Esercitazione: Creare un film consigliato usando la fattorizzazione matrice con ML.NET
In questa esercitazione viene illustrato come creare un sistema di raccomandazione di film con ML.NET in un'applicazione console .NET Core. I passaggi usano C# e Visual Studio 2019.
In questa esercitazione verranno illustrate le procedure per:
- Selezionare un algoritmo di Machine Learning
- Preparare e caricare i dati
- Creare un modello ed eseguirne il training
- Valutare un modello
- Distribuire e usare un modello
È possibile trovare il codice sorgente per questa esercitazione nel repository dotnet/samples.
Flusso di lavoro di apprendimento automatico
Per completare questa attività, così come qualsiasi altra attività ML.NET, si useranno i passaggi seguenti:
Prerequisiti
Selezionare l'attività di apprendimento automatico appropriata
I problemi relativi alla raccomandazione, ad esempio la raccomandazione di un elenco di film o di un elenco di prodotti correlati, possono essere affrontati in diversi modi, ma in questo caso si effettuerà la previsione della valutazione (da 1 a 5) che un utente assegnerà a un determinato film e si raccomanderà il film se è stato valutato al di sopra di una soglia definita (tanto più elevata è la valutazione, quanto più elevata sarà la probabilità che a un utente piaccia un determinato film).
Creare un'applicazione console
Creare un progetto
Creare un'applicazione console C# denominata "MovieRecommender". Fare clic sul pulsante Next (Avanti).
Scegliere .NET 6 come framework da usare. Fare clic sul pulsante Crea.
Creare una directory denominata Data nel progetto per archiviare il set di dati:
In Esplora soluzioni fare clic con il pulsante destro del mouse sul progetto e scegliere Aggiungi>Nuova cartella. Digitare "Data" e premere INVIO.
Installare i pacchetti NuGet Microsoft.ML e Microsoft.ML.Recommender:
Nota
Questo esempio usa la versione stabile più recente dei pacchetti NuGet menzionati a meno che non sia specificato in altro modo.
In Esplora soluzioni fare clic con il pulsante destro del mouse sul progetto e scegliere Gestisci pacchetti NuGet. Scegliere "nuget.org" come Origine del pacchetto, selezionare la scheda Sfoglia, trovare Microsoft.ML, selezionare il pacchetto nell'elenco e quindi selezionare il pulsante Installa. Selezionare il pulsante OK nella finestra di dialogo Anteprima modifiche e quindi selezionare il pulsante Accetto nella finestra di dialogo Accettazione della licenza se si accettano le condizioni di licenza per i pacchetti elencati. Ripetere questi passaggi per Microsoft.ML.Recommender.
Aggiungere le istruzioni
usingseguenti all'inizio del file Program.cs:using Microsoft.ML; using Microsoft.ML.Trainers; using MovieRecommendation;
Scarica i tuoi dati
Scaricare i due set di dati e salvarli nella cartella Data precedentemente creata:
Fare clic con il pulsante destro del mouse su recommendation-ratings-train.csv e selezionare "Salva collegamento con nome..." o "Salva oggetto con nome..."
Fare clic con il pulsante destro del mouse su recommendation-ratings-test.csv e selezionare "Salva collegamento con nome..." o "Salva oggetto con nome..."
Assicurarsi di salvare i file *.csv nella cartella Dati o dopo averla salvata altrove, spostare i file *.csv nella cartella Dati .
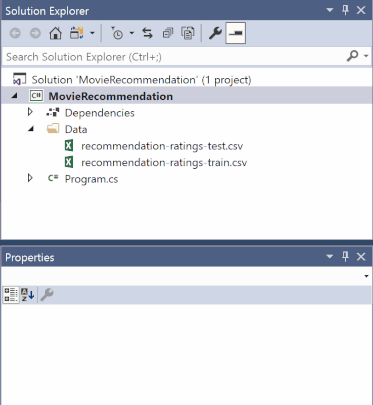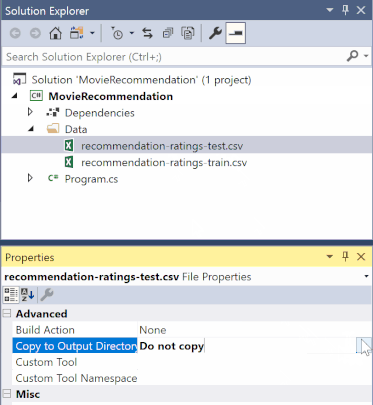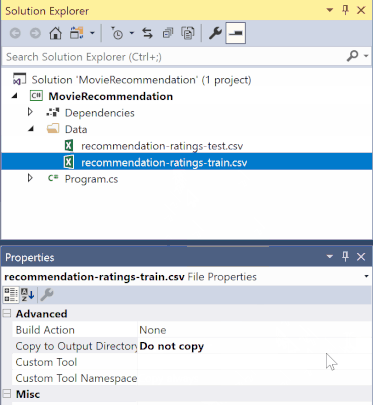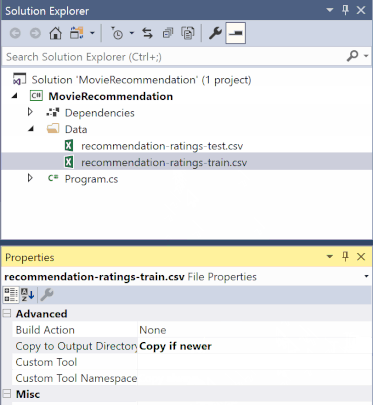
In Esplora soluzioni fare clic con il pulsante destro del mouse su ognuno dei file *.csv e selezionare Proprietà. In Avanzate modificare il valore di Copia in Directory di output in Copia se più recente.
Caricare i dati
Il primo passaggio del processo ML.NET è la preparazione e il caricamento dei dati di training e test del modello.
I dati delle valutazioni della raccomandazione vengono divisi in set di dati Train e Test. I dati Train vengono usati per il fit del modello. I dati Test vengono usati per effettuare previsioni con il modello sottoposto a training e valutarne le prestazioni. Per i dati Train e Test in genere si applica una suddivisione 80/20.
Di seguito è riportata un'anteprima dei dati dei file *.csv:
Nei file *.csv sono presenti quattro colonne:
userIdmovieIdratingtimestamp
Nel Machine Learning le colonne usate per effettuare una previsione sono denominate Features (Caratteristiche) e la colonna con la previsione restituita è denominata Label (Etichetta).
In questo caso si vuole prevedere le valutazioni di film, quindi la colonna della valutazione è la colonna Label. Le altre tre colonne, userId, movieId e timestamp, sono tutte Features usate per la previsione di Label.
| Funzionalità | Etichetta |
|---|---|
userId |
rating |
movieId |
|
timestamp |
È possibile decidere quali Features vengono usate per la previsione di Label. È anche possibile usare metodi come l'importanza della funzionalità permutazione per facilitare la selezione dei migliori Features.
In questo caso è consigliabile eliminare la colonna timestamp come Feature perché il timestamp in realtà non influisce sulla valutazione di un determinato film da parte di un utente e quindi non contribuisce a effettuare una previsione più accurata:
| Funzionalità | Etichetta |
|---|---|
userId |
rating |
movieId |
È quindi necessario definire la struttura dei dati per la classe di input.
Aggiungere una nuova classe al progetto:
In Esplora soluzioni fare clic con il pulsante destro del mouse sul progetto e quindi scegliere Aggiungi > nuovo elemento.
Nella finestra di dialogo Aggiungi nuovo elemento selezionare Classe e modificare il valore del campo Nome in MovieRatingData.cs. Selezionare quindi il pulsante Aggiungi.
Il file MovieRatingData.cs verrà aperto nell'editor di codice. Aggiungere l'istruzione using seguente all'inizio di MovieRatingData.cs:
using Microsoft.ML.Data;
Creare una classe denominata MovieRating rimuovendo la definizione di classe esistente e aggiungendo il codice seguente in MovieRatingData.cs:
public class MovieRating
{
[LoadColumn(0)]
public float userId;
[LoadColumn(1)]
public float movieId;
[LoadColumn(2)]
public float Label;
}
MovieRating specifica una classe di dati di input. L'attributo LoadColumn specifica quali colonne (in base all'indice delle colonne) nel set di dati è necessario caricare. Le colonne userId e movieId sono le Features, ovvero gli input che si forniranno al modello per la previsione di Label, e la colonna della valutazione è l'oggetto Label di cui si otterrà la previsione, ovvero l'output del modello.
Creare un'altra classe, MovieRatingPrediction, per rappresentare i risultati previsti aggiungendo il codice seguente dopo la classe MovieRating in MovieRatingData.cs:
public class MovieRatingPrediction
{
public float Label;
public float Score;
}
In Program.cs sostituire con Console.WriteLine("Hello World!") il codice seguente:
MLContext mlContext = new MLContext();
La classe MLContext è un punto di partenza per tutte le operazioni ML.NET e l'inizializzazione di mlContext crea un nuovo ambiente ML.NET che può essere condiviso tra gli oggetti del flusso di lavoro della creazione del modello. Dal punto di vista concettuale è simile a DBContext in Entity Framework.
Nella parte inferiore del file creare un metodo denominato LoadData():
(IDataView training, IDataView test) LoadData(MLContext mlContext)
{
}
Nota
Questo metodo restituisce un errore finché non si aggiungerà un'istruzione return nei passaggi seguenti.
Inizializzare le variabili di percorso dei dati, caricare i dati dai file con estensione csv e restituire i dati Train e Test come oggetti IDataView aggiungendo il codice seguente come riga successiva in LoadData():
var trainingDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "recommendation-ratings-train.csv");
var testDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "recommendation-ratings-test.csv");
IDataView trainingDataView = mlContext.Data.LoadFromTextFile<MovieRating>(trainingDataPath, hasHeader: true, separatorChar: ',');
IDataView testDataView = mlContext.Data.LoadFromTextFile<MovieRating>(testDataPath, hasHeader: true, separatorChar: ',');
return (trainingDataView, testDataView);
I dati in ML.NET sono rappresentati come interfaccia IDataView. IDataView è un modo flessibile ed efficiente di descrivere i dati tabulari (numerici e di testo). È possibile caricare dati da un file di testo o in tempo reale, ad esempio da un database SQL o file di log, in un oggetto IDataView.
LoadFromTextFile() definisce lo schema dei dati e legge il contenuto del file. Acquisisce le variabili di percorso dei dati e restituisce un oggetto IDataView. In questo caso viene specificato il percorso dei file Test e Train e vengono indicati sia l'intestazione del file di testo, in modo che il metodo possa usare correttamente i nomi di colonna, sia la virgola come separatore dei dati di tipo carattere (il separatore predefinito è una tabulazione).
Aggiungere il codice seguente per chiamare il LoadData() metodo e restituire i Train dati e Test :
(IDataView trainingDataView, IDataView testDataView) = LoadData(mlContext);
Creare il modello ed eseguirne il training
Creare il metodo BuildAndTrainModel() subito dopo il metodo LoadData(), usando il codice seguente:
ITransformer BuildAndTrainModel(MLContext mlContext, IDataView trainingDataView)
{
}
Nota
Questo metodo restituisce un errore finché non si aggiungerà un'istruzione return nei passaggi seguenti.
Definire le trasformazioni dei dati aggiungendo il codice seguente a BuildAndTrainModel():
IEstimator<ITransformer> estimator = mlContext.Transforms.Conversion.MapValueToKey(outputColumnName: "userIdEncoded", inputColumnName: "userId")
.Append(mlContext.Transforms.Conversion.MapValueToKey(outputColumnName: "movieIdEncoded", inputColumnName: "movieId"));
Poiché userId e movieId rappresentano utenti e titoli di film, non valori reali, viene usato il metodo MapValueToKey() per trasformare ogni userId e ogni movieId in una colonna chiave di tipo numerico Feature (un formato accettato dagli algoritmi di raccomandazione) e aggiungerle come nuove colonne del set di dati:
| userId | movieId | Etichetta | userIdEncoded | movieIdEncoded |
|---|---|---|---|---|
| 1 | 1 | 4 | userKey1 | movieKey1 |
| 1 | 3 | 4 | userKey1 | movieKey2 |
| 1 | 6 | 4 | userKey1 | movieKey3 |
Scegliere l'algoritmo di Machine Learning e aggiungerlo alle definizioni di trasformazione dei dati aggiungendo il codice seguente come riga successiva in BuildAndTrainModel():
var options = new MatrixFactorizationTrainer.Options
{
MatrixColumnIndexColumnName = "userIdEncoded",
MatrixRowIndexColumnName = "movieIdEncoded",
LabelColumnName = "Label",
NumberOfIterations = 20,
ApproximationRank = 100
};
var trainerEstimator = estimator.Append(mlContext.Recommendation().Trainers.MatrixFactorization(options));
MatrixFactorizationTrainer è l'algoritmo di training della raccomandazione. La fattorizzazione di matrice è un approccio comune alla raccomandazione quando si hanno a disposizione dati su come gli utenti hanno valutato i prodotti in passato, come nel caso dei set di dati usati in questa esercitazione. Per le situazioni in cui sono disponibili dati diversi, esistono altri algoritmi di raccomandazione. Per altre informazioni, vedere la sezione Altri algoritmi di raccomandazione più avanti in questo articolo.
In questo caso, l'algoritmo Matrix Factorization usa un metodo denominato "filtraggio collaborativo" il quale presuppone che se l'utente 1 ha la stessa opinione dell'utente 2 relativamente a un determinato problema, è probabile che l'utente 1 sia d'accordo con l'utente 2 riguardo a un altro problema.
Se ad esempio l'utente 1 e l'utente 2 valutano i film in modo simile, è probabile che all'utente 2 piaccia un film che l'utente 1 ha visto e a cui ha assegnato una valutazione elevata:
Incredibles 2 (2018) |
The Avengers (2012) |
Guardians of the Galaxy (2014) |
|
|---|---|---|---|
| Utente 1 | Ha visto e apprezzato il film | Ha visto e apprezzato il film | Ha visto e apprezzato il film |
| Utente 2 | Ha visto e apprezzato il film | Ha visto e apprezzato il film | Non l'ha visto - RACCOMANDARE il film |
Il trainer Matrix Factorization include diverse opzioni. Per altre informazioni, vedere la sezione Iperparametri dell'algoritmo più avanti in questo articolo.
Eseguire il fit del modello ai dati Train e restituire il modello sottoposto a training aggiungendo il codice seguente come riga successiva nel metodo BuildAndTrainModel():
Console.WriteLine("=============== Training the model ===============");
ITransformer model = trainerEstimator.Fit(trainingDataView);
return model;
Il metodo Fit() esegue il training del modello con il set di dati di training specificato. Tecnicamente il metodo esegue le definizioni Estimator trasformando i dati e applicando il training, quindi restituisce il modello sottoposto a training, ovvero un Transformer.
Per altre informazioni sul flusso di lavoro di training del modello in ML.NET, vedere Informazioni ML.NET e come funziona?
Aggiungere quanto segue come riga successiva di codice sotto la chiamata al metodo per chiamare BuildAndTrainModel() il metodo e restituire il modello sottoposto a LoadData() training:
ITransformer model = BuildAndTrainModel(mlContext, trainingDataView);
Valutare il modello
Dopo aver eseguito il training del modello, usare i dati di test per valutare le prestazioni del modello.
Creare il metodo EvaluateModel() subito dopo il metodo BuildAndTrainModel(), usando il codice seguente:
void EvaluateModel(MLContext mlContext, IDataView testDataView, ITransformer model)
{
}
Trasformare i dati Test aggiungendo il codice seguente a EvaluateModel():
Console.WriteLine("=============== Evaluating the model ===============");
var prediction = model.Transform(testDataView);
Il metodo Transform() effettua previsioni per più righe di input specificate di un set di dati di test.
Valutare il modello aggiungendo il codice seguente come riga successiva nel metodo EvaluateModel():
var metrics = mlContext.Regression.Evaluate(prediction, labelColumnName: "Label", scoreColumnName: "Score");
Dopo aver impostato la previsione, il metodo Evaluate() valuta il modello confrontando i valori stimati con gli oggetti Labels effettivi presenti nel set di dati di test e restituisce le metriche relative alle prestazioni del modello.
Stampare le metriche di valutazione nella console aggiungendo il codice seguente come riga successiva nel metodo EvaluateModel():
Console.WriteLine("Root Mean Squared Error : " + metrics.RootMeanSquaredError.ToString());
Console.WriteLine("RSquared: " + metrics.RSquared.ToString());
Aggiungere quanto segue come riga di codice successiva sotto la chiamata al metodo per chiamare il BuildAndTrainModel()EvaluateModel() metodo:
EvaluateModel(mlContext, testDataView, model);
A questo punto, l'output dovrebbe avere un aspetto simile al testo seguente:
=============== Training the model ===============
iter tr_rmse obj
0 1.5403 3.1262e+05
1 0.9221 1.6030e+05
2 0.8687 1.5046e+05
3 0.8416 1.4584e+05
4 0.8142 1.4209e+05
5 0.7849 1.3907e+05
6 0.7544 1.3594e+05
7 0.7266 1.3361e+05
8 0.6987 1.3110e+05
9 0.6751 1.2948e+05
10 0.6530 1.2766e+05
11 0.6350 1.2644e+05
12 0.6197 1.2541e+05
13 0.6067 1.2470e+05
14 0.5953 1.2382e+05
15 0.5871 1.2342e+05
16 0.5781 1.2279e+05
17 0.5713 1.2240e+05
18 0.5660 1.2230e+05
19 0.5592 1.2179e+05
=============== Evaluating the model ===============
Rms: 0.994051469730769
RSquared: 0.412556298844873
Questo output presenta 20 iterazioni. In ogni iterazione la misura di errore diminuisce ed è sempre più prossima allo 0.
La metrica root of mean squared error (RMS o RMSE) viene usata per misurare le differenze tra i valori stimati da un modello e quelli osservati in set di dati di test. Tecnicamente è la radice quadrata della media dei quadrati degli errori. Più basso è il valore, migliore è il modello.
R Squared indica il livello di adattamento dei dati a un modello. È compreso tra 0 e 1. Un valore pari a 0 indica che i dati sono casuali o non possono essere adattati al modello. Un valore pari a 1 indica che il modello corrisponde esattamente ai dati. Il punteggio R Squared deve essere il più vicino possibile a 1.
La creazione di modelli efficaci è un processo iterativo. Questo modello ha inizialmente una qualità inferiore, perché l'esercitazione usa set di dati di dimensioni contenute per consentire il training rapido del modello. Se non si è soddisfatti della qualità del modello, è possibile provare a migliorarla fornendo set di dati di training più grandi o scegliendo algoritmi di training diversi con iperparametri diversi per ogni algoritmo. Per altre informazioni, vedere la sezione Migliorare il modello più avanti.
Usare il modello
Ora è possibile usare il modello sottoposto a training per effettuare previsioni sui nuovi dati.
Creare il metodo UseModelForSinglePrediction() subito dopo il metodo EvaluateModel(), usando il codice seguente:
void UseModelForSinglePrediction(MLContext mlContext, ITransformer model)
{
}
Usare PredictionEngine per prevedere la valutazione aggiungendo il codice seguente a UseModelForSinglePrediction():
Console.WriteLine("=============== Making a prediction ===============");
var predictionEngine = mlContext.Model.CreatePredictionEngine<MovieRating, MovieRatingPrediction>(model);
PredictionEngine è un'API pratico, che consente di eseguire una stima in una singola istanza di dati. PredictionEngine non è thread-safe. È accettabile usare in ambienti a thread singolo o prototipo. Per migliorare le prestazioni e la sicurezza dei thread negli ambienti di produzione, usare il PredictionEnginePool servizio, che crea un ObjectPool oggetto da PredictionEngine usare in tutta l'applicazione. Vedere questa guida su come usare PredictionEnginePool in un'API Web di ASP.NET Core.
Nota
L'estensione del servizio PredictionEnginePool è attualmente in anteprima.
Creare un'istanza di MovieRating denominata testInput e passarla al motore di previsione aggiungendo il codice seguente come righe successive nel metodo UseModelForSinglePrediction():
var testInput = new MovieRating { userId = 6, movieId = 10 };
var movieRatingPrediction = predictionEngine.Predict(testInput);
La funzione Predict() effettua una previsione su una singola colonna di dati.
È quindi possibile usare Score, o la valutazione prevista, per determinare se si vuole raccomandare il film con movieId 10 all'utente 6. Tanto più elevato è il valore di Score, quanto più elevata sarà la probabilità che a un utente piaccia un determinato film. In questo caso, si supponga di consigliare film con una valutazione stimata di > 3,5.
Per stampare i risultati, aggiungere il codice seguente come righe successive nel metodo UseModelForSinglePrediction():
if (Math.Round(movieRatingPrediction.Score, 1) > 3.5)
{
Console.WriteLine("Movie " + testInput.movieId + " is recommended for user " + testInput.userId);
}
else
{
Console.WriteLine("Movie " + testInput.movieId + " is not recommended for user " + testInput.userId);
}
Aggiungere quanto segue come riga di codice successiva dopo la chiamata al metodo per chiamare UseModelForSinglePrediction() il EvaluateModel() metodo:
UseModelForSinglePrediction(mlContext, model);
L'output di questo metodo dovrebbe avere un aspetto simile al testo seguente:
=============== Making a prediction ===============
Movie 10 is recommended for user 6
Salvare il modello
Per usare il modello per effettuare previsioni nelle applicazioni per l'utente finale, è prima necessario salvare il modello.
Creare il metodo SaveModel() subito dopo il metodo UseModelForSinglePrediction(), usando il codice seguente:
void SaveModel(MLContext mlContext, DataViewSchema trainingDataViewSchema, ITransformer model)
{
}
Salvare il modello sottoposto a training aggiungendo il codice seguente nel metodo SaveModel():
var modelPath = Path.Combine(Environment.CurrentDirectory, "Data", "MovieRecommenderModel.zip");
Console.WriteLine("=============== Saving the model to a file ===============");
mlContext.Model.Save(model, trainingDataViewSchema, modelPath);
Questo metodo salva il modello sottoposto a training in un file con estensione zip (nella cartella "Data") che potrà essere successivamente usato in altre applicazioni .NET per effettuare previsioni.
Aggiungere quanto segue come riga di codice successiva dopo la chiamata al metodo per chiamare SaveModel() il UseModelForSinglePrediction() metodo:
SaveModel(mlContext, trainingDataView.Schema, model);
Usare il modello salvato
Dopo aver salvato il modello sottoposto a training, è possibile usare il modello in ambienti diversi. Vedere Salvare e caricare modelli sottoposti a training per informazioni su come rendere operativo un modello di Machine Learning sottoposto a training nelle app.
Risultati
Dopo aver completato la procedura descritta sopra, eseguire l'app console (CTRL + F5). I risultati della previsione singola indicata in precedenza dovrebbero essere simili a quanto riportato di seguito. È possibile che vengano visualizzati avvisi o messaggi di elaborazione che tuttavia, per chiarezza, sono stati rimossi dai risultati riportati di seguito.
=============== Training the model ===============
iter tr_rmse obj
0 1.5382 3.1213e+05
1 0.9223 1.6051e+05
2 0.8691 1.5050e+05
3 0.8413 1.4576e+05
4 0.8145 1.4208e+05
5 0.7848 1.3895e+05
6 0.7552 1.3613e+05
7 0.7259 1.3357e+05
8 0.6987 1.3121e+05
9 0.6747 1.2949e+05
10 0.6533 1.2766e+05
11 0.6353 1.2636e+05
12 0.6209 1.2561e+05
13 0.6072 1.2462e+05
14 0.5965 1.2394e+05
15 0.5868 1.2352e+05
16 0.5782 1.2279e+05
17 0.5713 1.2227e+05
18 0.5637 1.2190e+05
19 0.5604 1.2178e+05
=============== Evaluating the model ===============
Rms: 0.977175077487166
RSquared: 0.43233349213192
=============== Making a prediction ===============
Movie 10 is recommended for user 6
=============== Saving the model to a file ===============
Congratulazioni! È stato creato un modello di Machine Learning per raccomandare film. È possibile trovare il codice sorgente per questa esercitazione nel repository dotnet/samples.
Migliorare il modello
È possibile migliorare le prestazioni del modello in diversi modi per ottenere previsioni più accurate.
Dati
L'aggiunta di altri dati di training con sufficienti esempi per ogni utente e ID film contribuisce a migliorare la qualità del modello di raccomandazione.
La convalida incrociata è una tecnica per la valutazione dei modelli che divide in modo casuale i dati in subset, anziché estrarre i dati di test dal set di dati come in questa esercitazione, e acquisisce alcuni gruppi come dati di training e altri come dati di test. In termini di qualità del modello, questo metodo offre prestazioni migliori rispetto alla divisione train-test.
Funzionalità
In questa esercitazione vengono usate solo le tre Features (user id, movie id e rating) offerte dal set di dati.
È un buon inizio, ma nella realtà è utile aggiungere altri attributi o Features, ad esempio età, sesso, posizione geografica e così via, se sono inclusi nel set di dati. L'aggiunta di Features più rilevanti può contribuire a migliorare le prestazioni del modello di raccomandazione.
Se non si è certi di quale Features sia l'aspetto più rilevante per l'attività di Machine Learning, è anche possibile usare L'importanza del calcolo del contributo delle funzionalità (FCC) e della permutazione, che ML.NET fornisce per individuare i più influenti Features.
Iperparametri dell'algoritmo
Anche se gli algoritmi di training predefiniti di ML.NET sono di ottima qualità, è possibile ottimizzare ulteriormente le prestazioni modificando gli iperparametri dell'algoritmo.
Per Matrix Factorization, è possibile sperimentare con iperparametri quali NumberOfIterations e ApproximationRank per vedere se vengono restituiti risultati migliori.
Ad esempio, in questa esercitazione le opzioni di algoritmo sono:
var options = new MatrixFactorizationTrainer.Options
{
MatrixColumnIndexColumnName = "userIdEncoded",
MatrixRowIndexColumnName = "movieIdEncoded",
LabelColumnName = "Label",
NumberOfIterations = 20,
ApproximationRank = 100
};
Altri algoritmi per la raccomandazione
L'algoritmo di fattorizzazione di matrice con filtraggio collaborativo è solo uno degli approcci per l'esecuzione di raccomandazioni di film. In molti casi, è possibile che i dati delle valutazioni non siano disponibili e che sia disponibile solo la cronologia del film relativa all'utente. In altri casi, si potrebbe avere di più dei soli dati di valutazione dell'utente.
| Algoritmo | Scenario | Esempio |
|---|---|---|
| One Class Matrix Factorization | Usare questo algoritmo quando sono disponibili solo userId e movieId. Questo stile di raccomandazione si basa sullo scenario di acquisto congiunto o di prodotti acquistati di frequente insieme e consiglierà quindi al cliente un set di prodotti in base alla propria cronologia di acquisto. | >Prova |
| Field Aware Factorization Machines | Usare questo algoritmo per creare raccomandazioni quando sono disponibili altre caratteristiche oltre a userId, productId e rating, ad esempio la descrizione del prodotto o il prezzo del prodotto. Questo metodo usa anche un approccio di filtraggio collaborativo. | >Prova |
Scenario con nuovi utenti
Un problema comune nel filtraggio collaborativo è quello relativo ai nuovi utenti per i quali non sono disponibili dati precedenti da cui trarre inferenze. Questo problema viene spesso risolto chiedendo ai nuovi utenti di creare un profilo e, ad esempio, valutare i film che hanno visto in passato. Anche se questo metodo introduce un compito in più per l'utente, esso consente di ottenere alcuni dati di partenza per i nuovi utenti senza una cronologia di valutazioni.
Risorse
I dati usati in questa esercitazione sono derivati dal set di dati MovieLens.
Passaggi successivi
In questa esercitazione sono state illustrate le procedure per:
- Selezionare un algoritmo di Machine Learning
- Preparare e caricare i dati
- Creare un modello ed eseguirne il training
- Valutare un modello
- Distribuire e usare un modello
Passare all'esercitazione successiva per altre informazioni