Sovranità dei dati per microservizio
Suggerimento
Questo contenuto è un estratto dell'eBook "Microservizi .NET: Architettura per le applicazioni .NET incluse in contenitori", disponibile in .NET Docs o come PDF scaricabile gratuitamente e da poter leggere offline.

Una regola importate per l'architettura dei microservizi prevede che ogni microservizio sia proprietario dei rispettivi dati di dominio e della rispettiva logica. Analogamente a un'applicazione completa che è proprietaria della rispettiva logica e dei rispettivi dati, ogni microservizio deve essere proprietario della rispettiva logica e dei rispettivi dati in un ciclo di vita autonomo, con una distribuzione indipendente per ogni microservizio.
Il modello concettuale del dominio presenterà quindi differenze tra sottosistemi e microservizi. È possibile prendere in considerazione le applicazioni aziendali, in cui le applicazioni CRM (Customer Relationship Management), i sottosistemi di acquisto transazionale e i sottosistemi di supporto clienti chiamano attributi e dati univoci dell'entità cliente e in cui ogni applicazione usa un contesto delimitato.
Questo principio è simile nella progettazione basata su domini (DDD, Domain-Driven Design), in cui ogni contesto delimitato o sottosistema autonomo o servizio deve essere proprietario del proprio modello di dominio (dati più logica e comportamento). Ogni contesto delimitato DDD è correlato a un microservizio aziendale (uno o più servizi). Il concetto relativo al criterio Bounded Context verrà illustrato in maggiore dettaglio nella sezione successiva.
L'approccio tradizionale (dati monolitici) usato in molte applicazioni prevede tuttavia un singolo database centralizzato o qualche database. Si tratta spesso di un database SQL normalizzato, usato per l'intera applicazione e per tutti i rispettivi sottosistemi interni, come mostrato nella figura 4-7.
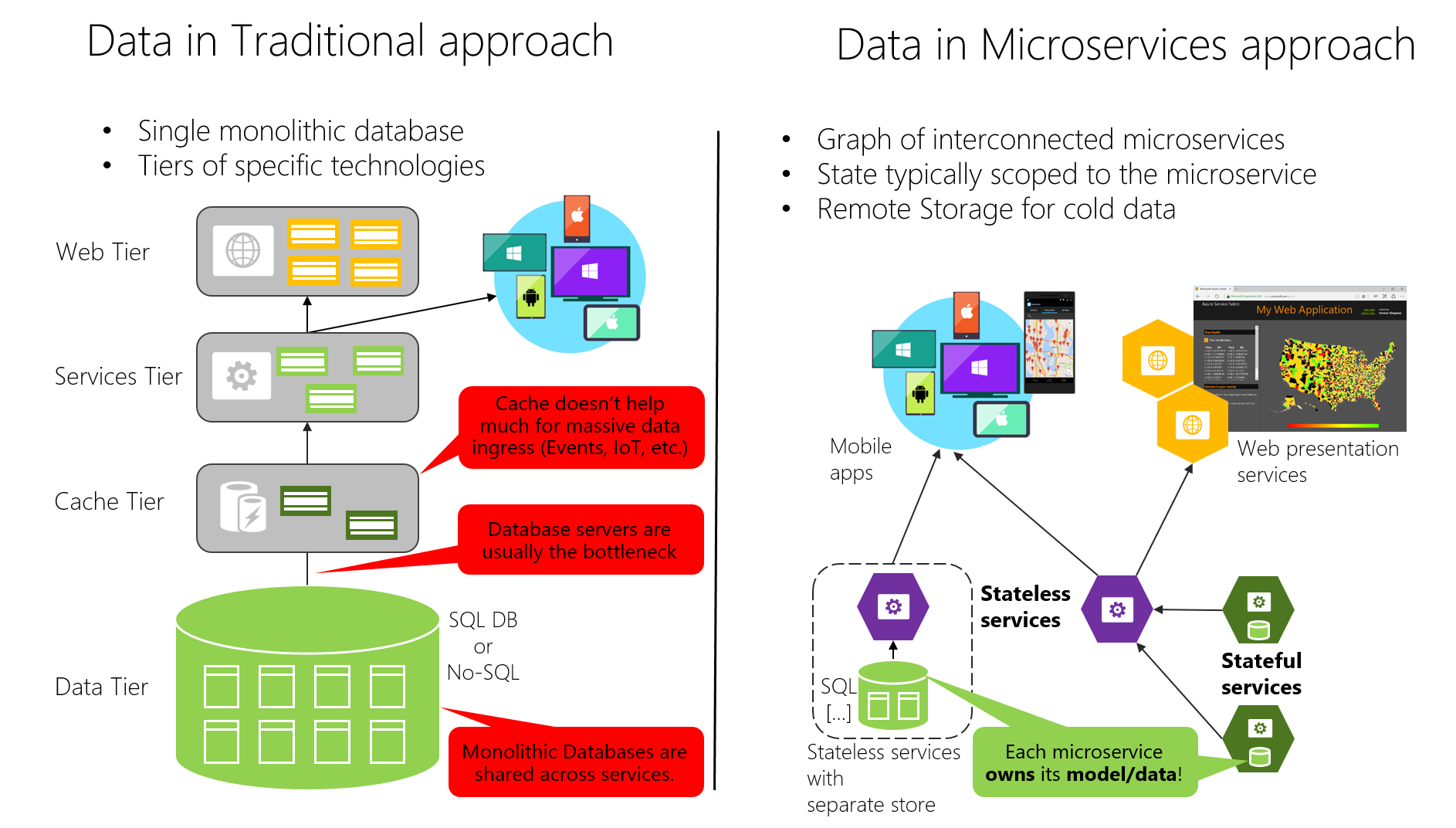
Figura 4-7. Confronto relativo alla sovranità dei dati: database monolitico e microservizi
Nell'approccio tradizionale, è presente un database singolo condiviso tra tutti i servizi, in genere in un'architettura a più livelli. Nell'approccio ai microservizi, ogni microservizio è proprietario dei propri modelli/dati. L'approccio basato sul database centralizzato risulta apparentemente più semplice e sembra consentire il riutilizzo delle entità nei diversi sottosistemi per assicurare la coerenza complessiva. In realtà si ottengono tuttavia tabelle di grandi dimensioni che gestiscono molti sottosistemi diversi e che includono attributi e colonne che risultano nella maggior parte dei casi superflui. Questo approccio è paragonabile all'uso della stessa mappa fisica per una breve passeggiata, per una gita di un giorno in auto e per l'apprendimento della geografia.
Un'applicazione monolitica con in genere un singolo database relazionale offre due vantaggi importanti, ovvero le transazioni ACID e il linguaggio SQL, che possono essere usati in tutte le tabelle e in tutti i dati correlati all'applicazione. Questo approccio consente di scrivere con facilità una query che combina dati da più tabelle.
L'accesso ai dati risulta tuttavia più complesso quando si passa a un'architettura di microservizi. Anche quando si usano transazioni ACID all'interno di un microservizio o contesto delimitato, è fondamentale considerare che i dati di proprietà di ogni microservizio sono privati per tale microservizio e devono essere accessibili solo in modo sincrono tramite gli endpoint API (REST, gRPC, SOAP e così via) o in modo asincrono tramite messaggistica (AMQP o simile).
L'incapsulamento dei dati assicura che i microservizi siano a regime di controllo libero e possano evolversi in modo indipendente. Se più servizi accedono agli stessi dati, gli aggiornamenti dello schema richiederebbero aggiornamenti coordinati per tutti i servizi. Ciò comprometterebbe l'autonomia del ciclo di vita dei microservizi. Le strutture di dati distribuite tuttavia non consentono di eseguire alcuna transazione ACID tra microservizi. È quindi necessario usare la coerenza finale quando un processo aziendale interessa più microservizi. Ciò è molto più difficile da implementare rispetto ai semplici join SQL, perché non è possibile creare vincoli di integrità o usare le transazioni distribuite tra database distinti, come verrà spiegato in un secondo momento. Analogamente, molte altre funzionalità di database relazionali non sono disponibili tra più microservizi.
I diversi microservizi inoltre usano spesso diversi tipi di database. Le applicazioni moderne archiviano ed elaborano diversi tipi di dati e un database relazionale non è sempre la scelta ottimale. Per alcuni casi d'uso è possibile che un database NoSQL, ad esempio Azure CosmosDB o MongoDB, offra un modello di dati più appropriato e prestazioni e scalabilità migliori rispetto a un database SQL come SQL Server o il database SQL di Azure. In altri casi un database relazionale è comunque l'approccio migliore. Le applicazioni basate su microservizi usano quindi spesso una combinazione di database SQL e NoSQL. Questo approccio viene a volte definito persistenza poliglotta.
Un'architettura partizionata, con persistenza poliglotta per l'archiviazione dei dati presenta molti vantaggi, tra cui servizi a regime di controllo libero e prestazioni, scalabilità, costi e gestibilità migliori. Può tuttavia introdurre alcuni problemi a livello di gestione dei dati distribuiti, come illustrato in "Identificazione dei limiti del modello di dominio" più avanti in questo capitolo.
Relazione tra microservizi e schema Bounded Context
Il concetto di microservizi deriva dallo schema Bounded Context in DDD (Domain-Driven Design). DDD gestisce modelli di grandi dimensioni suddividendoli in più contesti delimitato e fornendo informazioni esplicite sui rispettivi limiti. Ogni contesto delimitato deve avere il proprio modello e il proprio database. Analogamente, ogni microservizio è proprietario dei rispettivi dati correlati. Ogni contesto delimitato inoltre ha un linguaggio comune specifico che semplifica le comunicazioni tra sviluppatori software ed esperti di dominio.
Questi termini, principalmente entità di dominio, nel linguaggio comune possono avere nomi diversi in contesti delimitati diversi, anche quando diverse entità di dominio condividono la stessa identità, ovvero l'ID univoco usato per leggere l'entità dalla risorsa di archiviazione. In un contesto delimitato di un profilo utente, ad esempio, è possibile che l'entità di dominio utente condivida l'identità con l'entità di dominio acquirente nel contesto delimitato di ordinazione.
Un microservizio è quindi simile a un contesto delimitato, ma specifica anche che si tratta di un servizio distribuito. È basato su un processo separato per ogni contesto delimitato e deve usare i protocolli distribuiti indicati in precedenza, ad esempio HTTP/HTTPS, WebSockets o AMQP. Lo schema Bounded Context, tuttavia, non specifica se il contesto delimitato è un servizio distribuito o se si tratta semplicemente di un limite logico, ad esempio un sottosistema generico, entro un'applicazione con distribuzione monolitica.
È importante evidenziare che la definizione di un servizio per ogni contesto delimitato è un buon punto di partenza. Non è tuttavia necessario limitare la progettazione a questo aspetto. In alcuni casi è necessario progettare un contesto delimitato o un microservizio aziendale costituito da diversi servizi fisici. Entrambi gli schemi, ovvero Bounded Context e il microservizio, sono tuttavia essenzialmente strettamente correlati.
I microservizi risultano vantaggiosi per DDD perché forniscono limiti reali sotto forma di microservizi distribuiti. In un contesto con limiti tuttavia è consigliabile non condividere il modello tra microservizi.
Risorse aggiuntive
Chris Richardson. Pattern: Database per service (Criterio: database per servizio)
https://microservices.io/patterns/data/database-per-service.htmlMartin Fowler. BoundedContext
https://martinfowler.com/bliki/BoundedContext.htmlMartin Fowler. PolyglotPersistence
https://martinfowler.com/bliki/PolyglotPersistence.htmlAlberto Brandolini. Progettazione orientata al dominio strategico con il Mapping del contesto
https://www.infoq.com/articles/ddd-contextmapping