Eseguire query su file CSV
In questo articolo verrà illustrato come eseguire una query su un singolo file CSV con il pool SQL serverless in Azure Synapse Analytics. I file CSV possono avere formati diversi:
- Con e senza riga di intestazione
- Valori delimitati da virgole e tabulazioni
- Terminazioni riga in stile Windows e UNIX
- Valori delimitati da virgolette o meno e caratteri di escape
Tutte le varianti precedenti verranno descritte di seguito.
Esempio di avvio rapido
La funzione OPENROWSET consente di leggere il contenuto del file CSV fornendo l'URL del file.
Leggere un file CSV
Il modo più semplice per visualizzare il contenuto del file CSV consiste nel fornire l'URL del file alla funzione OPENROWSET, specificare csv per FORMAT e 2.0 per PARSER_VERSION. Se il file è disponibile pubblicamente o se l'identità di Microsoft Entra può accedere a questo file, dovrebbe essere possibile visualizzare il contenuto del file usando la query simile a quella illustrata nell'esempio seguente:
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2 ) as rows
L'opzione firstrow consente di ignorare la prima riga del file CSV che rappresenta l'intestazione in questo caso. Verificare che sia possibile accedere a questo file. Se il file è protetto con una chiave di firma di accesso condiviso o con un'identità personalizzata, potrebbe essere necessario configurare la credenziale a livello di server per l'account di accesso SQL.
Importante
Se il file CSV contiene caratteri UTF-8, assicurarsi di usare regole di confronto del database UTF-8, ad esempio Latin1_General_100_CI_AS_SC_UTF8.
Una mancata corrispondenza tra la codifica del testo nel file e le regole di confronto potrebbe causare errori di conversione imprevisti.
È possibile modificare facilmente le regole di confronto predefinite del database corrente usando l'istruzione T-SQL seguente: alter database current collate Latin1_General_100_CI_AI_SC_UTF8
Utilizzo dell'origine dati
Nell'esempio precedente viene usato il percorso completo del file. In alternativa, è possibile creare un'origine dati esterna con il percorso che punta alla cartella radice della risorsa di archiviazione:
create external data source covid
with ( location = 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases' );
Dopo aver creato un'origine dati, è possibile usare tale origine dati e il percorso relativo del file nella funzione OPENROWSET:
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) as rows
Se un'origine dati è protetta con la chiave di firma di accesso condiviso o l'identità personalizzata, è possibile configurare l'origine dati con credenziali con ambito database.
Specificare lo schema in modo esplicito
OPENROWSET consente di specificare in modo esplicito le colonne che si intende leggere dal file usando la clausola WITH:
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) with (
date_rep date 1,
cases int 5,
geo_id varchar(6) 8
) as rows
I numeri dopo un tipo di dati nella clausola WITH rappresentano l'indice di colonna nel file CSV.
Importante
Se il file CSV contiene caratteri UTF-8, assicurarsi di specificare in modo esplicito alcune regole di confronto UTF-8 (ad esempio Latin1_General_100_CI_AS_SC_UTF8) per tutte le colonne nella WITH clausola o impostare alcune regole di confronto UTF-8 a livello di database.
Una mancata corrispondenza tra la codifica del testo nel file e le regole di confronto potrebbe causare errori di conversione imprevisti.
È possibile modificare facilmente le regole di confronto predefinite del database corrente usando l'istruzione T-SQL seguente: alter database current collate Latin1_General_100_CI_AI_SC_UTF8 È possibile impostare facilmente le regole di confronto sui tipi di colonna usando la definizione seguente: geo_id varchar(6) collate Latin1_General_100_CI_AI_SC_UTF8 8
Nelle sezioni seguenti viene illustrato come eseguire query su vari tipi di file CSV.
Prerequisiti
Il primo passaggio consiste nel creare un database in cui verranno create le tabelle. Inizializzare quindi gli oggetti eseguendo uno script di installazione su tale database. Questo script di installazione creerà le origini dati, le credenziali con ambito database e i formati di file esterni usati in questi esempi.
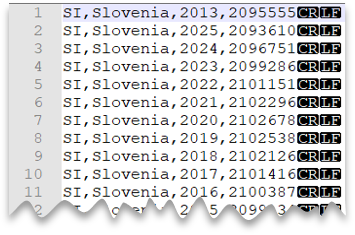
Nuova riga in stile Windows
La query seguente mostra come leggere un file CSV senza alcuna riga di intestazione, con nuova riga in stile Windows e colonne delimitate da virgole.
Anteprima file:
SELECT *
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
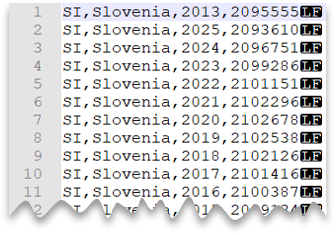
Nuova riga in stile UNIX
La query seguente mostra come leggere un file senza alcuna riga di intestazione, con nuova riga in stile UNIX e colonne delimitate da virgole. Si noti la posizione diversa del file rispetto agli altri esempi.
Anteprima file:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
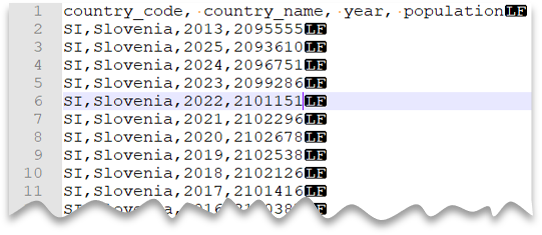
Riga di intestazione
La query seguente mostra come leggere un file con una riga di intestazione, con nuova riga in stile UNIX e colonne delimitate da virgole. Si noti la posizione diversa del file rispetto agli altri esempi.
Anteprima file:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
HEADER_ROW = TRUE
) AS [r]
L'opzione HEADER_ROW = TRUE comporterà la lettura dei nomi di colonna dalla riga di intestazione nel file. È ideale per finalità di esplorazione quando non si conosce il contenuto dei file. Per prestazioni ottimali, vedere la sezione Usare i tipi di dati appropriati in Procedure consigliate. Altre informazioni sulla sintassi di OPENROWSET sono disponibili anche qui.
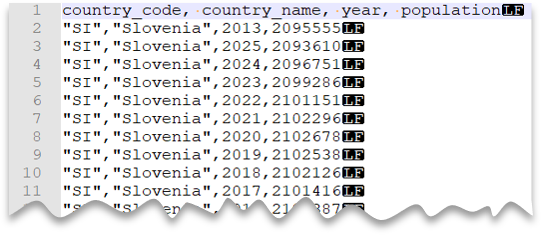
Carattere virgolette personalizzato
La query seguente mostra come leggere un file con riga di intestazione, nuova riga in stile UNIX, colonne delimitate da virgole e valori delimitati da virgolette. Si noti la posizione diversa del file rispetto agli altri esempi.
Anteprima file:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
FIELDQUOTE = '"'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
Nota
Questa query restituisce gli stessi risultati se il parametro FIELDQUOTE è stato omesso, poiché il valore predefinito per FIELDQUOTE è una virgoletta doppia.
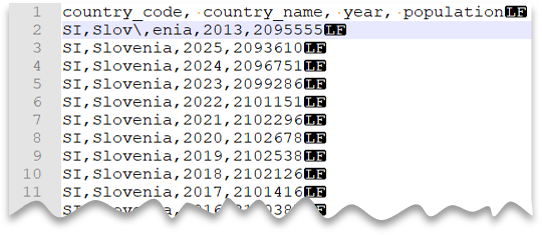
Caratteri di escape
La query seguente mostra come leggere un file con riga di intestazione, nuova riga in stile UNIX, colonne delimitate da virgole e l'uso di un carattere di escape per il delimitatore di campo (virgola) all'interno dei valori. Si noti la posizione diversa del file rispetto agli altri esempi.
Anteprima file:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
ESCAPECHAR = '\\'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
Nota
Questa query avrà esito negativo se il parametro ESCAPECHAR non è specificato perché la virgola in "Slov,enia" verrebbe considerata come delimitatore di campo anziché come parte del nome del Paese/dell'area. "Slov,enia" verrebbe considerato come composto da due colonne. La riga specifica avrà quindi una colonna in più rispetto alle altre righe e una colonna in più rispetto a quelle definite nella clausola WITH.
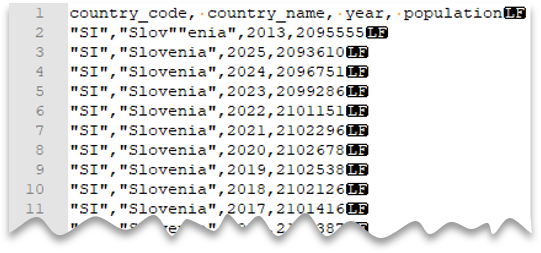
Aggiungere caratteri di escape per testo tra virgolette
La query seguente mostra come leggere un file con una riga di intestazione, una nuova riga in formato UNIX, colonne delimitate da virgole e un carattere di escape per testo tra virgolette all'interno dei valori. Si noti la posizione diversa del file rispetto agli altri esempi.
Anteprima file:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
Nota
Il carattere di virgolette deve essere impostato come escape con un altro carattere di virgolette. Il carattere di virgolette può essere visualizzato all'interno del valore della colonna solo se il valore è incapsulato con caratteri di virgolette.
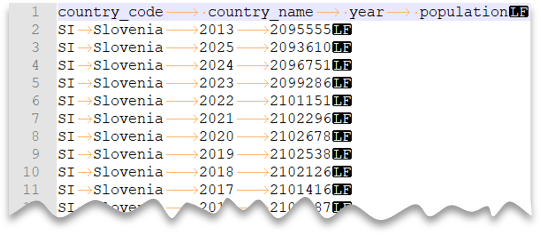
File delimitati da tabulazioni
La query seguente mostra come leggere un file con riga di intestazione, nuova riga in stile UNIX e colonne delimitate da tabulazioni. Si noti la posizione diversa del file rispetto agli altri esempi.
Anteprima file:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-tsv/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR ='\t',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017
Restituire un subset di colonne
Fino ad ora è stato specificato lo schema del file CSV usando il parametro WITH ed elencando tutte le colonne. È possibile specificare solo le colonne effettivamente necessarie nella query usando un numero ordinale per ogni colonna necessaria. Si ometteranno anche le colonne di nessun interesse.
La query seguente restituisce il numero di nomi di Paese/area distinti in un file, specificando solo le colonne necessarie:
Nota
Osservare la clausola WITH nella query seguente. Si noti che è presente "2" (senza virgolette) alla fine della riga in cui si definisce la colonna [country_name]. Ciò significa che la colonna [country_name] è la seconda colonna del file. La query ignorerà tutte le colonne del file, ad eccezione della seconda.
SELECT
COUNT(DISTINCT country_name) AS countries
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
--[country_code] VARCHAR (5),
[country_name] VARCHAR (100) 2
--[year] smallint,
--[population] bigint
) AS [r]
Esecuzione di query su file accodabili
I file CSV usati nella query non devono essere modificati durante l'esecuzione della query. Nella query a esecuzione prolungata il pool SQL può ripetere le letture, leggere parti dei file o persino leggere il file più volte. La modifica del contenuto del file potrebbe generare risultati errati. Di conseguenza, la query del pool SQL non riesce se rileva che l'ora di modifica di un qualsiasi file è cambiata durante l'esecuzione della query.
In alcuni scenari potrebbe essere utile leggere i file che vengono accodati continuamente. Per evitare errori di query causati da file accodati continuamente, è possibile consentire alla funzione OPENROWSET di ignorare letture potenzialmente incoerenti usando l'impostazione ROWSET_OPTIONS.
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2,
ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}') as rows
L'opzione di lettura ALLOW_INCONSISTENT_READS disabiliterà il controllo dell'ora di modifica del file durante il ciclo di vita della query e leggerà tutto il contenuto del file. Nei file accodabili il contenuto esistente non viene aggiornato e vengono aggiunte solo le righe nuove. La probabilità di risultati errati è quindi minima rispetto ai file aggiornabili. Questa opzione potrebbe consentire di leggere i file accodati di frequente senza gestire gli errori. Nella maggior parte degli scenari il pool SQL ignorerà solo alcune righe accodate ai file durante l'esecuzione della query.
Passaggi successivi
Negli articoli successivi verrà illustrato come: