Panoramica dei processi di importazione ed esportazione dati
Per creare e gestire processi di importazione ed esportazione di dati si utilizza l'area di lavoro Gestione dati. Per impostazione predefinita, il processo di importazione ed esportazione crea una tabella di gestione temporanea per ciascuna entità nel database di destinazione. Le tabelle di gestione temporanea consentono di verificare, pulire o convertire i dati prima di spostarli.
Nota
In questo articolo si presuppone di aver acquisito dimestichezza con l'argomento entità di dati.
Processo di importazione/esportazione di dati
Di seguito vengono riportati i passaggi per l'importazione o l'esportazione di dati.
Creare un processo di importazione o esportazione in cui completare le seguenti attività:
- Definire la categoria del progetto.
- Identificare le entità da importare o esportare.
- Impostare il formato dei dati per il processo.
- Sequenziare le entità di modo che vengano elaborate in gruppi logici e in un ordine significativo.
- Determinare se utilizzare le tabelle di gestione temporanea.
Verificare che i dati di origine e i dati di destinazione siano mappati correttamente.
Verificare la protezione per il processo di importazione o esportazione.
Eseguire il processo di importazione o di esportazione.
Verificare che il processo sia stato eseguito come previsto esaminando lo storico processi.
Pulire le tabelle di gestione temporanea.
Le altre sezioni di questo articolo forniscono ulteriori informazioni su ogni fase del processo.
Nota
Per aggiornare il modulo di importazione/esportazione dei dati per visualizzare i progressi più recenti, utilizzare l'icona di aggiornamento dei moduli. L'aggiornamento a livello del browser non è consigliato perché interromperebbe qualsiasi lavoro di importazione/esportazione che non viene eseguito in un batch.
Creare un processo di importazione o di esportazione
Un processo di importazione o esportazione di dati può essere eseguito una sola volta oppure più volte.
Definire la categoria del progetto
Si consiglia di selezionare attentamente una categoria di progetto appropriata per il processo di esportazione o di importazione. Le categorie di progetto consentono di gestire i processi correlati.
Identificare le entità da importare o esportare
È possibile aggiungere specifiche entità a un processo di esportazione o di importazione oppure selezionare un modello da applicare. I modelli includono un elenco di entità in un processo. L'opzione Applica modello è disponibile dopo aver denominato e salvato il processo.
Impostare il formato dei dati per il processo
Quando si seleziona un'entità, è necessario selezionare il formato dei dati esportato o importato. Si definiscono i formati utilizzando il riquadro Impostazione origini dati. Un formato di dati di origine è una combinazione Tipo, Formato file, Delimitatore di riga e Delimitatore di colonna. Sono inclusi altri attributi, ma questi sono quelli fondamentali da ricordare. Nella tabella riportata di seguito vengono elencate le combinazioni valide.
| Formato file | Delimitatore di riga/colonna | Stile XML |
|---|---|---|
| Excel | Excel | -NA- |
| XML | -NA- | Elemento XML Attributo XML |
| Larghezza fissa, delimitata | Virgola, punto e virgola, tabulazione, barra verticale, due punti | -NA- |
Nota
È importante selezionare il valore corretto per Delimitatore riga, Delimitatore colonna e Qualificatore testo, se l'opzione Formato file è impostata su Delimitato. Assicurati che i tuoi dati non contengano il carattere utilizzato come delimitatore o qualificatore, poiché ciò potrebbe causare errori durante l'importazione e l'esportazione.
Nota
Per i formati di file basati su XML, assicurati di utilizzare solo caratteri validi. Per maggiori informazioni sui caratteri validi, vedi Caratteri validi in XML 1.0. XML 1.0 non consente alcun carattere di controllo ad eccezione di tabulazioni, ritorni a capo e avanzamenti di riga. Esempi di caratteri non validi sono parentesi quadre, parentesi graffe e barre rovesciate.
Utilizza Unicode invece di una tabella codici specifica per importare o esportare dati. Ciò contribuisce a fornire i risultati più coerenti ed eliminare i processi di gestione dati che non riescono perché includono caratteri Unicode. I formati dei dati di origine definiti dal sistema che utilizzano Unicode includono Unicode nel nome dell'origine. Il formato Unicode viene applicato selezionando una tabella codici ANSI di codifica Unicode come Tabella codici nella scheda Impostazioni regionali. Seleziona una delle seguenti tabelle codici per Unicode:
| Tabella codici | Nome visualizzato |
|---|---|
| 1200 | Unicode |
| 12000 | Unicode (UTF-32) |
| 12001 | Unicode (UTF-32 Big-Endian) |
| 1201 | Unicode (Big-Endian) |
| 65000 | Unicode (UTF-7) |
| 65001 | Unicode (UTF-8) |
Per maggiori informazioni sulle tabelle codici, vedi Identificatori di tabelle codici.
Sequenziare le entità
È possibile sequenziare le entità in un modello di dati o nei processi di importazione e esportazione. Quando si esegue un processo contenente più entità di dati, è necessario assicurarsi che le entità di dati siano sequenziate correttamente. Il sequenziamento delle entità deve essere eseguito in modo da poter risolvere qualsiasi dipendenza funzionale tra le entità. Se le entità non hanno dipendenze funzionali, possono essere programmate per l'importazione o l'esportazione parallela.
Unità di esecuzione, livelli e sequenze
L'unità di esecuzione, il livello nell'unità di esecuzione e la sequenza di un'entità consentono di determinare l'ordine in cui i dati vengono esportati o importati.
- Le entità nelle differenti unità di esecuzione sono elaborate in parallelo.
- In ogni unità di esecuzione, le entità vengono elaborate in parallelo se hanno lo stesso livello.
- In ogni livello, le entità vengono elaborate in base al relativo numero di sequenza in tale livello.
- Dopo l'elaborazione di un livello, viene elaborato il livello successivo.
Risequenziamento
È possibile che si intenda sequenziare di nuovo le entità nelle situazioni seguenti:
- Se si utilizza un solo processo di dati per tutte le modifiche, è possibile utilizzare le opzioni di risequenziamento in modo da ottimizzare il tempo di esecuzione dell'intero processo. In questi casi, è possibile utilizzare l'unità di esecuzione per rappresentare il modulo, il livello per rappresentare l'area funzionale nel modulo e la sequenza per rappresentare l'entità. Utilizzando questo approccio, è possibile gestire i moduli in parallelo, ma anche in sequenza. Per assicurare una corretta esecuzione delle operazioni in parallelo, è necessario considerare tutte le dipendenze.
- Se si utilizzano più processi di dati (ad esempio un processo per ogni modulo), è possibile utilizzare il sequenziamento per modificare il livello e la sequenza delle entità per un'esecuzione ottimale.
- Se non vi sono dipendenze, è possibile sequenziare le entità in differenti unità di esecuzione per un'ottimizzazione massima.
Il menu Risequenziamento è disponibile quando si selezionano più entità. È possibile eseguire il risequenziamento in base alle opzioni relative a unità di esecuzione, livello o sequenza. È possibile impostare un incremento per il risequenziamento delle entità selezionate. L'unità, il livello e/o il numero di sequenza selezionato per ciascuna entità viene aggiornato in base all'incremento specificato.
Ordinamento
È possibile utilizzare Ordina per per visualizzare l'elenco delle entità nell'ordine sequenziale.
Troncamento
Per i progetti di importazione, è possibile scegliere di troncare i record nelle entità prima dell'importazione. Il troncamento è utile se i record devono essere importati in un set di tabelle pulito. Per impostazione predefinita questa opzione è disattivata.
Verificare che i dati di origine e i dati di destinazione siano mappati correttamente
Il mapping è una funzione disponibile per i processi di importazione e quelli di esportazione.
- Nel contesto di un processo di importazione, il mapping descrive quali colonne nel file di origine diventano colonne nella tabella di gestione temporanea. Di conseguenza, il sistema può determinare quale colonna di dati nel file di origine deve essere copiata in quale colonna della tabella di gestione temporanea.
- Nel contesto di un processo di esportazione, il mapping descrive quali colonne della tabella di gestione temporanea diventano le colonne nel file di origine.
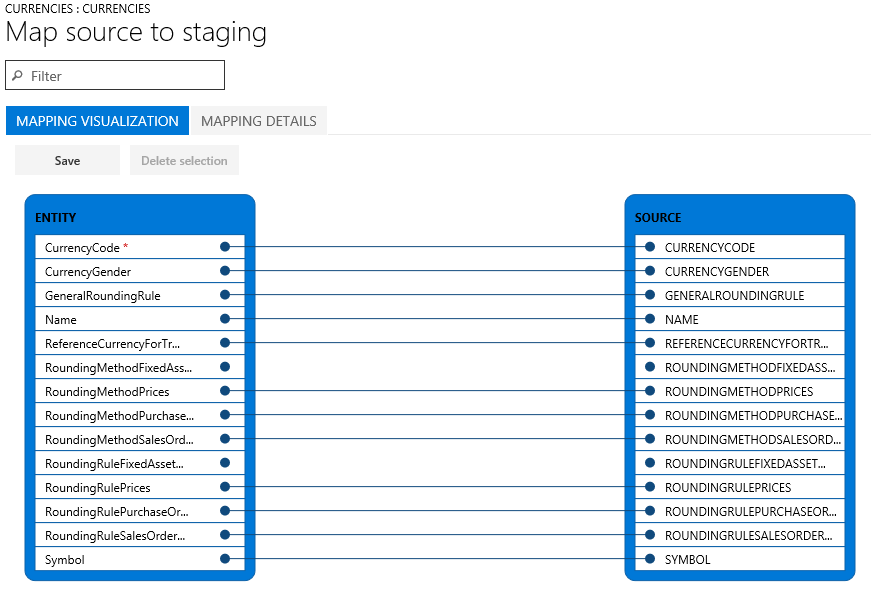
Se i nomi di colonna nella tabella di gestione temporanea e nel file corrispondono, il sistema stabilisce automaticamente il mapping in base ai nomi. Tuttavia, se i nomi differiscono, le colonne non vengono mappate automaticamente. In questi casi, è necessario completare il mapping selezionando l'opzione Visualizza mapping per l'entità nel processo di dati.
Sono disponibili due visualizzazioni di mapping: Visualizzazione mapping, ovvero la visualizzazione predefinita, e Dettagli mapping. Un asterisco rosso (*) identifica i campi obbligatori nell'entità. È necessario mappare questi campi per poter utilizzare l'entità. È possibile annullare il mapping di altri campi quando si utilizza l'entità. Per annullare il mapping di un campo, selezionare il campo nella colonna Entità o nella colonna Origine e quindi selezionare Elimina la selezione. Selezionare Salva per salvare le modifiche e chiudere la pagina per ritornare al progetto. È possibile utilizzare lo stesso processo per modificare il mapping da Origine a Gestione temporanea dopo l'importazione.
È possibile generare un mapping nella pagina selezionando Genera mapping origine. Il comportamento di un mapping generato è quello di un mapping automatico. Di conseguenza, è necessario mappare manualmente tutti i campi non mappati.
Verificare la protezione per il processo di importazione o esportazione
L'accesso all'area di lavoro Gestione dati può essere limitato, di modo che gli utenti non amministratori possano accedere solo a specifici processi di dati. L'accesso a un processo di dati implica l'accesso completo allo storico esecuzioni di quel processo e l'accesso alle tabelle di staging. Di conseguenza, è necessario assicurarsi di aver implementato i controlli di accesso appropriati quando si crea un processo di dati.
Proteggere un processo in base a ruoli e utenti
Utilizzare il menu Ruoli applicabili per limitare l'accesso al processo a uno o più ruoli di sicurezza. Solo gli utenti con quei ruoli hanno accesso al processo.
È inoltre possibile limitare l'accesso a un processo a specifici utenti. Quando si protegge un processo in base agli utenti anziché ai ruoli, il livello di controllo è maggiore se molteplici utenti sono assegnati a un ruolo.
Proteggere un processo in base alla persona giuridica
I processi di dati sono globali per natura. Di conseguenza, se un processo di dati è stato creato e utilizzato in una persona giuridica, il processo è visibile in altre persone giuridiche nel sistema. Questo comportamento predefinito potrebbe essere preferibile in alcuni scenari di applicazione. Ad esempio, un'organizzazione che importa fatture mediante entità di dati potrebbe fornire un team di elaborazione delle fatture centralizzato che è responsabile della gestione degli errori nelle fatture per tutti i reparti dell'organizzazione. In questo scenario, per il team di elaborazione delle fatture centralizzato è utile avere accesso a processi di importazione delle fatture di tutte le persone giuridiche. Di conseguenza, il comportamento predefinito soddisfa il requisito a livello di persona giuridica.
Tuttavia, un'organizzazione potrebbe necessitare di avere team di elaborazione delle fatture per entità giuridica. In tal caso, un team in una persona giuridica deve avere accesso solo al processo di importazione delle fatture nella relativa persona giuridica. Per soddisfare questo requisito, è possibile configurare il controllo dell'accesso basato sulle persone giuridiche nei processi di dati utilizzando il menu Persone giuridiche applicabili nel processo di dati. Dopo la configurazione, gli utenti possono visualizzare solo i processi disponibili nella persona giuridica a cui hanno correntemente accesso. Per visualizzare i processi di un'altra persona giuridica, gli utenti devono accedere a quella persona giuridica.
Un processo può essere protetto in base a ruoli, utenti e persone giuridiche contemporaneamente.
Eseguire il processo di importazione o di esportazione
È possibile eseguire un processo una volta facendo clic sul pulsante Importa o Esporta dopo aver definito il processo. Per impostare un processo ricorrente, selezionare Crea processo dati ricorrente.
Nota
Un processo di importazione o esportazione può essere eseguito selezionando il pulsante Importa o Esporta. Questo pianificherà un processo batch da eseguire solo una volta. Il processo potrebbe non essere eseguito immediatamente se il servizio batch subisce una limitazione a causa del carico sul servizio batch. I processi possono anche essere eseguiti in modo sincrono selezionando Importa adesso o Esporta adesso. Questa selezione avvia immediatamente il processo e risulta utile se il batch non viene avviato a causa di una limitazione. I processi possono anche essere programmati per essere eseguiti in un secondo momento. Questo può essere fatto scegliendo l'opzione Esegui in batch. Le risorse batch sono soggette a limitazione, quindi il processo batch potrebbe non essere avviato immediatamente. L'utilizzo di un batch è l'opzione consigliata perché aiuta anche con grandi volumi di dati che devono essere importati o esportati. I processi batch possono essere pianificati per l'esecuzione in un gruppo batch specifico, che consente un maggior controllo da una prospettiva di bilanciamento del carico.
Verificare che il processo è stato eseguito come previsto
Lo storico processi è disponibile per la risoluzione dei problemi e l'analisi dei processi di importazione e di esportazione. Le esecuzioni dello storico processi sono organizzate in base a intervalli di tempo.
Ogni esecuzione di processo fornisce i seguenti dettagli:
- Dettagli esecuzione
- Registro di esecuzione
I dettagli relativi all'esecuzione indicano lo stato di ciascuna entità di dati elaborata nel processo. Di conseguenza, è possibile trovare rapidamente le seguenti informazioni:
- Quali entità sono state elaborate
- Per un'entità, quanti record sono stati elaborati correttamente e quanti no
- I record di gestione temporanea per ogni entità
È possibile scaricare i dati di gestione temporanea in un file per i processi di esportazione, oppure scaricarlo come pacchetto per i processi di esportazione e importazione.
Dai dettagli di esecuzione è anche possibile aprire il registro di esecuzione.
Importazioni parallele
Per accelerare l'importazione di dati, è possibile abilitare l'elaborazione parallela dell'importazione di un file se l'entità supporta le importazioni parallele. Per configurare l'importazione parallela per un'entità, è necessario seguire i seguenti passaggi.
Passare all'Amministrazione sistema > Aree di lavoro > Gestione dati.
Nella sezione Importa/Esporta, selezionare il riquadro Parametri framework per aprire la pagina Parametri framework di importazione/esportazione dei dati.
Nella scheda Impostazioni entità, selezionare Configura parametri di esecuzione entità per aprire la pagina Parametri di esecuzione importazione entità.
Impostare i seguenti campi per configurare l'importazione parallela per un'entità:
- Nel campo Entità, selezionare l'entità. Se il campo dell'entità è vuoto, il valore vuoto viene utilizzato come impostazione predefinita per tutte le importazioni successive, se l'entità supporta l'importazione parallela.
- Nel campo Conteggio dei record di soglia importazione immettere il conteggio dei record di soglia per l'importazione. Ciò determina il conteggio dei record che deve essere elaborato da un thread. Se un file ha 10.000 record, un conteggio di record pari a 2.500 con 4 attività significa che ogni thread elabora 2.500 record.
- Nel campo Conteggio attività importazione inserire il conteggio delle attività di importazione. Il conteggio non deve superare il numero massimo di thread in batch assegnati per l'elaborazione batch in Amministrazione di sistema >Configurazione del server.
Nota
L'aggiunta di troppe attività parallele fa sì che l'infrastruttura sottostante utilizzi la capacità delle risorse al 100%, con conseguente impatto sulle prestazioni di ambiente e su altre operazioni. Si consiglia di comprendere la capacità delle risorse di ambiente e il consumo in base alle attività di importazione parallela configurate e di limitare il numero di attività.
Pulizia storico processi
Per impostazione predefinita, le voci dello storico processi e i relativi dati della tabella di gestione temporanea più vecchi di 90 giorni vengono eliminati automaticamente. La funzionalità di pulizia dello storico processi in Gestione dati può essere utilizzata per configurare la pulizia periodica dello storico esecuzioni con un periodo di conservazione inferiore a quello predefinito. Questa funzionalità sostituisce la funzionalità precedente di pulizia delle tabelle di gestione temporanea, ora deprecata. Le seguenti tabelle vengono pulite dal processo di pulizia.
Tutte le tabelle di gestione temporanea
DMFSTAGINGVALIDATIONLOG
DMFSTAGINGEXECUTIONERRORS
DMFSTAGINGLOGDETAIL
DMFSTAGINGLOG
DMFDEFINITIONGROUPEXECUTIONHISTORY
DMFEXECUTION
DMFDEFINITIONGROUPEXECUTION
La funzionalità Pulizia storico esecuzioni è accessibile da Gestione dati > Pulizia storico processi.
Parametri di programmazione
Quando pianifichi i l processo di pulizia, i seguenti parametri devono essere specificati per definire i criteri di pulizia.
Numero di giorni di mantenimento storico - Questa impostazione viene utilizzata per stabilire la quantità dello storico di esecuzione da conservare. Lo storico è specificato in numero di giorni. Quando il processo di pulizia viene programmato come processo batch ricorrente, questa impostazione agirà come una finestra in continuo spostamento, sempre lasciando lo storico intatto per il numero di giorni specificato ed eliminando il resto. Il valore predefinito è sette giorni.
Numero di ore per eseguire il processo: a seconda della quantità dello storico da pulire, il tempo di esecuzione totale per il processo di pulizia può variare da alcuni minuti a qualche ora. Questo parametro deve essere impostato sul numero di ore di esecuzione del processo. Dopo che il processo di pulizia è stato eseguito per il numero di ore specificato, il processo verrà terminato e riprenderà la pulizia alla successiva esecuzione in base alla pianificazione della ricorrenza.
Un tempo di esecuzione massimo può essere specificato impostando un limite massimo sul numero di ore in cui il processo deve essere eseguito mediante questa impostazione. La logica di pulizia gestisce un ID di esecuzione processo alla volta in una sequenza cronologica, con il più vecchio come primo della pulizia dello storico esecuzioni correlato. Smette di rilevare nuovi ID di esecuzione per la pulizia quando la durata rimanente di esecuzione rientra nell'ultimo 10% della durata specificata. In alcuni casi, è previsto che il processo di pulizia continui oltre il tempo massimo specificato. La durata dipende in gran parte dal numero di record da eliminare per l'ID di esecuzione corrente che è stato avviata prima della soglia di 10% venga raggiunta. La pulizia iniziata deve essere completata per assicurarla l'integrità dei dati, pertanto la pulizia continua nonostante il superamento del limite specificato. Al termine, i nuovi ID di esecuzione non vengono prelevati e il processo di pulizia termina. Lo storico esecuzioni rimanente che non è stato pulito per mancanza di tempo di esecuzione, viene selezionato nella successiva programmazione del processo di pulizia. Il valore predefinito e minimo per questa impostazione è impostato su 2 ore.
Batch ricorrente: il processo di pulizia può essere eseguito come esecuzione manuale occasionale, oppure può essere programmata per l'esecuzione ricorrente in batch. Il batch può essere programmato utilizzando le impostazioni Esecuzione in background, che è l'impostazione batch standard.
Nota
Se la funzionalità Pulizia storico processi non viene utilizzata, lo storico esecuzioni più vecchio di 90 giorni viene comunque eliminato automaticamente. È possibile eseguire la pulizia dello storico processi insieme all'eliminazione automatica. Assicurati che il processo di pulizia sia pianificato per l'esecuzione ricorrente. Come spiegato sopra, in qualsiasi esecuzione di pulizia il processo pulirà il maggior numero di ID di esecuzione possibile entro le ore massime previste.
Pulizia e archiviazione dello storico processi
La funzionalità di pulizia e archiviazione dello storico processi sostituisce le versioni precedenti della funzionalità di pulizia. Questa sezione descrive queste nuove funzionalità.
Una delle principali modifiche alla funzionalità di pulizia è l'uso del processo batch di sistema per la pulizia dello storico. L'utilizzo del processo batch di sistema consente alle app per la finanza e le operazioni di pianificare ed eseguire automaticamente il processo batch di pulizia non appena il sistema è pronto. Non è più necessario pianificare manualmente il processo batch. In questa modalità di esecuzione predefinita, il processo batch viene eseguito ogni ora a partire dalla mezzanotte e conserva lo storico esecuzioni degli ultimi 7 giorni. Lo storco eliminato viene archiviato per il recupero futuro. A partire dalla versione 10.0.20, questa funzionalità è sempre attiva.
La seconda modifica nel processo di pulizia è l'archiviazione dello storico esecuzioni eliminato. Il processo di pulizia archivia i record eliminati nell'archiviazione BLOB che DIXF utilizza per le integrazioni regolari. Il file archiviato è nel formato del pacchetto DIXF ed è disponibile per sette giorni nel BLOB durante il quale potrà essere scaricato. La longevità predefinita di sette giorni per il file archiviato può essere modificata fino a un massimo di 90 giorni nei parametri.
Modifica delle impostazioni predefinite
Questa funzionalità è attualmente in anteprima e deve essere esplicitamente attivata abilitando l'anteprima DMFEnableExecutionHistoryCleanupSystemJob. Anche la funzionalità di gestione temporanea deve essere attivata in gestione funzionalità.
Per modificare l'impostazione predefinita per la longevità del file archiviato, accedere all'area di lavoro della gestione dei dati e selezionare Pulizia storico processi. Impostare Giorni in cui conservare il pacchetto in BLOB su un valore compreso tra 7 e 90 (inclusi). Ciò ha effetto sugli archivi creati dopo questa modifica.
Download del pacchetto archiviato
Questa funzionalità è attualmente in anteprima e deve essere esplicitamente attivata abilitando l'anteprima DMFEnableExecutionHistoryCleanupSystemJob. Anche la funzionalità di gestione temporanea deve essere attivata in gestione funzionalità.
Per scaricare lo storico esecuzioni archiviato, andare all'area di lavoro della gestione dei dati e selezionare Pulizia storico processi. Selezionare Cronologia di backup del pacchetto per aprire il modulo dello storico. Questo modulo mostra l'elenco di tutti i pacchetti archiviati. Un archivio può essere selezionato e scaricato selezionando Scarica il pacchetto. Il pacchetto scaricato è nel formato del pacchetto DIXF e contiene i seguenti file:
- Il file della tabella di gestione temporanea dell'entità
- DMFDEFINITIONGROUPEXECUTION
- DMFDEFINITIONGROUPEXECUTIONHISTORY
- DMFEXECUTION
- DMFSTAGINGEXECUTIONERRORS
- DMFSTAGINGLOG
- DMFSTAGINGLOGDETAILS
- DMFSTAGINGVALIDATIONLOG
Ordinamento dei dati di entità composite tramite xslt
Questa funzionalità consente di esportare un'entità composita e di applicare un file xslt per ordinare i dati nel file xml.
Per ordinare i dati delle entità composite utilizzando xslt, segui questi passaggi.
- Crea un file xslt per ordinare i dati in formato XML. Ad esempio, se si dispone di un file XSLT per l'entità Ordini di acquisto composita V3 predefinita, è possibile ordinare i dati del formato dell'attributo XML in base a INVOICEVENDORACCOUNTNUMBER per PURCHPURCHASEORDERHEADERV2ENTITY e in base a LINENUMBER per PURCHPURCHASEORDERLINEV2ENTITY.
<xsl:stylesheet version='1.0' xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/*">
<xsl:copy>
<xsl:apply-templates select="@*" />
<xsl:apply-templates>
<xsl:sort select="@INVOICEVENDORACCOUNTNUMBER" data-type="text" order="ascending" />
</xsl:apply-templates>
</xsl:copy>
</xsl:template>
<xsl:template match="PURCHPURCHASEORDERHEADERV2ENTITY">
<xsl:copy>
<xsl:apply-templates select="@*"/>
<xsl:apply-templates select="*">
<xsl:sort select="@LINENUMBER" data-type="number" order="descending"/>
</xsl:apply-templates>
</xsl:copy>
</xsl:template>
<xsl:template match="@*|node()">
<xsl:copy>
<xsl:apply-templates select="@*|node()"/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>
- Vai all'area di lavoro Gestione dei dati.
- Dall'elenco dei progetti Esportazione dati, seleziona un progetto con origine dati XML e Visualizza mappa.
- Seleziona Visualizza mappa per qualsiasi entità.
- Seleziona la scheda Trasformazioni
- Seleziona Nuovo e carica il file xslt creato nel passaggio 1.