filterable": false, "facetable": false } ] }Selezionare Invia richiesta. È necessario avere una risposta
HTTP/1.1 201 Createde il corpo della risposta deve includere la rappresentazione JSON dello schema dell'indice.Caricare dati nell'indice usando documenti che contengono vari formati di numero di telefono. Si tratta di dati di test.
### Load documents POST {{baseUrl}}/indexes/phone-numbers-index/docs/index?api-version=2024-07-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "value": [ { "@search.action": "upload", "id": "1", "phone_number": "425-555-0100" }, { "@search.action": "upload", "id": "2", "phone_number": "(321) 555-0199" }, { "@search.action": "upload", "id": "3", "phone_number": "+1 425-555-0100" }, { "@search.action": "upload", "id": "4", "phone_number": "+1 (321) 555-0199" }, { "@search.action": "upload", "id": "5", "phone_number": "4255550100" }, { "@search.action": "upload", "id": "6", "phone_number": "13215550199" }, { "@search.action": "upload", "id": "7", "phone_number": "425 555 0100" }, { "@search.action": "upload", "id": "8", "phone_number": "321.555.0199" } ] }Si proverà ora a eseguire alcune query simili a quanto un utente potrebbe digitare. Un utente potrebbe cercare
(425) 555-0100in un numero qualsiasi di formati e aspettarsi comunque che vengano restituiti risultati. Per iniziare, cercare(425) 555-0100:### Search for a phone number GET {{baseUrl}}/indexes/phone-numbers-index/docs/search?api-version=2024-07-01&search=(425) 555-0100 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}}La query restituisce tre dei quattro risultati previsti, ma anche due risultati imprevisti:
{ "value": [ { "@search.score": 0.05634898, "phone_number": "+1 425-555-0100" }, { "@search.score": 0.05634898, "phone_number": "425 555 0100" }, { "@search.score": 0.05634898, "phone_number": "425-555-0100" }, { "@search.score": 0.020766128, "phone_number": "(321) 555-0199" }, { "@search.score": 0.020766128, "phone_number": "+1 (321) 555-0199" } ] }Riprovare senza alcuna formattazione:
4255550100.### Search for a phone number GET {{baseUrl}}/indexes/phone-numbers-index/docs/search?api-version=2024-07-01&search=4255550100 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}}Le prestazioni di questa query sono ancora peggiori, dato che restituisce solo una delle quattro corrispondenze corrette.
{ "value": [ { "@search.score": 0.6015292, "phone_number": "4255550100" } ] }
Questi risultati possono creare confusione. Nella prossima sezione si esamineranno i motivi per cui si ottengono questi risultati.
Esaminare il funzionamento degli analizzatori
Per comprendere questi risultati di ricerca, è necessario comprendere il funzionamento dell'analizzatore. Dopo di che, sarà possibile testare l'analizzatore predefinito usando l'API Analizza, fornendo le basi per la progettazione di un analizzatore che soddisfi meglio le esigenze.
Un analizzatore è un componente del motore di ricerca full-text responsabile dell'elaborazione di testo in stringhe di query e documenti indicizzati. Analizzatori diversi modificano il testo in modi diversi a seconda dello scenario. Per questo scenario è necessario creare un analizzatore mirato per i numeri di telefono.
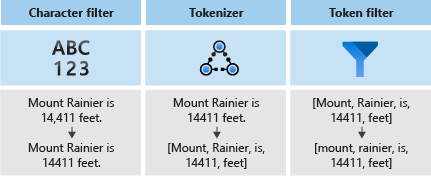
Gli analizzatori sono costituiti da tre componenti:
- I filtri di caratteri che consentono di rimuovere o sostituire singoli caratteri dal testo di input.
- Un tokenizer che suddivide il testo di input in token, che diventano chiavi nell'indice di ricerca.
- I filtri di token che modificano i token generati dal tokenizer.
Nel diagramma seguente si può notare come questi tre componenti interagiscono tra loro per suddividere una frase in token:
Questi token vengono quindi archiviati in un indice invertito, che consente ricerche full-text rapide. Un indice invertito abilita la ricerca full-text eseguendo il mapping di tutti i termini univoci estratti durante l'analisi lessicale ai documenti che li contengono. Il diagramma seguente ne illustra un esempio:

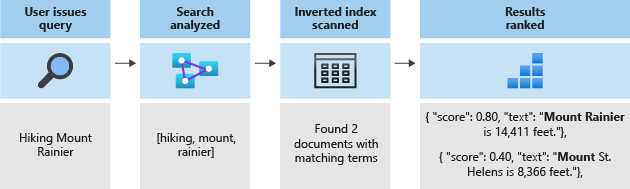
L'intero processo di ricerca consiste nel cercare i termini archiviati nell'indice invertito. Quando un utente esegue una query:
- La query viene analizzata, così come i termini della query.
- Viene quindi eseguita la scansione dell'indice invertito alla ricerca di documenti contenenti termini corrispondenti.
- Infine, i documenti recuperati vengono classificati in base all'algoritmo di punteggio.
Se i termini della query non corrispondono a quelli nell'indice invertito, non vengono restituiti risultati. Per altre informazioni sul funzionamento delle query, vedere questo articolo sulla ricerca full-text.
Nota
Le query con termini parziali sono un'importante eccezione a questa regola. Queste query (query con prefisso, query con caratteri jolly, query espressione regolare), a differenza delle query di termini normali, ignorano il processo di analisi lessicale. I termini parziali sono solo in minuscolo prima di essere confrontati con i termini nell'indice. Se un analizzatore non è configurato per supportare questi tipi di query, si riceveranno spesso risultati imprevisti perché i termini corrispondenti non esistono nell'indice.
Analizzatori di test che usano l'API Analizza
Azure AI Search fornisce un'API Analizza che consente di testare gli analizzatori per comprendere il modo in cui elaborano il testo.
L'API Analizza viene chiamata tramite la richiesta seguente:
POST {{baseUrl}}/indexes/phone-numbers-index/analyze?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"text": "(425) 555-0100",
"analyzer": "standard.lucene"
}
L'API restituisce i token estratti dal testo usando l'analizzatore specificato. L'analizzatore Lucene standard suddivide il numero di telefono in tre token distinti:
{
"tokens": [
{
"token": "425",
"startOffset": 1,
"endOffset": 4,
"position": 0
},
{
"token": "555",
"startOffset": 6,
"endOffset": 9,
"position": 1
},
{
"token": "0100",
"startOffset": 10,
"endOffset": 14,
"position": 2
}
]
}
Il numero di telefono 4255550100 formattato senza punteggiatura viene invece tokenizzato in un singolo token.
{
"text": "4255550100",
"analyzer": "standard.lucene"
}
Risposta:
{
"tokens": [
{
"token": "4255550100",
"startOffset": 0,
"endOffset": 10,
"position": 0
}
]
}
Tenere presente che vengono analizzati sia i termini della query che i documenti indicizzati. Ripensando ai risultati della ricerca del passaggio precedente, si può iniziare a capire perché vengono restituiti questi risultati.
Nella prima query sono stati restituiti numeri di telefono imprevisti perché uno dei relativi token, 555, corrispondeva a uno dei termini cercati. Nella seconda query è stato restituito solo un numero, poiché era l'unico record ad avere un token corrispondente a 4255550100.
Creare un analizzatore personalizzato
Ora che i risultati restituiti non sono più un mistero, è il momento di creare un analizzatore personalizzato per migliorare la logica di tokenizzazione.
L'obiettivo è fornire una ricerca intuitiva dei numeri di telefono, indipendentemente dal formato della query o della stringa indicizzata. Per ottenere questo risultato, si specificherà un filtro di caratteri, un tokenizer e un filtro di token.
Filtri di caratteri
I filtri di caratteri vengono usati per elaborare il testo prima di inserirlo nel tokenizer. Gli utilizzi comuni dei filtri di caratteri includono l'esclusione di elementi HTML o la sostituzione di caratteri speciali.
Per i numeri di telefono occorre rimuovere gli spazi vuoti e i caratteri speciali perché non tutti i formati dei numeri di telefono contengono gli stessi spazi e caratteri speciali.
"charFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.MappingCharFilter",
"name": "phone_char_mapping",
"mappings": [
"-=>",
"(=>",
")=>",
"+=>",
".=>",
"\\u0020=>"
]
}
]
Il filtro rimuovei -()+. e spazi e dall'input.
| Input | Output |
|---|---|
(321) 555-0199 |
3215550199 |
321.555.0199 |
3215550199 |
Tokenizer
I tokenizer suddividono il testo in token eliminando al contempo alcuni caratteri, ad esempio la punteggiatura. In molti casi, l'obiettivo della tokenizzazione è suddividere una frase in singole parole.
Per questo scenario si userà un tokenizer di parole chiave, keyword_v2, perché si vuole acquisire il numero di telefono come singolo termine. Si noti che questo non è l'unico modo per risolvere il problema. Vedere la sezione Approcci alternativi di seguito.
I tokenizer di parole chiave generano sempre lo stesso testo fornito come singolo termine.
| Input | Output |
|---|---|
The dog swims. |
[The dog swims.] |
3215550199 |
[3215550199] |
Filtri di token
I filtri di token vengono usati per filtrare o modificare i token generati dal tokenizer. Vengono comunemente usati anche per convertire in minuscolo tutti i caratteri Un altro uso comune consiste nel filtrare parole non significative, ad esempio the, and o is.
Sebbene non sia necessario usare questi filtri per questo scenario, verrà usato un filtro token nGram per consentire ricerche parziali dei numeri di telefono.
"tokenFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.NGramTokenFilterV2",
"name": "custom_ngram_filter",
"minGram": 3,
"maxGram": 20
}
]
NGramTokenFilterV2
Il filtro di token nGram_v2 suddivide i token in n-grammi di una determinata dimensione in base ai parametri minGram e maxGram.
Per l'analizzatore dei numeri di telefono, minGram viene impostato su 3 perché è la sottostringa più corta che si prevede venga cercata dagli utenti. maxGram viene impostato su 20 per assicurare che tutti i numeri di telefono, anche quelli comprensivi di numero interno, rientrino in un singolo n-gramma.
Il lato negativo degli n-grammi è che vengono restituiti anche alcuni falsi positivi. Questo problema verrà risolto in un passaggio successivo creando un analizzatore distinto per ricerche che non includono il filtro di token di n-gram.
| Input | Output |
|---|---|
[12345] |
[123, 1234, 12345, 234, 2345, 345] |
[3215550199] |
[321, 3215, 32155, 321555, 3215550, 32155501, 321555019, 3215550199, 215, 2155, 21555, 215550, ... ] |
Analizzatore
Una volta predisposti i filtri di caratteri, il tokenizer e i filtri di token, è possibile definire l'analizzatore.
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer",
"tokenizer": "keyword_v2",
"tokenFilters": [
"custom_ngram_filter"
],
"charFilters": [
"phone_char_mapping"
]
}
]
Dall'API Analizza, dati gli input seguenti, gli output dell'analizzatore personalizzato sono illustrati nella tabella seguente.
| Input | Output |
|---|---|
12345 |
[123, 1234, 12345, 234, 2345, 345] |
(321) 555-0199 |
[321, 3215, 32155, 321555, 3215550, 32155501, 321555019, 3215550199, 215, 2155, 21555, 215550, ... ] |
Tutti i token nella colonna di output sono presenti nell'indice. Se la query include uno qualsiasi di questi termini, viene restituito il numero di telefono.
Ricompilare usando il nuovo analizzatore
Eliminare l'indice corrente:
### Delete the index DELETE {{baseUrl}}/indexes/phone-numbers-index?api-version=2024-07-01 HTTP/1.1 api-key: {{apiKey}}Ricreare l'indice usando il nuovo analizzatore. Questo schema di indice aggiunge una definizione dell'analizzatore personalizzata e un'assegnazione di analizzatore personalizzata nel campo numero di telefono.
### Create a new index POST {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "name": "phone-numbers-index-2", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "searchable": true, "filterable": false, "facetable": false, "sortable": true }, { "name": "phone_number", "type": "Edm.String", "sortable": false, "searchable": true, "filterable": false, "facetable": false, "analyzer": "phone_analyzer" } ], "analyzers": [ { "@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer", "name": "phone_analyzer", "tokenizer": "keyword_v2", "tokenFilters": [ "custom_ngram_filter" ], "charFilters": [ "phone_char_mapping" ] } ], "charFilters": [ { "@odata.type": "#Microsoft.Azure.Search.MappingCharFilter", "name": "phone_char_mapping", "mappings": [ "-=>", "(=>", ")=>", "+=>", ".=>", "\\u0020=>" ] } ], "tokenFilters": [ { "@odata.type": "#Microsoft.Azure.Search.NGramTokenFilterV2", "name": "custom_ngram_filter", "minGram": 3, "maxGram": 20 } ] }
Testare l'analizzatore personalizzato
Dopo aver ricreato l'indice, è ora possibile testare l'analizzatore usando la richiesta seguente:
POST {{baseUrl}}/indexes/tutorial-first-analyzer/analyze?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"text": "+1 (321) 555-0199",
"analyzer": "phone_analyzer"
}
A questo punto, si dovrebbe visualizzare la raccolta di token risultanti dal numero di telefono:
{
"tokens": [
{
"token": "132",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
{
"token": "1321",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
{
"token": "13215",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
...
...
...
]
}
Rivedere l'analizzatore personalizzato per gestire i falsi positivi
Dopo aver eseguito alcune query di esempio sull'indice con l'analizzatore personalizzato, si noterà che il richiamo è migliorato e tutti i numeri di telefono corrispondenti vengono ora restituiti. Tuttavia, il filtro di token di n-gramma causa anche la restituzione di alcuni falsi positivi. È un effetto collaterale comune di questo tipo di filtro.
Per evitare falsi positivi, verrà creato un analizzatore distinto per l'esecuzione di query. Questo analizzatore è identico a quello precedente, ad eccezione del fatto che omette il custom_ngram_filter.
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer_search",
"tokenizer": "custom_tokenizer_phone",
"tokenFilters": [],
"charFilters": [
"phone_char_mapping"
]
}
Nella definizione dell'indice si specificherà quindi sia indexAnalyzer che searchAnalyzer.
{
"name": "phone_number",
"type": "Edm.String",
"sortable": false,
"searchable": true,
"filterable": false,
"facetable": false,
"indexAnalyzer": "phone_analyzer",
"searchAnalyzer": "phone_analyzer_search"
}
Dopo questa modifica, è tutto pronto. Di seguito sono elencati i passaggi successivi:
Eliminare l'indice.
Ricreare l'indice dopo aver aggiunto il nuovo analizzatore personalizzato (
phone_analyzer-search) e averlo assegnati alla proprietàphone-numberdel camposearchAnalyzer.Ricaricare i dati.
Testare nuovamente le query per verificare che la ricerca funzioni come previsto. Se si sta usando il file campione, questo passaggio crea il terzo indice denominato
phone-number-index-3.
Approcci alternativi
L'analizzatore descritto nella sezione precedente è progettato per ottimizzare la flessibilità per la ricerca. Il costo di questo risultato è però l'archiviazione di molti termini potenzialmente irrilevanti nell'indice.
L'esempio seguente mostra un analizzatore alternativo più efficiente nella tokenizzazione, ma che presenta svantaggi.
Dato un input di 14255550100, l'analizzatore non può suddividere logicamente in blocchi il numero di telefono. Ad esempio, non può separare il prefisso internazionale, 1, dal prefisso della località, 425. A causa di questa discrepanza, il numero di telefono riportato sopra non verrebbe restituito se l'utente non includesse il prefisso internazionale nella ricerca.
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer_shingles",
"tokenizer": "custom_tokenizer_phone",
"tokenFilters": [
"custom_shingle_filter"
]
}
],
"tokenizers": [
{
"@odata.type": "#Microsoft.Azure.Search.StandardTokenizerV2",
"name": "custom_tokenizer_phone",
"maxTokenLength": 4
}
],
"tokenFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.ShingleTokenFilter",
"name": "custom_shingle_filter",
"minShingleSize": 2,
"maxShingleSize": 6,
"tokenSeparator": ""
}
]
Nell'esempio seguente, il numero di telefono è suddiviso nei blocchi che si prevede vengano generalmente cercati dall'utente.
| Input | Output |
|---|---|
(321) 555-0199 |
[321, 555, 0199, 321555, 5550199, 3215550199] |
A seconda delle esigenze, questo può essere una soluzione più efficiente al problema.
Risultati
Questa esercitazione ha illustrato il processo di compilazione e test di un analizzatore personalizzato. È stato creato un indice, sono stati indicizzati i dati e quindi è stata eseguita una query sull'indice per controllare i risultati della ricerca restituiti. Successivamente, è stata usata l'API Analizza per vedere il processo di analisi lessicale in azione.
Sebbene l'analizzatore definito in questa esercitazione offra una soluzione semplice per la ricerca di numeri di telefono, questo stesso processo può essere usato per creare un analizzatore personalizzato per qualsiasi scenario con caratteristiche simili.
Pulire le risorse
Quando si lavora nella propria sottoscrizione, una volta terminato un progetto è opportuno rimuovere le risorse che non sono più necessarie. Le risorse che rimangono in esecuzione hanno un costo. È possibile eliminare risorse singole oppure gruppi di risorse per eliminare l'intero set di risorse.
È possibile trovare e gestire le risorse nella portale di Azure, usando il collegamento Tutte le risorse o Gruppi di risorse nel riquadro di spostamento a sinistra.
Passaggi successivi
Ora che si è appreso come creare un analizzatore personalizzato, si può passare ad esaminare tutti i diversi filtri, tokenizer e analizzatori disponibili per creare un'esperienza di ricerca avanzata.