Usare il gruppo di disponibilità distribuito per eseguire la migrazione di database da un'istanza autonoma
È possibile usare un gruppo di disponibilità distribuito per eseguire la migrazione di un database (o più database) da un'istanza autonoma di SQL Server a SQL Server su macchine virtuali di Azure.
Dopo aver convalidato l'istanza di SQL Server di origine soddisfa i prerequisiti, seguire la procedura descritta in questo articolo per creare un gruppo di disponibilità nell'istanza autonoma di SQL Server ed eseguire la migrazione del database (o del gruppo di database) alla macchina virtuale di SQL Server in Azure.
Questo articolo è destinato ai database in un'istanza autonoma di SQL Server. Questa soluzione non richiede un cluster di failover di Windows Server (WSFC) o un listener del gruppo di disponibilità. È anche possibile eseguire la migrazione dei database in un gruppo di disponibilità.
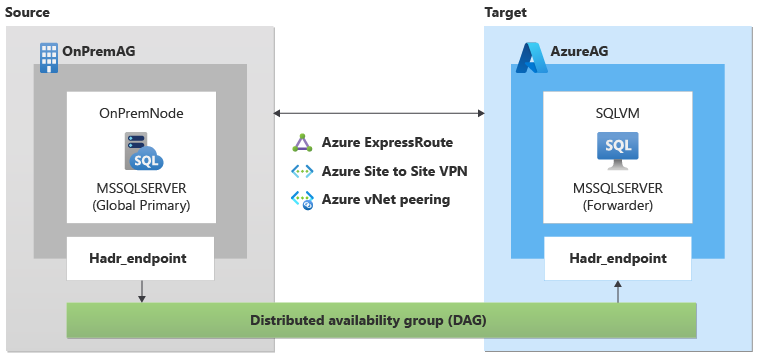
Configurazione iniziale
Il primo passaggio consiste nel creare la macchina virtuale di SQL Server in Azure. È possibile farlo usando il portale di Azure, Azure PowerShell o il modello di ARM.
Assicurarsi di configurare la macchina virtuale di SQL Server in base ai prerequisiti.
Per semplicità, aggiungere la macchina virtuale di SQL Server di destinazione allo stesso dominio di SQL Server di origine. In caso contrario, aggiungere la macchina virtuale di SQL Server di destinazione a un dominio federato con il dominio di SQL Server di origine.
Per usare il seeding automatico per creare il gruppo di disponibilità distribuito (DAG), il nome dell'istanza per il database primario globale (origine) del dag deve corrispondere al nome dell'istanza del server d'inoltro (destinazione) del dag. Se c’è una mancata corrispondenza del nome di istanza tra il server primario globale e il server d'inoltro, è necessario usare il seeding manuale per creare il dag e aggiungere manualmente eventuali file di database aggiuntivi in futuro.
Questo articolo usa i parametri di esempio seguenti:
- Nome database:
Adventureworks2022 - Nome computer di origine (primario globale in DAG):
OnPremNode - Nome dell'istanza di SQL Server di origine:
MSSQLSERVER - Nome del gruppo di disponibilità di origine:
OnPremAg - Nome della macchina virtuale di SQL Server di destinazione (server d'inoltro in DAG):
SQLVM - Sql Server di destinazione nel nome dell'istanza di macchina virtuale di Azure:
MSSQLSERVER - Nome del gruppo di disponibilità di destinazione:
AzureAG - Nome endpoint:
Hadr_endpoint - Nome gruppo di disponibilità distribuito:
DAG - Nome di dominio:
Contoso
Creare endpoint
Usare Transact-SQL (T-SQL) per creare endpoint nelle istanze di SQL Server di origine (OnPremNode) e di destinazione (SQLVM).
Per creare gli endpoint, eseguire questo script T-SQL nei server di origine e di destinazione:
CREATE ENDPOINT [Hadr_endpoint] STATE = STARTED
AS TCP (
LISTENER_PORT = 5022,
LISTENER_IP = ALL
)
FOR DATA_MIRRORING(ROLE = ALL,
AUTHENTICATION = WINDOWS NEGOTIATE,
ENCRYPTION = REQUIRED ALGORITHM AES);
GO
Gli account di dominio hanno automaticamente accesso agli endpoint, ma gli account del servizio potrebbero non far parte automaticamente del gruppo sysadmin e non disporre dell'autorizzazione di connessione. Per concedere manualmente all'account del servizio SQL Server l'autorizzazione di connessione all'endpoint, eseguire lo script T-SQL seguente in entrambi i server:
GRANT CONNECT ON ENDPOINT::[Hadr_endpoint] TO [<your account>];
Creare un gruppo di disponibilità di origine
Poiché un gruppo di disponibilità distribuito è un gruppo di disponibilità speciale che si estende su due singoli gruppi di disponibilità, è prima necessario creare un gruppo di disponibilità nell'istanza di SQL Server di origine. Se si ha già un gruppo di disponibilità che si vuole gestire in Azure, eseguire invece la migrazione del gruppo di disponibilità.
Usare Transact-SQL (T-SQL) per creare un gruppo di disponibilità (OnPremAg) nell'istanza di origine (OnPremNode) per il database Adventureworks2022 di esempio.
Per creare il gruppo di disponibilità, eseguire questo script nell'origine:
CREATE AVAILABILITY GROUP [OnPremAG]
WITH (
AUTOMATED_BACKUP_PREFERENCE = PRIMARY,
DB_FAILOVER = OFF,
DTC_SUPPORT = NONE,
CLUSTER_TYPE = NONE
)
FOR DATABASE [Adventureworks2022] REPLICA ON N'OnPremNode'
WITH (
ENDPOINT_URL = N'TCP://OnPremNode.contoso.com:5022',
FAILOVER_MODE = MANUAL,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
SEEDING_MODE = AUTOMATIC,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO)
);
GO
Creare un gruppo di disponibilità destinazione
È anche necessario creare un gruppo di disponibilità nella macchina virtuale di SQL Server di destinazione.
Usare Transact-SQL (T-SQL) per creare un gruppo di disponibilità (AzureAG) nell'istanza di destinazione (SQLVM).
Per creare il gruppo di disponibilità, eseguire questo script nella destinazione:
CREATE AVAILABILITY GROUP [AzureAG]
WITH (
AUTOMATED_BACKUP_PREFERENCE = PRIMARY,
DB_FAILOVER = OFF,
DTC_SUPPORT = NONE,
CLUSTER_TYPE = NONE,
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 0
)
FOR REPLICA ON N'SQLVM'
WITH (
ENDPOINT_URL = N'TCP://SQLVM.contoso.com:5022',
FAILOVER_MODE = MANUAL,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
SEEDING_MODE = AUTOMATIC,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO)
);
GO
Creare un gruppo di disponibilità distribuito
Dopo aver configurato i gruppi di disponibilità di origine (OnPremAG) e di destinazione (AzureAG), creare il gruppo di disponibilità distribuito per estendersi su entrambi i singoli gruppi di disponibilità.
Usare Transact-SQL nell'istanza di SQL Server di origine (OnPremNode) e nel gruppo di disponibilità (OnPremAG) per creare il gruppo di disponibilità distribuito (DAG).
Per creare il gruppo di disponibilità distribuito, eseguire questo script nell'origine:
CREATE AVAILABILITY GROUP [DAG]
WITH (DISTRIBUTED) AVAILABILITY GROUP
ON 'OnPremAG' WITH (
LISTENER_URL = 'tcp://OnPremNode.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'AzureAG' WITH (
LISTENER_URL = 'tcp://SQLVM.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
GO
La modalità di seeding è impostata su AUTOMATIC come versione di SQL Server nella destinazione e l'origine è la stessa. Se la destinazione di SQL Server è una versione successiva o se il server primario globale e il server d'inoltro hanno nomi di istanza diversi, creare il gruppo di disponibilità distribuito e aggiungere il gruppo di disponibilità secondario al gruppo di disponibilità distribuito con SEEDING_MODE impostato su MANUAL. Ripristinare quindi manualmente i database dall'origine all'istanza di SQL Server di destinazione. Per altre informazioni, vedere Aggiornamento delle versioni durante la migrazione.
Dopo aver creato il gruppo di disponibilità distribuito, aggiungere il gruppo di disponibilità di destinazione (AzureAG) nell'istanza di destinazione (SQLVM) al gruppo di disponibilità distribuito (DAG).
Per aggiungere il gruppo di disponibilità di destinazione al gruppo di disponibilità distribuito, eseguire questo script nella destinazione:
ALTER AVAILABILITY GROUP [DAG]
JOIN AVAILABILITY GROUP
ON 'OnPremAG' WITH (
LISTENER_URL = 'tcp://OnPremNode.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'AzureAG' WITH (
LISTENER_URL = 'tcp://SQLVM.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
GO
Se è necessario annullare, sospendere o ritardare la sincronizzazione tra i gruppi di disponibilità di origine e di destinazione, ad esempio problemi di prestazioni, eseguire questo script nell'istanza primaria globale di origine (OnPremNode):
ALTER AVAILABILITY GROUP [DAG]
MODIFY AVAILABILITY GROUP
ON 'AzureAG' WITH (SEEDING_MODE = MANUAL);
Per altre informazioni, vedere Annullare il seeding automatico al server d'inoltro.