Gestire lo stato e i dati nelle applicazioni di Docker
Suggerimento
Questo contenuto è un estratto dell'eBook "Microservizi .NET: Architettura per le applicazioni .NET incluse in contenitori", disponibile in .NET Docs o come PDF scaricabile gratuitamente e da poter leggere offline.

Nella maggior parte dei casi è possibile considerare un contenitore come un'istanza di un processo. Un processo non mantiene uno stato persistente. Anche se un contenitore può scrivere nella propria archiviazione locale, presupporre che un'istanza resti disponibile all'infinito sarebbe come presupporre che una singola posizione in memoria sia durevole. Presupporre che le immagine del contenitore, ad esempio i processi, abbiano più istanze o che alla fine saranno eliminate. Se vengono gestite con un agente di orchestrazione del contenitore, presupporre che possano essere spostate da un nodo o da una macchina virtuale a un'altra.
Le soluzioni seguenti vengono usate per gestire i dati nelle applicazioni di Docker:
Dall'host Docker, come volumi Docker:
I volumi vengono archiviati in un'area del file system dell'host gestito da Docker.
I montaggi di associazione possono eseguire il mapping a qualsiasi cartella nel file system dell'host. Non è pertanto possibile controllare l'accesso dal processo Docker, aumentando così il rischio per la sicurezza, dal momento che un contenitore potrebbe accedere alle cartelle sensibili del sistema operativo.
I montaggi di tipo tmpfs sono come cartelle virtuali presenti solo nella memoria dell'host e non vengono mai scritte nel file system.
Dall'archiviazione remota:
Archiviazione di Azure che fornisce un'archiviazione geo-distribuibile e una buona soluzione di persistenza a lungo termine per i contenitori.
Database relazionali remoti come i database SQL di Azure, database NoSQL come Azure Cosmos DB o servizi di cache come Redis.
Dal contenitore Docker:
- Sovrimpressione del file system. La funzionalità Docker implementa un'operazione di copia su scrittura che archivia le informazioni aggiornate nel file system radice del contenitore. Tali informazioni vengono aggiunte all'immagine originale su cui si basa il contenitore. Se il contenitore viene eliminato dal sistema, le modifiche andranno perdute. Quindi, anche se è possibile salvare lo stato di un contenitore all'interno dell'archiviazione locale, progettare un sistema in base a questo presupposto genererebbe un conflitto con una delle impostazioni predefinite della progettazione di contenitori, ovvero l'assenza di stato.
Tuttavia, l’uso dei volumi Docker rappresenta ora il modo migliore per gestire i dati locali in Docker. Per altre informazioni sull'archiviazione in contenitore, vedere Docker storage drivers (Driver di archiviazione Docker) e About storage drivers (Informazioni sui driver di archiviazione).
Queste opzioni sono descritte di seguito più nel dettaglio:
I volumi di dati sono directory associate dal sistema operativo host alle directory nei contenitori. Quando il codice nel contenitore accede alla directory, in realtà accede a una directory nel sistema operativo host. Questa directory non è associata alla durata del contenitore stesso, viene gestita da Docker e isolata dalla funzionalità principale del computer host. Di conseguenza, i volumi di dati sono progettati per rendere persistenti i dati in modo indipendente dalla durata del contenitore. Se si elimina un contenitore o un'immagine dall'host Docker, i dati persistenti nel volume di dati non vengono eliminati.
I volumi possono essere denominati o possono essere anonimi (opzione predefinita). I volumi denominati rappresentano l'evoluzione dei contenitori dei volumi di dati e semplificano la condivisione dei dati tra contenitori. I volumi supportano anche i driver di volume che consentono, tra le altre opzioni, di archiviare i dati in host remoti.
I montaggi di associazione sono disponibili da molto tempo e consentire il mapping di qualsiasi cartella a un punto di montaggio in un contenitore. I montaggi di associazione presentano più limitazioni rispetto ai volumi e generano alcuni problemi importanti in termini di sicurezza. È quindi consigliabile usare i volumi.
I montaggi di tipo tmpfs sono essenzialmente cartelle virtuali presenti solo nella memoria dell'host e non vengono mai scritte nel file system. Sono sicuri e veloci, consumano la memoria e sono applicabili solo a dati temporanei e non permanenti.
Come illustrato nella figura 4-5, i volumi Docker normali possono essere archiviati fuori dai contenitori stessi, ma all'interno dei limiti fisici del server host o della macchina virtuale. Tuttavia, i contenitori Docker non possono accedere a un volume da un server host o da una macchina virtuale a un'altra. In altre parole, con questi volumi non è possibile gestire i dati condivisi tra contenitori che vengono eseguiti in host Docker diversi. A tale scopo, si può tuttavia usare un driver del volume che supporta gli host remoti.
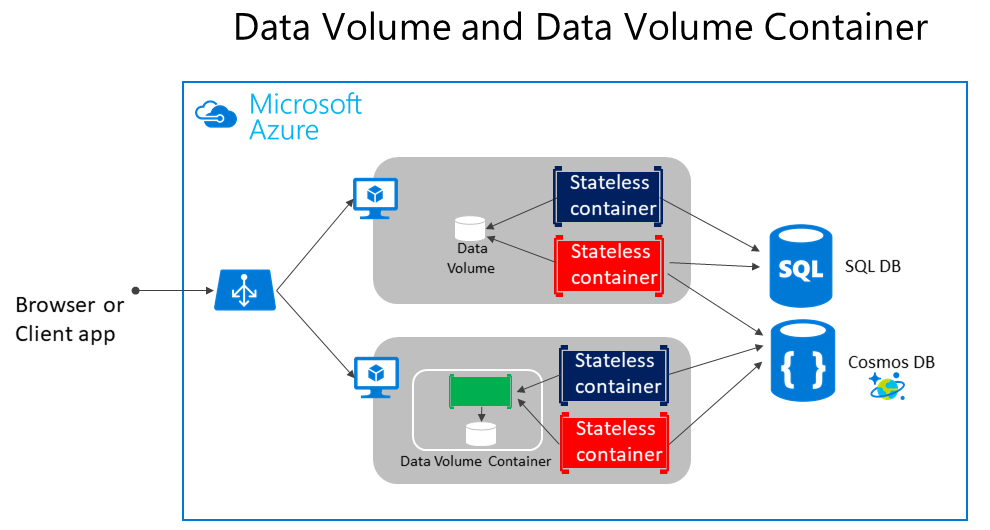
Figura 4-5. Volumi di dati e origini dati esterne per applicazioni basate su contenitore
I volumi possono essere condivisi tra contenitori, ma solo nello stesso host, a meno che non si usi un driver remoto che supporta host remoti. Quando i contenitori Docker vengono gestiti da un agente di orchestrazione, i contenitori possono anche "spostarsi" tra gli host, a seconda delle ottimizzazioni eseguite dal cluster. Non è quindi consigliabile usare i volumi di dati per i dati aziendali. Tuttavia, possono essere efficaci quando si lavora con file di traccia, file temporanei o file simili che non influiscono sulla coerenza dei dati aziendali.
Gli strumenti per le origini dati remote e la cache, ad esempio i database SQL di Azure, Azure Cosmos DB o le cache remote come Redis, possono essere usati nelle applicazioni incluse in contenitori allo stesso modo con cui vengono usati durante lo sviluppo senza contenitori. Si tratta di un modo consolidato per archiviare i dati delle applicazioni aziendali.
Archiviazione di Azure. I dati aziendali in genere devono essere inseriti in risorse o database esterni, ad esempio Archiviazione di Azure. Archiviazione di Azure fornisce essenzialmente i servizi seguenti nel cloud:
L'archiviazione BLOB archivia i dati oggetto non strutturati. Un BLOB può essere costituito da qualsiasi tipo di dati di testo o binari, ad esempio documenti o file multimediali (file di immagini, audio e video). L'archivio BLOB è anche denominato archivio di oggetti.
L'archiviazione dei file offre un'archiviazione condivisa per le applicazioni legacy usando il protocollo SMB standard. Le macchine virtuali di Azure e i servizi cloud possono condividere i dati dei file nei componenti delle applicazioni tramite condivisioni montate. Le applicazioni locali possono accedere ai dati dei file in una condivisione tramite l'API REST del Servizio file.
L'Archiviazione tabelle archivia set di dati strutturati. L'archiviazione tabelle è un archivio dati chiave-attributo NoSQL, che consente di sviluppare e di accedere rapidamente a quantità elevate di dati.
Database relazionali e database NoSQL. Esistono numerose opzioni per i database esterni, dai database relazionali come SQL Server, PostgreSQL, Oracle o NoSQL ai database NoSQL come Azure Cosmos DB, MongoDB e così via. Questi database non verranno spiegati in questa guida perché riguardano un argomento completamente diverso.