Integrazione e recapito continui per un'area di lavoro Azure Synapse Analytics
L'integrazione continua (CI) è il processo di automazione della compilazione e dei test del codice ogni volta che un membro del team esegue il commit di una modifica al controllo della versione. Il recapito continuo (CD) è il processo di compilazione, test, configurazione e distribuzione da più ambienti di test o gestione temporanea in un ambiente di produzione.
In un'area di lavoro Azure Synapse Analytics, CI/CD sposta tutte le entità da un ambiente (sviluppo, test, produzione) a un altro. La promozione dell'area di lavoro in un'altra area di lavoro è un processo suddiviso in due parti. Innanzitutto, usare un Modello di Azure Resource Manager (modello di ARM) per creare o aggiornare le risorse dell'area di lavoro (pool e area di lavoro). Eseguire quindi la migrazione di artefatti come script SQL e notebook, definizioni di processi Spark, pipeline, set di dati e altri artefatti usando gli strumenti di Distribuzione dell'area di lavoro Synapse in Azure DevOps o in GitHub.
Questo articolo mostra come usare una pipeline di versione di Azure DevOps e GitHub Actions per automatizzare la distribuzione di un'area di lavoro di Azure Synapse in più ambienti.
Prerequisiti
Per automatizzare la distribuzione di un'area di lavoro di Azure Synapse in più ambienti è necessario che siano soddisfatti i prerequisiti e le configurazioni seguenti. È possibile scegliere di usare Azure DevOps o GitHub in base alle preferenze o alla configurazione esistente.
Azure DevOps
Se si usa Azure DevOps:
- Preparare un progetto Azure DevOps per l'esecuzione della pipeline di versione.
- Concedere l’accesso Basic a tutti gli utenti che archivieranno il codice a livello di organizzazione, in modo che possano visualizzare il repository.
- Concedere l'autorizzazione per il repository Azure Synapse al proprietario.
- Assicurarsi di aver creato un agente di macchine virtuali di Azure DevOps self-hosted o di usare un agente ospitato di Azure DevOps.
- Concedere le autorizzazioni per creare una connessione al servizio di Azure Resource Manager per il gruppo di risorse.
- Un amministratore di Microsoft Entra deve installare l'estensione Azure DevOps Synapse Workspace Deployment Agent nell'organizzazione di Azure DevOps.
- Creare o nominare un account del servizio esistente per l'esecuzione della pipeline. È possibile usare un token di accesso personale anziché un account del servizio, ma le pipeline non funzioneranno dopo l'eliminazione dell'account utente.
GitHub
Se si usa GitHub:
- Creare un repository GitHub contenente gli artefatti dell'area di lavoro di Azure Synapse e il modello dell’area di lavoro.
- Assicurarsi di aver creato uno strumento di esecuzione self-hosted o di usare uno strumento di esecuzione ospitato in GitHub.
Microsoft Entra ID
- Se si usa un'entità servizio, in Microsoft Entra ID creare un'entità servizio da usare per la distribuzione.
- Se si usa un'identità gestita, abilitare l'identità gestita assegnata dal sistema nella macchina virtuale in Azure come agente o strumento di esecuzione e quindi aggiungerla ad Azure Synapse Studio come amministratore di Synapse.
- Usare il ruolo di amministratore di Microsoft Entra per completare queste azioni.
Azure Synapse Analytics
Nota
È possibile automatizzare e distribuire questi prerequisiti usando la stessa pipeline, un modello di ARM o l'interfaccia della riga di comando di Azure, ma questi processi non sono descritti in questo articolo.
L'area di lavoro "origine" usata per lo sviluppo deve essere configurata con un repository Git in Azure Synapse Studio. Per altre informazioni vedere Controllo del codice sorgente in Azure Synapse Studio.
Configurare un'area di lavoro vuota per la distribuzione in:
- Creare una nuova area di lavoro Azure Synapse.
- Concedere all'entità servizio le seguenti autorizzazioni di accesso alla nuova area di lavoro di Synapse:
- Microsoft.Synapse/workspaces/integrationruntimes/write
- Microsoft.Synapse/workspaces/operationResults/read
- Microsoft.Synapse/workspaces/read
- Nell'area di lavoro non configurare la connessione al repository Git.
- Nell'area di lavoro di Azure Synapse passare a Studio>Gestisci>Controllo di accesso. Assegnare il ruolo di "autore artefatti di Synapse" all'entità servizio. Se la pipeline di distribuzione dovrà distribuire endpoint privati gestiti, assegnare invece il ruolo di '"amministratore di Synapse".
- Quando si usano servizi collegati le cui informazioni di connessione vengono archiviate in Azure Key Vault, è consigliabile mantenere insiemi di credenziali delle chiavi separati per ambienti diversi. È anche possibile configurare i livelli di autorizzazione separati per ogni insieme di credenziali delle chiavi. Ad esempio, è possibile che non si voglia che i membri del team siano autorizzati ad accedere ai segreti di produzione. Se si segue questo approccio, è consigliabile mantenere gli stessi nomi dei segreti in tutte le fasi. Se si mantengono gli stessi nomi dei segreti, non è necessario parametrizzare ogni stringa di connessione negli ambienti CI/CD, perché l'unica cosa che cambia è il nome dell'insieme di credenziali delle chiavi, che è un parametro separato.
Altri prerequisiti
- I pool di Spark e i runtime di integrazione self-hosted non vengono creati in un'attività di distribuzione dell'area di lavoro. Se si dispone di un servizio collegato che usa un runtime di integrazione self-hosted, creare manualmente il runtime nella nuova area di lavoro.
- Se gli elementi nell'area di lavoro di sviluppo sono collegati ai pool specifici, assicurarsi di creare o parametrizzare gli stessi nomi per i pool nell'area di lavoro di destinazione nel file di parametri.
- Se i pool SQL a cui è stato effettuato il provisioning vengono sospesi quando si tenta di eseguire la distribuzione, la distribuzione potrebbe non riuscire.
Per altre informazioni vedere CI/CD - Integrazione continua e recapito continuo in Azure Synapse Analytics Parte 4 - Pipeline di versione.
Creare una pipeline di versione in Azure DevOps
Questa sezione descrive come distribuire un'area di lavoro di Azure Synapse in Azure DevOps.
In Azure DevOpsaprire il progetto creato per la versione.
Nel menu a sinistra selezionare Pipeline>Versioni.
Selezionare New pipeline (Nuova pipeline). Se sono già presenti pipeline selezionare Nuova>Nuova pipeline di versione.
Selezionare il modello Fase vuota.
In Nome fase immettere il nome dell'ambiente.
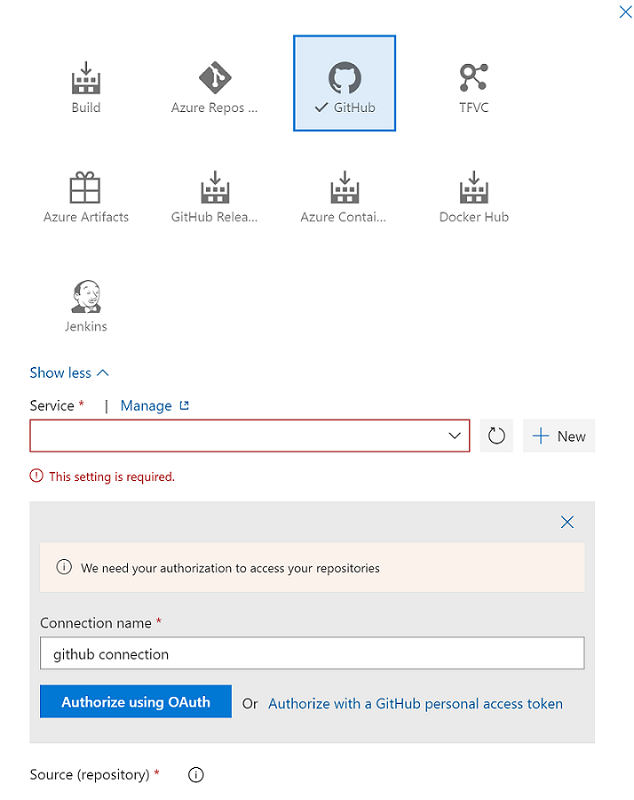
Selezionare Aggiungi artefattoe quindi selezionare il repository Git configurato con Azure Synapse Studio nell'ambiente di sviluppo. Selezionare il repository Git in cui si gestiscono i pool e il modello di ARM dell'area di lavoro. Se si usa GitHub come database di origine, creare una connessione al servizio per l'account GitHub e i repository pull. Per altre informazioni vedere Connessioni al servizio.
Selezionare il ramo del modello di ARM della risorsa. Per la versione predefinita, selezionare Più recente dal ramo predefinito.

Per il ramo predefinito degli artefatti, selezionare il ramo di pubblicazione del repository o altri rami non pubblici che includono gli artefatti di Synapse. Per impostazione predefinita il ramo di pubblicazione è
workspace_publish. Per la versione predefinita, selezionare Più recente dal ramo predefinito.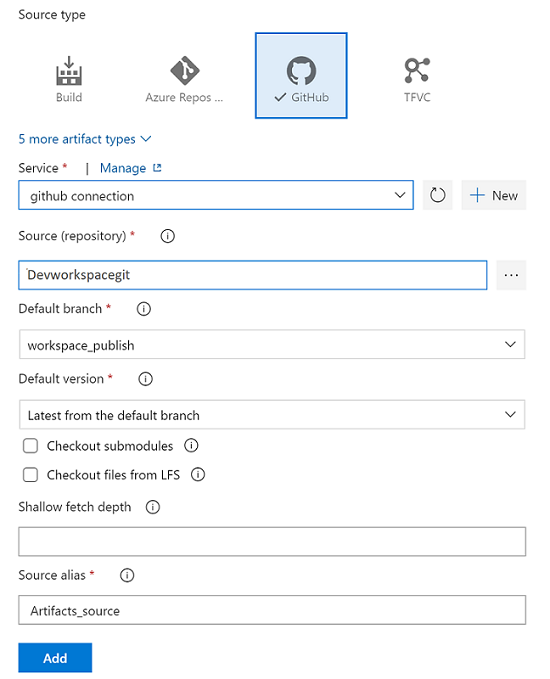

Configurare un'attività di fase per un modello di ARM per creare e aggiornare una risorsa
Se si dispone di un modello di ARM che distribuisce una risorsa, ad esempio un'area di lavoro di Azure Synapse, un pool di Spark e SQL o un insieme di credenziali delle chiavi, aggiungere un'attività di distribuzione di Azure Resource Manager per creare o aggiornare tali risorse:
Nella visualizzazione dei passaggi selezionare Visualizza le attività della fase.
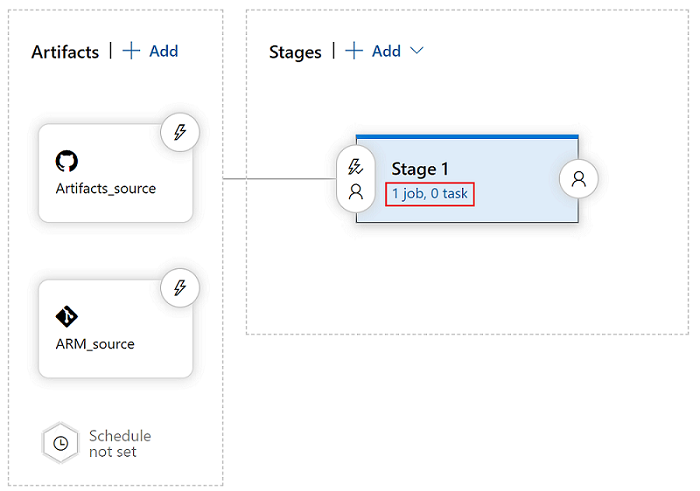
Creare una nuova attività. Cercare Distribuzione del modello di Azure Resource Manager e quindi selezionare Aggiungi.
Nella scheda Attività di distribuzione selezionare la sottoscrizione, il gruppo di risorse e il percorso per l'area di lavoro. Fornire le credenziali, se necessario.
In Azioneselezionare Crea o aggiorna gruppo di risorse.
In Modelloselezionare il pulsante con i puntini di sospensione (...). Passare al modello ARM dell'area di lavoro.
In Parametri del modello selezionare ... per scegliere il file di parametri.
In Sostituisci i parametri del modello selezionare ..., quindi immettere i valori dei parametri da usare per l'area di lavoro.
In Modalità di distribuzione selezionare Incrementale.
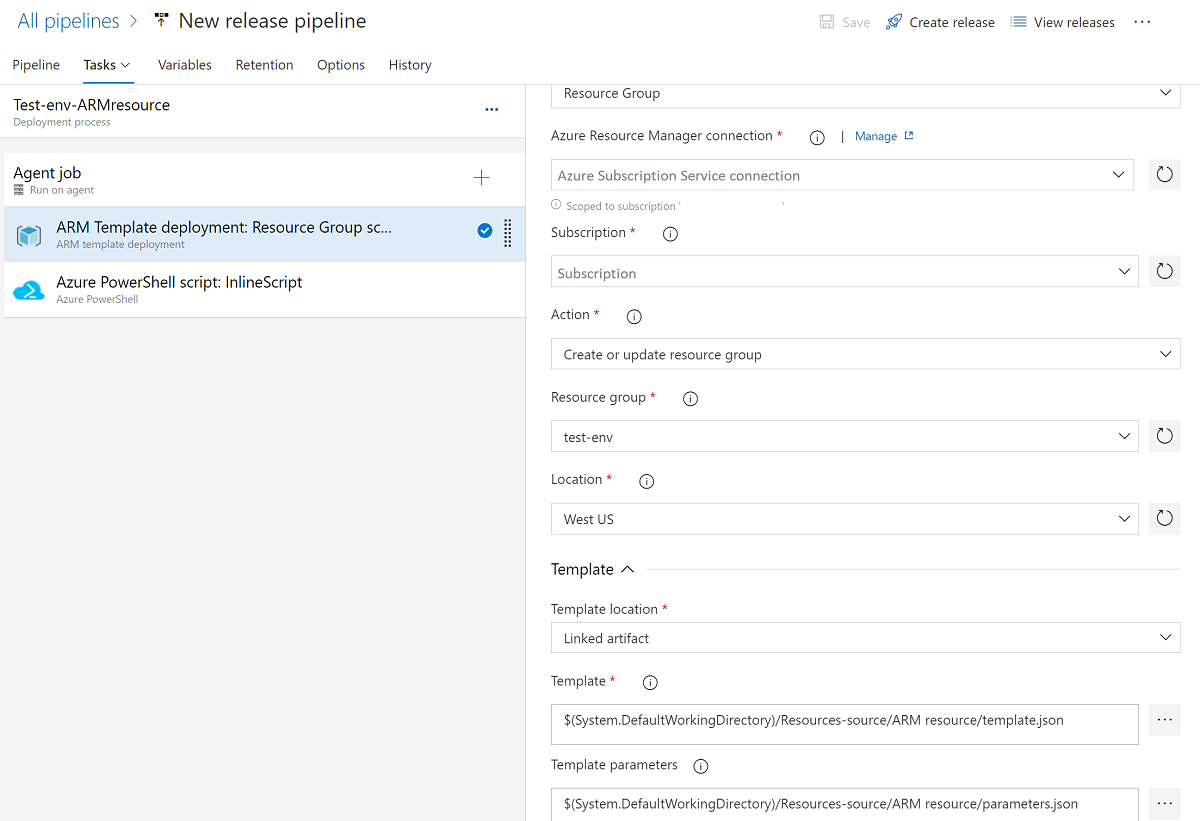
(Facoltativo) Aggiungere Azure PowerShell per la concessione e l’aggiornare l'assegnazione di ruolo dell'area di lavoro. Se si usa una pipeline di versione per creare un'area di lavoro di Azure Synapse, l'entità servizio della pipeline viene aggiunta come amministratore predefinito dell'area di lavoro. È possibile eseguire PowerShell per concedere ad altri account di accedere all'area di lavoro.


Avviso
Nella modalità di distribuzione completa le risorse nel gruppo di risorse non specificate nel nuovo modello di ARM vengono eliminate. Per altre informazioni, vedere Modalità di distribuzione di Azure Resource Manager.
Configurare un'attività di fase per la distribuzione degli artefatti di Azure Synapse
Usare l'estensione Distribuzione dell'area di lavoro di Synapse per distribuire altri elementi nell'area di lavoro di Azure Synapse. Gli elementi che è possibile distribuire includono set di dati, script SQL e notebook, definizioni di processi Spark, runtime di integrazione, flussi di dati, credenziali e altri artefatti nell'area di lavoro.
Installare e aggiungere l'estensione di distribuzione
Cercare e ottenere l'estensione da Visual Studio Marketplace.
Selezionare l'organizzazione di Azure DevOps in cui si vuole installare l'estensione.
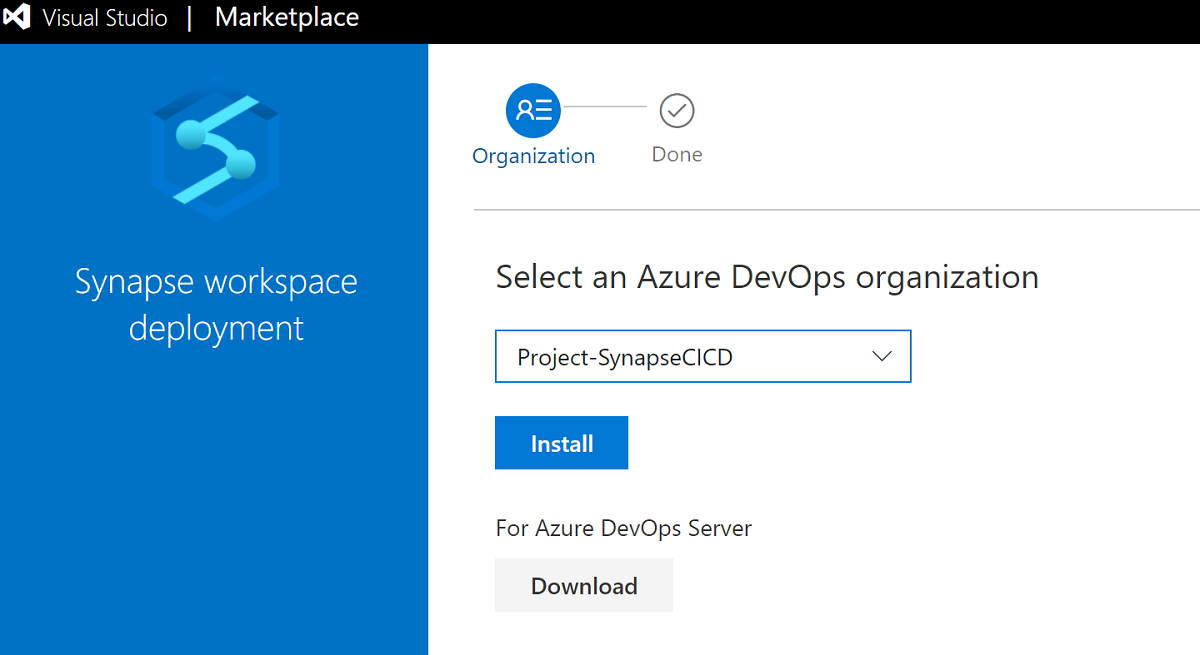
Assicurarsi che all'entità servizio della pipeline di Azure DevOps sia stata concessa l'autorizzazione per la sottoscrizione e sia stato assegnato il ruolo di amministratore dell'area di lavoro di Synapse.
Per creare una nuova attività cercare Distribuzione dell'area di lavoro di Synapse e quindi selezionare Aggiungi.

Configurare l'attività di distribuzione
L'attività di distribuzione supporta tre tipi di operazioni, convalida solo, distribuisci e convalida e distribuisci.
Nota
Questa estensione per la distribuzione dell'area di lavoro non è compatibile con le versioni precedenti. Assicurarsi che venga installata e usata la versione più recente. È possibile leggere la nota sulla versione in panoramicain Azure DevOps e la versione più recente inAzioni di GitHub.
La convalida consiste nel convalidare gli artefatti di Synapse in un ramo non pubblico con l'attività e generare il modello dell'area di lavoro e il file del modello di parametro. L'operazione solo convalida funziona nella pipeline YAML. Ecco il file YAML di esempio:
pool:
vmImage: ubuntu-latest
resources:
repositories:
- repository: <repository name>
type: git
name: <name>
ref: <user/collaboration branch>
steps:
- checkout: <name>
- task: Synapse workspace deployment@2
continueOnError: true
inputs:
operation: 'validate'
ArtifactsFolder: '$(System.DefaultWorkingDirectory)/ArtifactFolder'
TargetWorkspaceName: '<target workspace name>'
Convalidare e distribuire può essere usato per distribuire direttamente l'area di lavoro da un ramo non pubblico con la cartella radice dell'artefatto.
Nota
L'attività di distribuzione deve scaricare i file JS di dipendenza da questo endpoint web.azuresynapse.net quando si seleziona come tipo di operazione Convalida o Convalida e distribuzione. Assicurarsi che l'endpoint web.azuresynapse.net sia autorizzato quando si abilitano i criteri di rete nella macchina virtuale.
L'operazione di convalida e distribuzione funziona sia nella pipeline YAML che in quella classica. Ecco il file YAML di esempio:
pool:
vmImage: ubuntu-latest
resources:
repositories:
- repository: <repository name>
type: git
name: <name>
ref: <user/collaboration branch>
steps:
- checkout: <name>
- task: Synapse workspace deployment@2
continueOnError: true
inputs:
operation: 'validateDeploy'
ArtifactsFolder: '$(System.DefaultWorkingDirectory)/ArtifactFolder'
TargetWorkspaceName: 'target workspace name'
azureSubscription: 'target Azure resource manager connection name'
ResourceGroupName: 'target workspace resource group'
DeleteArtifactsNotInTemplate: true
OverrideArmParameters: >
-key1 value1
-key2 value2
Distribuzione Gli input dell’operazione di distribuzione includono il modello di area di lavoro di Synapse e il modello di parametro, che possono essere creati dopo la pubblicazione nel ramo di pubblicazione dell'area di lavoro o dopo la convalida. È uguale alla versione 1.x.
È possibile scegliere i tipi di operazione in base al caso d'uso. La parte seguente è un esempio della distribuzione.
Nell'attività selezionare il tipo di operazione, ad esempio Distribuzione.
Nell'attività accanto a Modello selezionare ... per scegliere il file modello.
Accanto a Parametri del modello selezionare … per scegliere il file dei parametri.
Selezionare connessione, gruppo di risorse e nome per l'area di lavoro.
Accanto a Esegui l'override dei parametri del modello selezionare .... Immettere i valori dei parametri da usare per l'area di lavoro, incluse le stringhe di connessione e le chiavi dell'account usate nei servizi collegati. Per altre informazioni vedere CI/CD - Integrazione continua e recapito continuo in Azure Synapse Analytics.
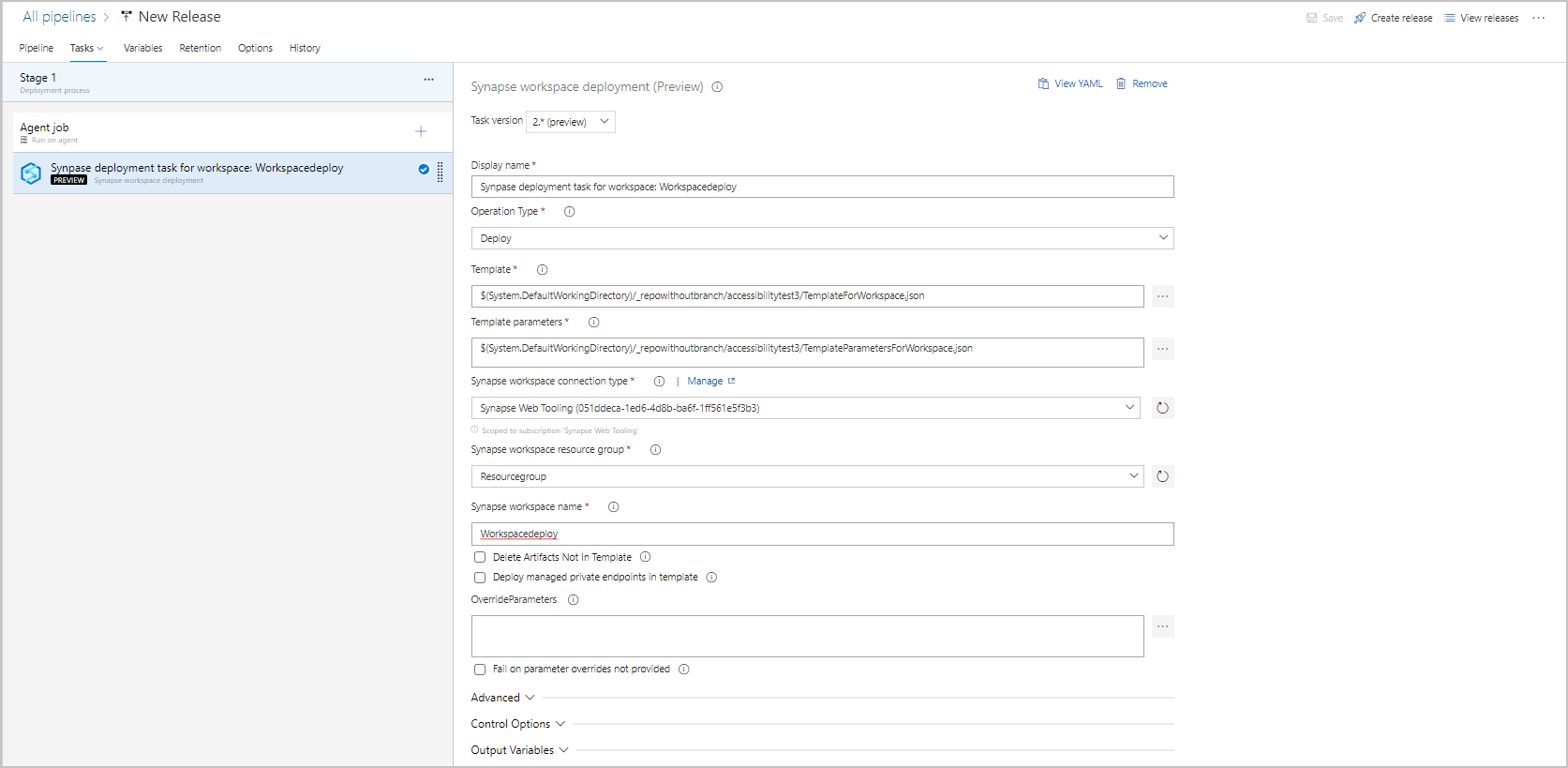
La distribuzione dell'endpoint privato gestito è supportata solo nella versione 2.x. Assicurarsi di selezionare la versione corretta e controllare il modello Deploy managed private endpoints in (Distribuisci endpoint privati gestiti).
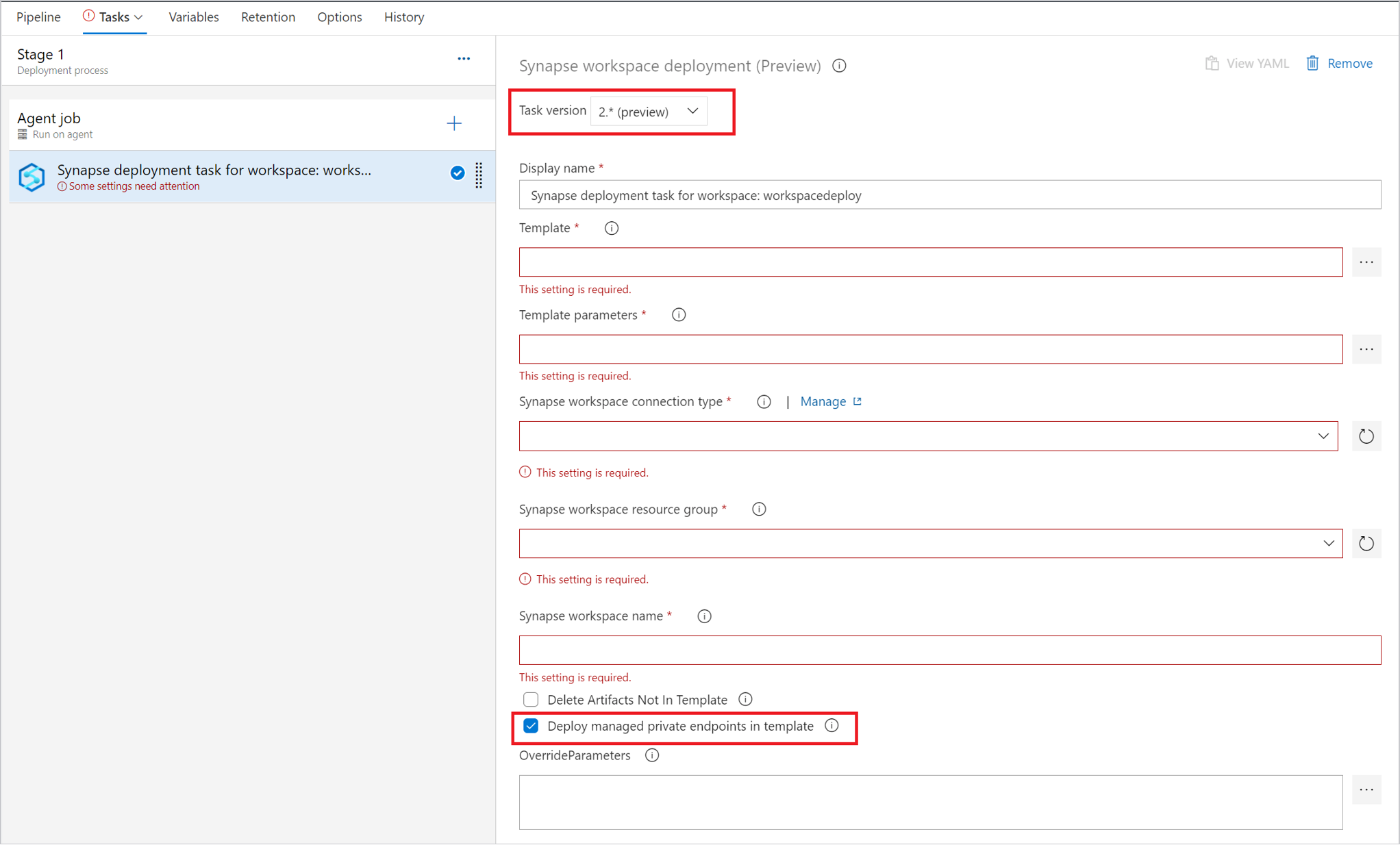
Per gestire i trigger è possibile usare l'interruttore di trigger per arrestare i trigger prima della distribuzione. È anche possibile aggiungere un'attività per riavviare i trigger dopo l'attività di distribuzione.
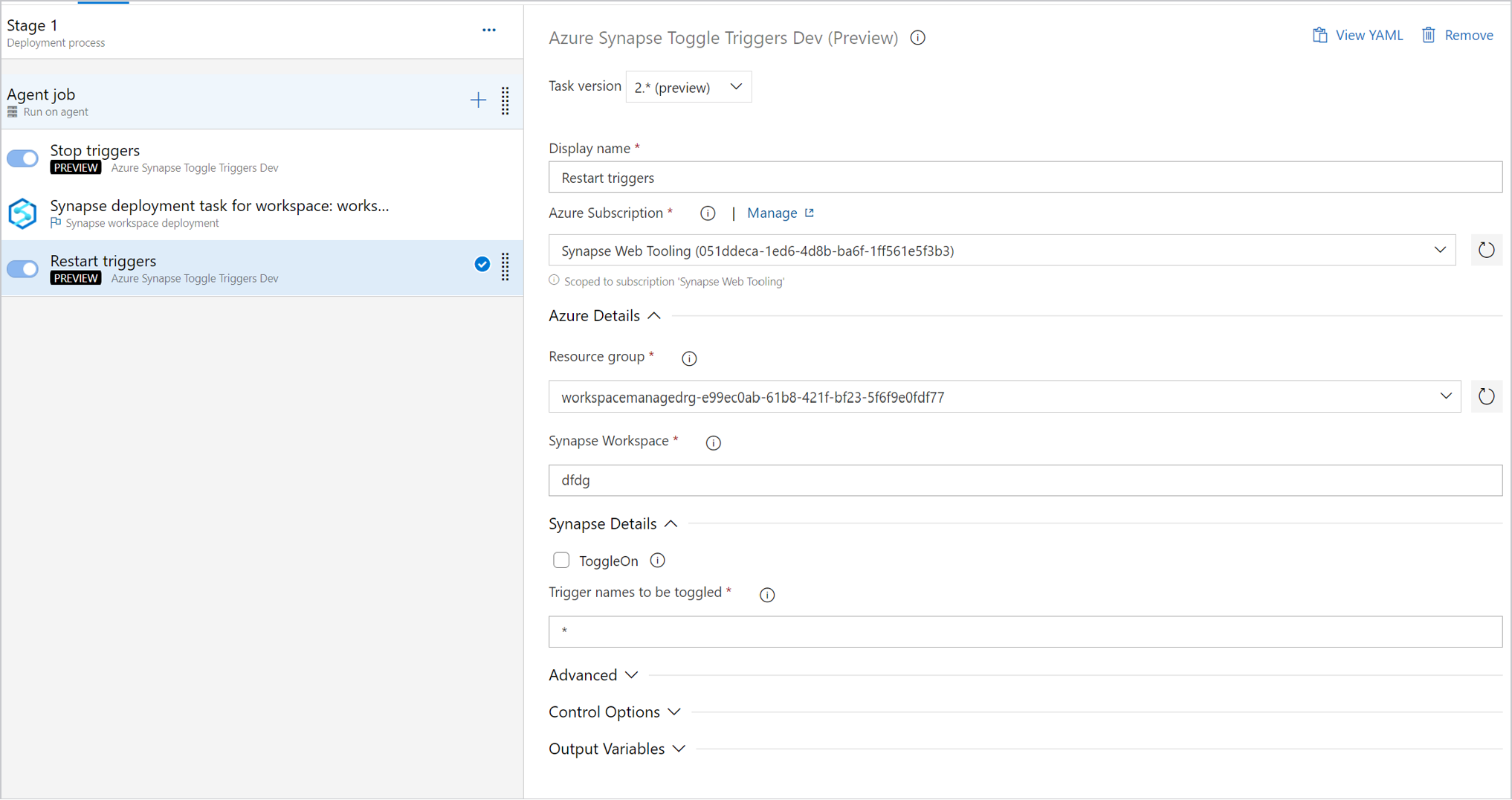


Importante
In scenari di integrazione continua e recapito continuo (CI/CD) il tipo di runtime di integrazione deve essere lo stesso in ambienti diversi. Ad esempio, se si dispone di un runtime di integrazione self-hosted nell'ambiente di sviluppo, lo stesso runtime di integrazione deve essere self-hosted in altri ambienti, ad esempio quello di test e di produzione. Analogamente, se si condividono i runtime di integrazione in più fasi, è necessario che i runtime di integrazione siano collegati e self-hosted in tutti gli ambienti, ad esempio quello di sviluppo, di test e di produzione.
Creare una versione per la distribuzione
Dopo aver salvato tutte le modifiche, è possibile selezionare Crea versione per creare manualmente una versione. Per informazioni su come automatizzare la creazione della versione vedere Trigger delle versioni di Azure DevOps.

Configurare una versione in GitHub Actions
Questa sezione descrive come creare flussi di lavoro GitHub usando GitHub Actions per la distribuzione dell'area di lavoro di Azure Synapse.
È possibile usare il modello di Azure Resource Manager per GitHub Actions per automatizzare la distribuzione di un modello di ARM in Azure per l'area di lavoro e i pool di calcolo.
File del flusso di lavoro
Definire un flusso di lavoro di GitHub Actions in un file YAML (.yml) nel percorso /.github/workflows/ nel repository. La definizione contiene i vari passaggi e parametri che costituiscono il flusso di lavoro.
Il file .yml è costituito da due sezioni:
| Sezione | Attività |
|---|---|
| Autenticazione | 1. Definire un'entità servizio. 2. Creare un segreto GitHub. |
| Distribuzione | Distribuire gli artefatti dell'area di lavoro. |
Configurare i segreti GitHub Actions
I segreti GitHub Actions sono variabili di ambiente crittografate. Chiunque disponga dell'autorizzazione di collaboratore per questo repository può usare questi segreti per interagire con Azioni nel repository.
Nel repository GitHub selezionare la scheda Impostazioni e quindi selezionare Segreti>Nuovo segreto del repository.
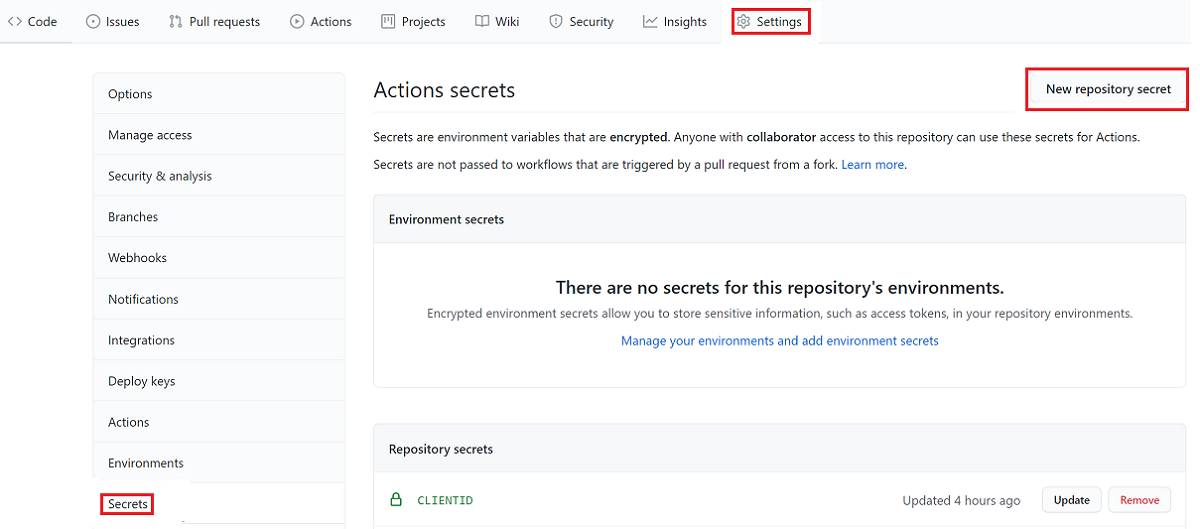
Aggiungere un nuovo segreto all'ID client e aggiungere un nuovo segreto client se si usa l'entità servizio per la distribuzione. È anche possibile scegliere di salvare l'ID sottoscrizione e l'ID tenant come segreti.

Aggiungere il flusso di lavoro
Nel repository GitHub passare ad Azioni.
Selezionare Set up your workflow yourself (Configurare manualmente il flusso di lavoro).
Nel file del flusso di lavoro eliminare tutti ciò che segue la sezione
on:. Ad esempio, il flusso di lavoro rimanente può essere simile all'esempio seguente:name: CI on: push: branches: [ master ] pull_request: branches: [ master ]Rinominare il flusso di lavoro. Nella scheda Marketplace cercare l'azione di distribuzione dell'area di lavoro di Synapse e quindi aggiungere l'azione.

Impostare i valori obbligatori e il modello dell’area di lavoro:
name: workspace deployment on: push: branches: [ publish_branch ] jobs: release: # You also can use the self-hosted runners. runs-on: windows-latest steps: # Checks out your repository under $GITHUB_WORKSPACE, so your job can access it. - uses: actions/checkout@v2 - uses: azure/synapse-workspace-deployment@release-1.0 with: TargetWorkspaceName: 'target workspace name' TemplateFile: './path of the TemplateForWorkspace.json' ParametersFile: './path of the TemplateParametersForWorkspace.json' OverrideArmParameters: './path of the parameters.yaml' environment: 'Azure Public' resourceGroup: 'target workspace resource group' clientId: ${{secrets.CLIENTID}} clientSecret: ${{secrets.CLIENTSECRET}} subscriptionId: 'subscriptionId of the target workspace' tenantId: 'tenantId' DeleteArtifactsNotInTemplate: 'true' managedIdentity: 'False'È possibile eseguire il commit delle modifiche. Selezionare Avvia commit, immettere il titolo e quindi aggiungere una descrizione (facoltativo). Selezionare quindi Esegui il commit del nuovo file.

Il file viene visualizzato nella cartella .github/workflows nel repository.
Nota
L'identità gestita è supportata solo con macchine virtuali self-hosted in Azure. Assicurarsi di impostare lo strumento di esecuzione su self-hosted. Abilitare l'identità gestita assegnata dal sistema per la macchina virtuale e aggiungerla ad Azure Synapse Studio come amministratore di Synapse.


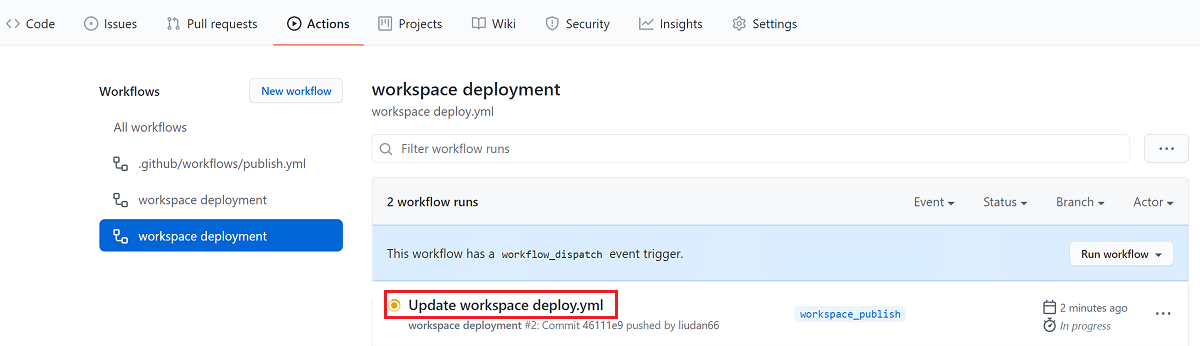
Esaminare la distribuzione
Nel repository GitHub passare ad Azioni.
Aprire il primo risultato per visualizzare i log dettagliati dell'esecuzione del flusso di lavoro:

Creare parametri personalizzati nel modello dell'area di lavoro
Se si usano CI/CD automatizzati e si vogliono modificare alcune proprietà durante la distribuzione, ma le proprietà non sono parametrizzate per impostazione predefinita, è possibile eseguire l'override del modello di parametro predefinito.
Per eseguire l'override del modello di parametro predefinito creare un modello di parametro personalizzato denominato template-parameters-definition.json nella cartella radice del ramo Git. È necessario usare esattamente questo nome file. Quando l'area di lavoro di Azure Synapse pubblica dal ramo di collaborazione o quando l'attività di distribuzione convalida gli artefatti in altri rami, legge questo file e ne usa la configurazione per generare i parametri. Se l'area di lavoro di Azure Synapse non trova questo file, userà il modello di parametro predefinito.
Sintassi dei parametri personalizzata
Per creare un file di parametri personalizzati è possibile usare le linee guida seguenti:
- Immettere il percorso della proprietà nel tipo di entità pertinente.
- Impostare un nome di proprietà su
*indica che si desidera parametrizzare tutte le proprietà di quella proprietà (solo fino al primo livello, non in modo ricorsivo). È possibile impostare eccezioni a questa configurazione. - Quando si imposta il valore di una proprietà come stringa, si indica che si vuole parametrizzare la proprietà. Usare il formato
<action>:<name>:<stype>.<action>può essere uno di questi caratteri:=specifica di mantenere il valore corrente come valore predefinito per il parametro.-specifica di non mantenere il valore predefinito per il parametro.|è un caso speciale per i segreti di Azure Key Vault per stringhe di connessione o chiavi.
<name>è il nome del parametro. Se è vuoto, viene usato il nome della proprietà. Se il valore inizia con un carattere-, il nome viene abbreviato. Ad esempio,AzureStorage1_properties_typeProperties_connectionStringviene abbreviato inAzureStorage1_connectionString.<stype>è il tipo di parametro. Se<stype>è vuoto e il tipo predefinito èstring. Valori supportati:string,securestring,int,bool,object,secureobjectearray.
- La specifica di una matrice nel file indica che la proprietà corrispondente nel modello è una matrice. Azure Synapse esegue l'iterazione di tutti gli oggetti nella matrice usando la definizione specificata. Il secondo oggetto, una stringa, diventa il nome della proprietà, che viene usato come nome per il parametro per ogni iterazione.
- Una definizione non può essere specifica di un'istanza di risorsa. Qualunque definizione viene applicata a tutte le risorse di quel tipo.
- Per impostazione predefinita tutte le stringhe sicure (ad esempio i segreti dell'insieme di credenziali delle chiavi) e le stringhe sicure (ad esempio stringhe di connessione, chiavi e token) vengono parametrizzate.
Esempio di definizione del modello di parametro
Ecco un esempio di definizione di un modello di parametro:
{
"Microsoft.Synapse/workspaces/notebooks": {
"properties": {
"bigDataPool": {
"referenceName": "="
}
}
},
"Microsoft.Synapse/workspaces/sqlscripts": {
"properties": {
"content": {
"currentConnection": {
"*": "-"
}
}
}
},
"Microsoft.Synapse/workspaces/pipelines": {
"properties": {
"activities": [{
"typeProperties": {
"waitTimeInSeconds": "-::int",
"headers": "=::object",
"activities": [
{
"typeProperties": {
"url": "-:-webUrl:string"
}
}
]
}
}]
}
},
"Microsoft.Synapse/workspaces/integrationRuntimes": {
"properties": {
"typeProperties": {
"*": "="
}
}
},
"Microsoft.Synapse/workspaces/triggers": {
"properties": {
"typeProperties": {
"recurrence": {
"*": "=",
"interval": "=:triggerSuffix:int",
"frequency": "=:-freq"
},
"maxConcurrency": "="
}
}
},
"Microsoft.Synapse/workspaces/linkedServices": {
"*": {
"properties": {
"typeProperties": {
"accountName": "=",
"username": "=",
"connectionString": "|:-connectionString:secureString",
"secretAccessKey": "|"
}
}
},
"AzureDataLakeStore": {
"properties": {
"typeProperties": {
"dataLakeStoreUri": "="
}
}
},
"AzureKeyVault": {
"properties": {
"typeProperties": {
"baseUrl": "|:baseUrl:secureString"
},
"parameters": {
"KeyVaultURL": {
"type": "=",
"defaultValue": "|:defaultValue:secureString"
}
}
}
}
},
"Microsoft.Synapse/workspaces/datasets": {
"*": {
"properties": {
"typeProperties": {
"folderPath": "=",
"fileName": "="
}
}
}
},
"Microsoft.Synapse/workspaces/credentials" : {
"properties": {
"typeProperties": {
"resourceId": "="
}
}
}
}
Ecco una spiegazione di come è costruito il modello precedente, in base al tipo di risorsa.
notebooks
- Ogni proprietà nel percorso
properties/bigDataPool/referenceNameè parametrizzate con il relativo valore predefinito. È possibile parametrizzare un pool di Spark collegato per ogni file di notebook.
sqlscripts
- Nel percorso
properties/content/currentConnectionle proprietàpoolNameedatabaseNamevengono parametrizzate come stringhe senza i valori predefiniti nel modello.
pipelines
- Ogni proprietà nel percorso
activities/typeProperties/waitTimeInSecondsè parametrizzata. Qualunque attività in una pipeline che dispone di una proprietà a livello di codice denominatawaitTimeInSeconds(ad esempio, l'attivitàWait) viene parametrizzata come numero, con un nome predefinito. La proprietà non avrà un valore predefinito nel modello di Resource Manager. La proprietà invece è un input necessario durante la distribuzione di Resource Manager. - La
headersproprietà (ad esempio, in un'attivitàWeb) viene parametrizzata con il tipoobject(oggetto). La proprietàheadersha un valore predefinito che corrisponde allo stesso valore della factory di origine.
integrationRuntimes
- Tutte le proprietà nel percorso
typePropertiesvengono parametrizzate con i rispettivi valori predefiniti. Ad esempio, ci sono due proprietà inIntegrationRuntimesproprietà del tipo:computePropertiesessisProperties. Entrambi i tipi di proprietà vengono creati con i rispettivi valori e tipi predefiniti (oggetto).
triggers
In
typeProperties, sono parametrizzate due proprietà:- La proprietà
maxConcurrencyha un valore predefinito ed è il tipostring. Il nome del parametro predefinito della proprietàmaxConcurrencyè<entityName>_properties_typeProperties_maxConcurrency. - Anche la proprietà
recurrenceè parametrizzata. Tutte le proprietà nella proprietàrecurrencevengono impostate per essere parametrizzate come stringhe, con valori predefiniti e nomi di parametro. Un'eccezione è la proprietàinterval, che è parametrizzata come tipoint. Il nome del parametro ha il suffisso<entityName>_properties_typeProperties_recurrence_triggerSuffix. Analogamente, la proprietàfreqè una stringa e viene parametrizzata come stringa. Tuttavia, la proprietàfreqè parametrizzata senza un valore predefinito. Il nome viene abbreviato e fatto seguire da un suffisso, ad esempio<entityName>_freq.
Nota
Attualmente è supportato un numero massimo di 50 trigger.
- La proprietà
linkedServices
- I servizi collegati sono univoci. Poiché i servizi collegati e i set di dati hanno un'ampia gamma di tipi, è possibile fornire una personalizzazione specifica del tipo. Nell'esempio precedente per tutti i servizi collegati del tipo
AzureDataLakeStoreviene applicato un modello specifico. Per tutti gli altri (identificati usando il*carattere ), viene applicato un modello diverso. - La proprietà
connectionStringviene parametrizzata come valoresecurestring. Non ha un valore predefinito. Il nome del parametro viene abbreviato e fatto seguire da un suffisso conconnectionString. - La proprietà
secretAccessKeyviene parametrizzata come valoreAzureKeyVaultSecret(ad esempio, in un servizio collegato Amazon S3). La proprietà viene parametrizzata automaticamente come segreto di Azure Key Vault e recuperata dall'insieme di credenziali delle chiavi configurato. È anche possibile parametrizzare l'insieme di credenziali delle chiavi stesso.
datasets
- Sebbene sia possibile personalizzare i tipi nei set di dati, non è necessaria una configurazione esplicita a livello di *. Nell'esempio precedente, vengono parametrizzate tutte le proprietà del set di dati in
typeProperties.
Procedure consigliate per la pipeline CI/CD
Se si usa l'integrazione Git con l'area di lavoro di Azure Synapse e si dispone di una pipeline CI/CD che sposta le modifiche dall’ambiente di sviluppo a quello di test e quindi nell'ambiente di produzione, si consiglia di seguire le procedure consigliate seguenti:
- Integrare solo l'area di lavoro di sviluppo con Git. Se si usa l'integrazione Git, integrare solo l'area di lavoro disviluppo di Azure Synapse con Git. Le modifiche all'ambiente di test e di produzione vengono distribuite tramite integrazione continua e recapito continuo (CI/CD) e non necessitano dell'integrazione di Git.
- Preparare i pool prima di eseguire la migrazione degli artefatti. Se si dispone di uno script SQL o un notebook collegato ai pool nell'area di lavoro di sviluppo, usare lo stesso nome per i pool in ambienti diversi.
- Sincronizzare il controllo delle versioni in scenari di infrastrutture come codice. Per gestire l'infrastruttura (reti, macchine virtuali, servizi di bilanciamento del carico e topologia di connessione) in un modello descrittivo, usare lo stesso sistema di controllo delle versioni usato dal team di DevOps per il codice sorgente.
- Esaminare le procedure consigliate per Azure Data Factory. Se si usa Data Factory, vedere le procedure consigliate per gli artefatti di Data Factory.
Risolvere i problemi di distribuzione degli artefatti
Usare l'attività di distribuzione dell'area di lavoro di Synapse per distribuire gli artefatti di Synapse
In Azure Synapse, a differenza di Data Factory, gli artefatti non sono risorse di Resource Manager. Non è possibile usare l'attività di distribuzione del modello di ARM per distribuire gli artefatti di Azure Synapse. Usare invece l'attività di distribuzione dell'area di lavoro di Synapse per distribuire gli artefatti e usare l'attività di distribuzione di ARM per la distribuzione delle risorse di ARM (pool e area di lavoro). Attualmente questa attività supporta solo i modelli Synapse in cui le risorse hanno il tipo Microsoft.Synapse. Con questa attività gli utenti possono distribuire automaticamente le modifiche da qualsiasi ramo senza dover pubblicare manualmente in Synapse Studio. Di seguito sono riportati alcuni problemi spesso generati.
1. Pubblicazione non riuscita: il file arm dell'area di lavoro è superiore a 20 MB
Esiste una limitazione delle dimensioni del file nel provider Git, ad esempio, in Azure DevOps le dimensioni massime del file sono pari a 20 MB. Quando le dimensioni del file modello dell'area di lavoro superano i 20 MB, questo errore si verifica quando si pubblicano modifiche in Synapse Studio, in cui viene generato e sincronizzato il file del modello dell'area di lavoro con Git. Per risolvere il problema è possibile usare l'attività di distribuzione di Synapse con l’operazione Convalida o Convalida e distribuzione per salvare il file del modello dell'area di lavoro direttamente nell'agente della pipeline e senza pubblicazione manuale in Synapse Studio.
2. Errore imprevisto del token nella versione
Se il file di parametri contiene valori di parametro non preceduti da caratteri di escape, la pipeline di versione non riesce ad analizzare il file e genera un unexpected token errore. Si consiglia di eseguire l'override dei parametri o usare l’insieme di credenziali delle chiavi per recuperare i valori di parametro. È anche possibile usare doppi caratteri di escape per risolvere il problema.
3. Distribuzione del runtime di integrazione non riuscita
Se il modello di area di lavoro è stato generato da un'area di lavoro abilitata per la rete virtuale gestita e si tenta di eseguire la distribuzione in un'area di lavoro normale o viceversa, questo errore si verifica.
4. Carattere imprevisto rilevato durante l'analisi del valore
Il modello non può essere analizzato nel file modello. Provare eseguendo l'escape delle barre rovesciata, ad esempio \\Test01\Test
5. Impossibile recuperare le informazioni dell'area di lavoro; non trovato
Le informazioni sull'area di lavoro di destinazione non sono configurate correttamente. Assicurarsi che l'ambito della connessione al servizio creato sia il gruppo di risorse con l'area di lavoro.
6. Eliminazione dell'artefatto non riuscita
L'estensione confronta gli artefatti presenti nel ramo di pubblicazione con il modello e li eliminerà in base alle differenze. Assicurarsi di non tentare di eliminare alcun artefatto presente nel ramo di pubblicazione e che un altro artefatto abbia un riferimento o una dipendenza da esso.
7. Distribuzione non riuscita con errore: posizione json 0
Se si tenta di aggiornare manualmente il modello, si verificherà questo errore. Assicurarsi di non aver modificato manualmente il modello.
8. La creazione o l'aggiornamento del documento non è riuscito a causa di riferimenti non validi
L'artefatto in Synapse può essere preso come riferimento da un altro artefatto. Se è stato parametrizzato un attributo a cui si fa riferimento in un artefatto, assicurarsi di fornire un valore corretto e non Null.
9. Impossibile recuperare lo stato di distribuzione nella distribuzione del notebook
Il notebook che si sta tentando di distribuire è collegato a un pool spark nel file modello dell'area di lavoro, mentre nella distribuzione il pool non esiste nell'area di lavoro di destinazione. Se non si parametrizza il nome del pool, assicurarsi di avere lo stesso nome per i pool tra gli ambienti.