Connettersi a tabelle Common Data Model in Azure Data Lake Storage
Nota
Azure Active Directory è ora Microsoft Entra ID. Ulteriori informazioni
Inserisci i dati in Dynamics 365 Customer Insights - Data usando il tuo account Azure Data Lake Storage con le tabelle Common Data Model. L'inserimento dati può essere completo o incrementale.
Prerequisiti
L'account Azure Data Lake Storage deve avere lo spazio dei nomi gerarchico abilitato. I dati devono essere archiviati in un formato di cartella gerarchica che definisce la cartella radice e dispone di sottocartelle per ciascuna tabella. Le sottocartelle possono contenere cartelle di dati completi o di dati incrementali.
Per eseguire l'autenticazione con un'entità servizio di Microsoft Entra, assicurati che sia configurata nel tenant. Per ulteriori informazioni, vedi Connessione a un account Azure Data Lake Storage con un'entità servizio di Microsoft Entra.
Per connetterti a un archivio protetto da firewall, Impostare collegamenti privati di Azure.
Se il tuo data lake non ha connsessioni a collegamenti privati, Customer Insights - Data deve anche connettersi utilizzando un collegamento privato, indipendentemente dall'impostazione di accesso alla rete.
L'istanza di Azure Data Lake Storage a cui desideri connetterti e usare per l'inserimento di dati deve trovarsi nella stessa area di Azure dell'ambiente Dynamics 365 Customer Insights e le sottoscrizioni devono essere nello stesso tenant. Le connessioni a una cartella di Common Data Model da un data lake in un'area diversa di Azure non sono supportate. Per conoscere l'area di Azure dell'ambiente, vai a Impostazioni>Sistema>Informazioni su in Customer Insights - Data.
I dati memorizzati nei servizi online possono essere archiviati in una posizione diversa da quella in cui i dati vengono elaborati o archiviati. Importando o connettendoti a dati archiviati nei servizi online, accetti che i dati possano essere trasferiti. Ulteriori informazioni in Centro protezione Microsoft.
L'entità servizio Customer Insights - Data deve avere uno dei ruoli seguenti per accedere all'account di archiviazione. Per altre informazioni, vedi Concedere le autorizzazioni all'entità servizio per accedere all'account di archiviazione.
- Lettore dati BLOB di archiviazione
- Proprietario dati BLOB di archiviazione
- Collaboratore dati BLOB di archiviazione
Quando ci si connette all'archiviazione di Azure utilizzando l'opzione Sottoscrizione di Azure, l'utente che configura la connessione all'origine dati necessita almeno delle autorizzazioni dei collaboratori dei dati BLOB di archiviazione nell'account di archiviazione.
Quando ci si connette all'archiviazione di Azure utilizzando l'opzione risorsa di Azure, l'utente che configura la connessione all'origine dati necessita almeno dell'autorizzazione per l'azione Microsoft.Storage/storageAccounts/read nell'account di archiviazione. Un ruolo predefinito di Azure che include questa azione è il ruolo Lettore. Per limitare l'accesso solo all'azione necessaria, crea un ruolo personalizzato di Azure che includa solo questa azione.
Per prestazioni ottimali, le dimensioni di una partizione devono essere pari o inferiori a 1 GB e il numero di file della partizione in una cartella non deve superare 1.000.
I dati in Data Lake Storage devono seguire lo standard Common Data Model per l'archiviazione dei dati e avere il manifesto Common Data Model per rappresentare lo schema dei file di dati (*.csv o *.parquet). Il manifesto deve fornire i dettagli delle tabelle come colonne di tabelle e tipi di dati, nonché la posizione del file di dati e il tipo di file. Per altre informazioni, vedi Manifesto Common Data Model. Se il manifesto non è presente, gli utenti amministratori con accesso Proprietario dati BLOB di archiviazione o Collaboratore dati BLOB di archiviazione possono definire lo schema durante l'inserimento dei dati.
Nota
Se uno qualsiasi dei campi nei file .parquet ha il tipo di dati Int96, i dati potrebbero non essere visualizzati nella pagina Tabelle. Ti consigliamo di utilizzare tipi di dati standard, come il formato timestamp Unix (che rappresenta il tempo come numero di secondi dal 1 gennaio 1970 a mezzanotte UTC).
Limiti
- Customer Insights - Data non supporta colonne di tipo decimale con precisione maggiore di 16.
Connettersi a Azure Data Lake Storage
Vai a Dati>Origini dati.
Seleziona Aggiungere un'origine dati.
Seleziona tabelle Common Data Model di Azure Data Lake.

Immetti un Nome dell'origine dati e una Descrizione opzionale. Al nome viene fatto riferimento nei processi di downstream e non è possibile modificarlo dopo la creazione dell'origine dati.
Scegli una delle seguenti opzioni per Connetti lo spazio di archiviazione tramite. Per ulteriori informazioni, vedi Connessione a un account Azure Data Lake Storage con un'entità servizio di Microsoft Entra.
- Risorsa di Azure: immetti l'ID risorsa.
- Sottoscrizione di Azure: seleziona Sottoscrizione e quindi Gruppo di risorse e Account di archiviazione.
Nota
È necessario uno dei seguenti ruoli per il contenitore per la creazione dell'origine dati:
- Lettore dati del BLOB di archiviazione è sufficiente per leggere da un account di archiviazione e importare i dati in Customer Insights - Data.
- Collaboratore dati BLOB di archiviazione o Proprietario è necessario per modificare i file manifesto direttamente in Customer Insights - Data.
Il ruolo nell'account di archiviazione fornirà lo stesso ruolo in tutti i relativi contenitori.
Scegli il nome del Contenitore che contiene i dati e lo schema (file model.json o manifest.json) da cui importare i dati e seleziona Avanti.
Nota
Qualsiasi file model.json o manifest.json associato a un'altra origine dati nell'ambiente non verrà visualizzato nell'elenco. Tuttavia, lo stesso file model.json o manifest.json può essere utilizzato per origini dati in più ambienti.
Facoltativamente, se desideri inserire i dati da un account di archiviazione tramite un collegamento privato di Azure, seleziona Abilita collegamento privato. Per altre informazioni, vai a Collegamenti privati.
Per creare un nuovo schema, vai a Creare un nuovo file di schema.
Per usare uno schema esistente, vai alla cartella contenente il file model.json o manifest.cdm.json. Puoi eseguire la ricerca in una directory per trovare il file.
Seleziona il file json, quindi Avanti. Viene visualizzato un elenco delle tabelle disponibili.
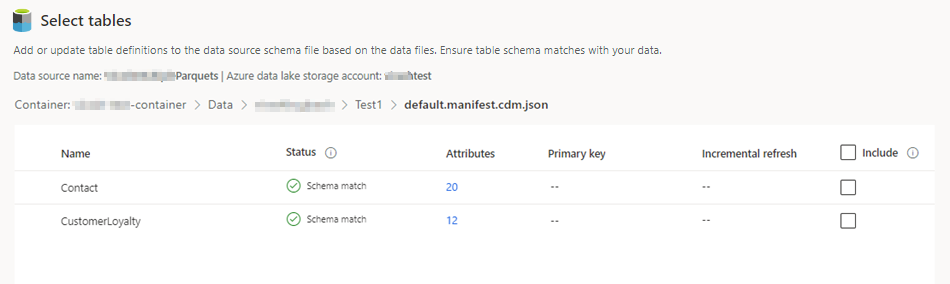
Seleziona le tabelle da includere.
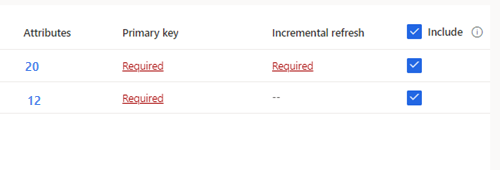
Suggerimento
Per modificare una tabella in un'interfaccia di modifica JSON, seleziona la tabella e quindi Modifica file schema. Apporta le modifiche e seleziona Salva.
Per le tabelle selezionate in cui non è stata definita una chiave primaria, Obbligatoria viene visualizzato in Chiave primaria. Per ciascuna di queste tabelle:
- Seleziona Obbligatoria. Viene visualizzato il riquadro Modifica tabella.
- Scegli la chiave primaria. La chiave primaria è un attributo univoco per la tabella. Affinché un attributo sia una chiave primaria valida, non deve includere valori duplicati, valori mancanti o valori null. Gli attributi del tipo di dati String, Integer e GUID sono supportati come chiavi primarie.
- Facoltativamente, modifica il modello di partizione.
- Seleziona Chiudi per salvare e chiudere il pannello.
Seleziona il numero di Colonne per ciascuna tabella inclusa. Visualizzata la pagina Gestisci gli attributi.
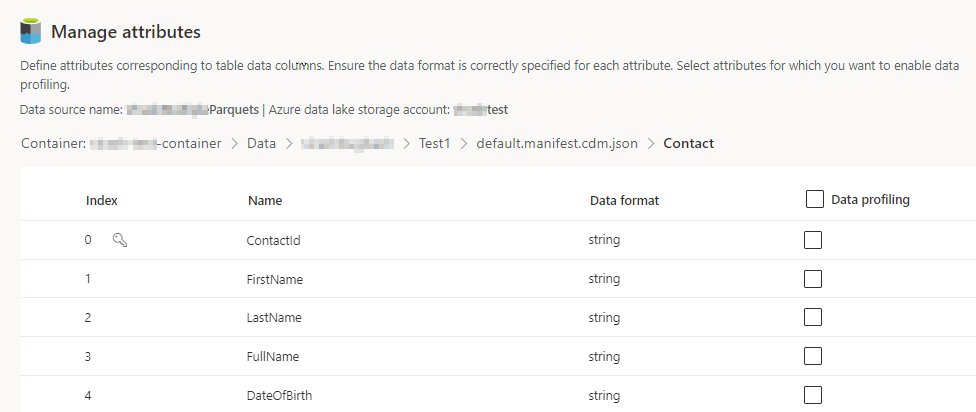
- Crea nuove colonne, modifica o elimina le colonne esistenti. È possibile modificare il nome, il formato dei dati o aggiungere un tipo semantico.
- Per abilitare l'analisi e altre funzionalità, seleziona Profiling dei dati per l'intera tabella o per colonne specifiche. Per impostazione predefinita, nessuna tabella è abilitata per il profiling dei dati.
- Seleziona Fatto.
Seleziona Salva. Verrà aperta la pagina Origine datiche mostra la nuova origine dati con stato Aggiornamento in corso.
Mancia
Essitono stati per attività e processi. La maggior parte dei processi dipende da altri processi upstream, come origini dati e aggiornamenti di profiling dei dati.
Seleziona lo stato per aprire il riquadro Dettagli stato e visualizza lo stato delle attività. Per annullare il processo, seleziona Annulla processo nella parte inferiore del riquadro.
In ogni attività puoi selezionare il collegamento Vedi dettagli per altre informazioni sullo stato, ad esempio tempo di elaborazione, data dell'ultima elaborazione ed eventuali errori e avvisi applicabili associati all'attività o al processo. Seleziona Visualizza stato del sistema nella parte inferiore del pannello per vedere altri processi nel sistema.

Il caricamento dei dati può richiedere tempo. Al termine dell'aggiornamento, i dati inseriti possono essere esaminati nella pagina Tabelle.
Creare un nuovo file di schema
Seleziona Crea file di schema.
Immetti un nome per il file e seleziona Salva.
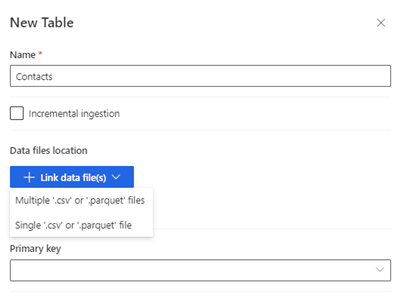
Seleziona Nuova tabella. Viene visualizzato il pannello Nuova tabella.
Immetti il nome della tabella e scegli il Percorso file di dati.
- Più file csv o parquet: accedi alla cartella radice, seleziona il tipo di modello e immetti l'espressione.
- File csv o parquet singolo: passa al file csv o parquet e selezionalo.
Seleziona Salva.
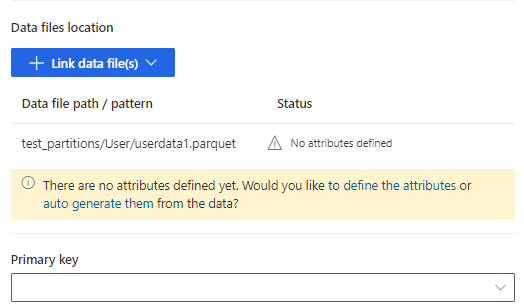
Seleziona definisci gli attributi per aggiungere manualmente gli attributi o seleziona generali automaticamente. Per definire gli attributi, immetti un nome, seleziona il formato dei dati e il tipo semantico opzionale. Per gli attributi generati automaticamente:
Dopo che gli attributi sono stati generati automaticamente, seleziona Rivedi gli attributi. Visualizzata la pagina Gestisci gli attributi.
Assicurati che il formato dei dati sia corretto per ogni attributo.
Per abilitare l'analisi e altre funzionalità, seleziona Profiling dei dati per l'intera tabella o per colonne specifiche. Per impostazione predefinita, nessuna tabella è abilitata per il profiling dei dati.
Seleziona Fatto. Viene visualizzata la pagina Seleziona tabelle.
Continua ad aggiungere tabelle e colonne, se applicabile.
Dopo aver aggiunto tutte le tabelle, seleziona Includi per includere le tabelle nell'inserimento dell'origine dati.
Per le tabelle selezionate in cui non è stata definita una chiave primaria, Obbligatoria viene visualizzato in Chiave primaria. Per ciascuna di queste tabelle:
- Seleziona Obbligatoria. Viene visualizzato il riquadro Modifica tabella.
- Scegli la chiave primaria. La chiave primaria è un attributo univoco per la tabella. Affinché un attributo sia una chiave primaria valida, non deve includere valori duplicati, valori mancanti o valori null. Gli attributi del tipo di dati String, Integer e GUID sono supportati come chiavi primarie.
- Facoltativamente, modifica il modello di partizione.
- Seleziona Chiudi per salvare e chiudere il pannello.
Seleziona Salva. Verrà aperta la pagina Origine datiche mostra la nuova origine dati con stato Aggiornamento in corso.
Mancia
Essitono stati per attività e processi. La maggior parte dei processi dipende da altri processi upstream, come origini dati e aggiornamenti di profiling dei dati.
Seleziona lo stato per aprire il riquadro Dettagli stato e visualizza lo stato delle attività. Per annullare il processo, seleziona Annulla processo nella parte inferiore del riquadro.
In ogni attività puoi selezionare il collegamento Vedi dettagli per altre informazioni sullo stato, ad esempio tempo di elaborazione, data dell'ultima elaborazione ed eventuali errori e avvisi applicabili associati all'attività o al processo. Seleziona Visualizza stato del sistema nella parte inferiore del pannello per vedere altri processi nel sistema.
Il caricamento dei dati può richiedere tempo. Al termine dell'aggiornamento, i dati inseriti possono essere esaminati nella pagina Dati>Tabelle.
Modificare un'origine dati Azure Data Lake Storage
Puoi aggiornare l'opzione Connettiti a un account di archiviazione usando. Per ulteriori informazioni, vedi Connessione a un account Azure Data Lake Storage con un'entità servizio di Microsoft Entra. Per connetterti a un contenitore diverso dal tuo account di archiviazione o modificare il nome dell'account, crea una nuova connessione all'origine dati.
Vai a Dati>Origini dati. Accanto all'origine dati che desideri aggiornare, seleziona Modifica.
Modifica una delle seguenti informazioni:
Description
Connetti lo spazio di archiviazione tramite e informazioni sulla connessione. Non puoi modificare le informazioni sul Contenitore durante l'aggiornamento della connessione.
Nota
Uno dei seguenti ruoli deve essere assegnato all'account di archiviazione o al contenitore:
- Lettore dati BLOB di archiviazione
- Proprietario dati BLOB di archiviazione
- Collaboratore dati BLOB di archiviazione
Abilita collegamento privato se desideri inserire i dati da un account di archiviazione tramite un collegamento privato di Azure. Per altre informazioni, vai a Collegamenti privati.
Seleziona Avanti.
Esegui una delle modifiche seguenti:
Passa a un altro file model.json o manifest.json con un set di tabelle diverso dal contenitore.
Per aggiungere altre tabelle da inserire, seleziona Nuova tabella.
Per rimuovere eventuali tabelle già selezionate se non ci sono dipendenze, seleziona la tabella, quindi Elimina.
Importante
Se sono presenti dipendenze dal file model.json o manifest.json esistente e dal set di tabelle, verrà visualizzato un messaggio di errore e non sarà possibile selezionare un file model.json o manifest.json diverso. Rimuovi queste dipendenze prima di cambiare il file model.json o manifest.json o crea un nuovo origine dati con il file model.json o manifest.json che vuoi utilizzare per evitare di rimuovere le dipendenze.
Per modificare il percorso dei file di dati o la chiave primaria, seleziona Modifica.
Modifica solo il nome della tabella in modo che corrisponda al nome della tabella nel file .json.
Nota
Mantieni sempre il nome della tabella uguale al nome della tabella nel file model.json o manifest.json dopo l'importazione. Customer Insights - Data convalida tutti i nomi di tabella con model.json o manifest.json durante ogni aggiornamento del sistema. Se il nome di una tabella cambia, si verifica un errore perché Customer Insights - Data non riesce a trovare il nuovo nome di tabella nel file .json. Se il nome di una tabella importata è stato modificato accidentalmente, modifica il nome della tabella in modo che corrisponda al nome nel file .json.
Seleziona Colonne per aggiungerle o modificarle o per abilitare il profiling dei dati. Quindi seleziona Fatto.
Seleziona Salva per applicare le modifiche e tornare alla pagina Origine dati.
Mancia
Essitono stati per attività e processi. La maggior parte dei processi dipende da altri processi upstream, come origini dati e aggiornamenti di profiling dei dati.
Seleziona lo stato per aprire il riquadro Dettagli stato e visualizza lo stato delle attività. Per annullare il processo, seleziona Annulla processo nella parte inferiore del riquadro.
In ogni attività puoi selezionare il collegamento Vedi dettagli per altre informazioni sullo stato, ad esempio tempo di elaborazione, data dell'ultima elaborazione ed eventuali errori e avvisi applicabili associati all'attività o al processo. Seleziona Visualizza stato del sistema nella parte inferiore del pannello per vedere altri processi nel sistema.