Convalida dell'input nelle query di Analisi di flusso di Azure
La convalida dell'input è una tecnica da usare per proteggere la logica di query principale da eventi in formato non valido o imprevisto. La query viene aggiornata per elaborare in modo esplicito e controllare i record in modo che non possano interrompere la logica principale.
Per implementare la convalida dell'input, si aggiungono due passaggi iniziali a una query. Assicurarsi prima di tutto che lo schema inviato alla logica di business di base corrisponda alle aspettative. Le eccezioni vengono quindi valutate e, facoltativamente, instradano record non validi in un output secondario.
Una query con convalida di input sarà strutturata nel modo seguente:
WITH preProcessingStage AS (
SELECT
-- Rename incoming fields, used for audit and debugging
field1 AS in_field1,
field2 AS in_field2,
...
-- Try casting fields in their expected type
TRY_CAST(field1 AS bigint) as field1,
TRY_CAST(field2 AS array) as field2,
...
FROM myInput TIMESTAMP BY myTimestamp
),
triagedOK AS (
SELECT -- Only fields in their new expected type
field1,
field2,
...
FROM preProcessingStage
WHERE ( ... ) -- Clauses make sure that the core business logic expectations are satisfied
),
triagedOut AS (
SELECT -- All fields to ease diagnostic
*
FROM preProcessingStage
WHERE NOT (...) -- Same clauses as triagedOK, opposed with NOT
)
-- Core business logic
SELECT
...
INTO myOutput
FROM triagedOK
...
-- Audit output. For human review, correction, and manual re-insertion downstream
SELECT
*
INTO BlobOutput -- To a storage adapter that doesn't require strong typing, here blob/adls
FROM triagedOut
Per un esempio completo di una query configurata con la convalida dell'input, vedere la sezione: Esempio di query con convalida di input.
Questo articolo illustra come implementare questa tecnica.
Contesto
I processi di Analisi di flusso di Azure elaborano i dati provenienti da flussi. Flussi sono sequenze di dati non elaborati trasmessi serializzati (CSV, JSON, AVRO...). Per leggere da un flusso, un'applicazione dovrà conoscere il formato di serializzazione specifico usato. In ASA il formato di serializzazione degli eventi deve essere definito durante la configurazione di un input di streaming.
Una volta deserializzati i dati, è necessario applicare uno schema per dare un significato. Per schema si intende l'elenco dei campi nel flusso e i rispettivi tipi di dati. Con ASA, lo schema dei dati in ingresso non deve essere impostato a livello di input. AsA supporta invece schemi di input dinamici in modo nativo. Si prevede che l'elenco di campi (colonne) e i relativi tipi cambino tra eventi (righe). AsA dedurrà anche i tipi di dati quando non viene fornito in modo esplicito e tenterà di eseguire il cast implicito dei tipi quando necessario.
La gestione dinamica dello schema è una funzionalità potente, fondamentale per l'elaborazione dei flussi. I flussi di dati spesso contengono dati provenienti da più origini, con più tipi di evento, ognuno con uno schema univoco. Per instradare, filtrare ed elaborare eventi su tali flussi, ASA deve inserirli tutti in qualsiasi schema.
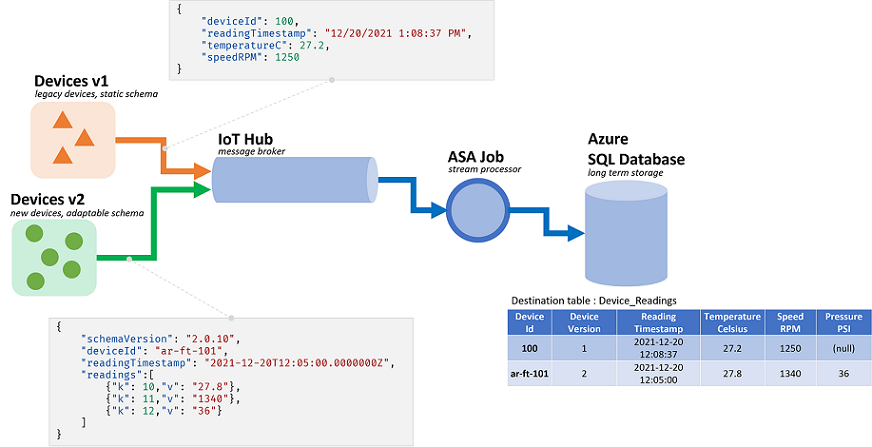
Tuttavia, le funzionalità offerte dalla gestione dinamica dello schema presentano un potenziale svantaggio. Gli eventi imprevisti possono scorrere la logica di query principale e interromperla. Ad esempio, è possibile usare ROUND in un campo di tipo NVARCHAR(MAX). ASA eseguirà il cast implicito in float in modo che corrisponda alla firma di ROUND. In questo caso, o speriamo, questo campo conterrà sempre valori numerici. Tuttavia, quando si riceve un evento con il campo impostato su "NaN"o se il campo è completamente mancante, il processo potrebbe non riuscire.
Con la convalida dell'input, si aggiungono passaggi preliminari alla query per gestire tali eventi in formato non valido. Useremo principalmente WITH e TRY_CAST per implementarlo.
Scenario: convalida dell'input per produttori di eventi non affidabili
Verrà creato un nuovo processo ASA che inserisce i dati da un singolo hub eventi. Come accade più spesso, non siamo responsabili dei produttori di dati. Qui i produttori sono dispositivi IoT venduti da più fornitori di hardware.
L'incontro con gli stakeholder è d'accordo su un formato di serializzazione e uno schema. Tutti i dispositivi eseguiranno il push di tali messaggi in un hub eventi comune, input del processo ASA.
Il contratto dello schema è definito come segue:
| Nome del campo | Tipo di campo | Descrizione campo |
|---|---|---|
deviceId |
Intero | Identificatore univoco del dispositivo |
readingTimestamp |
Datetime | Ora del messaggio, generata da un gateway centrale |
readingStr |
String | |
readingNum |
Numerico | |
readingArray |
Matrice di stringhe |
Che a sua volta fornisce il messaggio di esempio seguente nella serializzazione JSON:
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7,
"readingArray" : ["A","B"]
}
È già possibile riscontrare una discrepanza tra il contratto dello schema e la relativa implementazione. Nel formato JSON non esiste alcun tipo di dati per datetime. Verrà trasmesso come stringa (vedere sopra readingTimestamp ). AsA può risolvere facilmente il problema, ma mostra la necessità di convalidare ed eseguire il cast esplicito dei tipi. Inoltre, per i dati serializzati in CSV, poiché tutti i valori vengono quindi trasmessi come stringa.
C'è un'altra discrepanza. AsA usa il proprio sistema di tipi che non corrisponde a quello in ingresso. Se ASA include tipi predefiniti per integer (bigint), datetime, string (nvarchar(max)) e matrici, supporta solo numeri tramite float. Questa mancata corrispondenza non è un problema per la maggior parte delle applicazioni. Ma in alcuni casi limite, potrebbe causare lievi deviazioni in precisione. In questo caso, il valore numerico verrà convertito come stringa in un nuovo campo. A valle si userà quindi un sistema che supporta decimale fisso per rilevare e correggere le potenziali deviazioni.
Tornare alla query, in questo caso si prevede di:
- Passare
readingStra una funzione definita dall'utente JavaScript - Contare il numero di record nella matrice
- Arrotondare
readingNumalla seconda posizione decimale - Inserire i dati in una tabella SQL
La tabella SQL di destinazione ha lo schema seguente:
CREATE TABLE [dbo].[readings](
[Device_Id] int NULL,
[Reading_Timestamp] datetime2(7) NULL,
[Reading_String] nvarchar(200) NULL,
[Reading_Num] decimal(18,2) NULL,
[Array_Count] int NULL
) ON [PRIMARY]
È consigliabile eseguire il mapping di ciò che accade a ogni campo mentre passa attraverso il processo:
| Campo | Input (JSON) | Tipo ereditato (ASA) | Output (SQL di Azure) | Commento |
|---|---|---|---|---|
deviceId |
number | bigint | integer | |
readingTimestamp |
string | nvarchar(MAX) | datetime2 | |
readingStr |
string | nvarchar(MAX) | nvarchar(200) | usato dalla funzione definita dall'utente |
readingNum |
number | float | decimal(18,2) | da arrotondare |
readingArray |
array(string) | matrice di nvarchar(MAX) | integer | da contare |
Prerequisiti
La query verrà sviluppata in Visual Studio Code usando l'estensione ASA Tools . I primi passaggi di questa esercitazione illustrano l'installazione dei componenti necessari.
In VS Code si useranno esecuzioni locali con input/output locale per non sostenere alcun costo e velocizzare il ciclo di debug. Non è necessario configurare un hub eventi o un database SQL di Azure.
Query di base
Si inizierà con un'implementazione di base, senza convalida di input. Verrà aggiunto nella sezione successiva.
In VS Code verrà creato un nuovo progetto ASA
input Nella cartella verrà creato un nuovo file JSON denominato data_readings.json e verranno aggiunti i record seguenti:
[
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7145,
"readingArray" : ["A","B"]
},
{
"deviceId" : 2,
"readingTimestamp" : "2021-12-10T10:01:00",
"readingStr" : "Another String",
"readingNum" : 2.378,
"readingArray" : ["C"]
},
{
"deviceId" : 3,
"readingTimestamp" : "2021-12-10T10:01:20",
"readingStr" : "A Third String",
"readingNum" : -4.85436,
"readingArray" : ["D","E","F"]
},
{
"deviceId" : 4,
"readingTimestamp" : "2021-12-10T10:02:10",
"readingStr" : "A Forth String",
"readingNum" : 1.2126,
"readingArray" : ["G","G"]
}
]
Si definirà quindi un input locale, denominato readings, che fa riferimento al file JSON creato in precedenza.
Dopo la configurazione dovrebbe essere simile al seguente:
{
"InputAlias": "readings",
"Type": "Data Stream",
"Format": "Json",
"FilePath": "data_readings.json",
"ScriptType": "InputMock"
}
Con i dati di anteprima, è possibile osservare che i record vengono caricati correttamente.
Verrà creata una nuova funzione definita dall'utente JavaScript denominata udfLen facendo clic con il pulsante destro del mouse sulla Functions cartella e selezionando ASA: Add Function. Il codice che verrà usato è:
// Sample UDF that returns the length of a string for demonstration only: LEN will return the same thing in ASAQL
function main(arg1) {
return arg1.length;
}
Nelle esecuzioni locali non è necessario definire gli output. Non è nemmeno necessario usare INTO a meno che non siano presenti più output. .asaql Nel file è possibile sostituire la query esistente con:
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
FROM readings AS r TIMESTAMP BY r.readingTimestamp
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
Esaminiamo rapidamente la query inviata:
- Per contare il numero di record in ogni matrice, è prima necessario decomprimerli. Useremo CROSS APPLY e GetArrayElements() (altri esempi qui)
- In questo modo vengono visualizzati due set di dati nella query: l'input originale e i valori della matrice. Per assicurarsi di non combinare i campi, definiamo gli alias (
AS r) e li usiamo ovunque - Quindi, per effettivamente
COUNTi valori della matrice, è necessario aggregare con GROUP BY - Per questo dobbiamo definire un intervallo di tempo. In questo caso, poiché non è necessario uno per la logica, la finestra snapshot è la scelta giusta
- In questo modo vengono visualizzati due set di dati nella query: l'input originale e i valori della matrice. Per assicurarsi di non combinare i campi, definiamo gli alias (
- È anche necessario tutti
GROUP BYi campi e proiettarli tutti inSELECT. La proiezione esplicita dei campi è una procedura consigliata, in quantoSELECT *consente il flusso degli errori dall'input all'output- Se si definisce un intervallo di tempo, è possibile definire un timestamp con TIMESTAMP BY. In questo caso non è necessario che la logica funzioni. Per le esecuzioni locali, senza
TIMESTAMP BYtutti i record vengono caricati in un singolo timestamp, l'ora di inizio dell'esecuzione.
- Se si definisce un intervallo di tempo, è possibile definire un timestamp con TIMESTAMP BY. In questo caso non è necessario che la logica funzioni. Per le esecuzioni locali, senza
- La funzione definita dall'utente viene usata per filtrare le letture con
readingStrmeno di due caratteri. Avremmo dovuto usare LEN qui. Viene usata una funzione definita dall'utente solo a scopo dimostrativo
È possibile avviare un'esecuzione e osservare i dati elaborati:
| deviceId | readingTimestamp | readingStr | readingNum | arrayCount |
|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00 | Valore stringa | 1,71 | 2 |
| 2 | 2021-12-10T10:01:00 | Un'altra stringa | 2,38 | 1 |
| 3 | 2021-12-10T10:01:20 | Una terza stringa | -4.85 | 3 |
| 1 | 2021-12-10T10:02:10 | Stringa in avanti | 1.21 | 2 |
Ora che si sa che la query funziona, è possibile testarla su più dati. Sostituire il contenuto di data_readings.json con i record seguenti:
[
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7145,
"readingArray" : ["A","B"]
},
{
"deviceId" : 2,
"readingTimestamp" : "2021-12-10T10:01:00",
"readingNum" : 2.378,
"readingArray" : ["C"]
},
{
"deviceId" : 3,
"readingTimestamp" : "2021-12-10T10:01:20",
"readingStr" : "A Third String",
"readingNum" : "NaN",
"readingArray" : ["D","E","F"]
},
{
"deviceId" : 4,
"readingTimestamp" : "2021-12-10T10:02:10",
"readingStr" : "A Forth String",
"readingNum" : 1.2126,
"readingArray" : {}
}
]
Ecco i problemi seguenti:
- Il dispositivo n. 1 ha fatto tutto bene
- Dispositivo n. 2 dimenticato di includere un
readingStr - Dispositivo n. 3 inviato
NaNcome numero - Il dispositivo n. 4 ha inviato un record vuoto anziché una matrice
L'esecuzione del processo non dovrebbe terminare correttamente. Verrà visualizzato uno dei messaggi di errore seguenti:
Il dispositivo 2 ci darà:
[Error] 12/22/2021 10:05:59 PM : **System Exception** Function 'udflen' resulted in an error: 'TypeError: Unable to get property 'length' of undefined or null reference' Stack: TypeError: Unable to get property 'length' of undefined or null reference at main (Unknown script code:3:5)
[Error] 12/22/2021 10:05:59 PM : at Microsoft.EventProcessing.HostedRuntimes.JavaScript.JavaScriptHostedFunctionsRuntime.
Il dispositivo 3 ci darà:
[Error] 12/22/2021 9:52:32 PM : **System Exception** The 1st argument of function round has invalid type 'nvarchar(max)'. Only 'bigint', 'float' is allowed.
[Error] 12/22/2021 9:52:32 PM : at Microsoft.EventProcessing.SteamR.Sql.Runtime.Arithmetics.Round(CompilerPosition pos, Object value, Object length)
Il dispositivo 4 ci darà:
[Error] 12/22/2021 9:50:41 PM : **System Exception** Cannot cast value of type 'record' to type 'array' in expression 'r . readingArray'. At line '9' and column '30'. TRY_CAST function can be used to handle values with unexpected type.
[Error] 12/22/2021 9:50:41 PM : at Microsoft.EventProcessing.SteamR.Sql.Runtime.Cast.ToArray(CompilerPosition pos, Object value, Boolean isUserCast)
Ogni volta che i record in formato non valido sono stati autorizzati a passare dall'input alla logica di query principale senza essere convalidati. Ora ci rendiamo conto del valore della convalida dell'input.
Implementazione della convalida dell'input
Estendere la query per convalidare l'input.
Il primo passaggio della convalida dell'input consiste nel definire le aspettative dello schema della logica di business di base. Esaminando il requisito originale, la logica principale consiste nel:
- Passare
readingStra una funzione definita dall'utente JavaScript per misurarne la lunghezza - Contare il numero di record nella matrice
- Arrotondare
readingNumalla seconda posizione decimale - Inserire i dati in una tabella SQL
Per ogni punto è possibile elencare le aspettative:
- La funzione definita dall'utente richiede un argomento di tipo string (nvarchar(max) qui) che non può essere null
GetArrayElements()richiede un argomento di matrice di tipi o un valore NullRoundrichiede un argomento di tipo bigint o float o un valore Null- Invece di basarsi sul cast implicito di ASA, è consigliabile eseguire questa operazione e gestire i conflitti di tipo nella query
Un modo per procedere consiste nell'adattare la logica principale per gestire queste eccezioni. Ma in questo caso, crediamo che la nostra logica principale sia perfetta. Si convaliderà invece i dati in ingresso.
Prima di tutto, si userà WITH per aggiungere un livello di convalida di input come primo passaggio della query. Si userà TRY_CAST per convertire i campi nel tipo previsto e impostarli su NULL se la conversione non riesce:
WITH readingsValidated AS (
SELECT
-- Rename incoming fields, used for audit and debugging
deviceId AS in_deviceId,
readingTimestamp AS in_readingTimestamp,
readingStr AS in_readingStr,
readingNum AS in_readingNum,
readingArray AS in_readingArray,
-- Try casting fields in their expected type
TRY_CAST(deviceId AS bigint) as deviceId,
TRY_CAST(readingTimestamp AS datetime) as readingTimestamp,
TRY_CAST(readingStr AS nvarchar(max)) as readingStr,
TRY_CAST(readingNum AS float) as readingNum,
TRY_CAST(readingArray AS array) as readingArray
FROM readings TIMESTAMP BY readingTimestamp
)
-- For debugging only
SELECT * FROM readingsValidated
Con l'ultimo file di input usato (quello con errori), questa query restituirà il set seguente:
| in_deviceId | in_readingTimestamp | in_readingStr | in_readingNum | in_readingArray | deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00 | Valore stringa | 1.7145 | ["A","B"] | 1 | 2021-12-10T10:00:00.0000000Z | Valore stringa | 1.7145 | ["A","B"] |
| 2 | 2021-12-10T10:01:00 | NULL | 2.378 | ["C"] | 2 | 2021-12-10T10:01:00.0000000Z | NULL | 2.378 | ["C"] |
| 3 | 2021-12-10T10:01:20 | Una terza stringa | NaN | ["D","E","F"] | 3 | 2021-12-10T10:01:20.0000000Z | Una terza stringa | NULL | ["D","E","F"] |
| 4 | 2021-12-10T10:02:10 | Stringa in avanti | 1.2126 | {} | 4 | 2021-12-10T10:02:10.0000000Z | Stringa in avanti | 1.2126 | NULL |
È già possibile vedere due degli errori risolti. Abbiamo trasformato NaN e {} in NULL. Ora si è certi che questi record verranno inseriti correttamente nella tabella SQL di destinazione.
A questo punto è necessario decidere come gestire i record con valori mancanti o non validi. Dopo alcune discussioni, si decide di rifiutare i record con un valore vuoto/non valido readingArray o mancante readingStr.
Si aggiunge quindi un secondo livello che valuta i record tra la convalida 1 e la logica principale:
WITH readingsValidated AS (
...
),
readingsToBeProcessed AS (
SELECT
deviceId,
readingTimestamp,
readingStr,
readingNum,
readingArray
FROM readingsValidated
WHERE
readingStr IS NOT NULL
AND readingArray IS NOT NULL
),
readingsToBeRejected AS (
SELECT
*
FROM readingsValidated
WHERE -- Same clauses as readingsToBeProcessed, opposed with NOT
NOT (
readingStr IS NOT NULL
AND readingArray IS NOT NULL
)
)
-- For debugging only
SELECT * INTO Debug1 FROM readingsToBeProcessed
SELECT * INTO Debug2 FROM readingsToBeRejected
È consigliabile scrivere una singola WHERE clausola per entrambi gli output e usarla NOT (...) nella seconda. In questo modo non è possibile escludere record da output e persi.
Ora si ottengono due output. Debug1 contiene i record che verranno inviati alla logica principale:
| deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00.0000000Z | Valore stringa | 1.7145 | ["A","B"] |
| 3 | 2021-12-10T10:01:20.0000000Z | Una terza stringa | NULL | ["D","E","F"] |
Debug2 contiene i record che verranno rifiutati:
| in_deviceId | in_readingTimestamp | in_readingStr | in_readingNum | in_readingArray | deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|---|---|---|---|---|
| 2 | 2021-12-10T10:01:00 | NULL | 2.378 | ["C"] | 2 | 2021-12-10T10:01:00.0000000Z | NULL | 2.378 | ["C"] |
| 4 | 2021-12-10T10:02:10 | Stringa in avanti | 1.2126 | {} | 4 | 2021-12-10T10:02:10.0000000Z | Stringa in avanti | 1.2126 | NULL |
Il passaggio finale consiste nell'aggiungere nuovamente la logica principale. Si aggiungerà anche l'output che raccoglie i rifiuti. In questo caso è consigliabile usare un adattatore di output che non impone la digitazione avanzata, ad esempio un account di archiviazione.
La query completa è disponibile nell'ultima sezione.
WITH
readingsValidated AS (...),
readingsToBeProcessed AS (...),
readingsToBeRejected AS (...)
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
INTO SQLOutput
FROM readingsToBeProcessed AS r
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
SELECT
*
INTO BlobOutput
FROM readingsToBeRejected
Che fornirà il set seguente per SQLOutput, senza alcun possibile errore:
| deviceId | readingTimestamp | readingStr | readingNum | readingArray |
|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00.0000000Z | Valore stringa | 1.7145 | 2 |
| 3 | 2021-12-10T10:01:20.0000000Z | Una terza stringa | NULL | 3 |
Gli altri due record vengono inviati a un Oggetto BlobOutput per la revisione umana e la post-elaborazione. La query è ora sicura.
Esempio di query con convalida di input
WITH readingsValidated AS (
SELECT
-- Rename incoming fields, used for audit and debugging
deviceId AS in_deviceId,
readingTimestamp AS in_readingTimestamp,
readingStr AS in_readingStr,
readingNum AS in_readingNum,
readingArray AS in_readingArray,
-- Try casting fields in their expected type
TRY_CAST(deviceId AS bigint) as deviceId,
TRY_CAST(readingTimestamp AS datetime) as readingTimestamp,
TRY_CAST(readingStr AS nvarchar(max)) as readingStr,
TRY_CAST(readingNum AS float) as readingNum,
TRY_CAST(readingArray AS array) as readingArray
FROM readings TIMESTAMP BY readingTimestamp
),
readingsToBeProcessed AS (
SELECT
deviceId,
readingTimestamp,
readingStr,
readingNum,
readingArray
FROM readingsValidated
WHERE
readingStr IS NOT NULL
AND readingArray IS NOT NULL
),
readingsToBeRejected AS (
SELECT
*
FROM readingsValidated
WHERE -- Same clauses as readingsToBeProcessed, opposed with NOT
NOT (
readingStr IS NOT NULL
AND readingArray IS NOT NULL
)
)
-- Core business logic
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
INTO SQLOutput
FROM readingsToBeProcessed AS r
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
-- Rejected output. For human review, correction, and manual re-insertion downstream
SELECT
*
INTO BlobOutput -- to a storage adapter that doesn't require strong typing, here blob/adls
FROM readingsToBeRejected
Estensione della convalida dell'input
GetType può essere usato per verificare in modo esplicito la presenza di un tipo. Funziona bene con CA edizione Standard nella proiezione o WHERE a livello di set. GetType può essere usato anche per controllare in modo dinamico lo schema in ingresso in un repository di metadati. Il repository può essere caricato tramite un set di dati di riferimento.
Gli unit test sono una procedura consigliata per garantire che la query sia resiliente. Verrà compilata una serie di test costituiti da file di input e dal relativo output previsto. La query dovrà corrispondere all'output generato da passare. In ASA, unit test viene eseguito tramite il modulo asa-streamanalytics-cicd npm. I test case con vari eventi in formato non valido devono essere creati e testati nella pipeline di distribuzione.
Infine, è possibile eseguire alcuni test di integrazione leggera in VS Code. È possibile inserire record nella tabella SQL tramite un'esecuzione locale in un output live.
Ottenere supporto
Per maggiore supporto, provare la Pagina delle domande di Domande e risposte Microsoft per Analisi di flusso di Azure.
Passaggi successivi
- Configurare pipeline CI/CD e unit test usando il pacchetto npm
- Panoramica delle esecuzioni locali di Analisi di flusso in Visual Studio Code con ASA Tools
- Eseguire test locali delle query di Analisi di flusso con dati di esempio con Visual Studio Code
- Testare le query di Analisi di flusso in locale rispetto all'input del flusso live usando Visual Studio Code
- Esplorare i processi di Analisi di flusso di Azure con Visual Studio Code (anteprima)