Livello di compatibilità per i processi di Analisi di flusso di Azure
Questo articolo descrive l'opzione del livello di compatibilità in Analisi di flusso di Azure.
Analisi di flusso è un servizio gestito, con aggiornamenti regolari delle funzionalità e miglioramenti costanti delle prestazioni. La maggior parte degli aggiornamenti dei runtime del servizio viene resa automaticamente disponibile agli utenti finali, indipendentemente dal livello di compatibilità. Tuttavia, quando una nuova funzionalità introduce una modifica nel comportamento dei processi esistenti o una modifica nel modo in cui i dati vengono utilizzati nei processi in esecuzione, questa modifica viene introdotta in un nuovo livello di compatibilità. È possibile mantenere in esecuzione i processi di Analisi di flusso esistenti senza modifiche importanti lasciando l'impostazione del livello di compatibilità ridotta. Quando si è pronti per i comportamenti di runtime più recenti, è possibile acconsentire esplicitamente aumentando il livello di compatibilità.
Scegliere un livello di compatibilità
Il livello di compatibilità controlla il comportamento di runtime di un processo di Analisi di flusso.
Analisi di flusso di Azure supporta attualmente tre livelli di compatibilità:
- 1.2 - Comportamento più recente con i miglioramenti più recenti
- 1.1 - Comportamento precedente
- 1.0 - Livello di compatibilità originale, introdotto durante la disponibilità generale di Analisi di flusso di Azure diversi anni fa.
Quando si crea un nuovo processo di Analisi di flusso, è consigliabile crearlo usando il livello di compatibilità più recente. Avviare la progettazione del processo basandosi sui comportamenti più recenti, per evitare modifiche e complessità aggiunte in un secondo momento.
Configurare il livello di compatibilità
È possibile impostare il livello di compatibilità per un processo di Analisi di flusso nel portale di Azure o usando la chiamata all'API REST di creazione del processo.
Per aggiornare il livello di compatibilità del processo nel portale di Azure:
- Usare il portale di Azure per individuare il processo di Analisi di flusso.
- Arrestare il processo prima di aggiornare il livello di compatibilità. Non è possibile aggiornare il livello di compatibilità se il processo è in esecuzione.
- Nell'intestazione Configura selezionare Livello di compatibilità.
- Scegliere il valore del livello di compatibilità desiderato.
- Selezionare Salva nella parte inferiore della pagina.
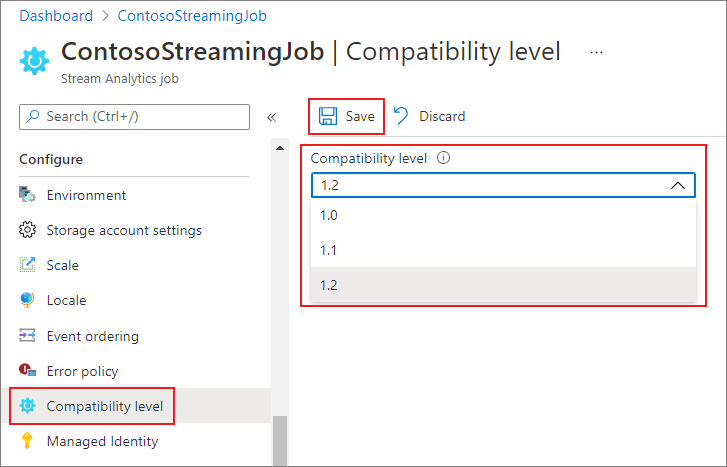
Quando si aggiorna il livello di compatibilità, il compilatore T convalida il processo con la sintassi corrispondente al livello di compatibilità selezionato.
Livello di compatibilità 1.2
Le modifiche principali seguenti sono introdotte nel livello di compatibilità 1.2:
Protocollo di messaggistica AMQP
1.2 livello: Analisi di flusso di Azure usa il protocollo di messaggistica AMQP (Advanced Message Queueing Protocol) per scrivere in code e argomenti bus di servizio. AMQP consente di creare applicazioni ibride multipiattaforma usando un protocollo aperto standard.
Funzioni geospaziali
Livelli precedenti: Analisi di flusso di Azure ha usato calcoli geografici.
1.2 livello: Analisi di flusso di Azure consente di calcolare le coordinate geografiche proiettate geometriche. Non vi sono modifiche alla firma delle funzioni geospaziali. Tuttavia, la loro semantica è leggermente diversa, consentendo calcoli più precisi di prima.
Analisi di flusso di Azure supporta l'indicizzazione dei dati di riferimento geospaziali. I dati di riferimento contenenti elementi geospaziali possono essere indicizzati per un calcolo di join più rapido.
Le funzioni geospaziali aggiornate portano l'espressività completa del formato geospaziale WKT (Well Known Text). È possibile specificare altri componenti geospaziali non supportati in precedenza con GeoJson.
Per altre informazioni, vedere Aggiornamenti delle funzionalità geospaziali in Analisi di flusso di Azure - Cloud e IoT Edge.
Esecuzione di query parallele per origini di input con più partizioni
Livelli precedenti: le query di Analisi di flusso di Azure richiedevano l'uso della clausola PARTITION BY per parallelizzare l'elaborazione delle query tra le partizioni di origine di input.
1.2 livello: se la logica di query può essere parallelizzata tra le partizioni di origine di input, Analisi di flusso di Azure crea istanze di query separate ed esegue calcoli in parallelo.
Integrazione dell'API bulk nativa con l'output di Azure Cosmos DB
Livelli precedenti: il comportamento upsert è stato inserito o unito.
Livello 1.2: l'integrazione dell'API bulk nativa con l'output di Azure Cosmos DB ottimizza la velocità effettiva e gestisce in modo efficiente le richieste di limitazione. Per altre informazioni, vedere la pagina output di Analisi di flusso di Azure in Azure Cosmos DB.
Il comportamento upsert viene inserito o sostituito.
DateTimeOffset durante la scrittura nell'output SQL
Livelli precedenti: i tipi DateTimeOffset sono stati modificati in formato UTC.
1.2 livello: DateTimeOffset non viene più modificato.
Long when writing to SQL output (Long when writing to SQL output)
Livelli precedenti: i valori sono stati troncati in base al tipo di destinazione.
1.2 livello: i valori che non rientrano nel tipo di destinazione vengono gestiti in base ai criteri di errore di output.
Serializzazione di record e matrici durante la scrittura nell'output SQL
Livelli precedenti: i record sono stati scritti come "Record" e le matrici sono state scritte come "Array".
1.2 livello: i record e le matrici vengono serializzati in formato JSON.
Convalida rigorosa del prefisso delle funzioni
Livelli precedenti: non è stata eseguita alcuna rigorosa convalida dei prefissi di funzione.
1.2 livello: Analisi di flusso di Azure ha una convalida rigorosa dei prefissi delle funzioni. L'aggiunta di un prefisso a una funzione predefinita causa un errore. Ad esempio, myprefix.ABS(…) non è supportato.
L'aggiunta di un prefisso alle aggregazioni predefinite genera anche un errore. Ad esempio, myprefix.SUM(…) non è supportato.
L'uso del prefisso "system" per qualsiasi funzione definita dall'utente genera un errore.
Non consentire array e oggetto come proprietà chiave nell'adattatore di output di Azure Cosmos DB
Livelli precedenti: i tipi array e object sono stati supportati come proprietà chiave.
1.2 livello: i tipi matrice e oggetto non sono più supportati come proprietà chiave.
Deserializzazione del tipo booleano in JSON, AVRO e PARQUET
Livelli precedenti: Analisi di flusso di Azure deserializza il valore booleano nel tipo BIGINT: false esegue il mapping a 0 e true esegue il mapping a 1. L'output crea solo valori booleani in JSON, AVRO e PARQUET se si converte in modo esplicito gli eventi in BIT.
Ad esempio, una query pass-through come SELECT value INTO output1 FROM input1 la lettura di un codice JSON { "value": true } da input1 scriverà nell'output1 un valore { "value": 1 }JSON.
1.2 livello: Analisi di flusso di Azure deserializza il valore booleano nel tipo BIT. False esegue il mapping a 0 e true esegue il mapping a 1. Una query pass-through come SELECT value INTO output1 FROM input1 la lettura di un codice JSON { "value": true } da input1 scriverà nell'output1 un valore { "value": true }JSON. È possibile eseguire il cast del valore al tipo BIT nella query per assicurarsi che vengano visualizzati come true e false nell'output per i formati che supportano il tipo booleano.
Livello di compatibilità 1.1
Nel livello di compatibilità 1.1 sono state introdotte le modifiche sostanziali seguenti:
Formato XML del bus di servizio
Livello 1.0: Analisi di flusso di Azure usa DataContractSerializer, quindi il contenuto del messaggio include tag XML. Ad esempio:
@\u0006string\b3http://schemas.microsoft.com/2003/10/Serialization/\u0001{ "SensorId":"1", "Temperature":64\}\u0001
Livello 1.1: il contenuto del messaggio contiene direttamente il flusso senza tag aggiuntivi. Ad esempio: { "SensorId":"1", "Temperature":64}
Distinzione maiuscole/minuscole persistente nei nomi dei campi
Livello 1.0: i nomi dei campi sono stati modificati in lettere minuscole durante l'elaborazione dal motore di Analisi di flusso di Azure.
1.1 livello: la distinzione tra maiuscole e minuscole viene mantenuta per i nomi dei campi quando vengono elaborati dal motore di Analisi di flusso di Azure.
Nota
La distinzione tra maiuscole e minuscole persistente non è ancora disponibile per i processi di Analisi di flusso ospitati in un ambiente di dispositivo perimetrale. Se il processo è ospitato in un dispositivo perimetrale, quindi, tutti i nomi di campo vengono convertiti in caratteri minuscoli.
FloatNaNDeserializationDisabled
Livello 1.0: il comando CREATE TABLE non ha filtrato gli eventi con NaN (Not-a-Number. Ad esempio, Infinity, -Infinity) in un tipo di colonna FLOAT perché non rientrano nell'intervallo documentato per questi numeri.
1.1 livello: CREATE TABLE consente di specificare uno schema sicuro. Il motore di Analisi di flusso convalida la conformità dei dati a questo schema e, con questo modello, il comando può filtrare anche eventi contrassegnati con valori NaN.
Disabilitare la conversione automatica delle stringhe datetime nel tipo DateTime in ingresso per JSON
Livello 1.0: il parser JSON convertirà automaticamente i valori stringa con informazioni di data/ora/fuso orario in tipo DATETIME in ingresso, in modo che il valore perda immediatamente la formattazione originale e le informazioni sul fuso orario. Poiché questa operazione viene eseguita in ingresso, anche se tale campo non è stato usato nella query, viene convertito in DateTime UTC.
1.1 livello: nessuna conversione automatica dei valori stringa con informazioni di data/ora/fuso orario in tipo DATETIME. Di conseguenza, le informazioni sul fuso orario e la formattazione originale vengono mantenute. Tuttavia, se il campo NVARCHAR(MAX) viene usato nella query come parte di un'espressione DATETIME (funzione DATEADD, ad esempio), viene convertito in tipo DATETIME per eseguire il calcolo e perde la forma originale.