Sottoscrizione di eventi
Suggerimento
Questo contenuto è un estratto dell'eBook "Microservizi .NET: Architettura per le applicazioni .NET incluse in contenitori", disponibile in .NET Docs o come PDF scaricabile gratuitamente e da poter leggere offline.

Il primo passaggio per poter usare il bus eventi consiste nel sottoscrivere i microservizi agli eventi che devono ricevere. Tale funzionalità deve essere eseguita nei microservizi di tipo ricevitore.
Il semplice codice seguente mostra che cosa ogni microservizio di tipo ricevitore deve implementare all'avvio del servizio, ovvero nella classe Startup, per poter sottoscrivere gli eventi necessari. In questo caso il microservizio basket-api deve sottoscrivere i messaggi ProductPriceChangedIntegrationEvent e OrderStartedIntegrationEvent.
Con la sottoscrizione dell'evento ProductPriceChangedIntegrationEvent, ad esempio, il microservizio basket è in grado di riconoscere eventuali modifiche apportate al prezzo di un prodotto e di avvertire l'utente della modifica se tale prodotto è presente nel carrello dell'utente.
var eventBus = app.ApplicationServices.GetRequiredService<IEventBus>();
eventBus.Subscribe<ProductPriceChangedIntegrationEvent,
ProductPriceChangedIntegrationEventHandler>();
eventBus.Subscribe<OrderStartedIntegrationEvent,
OrderStartedIntegrationEventHandler>();
Dopo l'esecuzione di questo codice il microservizio del sottoscrittore sarà in ascolto tramite i canali RabbitMQ. Quando arrivano messaggi di tipo ProductPriceChangedIntegrationEvent, il codice richiama il gestore dell'evento che è stato passato ad esso ed elabora l'evento.
Pubblicazione di eventi tramite il bus di eventi
Il mittente del messaggio (microservizio di origine) pubblica infine gli eventi di integrazione con codice simile all'esempio seguente. Questo approccio è un esempio semplificato che non tiene conto dell'atomicità. È opportuno implementare codice simile ogni volta che un evento deve essere propagato in più microservizi, in genere subito dopo il commit di dati o transazioni dal microservizio di origine.
Per iniziare, l'oggetto di implementazione del bus di eventi (basato su RabbitMQ o su un bus di servizio) verrà inserito a livello del costruttore del costruttore, come illustrato nel codice seguente:
[Route("api/v1/[controller]")]
public class CatalogController : ControllerBase
{
private readonly CatalogContext _context;
private readonly IOptionsSnapshot<Settings> _settings;
private readonly IEventBus _eventBus;
public CatalogController(CatalogContext context,
IOptionsSnapshot<Settings> settings,
IEventBus eventBus)
{
_context = context;
_settings = settings;
_eventBus = eventBus;
}
// ...
}
L'oggetto può quindi essere usato dai metodi del controller, come nel metodo UpdateProduct:
[Route("items")]
[HttpPost]
public async Task<IActionResult> UpdateProduct([FromBody]CatalogItem product)
{
var item = await _context.CatalogItems.SingleOrDefaultAsync(
i => i.Id == product.Id);
// ...
if (item.Price != product.Price)
{
var oldPrice = item.Price;
item.Price = product.Price;
_context.CatalogItems.Update(item);
var @event = new ProductPriceChangedIntegrationEvent(item.Id,
item.Price,
oldPrice);
// Commit changes in original transaction
await _context.SaveChangesAsync();
// Publish integration event to the event bus
// (RabbitMQ or a service bus underneath)
_eventBus.Publish(@event);
// ...
}
// ...
}
In questo caso, dal momento che il microservizio di origine è un semplice microservizio CRUD, tale codice viene inserito direttamente in un controller API Web.
In microservizi più avanzati, ad esempio quando si usano approcci basati su CQRS, può essere implementato nella classe CommandHandler, all'interno del metodo Handle().
Progettazione di atomicità e resilienza quando si esegue la pubblicazione nel bus di eventi
Quando si pubblicano eventi di integrazione tramite un sistema di messaggistica distribuito, quale il bus di eventi, si presenta il problema dell'aggiornamento del database originale e della pubblicazione di un evento in modo atomico (ovvero, il completamento di entrambe le operazioni o di nessuna delle due). Nell'esempio semplificato illustrato in precedenza il codice esegue, ad esempio, il commit dei dati nel database in caso di modifica del prezzo del prodotto e quindi pubblica un messaggio ProductPriceChangedIntegrationEvent. Inizialmente, potrebbe risultare fondamentale che queste due operazioni vengano eseguite in modo atomico. Se però si usa una transazione distribuita che interessa il database e il broker messaggi, come in sistemi meno recenti quali Microsoft Message Queuing (MSMQ), questo approccio non è consigliabile per i motivi descritti dal teorema CAP.
In pratica, si usano i microservizi per creare sistemi scalabili e a disponibilità elevata. Per semplificare, il teorema CAP afferma che non è possibile creare un database (distribuito), o un microservizio proprietario del proprio modello, che sia continuamente disponibile, assolutamente coerente e tollerante di qualsiasi partizione. È necessario scegliere due di queste tre proprietà.
Nelle architetture basate su microservizi è consigliabile scegliere disponibilità e tolleranza, dando minore importanza alla coerenza assoluta. Di conseguenza, nella maggior parte delle moderne applicazioni basate su microservizi si preferisce in genere non usare transazioni distribuite nella messaggistica, come si fa quando si implementano le transazioni distribuite basate su Windows Distributed Transaction Coordinator (DTC) con MSMQ.
Torniamo indietro al problema iniziale e al relativo esempio. Se si verifica un arresto anomalo del servizio dopo l'aggiornamento del database (in questo caso, subito dopo la riga di codice con _context.SaveChangesAsync()), ma prima della pubblicazione dell'evento di integrazione, l'intero sistema potrebbe risultare incoerente. Potrebbe trattarsi di un approccio business critical, a seconda della specifica operazione di business gestita.
Come accennato in precedenza nella sezione relativa all'architettura, è possibile adottare diversi approcci per gestire questo problema:
Uso dello schema Event Sourcing completo.
Uso dell'estrazione del log delle transazioni.
Uso dello schema Outbox. Si tratta di una tabella transazionale per archiviare gli eventi di integrazione (estendendo la transazione locale).
Per questo scenario uno degli approcci migliori, se non il migliore, consiste nell'usare lo schema Event Sourcing completo. In molti scenari di applicazione, tuttavia, potrebbe non essere possibile implementare un sistema Event Sourcing completo. Lo schema Event Sourcing implica l'archiviazione dei soli eventi di dominio nel database transazionale, anziché dei dati relativi allo stato corrente. L'archiviazione dei soli eventi di dominio può presentare notevoli vantaggi, consentendo ad esempio di poter disporre della cronologia di sistema e poter determinare lo stato del sistema in qualsiasi momento nel passato. L'implementazione di un sistema Event Sourcing completo richiede però la ridefinizione dell'architettura della maggior parte del sistema e implica molti altri requisiti e complessità. Si supponga, ad esempio, di voler usare un database appositamente pensato per lo schema Event Sourcing, come Event Store, oppure un database orientato ai documenti, come Azure Cosmos DB, MongoDB, Cassandra, CouchDB o RavenDB. Lo schema Event Sourcing costituisce un valido approccio a questo problema, ma non è la soluzione più semplice a meno che non si abbia già familiarità con Event Sourcing.
L'approccio basato sull'estrazione del log delle transazioni sembra inizialmente agevole. Per usare questo approccio, però, è necessario accoppiare il microservizio al log delle transazioni RDBMS, ad esempio il log delle transazioni di SQL Server Tale approccio non è probabilmente auspicabile. Un altro svantaggio è che gli aggiornamenti di basso livello registrati nel log delle transazioni potrebbero non essere allo stesso livello degli eventi di integrazione di alto livello. In questo caso il processo di decompilazione di tali operazioni del log delle transazioni può risultare complesso.
Per un approccio bilanciato è possibile combinare una tabella di database transazionale e un schema Event Sourcing semplificato. È possibile usare uno stato quale "pronto per la pubblicazione dell'evento", che viene impostato nell'evento originale quando se ne esegue il commit nella tabella eventi di integrazione. Si prova quindi a pubblicare l'evento nel bus di eventi. Se l'azione dell'evento di pubblicazione viene completata, si può avviare un'altra transazione nel servizio di origine e cambiare lo stato da "pronto per la pubblicazione dell'evento" in "evento già pubblicato".
Se l'azione dell'evento di pubblicazione nel bus di eventi non viene completata, i dati non saranno ancora incoerenti all'interno di microservizio di origine (perché sono ancora contrassegnati come "pronto per la pubblicazione dell'evento") e alla fine saranno coerenti rispetto al resto dei servizi. È sempre possibile usare processi in background per controllare lo stato delle transazioni o degli eventi di integrazione. Se il processo trova un evento nello stato "pronto per la pubblicazione dell'evento", può provare a ripubblicarlo nel bus di eventi.
Si noti che con questo approccio, si rendono persistenti solo gli eventi di integrazione per ogni microservizio di origine e solo gli eventi che si vogliono comunicare ad altri microservizi o sistemi esterni. Al contrario, in un sistema Event Sourcing, vengono archiviati anche tutti gli eventi di dominio.
Questo approccio bilanciato è quindi un sistema Event Sourcing semplificato. È necessario un elenco di eventi di integrazione con lo stato corrente ("pronto per la pubblicazione" e "pubblicato"). ma è necessario implementare questi stati solo per gli eventi di integrazione. In questo approccio, inoltre, non è necessario archiviare tutti i dati di dominio come eventi nel database transazionale, come si farebbe in un sistema Event Sourcing completo.
Se si usa già un database relazionale, è possibile usare una tabella transazionale peer archiviare gli eventi di integrazione. Per ottenere l'atomicità nell'applicazione, si usa un processo in due passaggi basato su transazioni locali. In pratica, nello stesso database che contiene le entità di dominio è presente una tabella IntegrationEvent. Tale tabella funge da assicurazione per garantire l'atomicità in modo che gli eventi di integrazione persistenti vengano inclusi nelle stesse transazioni che stanno eseguendo il commit dei dati di dominio.
Nel dettaglio il processo è il seguente:
L'applicazione avvia una transazione di database locale.
quindi aggiorna lo stato delle entità di dominio e inserisce un evento nella tabella eventi di integrazione
Infine esegue il commit della transazione, in modo da consentire di ottenere l'atomicità desiderata e quindi
L'evento viene pubblicato in qualche modo (passaggio successivo).
Quando si implementano i passaggi per la pubblicazione degli eventi, è possibile scegliere una delle opzioni seguenti:
Pubblicare l'evento di integrazione subito dopo il commit della transazione e usare un'altra transazione locale per contrassegnare gli eventi nella tabella come in corso di pubblicazione. Usare quindi la tabella come un artefatto per tenere traccia degli eventi di integrazione in caso di problemi nei microservizi remoti ed eseguire le azioni di compensazione sulla base degli eventi di integrazione archiviati.
Usare la tabella come una sorta di coda. Un processo o un thread applicazione separato esegue una query sulla tabella eventi di integrazione, pubblica gli eventi nel bus di eventi e quindi usa una transazione locale per contrassegnare gli eventi come pubblicati.
La figura 6-22 illustra l'architettura relativa al primo di questi approcci.
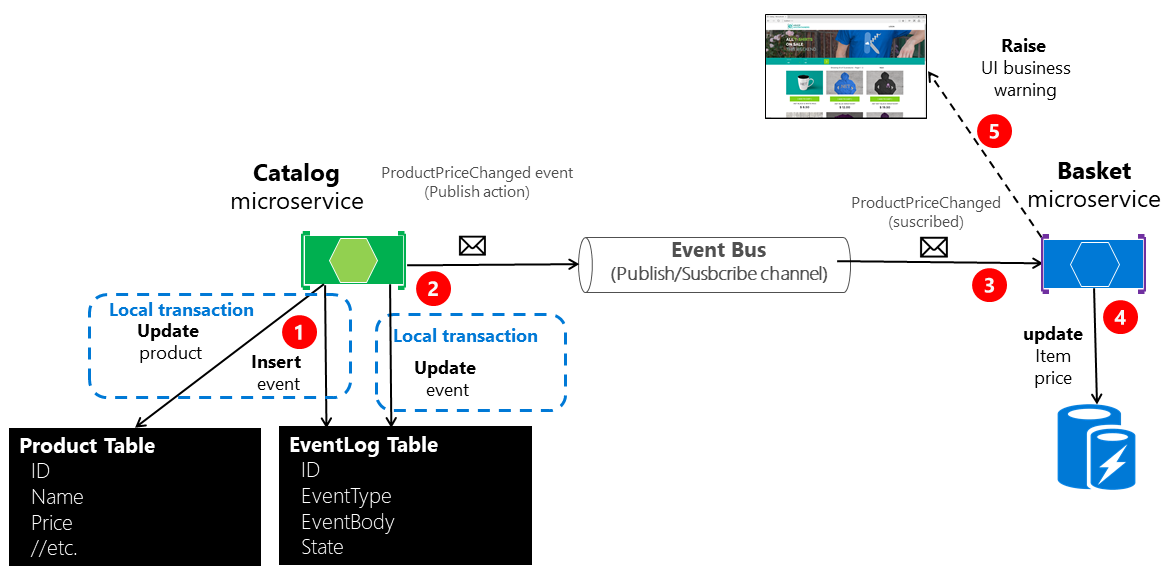
Figura 6-22. Atomicità durante la pubblicazione di eventi nel bus di eventi
Nell'approccio illustrato nella figura 6-22 manca un microservizio worker aggiuntivo che è responsabile della verifica e della conferma del completamento degli eventi di integrazione pubblicati. In caso di errore, il microservizio worker aggiuntivo è in grado di leggere gli eventi dalla tabella e ripubblicarli, ovvero di ripetere il passaggio numero 2.
Nel secondo approccio si usa invece la tabella EventLog come coda e si usa sempre un microservizio worker per pubblicare i messaggi. Il processo corrispondente è simile a quello illustrato nella figura 6-23, in cui viene illustrato un microservizio aggiuntivo, mentre la tabella è l'unica origine durante la pubblicazione di eventi.
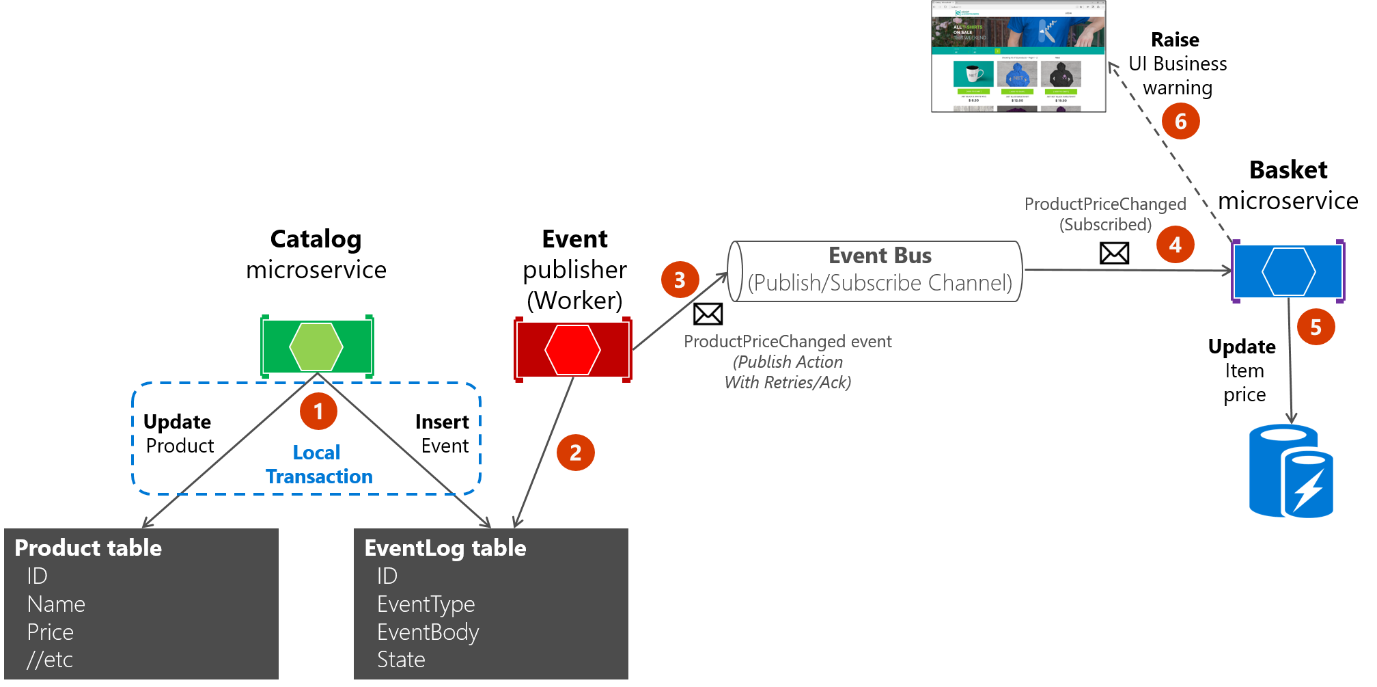
Figura 6-23. Atomicità durante la pubblicazione di eventi nel bus di eventi con un microservizio worker
Per semplicità, nell'esempio eShopOnContainers viene usato il primo approccio (senza processi o microservizi di controllo aggiuntivi) oltre al bus di eventi. Tuttavia, l'esempio eShopOnContainers non gestisce tutti i possibili casi di errore. In un'applicazione reale distribuita nel cloud è necessario accettare il fatto che i problemi sono inevitabili e che è necessario implementare la logica di verifica e reinvio. L'uso della tabella come coda può essere più efficace rispetto al primo approccio se la tabella costituisce l'unica origine degli eventi durante la pubblicazione (con il worker) tramite il bus di eventi.
Implementazione dell'atomicità durante la pubblicazione di eventi di integrazione tramite il bus di eventi
Il codice seguente mostra come creare una singola transazione che interessa più oggetti DbContext, ovvero un contesto correlato ai dati originali da aggiornare e un secondo contesto correlato alla tabella IntegrationEventLog.
La transazione nell'esempio di codice seguente non sarà resiliente se le connessioni al database presentano problemi nel momento in cui viene eseguito il codice. Questa situazione può verificarsi in sistemi basati sul cloud come Azure SQL DB, che potrebbe spostare database tra server. Per l'implementazione di transazioni resilienti in più contesti, vedere la sezione Implementazione di connessioni SQL resilienti di Entity Framework Core più avanti in questa guida.
Per chiarezza l'esempio seguente mostra l'intero processo in un unico frammento di codice. L'implementazione di eShopOnContainers viene tuttavia sottoposta a refactoring e questa logica viene suddivisa in più classi in modo che sia più facilmente gestibile.
// Update Product from the Catalog microservice
//
public async Task<IActionResult> UpdateProduct([FromBody]CatalogItem productToUpdate)
{
var catalogItem =
await _catalogContext.CatalogItems.SingleOrDefaultAsync(i => i.Id ==
productToUpdate.Id);
if (catalogItem == null) return NotFound();
bool raiseProductPriceChangedEvent = false;
IntegrationEvent priceChangedEvent = null;
if (catalogItem.Price != productToUpdate.Price)
raiseProductPriceChangedEvent = true;
if (raiseProductPriceChangedEvent) // Create event if price has changed
{
var oldPrice = catalogItem.Price;
priceChangedEvent = new ProductPriceChangedIntegrationEvent(catalogItem.Id,
productToUpdate.Price,
oldPrice);
}
// Update current product
catalogItem = productToUpdate;
// Just save the updated product if the Product's Price hasn't changed.
if (!raiseProductPriceChangedEvent)
{
await _catalogContext.SaveChangesAsync();
}
else // Publish to event bus only if product price changed
{
// Achieving atomicity between original DB and the IntegrationEventLog
// with a local transaction
using (var transaction = _catalogContext.Database.BeginTransaction())
{
_catalogContext.CatalogItems.Update(catalogItem);
await _catalogContext.SaveChangesAsync();
await _integrationEventLogService.SaveEventAsync(priceChangedEvent);
transaction.Commit();
}
// Publish the integration event through the event bus
_eventBus.Publish(priceChangedEvent);
_integrationEventLogService.MarkEventAsPublishedAsync(
priceChangedEvent);
}
return Ok();
}
Dopo la creazione dell'evento di integrazione ProductPriceChangedIntegrationEvent, la transazione in cui è archiviata l'operazione di dominio originale (aggiornamento dell'elemento del catalogo) include anche la persistenza dell'evento nella tabella EventLog. In questo modo diventa una singola transazione e sarà sempre possibile verificare se i messaggi di evento sono stati inviati.
La tabella del log eventi viene aggiornata in modo atomico con l'operazione di database originale, usando una transazione locale sullo stesso database. Se una qualsiasi delle operazioni non riesce, viene generata un'eccezione e la transazione esegue il rollback di qualsiasi operazione completata, in modo da garantire la coerenza tra le operazioni di dominio e i messaggi di evento salvati nella tabella.
Ricezione di messaggi dalle sottoscrizioni: gestori degli eventi in microservizi di tipo ricevitore
Oltre alla logica di sottoscrizione degli eventi, è necessario implementare il codice interno per i gestori degli eventi di integrazione, ad esempio un metodo di callback. Nel gestore dell'evento viene specificato dove verranno ricevuti ed elaborati i messaggi di evento di un determinato tipo.
Un gestore dell'evento riceve prima un'istanza di evento dal bus di eventi. Successivamente individua il componente da elaborare in relazione all'evento di integrazione, propagando l'evento e rendendolo persistente come modifica di stato nel microservizio di tipo ricevitore. Ad esempio, se un evento ProductPriceChanged ha origine nel microservizio Catalog, viene gestito nel microservizio basket e cambia lo stato in questo microservizio Basket di tipo ricevitore, come illustrato nel codice seguente.
namespace Microsoft.eShopOnContainers.Services.Basket.API.IntegrationEvents.EventHandling
{
public class ProductPriceChangedIntegrationEventHandler :
IIntegrationEventHandler<ProductPriceChangedIntegrationEvent>
{
private readonly IBasketRepository _repository;
public ProductPriceChangedIntegrationEventHandler(
IBasketRepository repository)
{
_repository = repository;
}
public async Task Handle(ProductPriceChangedIntegrationEvent @event)
{
var userIds = await _repository.GetUsers();
foreach (var id in userIds)
{
var basket = await _repository.GetBasket(id);
await UpdatePriceInBasketItems(@event.ProductId, @event.NewPrice, basket);
}
}
private async Task UpdatePriceInBasketItems(int productId, decimal newPrice,
CustomerBasket basket)
{
var itemsToUpdate = basket?.Items?.Where(x => int.Parse(x.ProductId) ==
productId).ToList();
if (itemsToUpdate != null)
{
foreach (var item in itemsToUpdate)
{
if(item.UnitPrice != newPrice)
{
var originalPrice = item.UnitPrice;
item.UnitPrice = newPrice;
item.OldUnitPrice = originalPrice;
}
}
await _repository.UpdateBasket(basket);
}
}
}
}
Il gestore dell'evento deve verificare se il prodotto è presente in una delle istanze del carrello, aggiorna il prezzo dell'articolo per ogni articolo del carrello correlato e infine crea un avviso da visualizzare all'utente sulla variazione di prezzo, come illustrato nella figura 6-24.
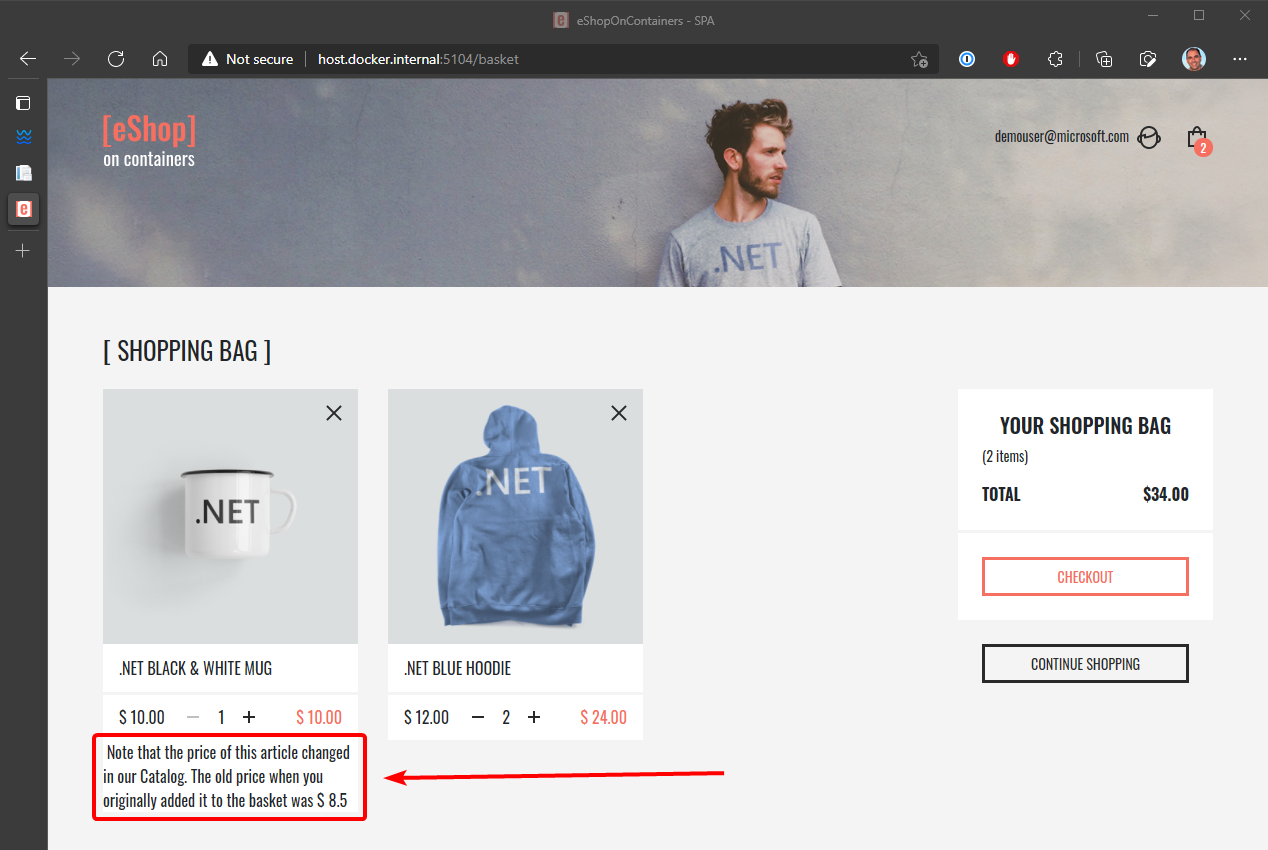
Figura 6-24. Visualizzazione di una variazione di prezzo dell'articolo in un carrello, comunicato dagli eventi di integrazione
Idempotenza negli eventi dei messaggi di aggiornamento
Un aspetto importante degli eventi dei messaggi di aggiornamento è che il messaggio deve essere nuovamente inviato in seguito a un errore che si verifica in un qualsiasi punto nelle comunicazioni. In caso contrario, un'attività in background potrebbe provare a pubblicare un evento che è già stato pubblicato, creando una condizione di race condition. Assicurarsi che gli aggiornamenti siano idempotenti o che forniscano informazioni sufficienti a garantire il rilevamento di un duplicato, la sua rimozione e il reinvio di una sola risposta.
Come notato in precedenza, con il termine idempotenza si indica un'operazione che può essere eseguita più volte senza modificare il risultato. In un ambiente di messaggistica, come durante la comunicazione di eventi, un evento è idempotente se può essere recapitato più volte senza modificare il risultato per il microservizio di tipo ricevitore. Tale condizione potrebbe essere necessaria in virtù della natura dell'evento stesso o del modo in cui il sistema gestisce l'evento. L'idempotenza dei messaggi è importante in qualsiasi applicazione che usa la messaggistica, non solo nelle applicazioni che implementano lo schema del bus di eventi.
Un esempio di un'operazione idempotente è dato da un'istruzione SQL che inserisce dati in una tabella solo se i dati non sono già presenti nella tabella. Non conta il numero di volte in cui si esegue l'istruzione SQL di inserimento: il risultato sarà lo stesso, ovvero la tabella conterrà tali dati. Un tale tipo di idempotenza può essere necessario anche quando si gestiscono i messaggi se il messaggio potrebbe potenzialmente essere inviato e di conseguenza elaborato più di una volta. Se, ad esempio, in base alla logica di ripetizione un mittente invia più volte lo stesso messaggio, è necessario assicurarsi che sia idempotente.
È possibile progettare messaggi idempotenti. Ad esempio, è possibile creare un evento che indica "imposta il prezzo del prodotto su 25 USD" invece di "aggiungi 5 USD al prezzo del prodotto". Mentre è possibile elaborare senza problemi il primo messaggio un qualsiasi numero di volte, ottenendo sempre lo stesso risultato, non si può dire altrettanto per il secondo messaggio. Ma anche nel primo caso è possibile che non si voglia elaborare il primo evento perché il sistema potrebbe aver inviato un evento di variazione del prezzo più recente e l'elaborazione del primo evento causerebbe la sovrascrittura del nuovo prezzo.
Un altro esempio è dato da un evento di completamento dell'ordine che viene propagato a più sottoscrittori. L'app deve assicurarsi che le informazioni sugli ordini vengano aggiornate in altri sistemi una sola volta, anche se sono presenti eventi di messaggio duplicati per lo stesso evento di completamento dell'ordine.
È consigliabile definire un certo tipo di identità per ogni evento in modo che sia possibile creare la logica in base alla quale ogni evento deve essere elaborato una sola volta per ogni ricevitore.
Alcune operazioni di elaborazione dei messaggi sono intrinsecamente idempotenti. Se, ad esempio, un sistema genera le anteprime delle immagini, non conta il numero di volte in cui viene elaborato il messaggio relativo all'anteprima generata. Il risultato è che le anteprime vengono generate e sono uguali ogni volta. D'altra parte, operazioni quali la chiamata di un gateway di pagamento per ricaricare una carta di credito potrebbero non essere affatto idempotenti. In questi casi è necessario assicurarsi che l'effetto dell'elaborazione di un messaggio per più volte sia quello desiderato.
Risorse aggiuntive
- Honoring message idempotency (Rispetto dell'idempotenza dei messaggi)
https://learn.microsoft.com/previous-versions/msp-n-p/jj591565(v=pandp.10)#honoring-message-idempotency
Deduplicazione dei messaggi degli eventi di integrazione
È possibile assicurarsi che gli eventi dei messaggi vengano inviati ed elaborati una sola volta per ogni sottoscrittore a livelli diversi. Un modo consiste nell'usare una funzionalità di deduplicazione offerta dall'infrastruttura di messaggistica in uso. Un altro consiste nell'implementare logica personalizzata nel microservizio di destinazione. La scelta migliore consiste nell'eseguire convalide sia a livello di trasporto che a livello di applicazione.
Deduplicazione degli eventi di messaggio a livello di gestore dell'evento
Un modo per assicurarsi che un evento venga elaborato una sola volta da qualsiasi ricevitore consiste nell'implementare una determinata logica durante l'elaborazione degli eventi dei messaggi nei gestori degli eventi. Questo è ad esempio l'approccio usato nell'applicazione eShopOnContainers, come si può vedere nel codice sorgente della classe UserCheckoutAcceptedIntegrationEventHandler quando riceve un evento di integrazione UserCheckoutAcceptedIntegrationEvent. In questo caso, viene eseguito il wrapping di CreateOrderCommand con un oggetto IdentifiedCommand, usando eventMsg.RequestId come identificatore, prima di inviarlo al gestore dei comandi.
Deduplicazione dei messaggi quando si usa RabbitMQ
Quando si verificano errori di rete intermittenti, è possono duplicare i messaggi, ma il ricevitore dei messaggi deve essere pronto per gestire questi messaggi duplicati. Se possibile, i ricevitori devono gestire i messaggi in modo idempotente. Questo approccio è preferibile rispetto a quando vengono gestiti in modo esplicito con la deduplicazione.
Secondo quando indicato nella documentazione di RabbitMQ, "se un messaggio viene recapitato a un consumer e quindi reinserito nella coda, perché ad esempio non è stato confermato prima dell'eliminazione della connessione al consumer, RabbitMQ imposterà il flag di nuovo recapito dopo il successivo recapito allo stesso o a un altro consumer".
Se il flag di "nuovo recapito" è impostato, il ricevitore deve tenerlo in considerazione perché il messaggio potrebbe essere già stato elaborato. Questo non è però garantito. Il messaggio potrebbe non aver mai raggiunto il ricevitore dopo che ha lasciato il broker di messaggi, probabilmente a causa di problemi di rete. D'altra parte, se il flag di "nuovo recapito" non è impostato, si può essere certi che il messaggio non è stato inviato più volte. Il ricevitore deve quindi deduplicare i messaggi o elaborarli in modo idempotente solo se nel messaggio è impostato il flag di nuovo recapito.
Risorse aggiuntive
Fork di eShopOnContainers tramite NServiceBus (Particular Software)
https://go.particular.net/eShopOnContainersMessaggistica basata su eventi
https://patterns.arcitura.com/soa-patterns/design_patterns/event_driven_messagingJimmy Bogard. Refactoring Towards Resilience: Evaluating Coupling (Refactoring e resilienza: valutazione dell'accoppiamento)
https://jimmybogard.com/refactoring-towards-resilience-evaluating-coupling/Canale di pubblicazione-sottoscrizione
https://www.enterpriseintegrationpatterns.com/patterns/messaging/PublishSubscribeChannel.htmlComunicazione tra contesti delimitati
https://learn.microsoft.com/previous-versions/msp-n-p/jj591572(v=pandp.10)Coerenza finale
https://en.wikipedia.org/wiki/Eventual_consistencyPhilip Brown. Strategie per l'integrazione di contesti delimitati
https://www.culttt.com/2014/11/26/strategies-integrating-bounded-contexts/Chris Richardson. Sviluppo di microservizi transazionali usando aggregazioni, Event Sourcing e CQRS - Parte 2
https://www.infoq.com/articles/microservices-aggregates-events-cqrs-part-2-richardsonChris Richardson. Modello di origine eventi
https://microservices.io/patterns/data/event-sourcing.htmlIntroduzione a Event Sourcing
https://learn.microsoft.com/previous-versions/msp-n-p/jj591559(v=pandp.10)Database di Event Store. Sito ufficiale.
https://geteventstore.com/Patrick Nommensen. Gestione di dati basati su eventi per microservizi
https://dzone.com/articles/event-driven-data-management-for-microservices-1Il teorema CAP
https://en.wikipedia.org/wiki/CAP_theoremChe cos'è il teorema CAP
https://www.quora.com/What-Is-CAP-Theorem-1Nozioni di base sulla coerenza dei dati
https://learn.microsoft.com/previous-versions/msp-n-p/dn589800(v=pandp.10)Rick Saling. Il teorema CAP: perché "tutto è diverso" con il cloud e Internet
https://learn.microsoft.com/archive/blogs/rickatmicrosoft/the-cap-theorem-why-everything-is-different-with-the-cloud-and-internet/Eric Brewer. CAP Twelve Years Later: How the "Rules" Have Changed (CAP dodici anni dopo: come sono cambiate le "regole")
https://www.infoq.com/articles/cap-twelve-years-later-how-the-rules-have-changedCAP, PACELC e microservizi
https://ardalis.com/cap-pacelc-and-microservices/Bus di servizio di Azure. Brokered Messaging: Duplicate Detection (Messaggistica negoziata: rilevamento duplicati)
https://github.com/microsoftarchive/msdn-code-gallery-microsoft/tree/master/Windows%20Azure%20Product%20Team/Brokered%20Messaging%20Duplicate%20DetectionReliability Guide (Guida all'affidabilità), documentazione RabbitMQ
https://www.rabbitmq.com/reliability.html#consumer