Considerazioni sulle prestazioni per EF 4, 5 e 6
Di David Obando, Eric Dettinger e altri
Pubblicato: aprile 2012
Ultimo aggiornamento: maggio 2014
1. Introduzione
I framework di mapping relazionale a oggetti sono un modo pratico per fornire un'astrazione per l'accesso ai dati in un'applicazione orientata agli oggetti. Per le applicazioni .NET, L'O/RM consigliato da Microsoft è Entity Framework. Con qualsiasi astrazione, tuttavia, le prestazioni possono diventare un problema.
Questo white paper è stato scritto per illustrare le considerazioni sulle prestazioni durante lo sviluppo di applicazioni con Entity Framework, per offrire agli sviluppatori un'idea degli algoritmi interni di Entity Framework che possono influire sulle prestazioni e fornire suggerimenti per l'analisi e il miglioramento delle prestazioni nelle applicazioni che usano Entity Framework. Esistono diversi argomenti validi sulle prestazioni già disponibili sul Web e abbiamo anche provato a puntare a queste risorse laddove possibile.
Le prestazioni sono un argomento difficile. Questo white paper è destinato a una risorsa che consente di prendere decisioni correlate alle prestazioni per le applicazioni che usano Entity Framework. Sono state incluse alcune metriche di test per illustrare le prestazioni, ma queste metriche non sono concepite come indicatori assoluti delle prestazioni visualizzate nell'applicazione.
A scopo pratico, questo documento presuppone che Entity Framework 4 venga eseguito in .NET 4.0 e Entity Framework 5 e 6 vengano eseguiti in .NET 4.5. Molti dei miglioramenti delle prestazioni apportati per Entity Framework 5 risiedono all'interno dei componenti principali forniti con .NET 4.5.
Entity Framework 6 è una versione fuori banda e non dipende dai componenti di Entity Framework forniti con .NET. Entity Framework 6 funziona sia su .NET 4.0 che su .NET 4.5 e può offrire un notevole vantaggio per le prestazioni a coloro che non sono stati aggiornati da .NET 4.0, ma vogliono i bit di Entity Framework più recenti nell'applicazione. Quando questo documento menziona Entity Framework 6, fa riferimento alla versione più recente disponibile al momento della stesura di questo articolo: versione 6.1.0.
2. Esecuzione di query ad accesso sporadico e frequente
La prima volta che viene eseguita una query su un determinato modello, Entity Framework esegue molte operazioni in background per caricare e convalidare il modello. Spesso si fa riferimento a questa prima query come query "a freddo". Altre query su un modello già caricato sono note come query "warm" e sono molto più veloci.
Verrà ora visualizzata una panoramica generale del tempo impiegato per l'esecuzione di una query con Entity Framework e si vedrà dove si stanno migliorando in Entity Framework 6.
Prima esecuzione di query: query a freddo
| Scritture utente codice | Azione | Impatto sulle prestazioni di EF4 | Impatto sulle prestazioni di EF5 | Impatto sulle prestazioni di EF6 |
|---|---|---|---|---|
using(var db = new MyContext()) { |
Creazione del contesto | Medio | Medio | Basso |
var q1 = from c in db.Customers where c.Id == id1 select c; |
Creazione di espressioni di query | Basso | Basso | Basso |
var c1 = q1.First(); |
Esecuzione di query LINQ | - Caricamento dei metadati: elevato ma memorizzato nella cache - Generazione di visualizzazioni: potenzialmente molto elevata ma memorizzata nella cache - Valutazione dei parametri: medio - Traduzione di query: Medio - Generazione materializer: media ma memorizzata nella cache - Esecuzione di query di database: potenzialmente elevata + Connessione ion. Aperto + Command.ExecuteReader + DataReader.Read Materializzazione degli oggetti: medio - Ricerca identità: medio |
- Caricamento dei metadati: elevato ma memorizzato nella cache - Generazione di visualizzazioni: potenzialmente molto elevata ma memorizzata nella cache - Valutazione dei parametri: Bassa - Traduzione di query: medio ma memorizzato nella cache - Generazione materializer: media ma memorizzata nella cache - Esecuzione di query di database: potenzialmente elevata (query migliori in alcune situazioni) + Connessione ion. Aperto + Command.ExecuteReader + DataReader.Read Materializzazione degli oggetti: medio - Ricerca identità: medio |
- Caricamento dei metadati: elevato ma memorizzato nella cache - Generazione di viste: media ma memorizzata nella cache - Valutazione dei parametri: Bassa - Traduzione di query: medio ma memorizzato nella cache - Generazione materializer: media ma memorizzata nella cache - Esecuzione di query di database: potenzialmente elevata (query migliori in alcune situazioni) + Connessione ion. Aperto + Command.ExecuteReader + DataReader.Read Materializzazione degli oggetti: media (più veloce di EF5) - Ricerca identità: medio |
} |
Connessione ion. Vicino | Basso | Basso | Basso |
Seconda esecuzione di query: query ad accesso frequente
| Scritture utente codice | Azione | Impatto sulle prestazioni di EF4 | Impatto sulle prestazioni di EF5 | Impatto sulle prestazioni di EF6 |
|---|---|---|---|---|
using(var db = new MyContext()) { |
Creazione del contesto | Medio | Medio | Basso |
var q1 = from c in db.Customers where c.Id == id1 select c; |
Creazione di espressioni di query | Basso | Basso | Basso |
var c1 = q1.First(); |
Esecuzione di query LINQ | - Ricerca di caricamento dei metadati - Visualizzare - Valutazione dei parametri: medio - Ricerca traduzione - Ricerca di generazione - Esecuzione di query di database: potenzialmente elevata + Connessione ion. Aperto + Command.ExecuteReader + DataReader.Read Materializzazione degli oggetti: medio - Ricerca identità: medio |
- Ricerca di caricamento dei metadati - Visualizzare - Valutazione dei parametri: Bassa - Ricerca traduzione - Ricerca di generazione - Esecuzione di query di database: potenzialmente elevata (query migliori in alcune situazioni) + Connessione ion. Aperto + Command.ExecuteReader + DataReader.Read Materializzazione degli oggetti: medio - Ricerca identità: medio |
- Ricerca di caricamento dei metadati - Visualizzare - Valutazione dei parametri: Bassa - Ricerca traduzione - Ricerca di generazione - Esecuzione di query di database: potenzialmente elevata (query migliori in alcune situazioni) + Connessione ion. Aperto + Command.ExecuteReader + DataReader.Read Materializzazione degli oggetti: media (più veloce di EF5) - Ricerca identità: medio |
} |
Connessione ion. Vicino | Basso | Basso | Basso |
Esistono diversi modi per ridurre il costo delle prestazioni delle query ad accesso sporadico e ad accesso frequente e verranno esaminate nella sezione seguente. In particolare, si esaminerà la riduzione del costo del caricamento del modello nelle query ad accesso sporadico usando viste pre-generate, che dovrebbero aiutare ad alleviare i problemi di prestazioni riscontrati durante la generazione della visualizzazione. Per le query ad accesso frequente, verrà illustrata la memorizzazione nella cache del piano di query, nessuna query di rilevamento e diverse opzioni di esecuzione delle query.
2.1 Che cos'è la generazione di visualizzazioni?
Per comprendere qual è la generazione di visualizzazioni, è necessario prima comprendere quali sono le "visualizzazioni di mapping". Le viste di mapping sono rappresentazioni eseguibili delle trasformazioni specificate nel mapping per ogni set di entità e associazione. Internamente, queste viste di mapping prendono la forma di CQT (alberi delle query canonici). Esistono due tipi di viste di mapping:
- Viste query: rappresentano la trasformazione necessaria per passare dallo schema del database al modello concettuale.
- Aggiornare le viste: rappresentano la trasformazione necessaria per passare dal modello concettuale allo schema del database.
Tenere presente che il modello concettuale può essere diverso dallo schema del database in vari modi. Ad esempio, una singola tabella può essere usata per archiviare i dati per due tipi di entità diversi. L'ereditarietà e i mapping non semplici svolgono un ruolo nella complessità delle visualizzazioni di mapping.
Il processo di calcolo di queste viste in base alla specifica del mapping è quello che chiamiamo generazione di viste. La generazione delle viste può essere eseguita in modo dinamico quando un modello viene caricato o in fase di compilazione usando "viste pregenerate"; quest'ultimo viene serializzato sotto forma di istruzioni Entity SQL in un file C# o VB.
Quando vengono generate visualizzazioni, vengono convalidate anche. Dal punto di vista delle prestazioni, la maggior parte del costo della generazione di viste è in realtà la convalida delle viste che garantisce che le connessioni tra le entità abbiano senso e abbiano la cardinalità corretta per tutte le operazioni supportate.
Quando viene eseguita una query su un set di entità, la query viene combinata con la vista query corrispondente e il risultato di questa composizione viene eseguito tramite il compilatore di piani per creare la rappresentazione della query che l'archivio di backup può comprendere. Per SQL Server, il risultato finale di questa compilazione sarà un'istruzione T-SQL edizione Standard LECT. La prima volta che viene eseguito un aggiornamento su un set di entità, la visualizzazione di aggiornamento viene eseguita tramite un processo simile per trasformarlo in istruzioni DML per il database di destinazione.
2.2 Fattori che influiscono sulle prestazioni della generazione di viste
Le prestazioni del passaggio di generazione della visualizzazione non solo dipendono dalle dimensioni del modello, ma anche dalla modalità di interconnessione del modello. Se due entità sono connesse tramite una catena di ereditarietà o un'associazione, si dice che siano connesse. Analogamente, se due tabelle sono connesse tramite una chiave esterna, sono connesse. Man mano che il numero di entità e tabelle connesse negli schemi aumenta, aumenta il costo di generazione della vista.
L'algoritmo usato per generare e convalidare le visualizzazioni è esponenziale nel peggiore dei casi, anche se si usano alcune ottimizzazioni per migliorarlo. I fattori più importanti che sembrano influire negativamente sulle prestazioni sono:
- Dimensioni del modello, che fanno riferimento al numero di entità e alla quantità di associazioni tra queste entità.
- Complessità del modello, in particolare l'ereditarietà che implica un numero elevato di tipi.
- Uso di associazioni indipendenti anziché associazioni di chiavi esterne.
Per i modelli di piccole dimensioni, i modelli semplici possono essere sufficientemente piccoli da non disturbare l'uso di viste pregenerate. Man mano che aumentano le dimensioni e la complessità del modello, sono disponibili diverse opzioni per ridurre il costo della generazione e della convalida della visualizzazione.
2.3 Uso di viste pregenerate per ridurre il tempo di caricamento del modello
Per informazioni dettagliate su come usare le viste pregenerate in Entity Framework 6, vedere Viste di mapping pregenerate
2.3.1 Viste pregenerate con Entity Framework Power Tools Community Edition
È possibile usare Entity Framework 6 Power Tools Community Edition per generare visualizzazioni dei modelli EDMX e Code First facendo clic con il pulsante destro del mouse sul file di classe del modello e usando il menu Entity Framework per selezionare "Genera visualizzazioni". Entity Framework Power Tools Community Edition funziona solo nei contesti derivati da DbContext.
2.3.2 Come usare le viste pregenerate con un modello creato da EDMGen
EDMGen è un'utilità fornita con .NET e funziona con Entity Framework 4 e 5, ma non con Entity Framework 6. EDMGen consente di generare un file di modello, il livello oggetto e le visualizzazioni dalla riga di comando. Uno degli output sarà un file Views nel linguaggio preferito, VB o C#. Si tratta di un file di codice contenente frammenti di codice Entity SQL per ogni set di entità. Per abilitare le visualizzazioni pregenerate, è sufficiente includere il file nel progetto.
Se si apportano manualmente modifiche ai file di schema per il modello, sarà necessario generare nuovamente il file delle visualizzazioni. A tale scopo, eseguire EDMGen con il flag /mode:ViewGeneration .
2.3.3 Come usare viste pre-generate con un file EDMX
È anche possibile usare EDMGen per generare visualizzazioni per un file EDMX, ovvero l'argomento MSDN di riferimento precedente descrive come aggiungere un evento di pre-compilazione per eseguire questa operazione, ma questo è complicato e in alcuni casi non è possibile. In genere è più semplice usare un modello T4 per generare le visualizzazioni quando il modello si trova in un file edmx.
Il blog del team di ADO.NET include un post che descrive come usare un modello T4 per la generazione di visualizzazioni ( <https://learn.microsoft.com/archive/blogs/adonet/how-to-use-a-t4-template-for-view-generation>). Questo post include un modello che può essere scaricato e aggiunto al progetto. Il modello è stato scritto per la prima versione di Entity Framework, quindi non è garantito che funzioni con le versioni più recenti di Entity Framework. Tuttavia, è possibile scaricare un set più aggiornato di modelli di generazione di viste per Entity Framework 4 e 5 da Visual Studio Gallery:
- VB.NET: <http://visualstudiogallery.msdn.microsoft.com/118b44f2-1b91-4de2-a584-7a680418941d>
- C#: <http://visualstudiogallery.msdn.microsoft.com/ae7730ce-ddab-470f-8456-1b313cd2c44d>
Se si usa Entity Framework 6, è possibile ottenere i modelli T4 di generazione di visualizzazione da Visual Studio Gallery all'indirizzo <http://visualstudiogallery.msdn.microsoft.com/18a7db90-6705-4d19-9dd1-0a6c23d0751f>.
2.4 Riduzione del costo della generazione di visualizzazioni
L'uso di viste pregenerate sposta il costo della generazione di viste dal caricamento del modello (runtime) alla fase di progettazione. Anche se ciò migliora le prestazioni di avvio in fase di esecuzione, si continuerà a riscontrare il dolore della generazione della visualizzazione durante lo sviluppo. Esistono diversi trucchi aggiuntivi che consentono di ridurre il costo della generazione della visualizzazione, sia in fase di compilazione che in fase di esecuzione.
2.4.1 Uso delle associazioni di chiavi esterne per ridurre i costi di generazione della visualizzazione
Si è visto un certo numero di casi in cui il passaggio delle associazioni nel modello da associazioni indipendenti a associazioni chiave esterne ha notevolmente migliorato il tempo impiegato per la generazione di visualizzazioni.
Per illustrare questo miglioramento, sono stati generati due versioni del modello Navision usando EDMGen. Nota: vedere appendice C per una descrizione del modello Navision. Il modello Navision è interessante per questo esercizio a causa della sua grande quantità di entità e relazioni tra di esse.
Una versione di questo modello molto grande è stata generata con associazioni di chiavi esterne e l'altra è stata generata con associazioni indipendenti. È stato quindi impiegato il tempo necessario per generare le visualizzazioni per ogni modello. Il test di Entity Framework 5 ha usato il metodo GenerateViews() dalla classe EntityViewGenerator per generare le visualizzazioni, mentre il test di Entity Framework 6 ha usato il metodo GenerateViews() dalla classe Archiviazione MappingItemCollection. Ciò è dovuto alla ristrutturazione del codice che si è verificata nella codebase di Entity Framework 6.
Usando Entity Framework 5, la generazione di viste per il modello con chiavi esterne ha richiesto 65 minuti in un computer lab. Non è noto per quanto tempo sarebbe necessario generare le visualizzazioni per il modello che usava associazioni indipendenti. È stato lasciato il test in esecuzione per più di un mese prima del riavvio del computer nel lab per installare gli aggiornamenti mensili.
Usando Entity Framework 6, la generazione di viste per il modello con chiavi esterne ha richiesto 28 secondi nello stesso computer lab. La generazione di viste per il modello che usa associazioni indipendenti ha richiesto 58 secondi. I miglioramenti apportati a Entity Framework 6 nel codice di generazione della vista indicano che molti progetti non necessitano di viste pregenerate per ottenere tempi di avvio più rapidi.
È importante notare che le viste pregenerate in Entity Framework 4 e 5 possono essere eseguite con EDMGen o Entity Framework Power Tools. Per la generazione di visualizzazioni di Entity Framework 6, è possibile usare Entity Framework Power Tools o a livello di codice, come descritto in Viste di mapping pregenerate.
2.4.1.1 Come usare chiavi esterne anziché associazioni indipendenti
Quando si usano EDMGen o Entity Designer in Visual Studio, si ottengono IK per impostazione predefinita e sono necessari solo un singolo flag della casella di controllo o della riga di comando per passare da FK a IA.
Se si dispone di un modello Code First di grandi dimensioni, l'uso di associazioni indipendenti avrà lo stesso effetto sulla generazione di viste. È possibile evitare questo impatto includendo le proprietà Foreign Key sulle classi per gli oggetti dipendenti, anche se alcuni sviluppatori considereranno questo aspetto inquinare il modello a oggetti. Altre informazioni su questo argomento sono disponibili in <http://blog.oneunicorn.com/2011/12/11/whats-the-deal-with-mapping-foreign-keys-using-the-entity-framework/>.
| Quando si usa | Operazione da eseguire |
|---|---|
| Finestra di progettazione entità | Dopo aver aggiunto un'associazione tra due entità, assicurarsi di disporre di un vincolo referenziale. I vincoli referenziale indicano a Entity Framework di usare chiavi esterne anziché associazioni indipendenti. Per altri dettagli, vedere <https://learn.microsoft.com/archive/blogs/efdesign/foreign-keys-in-the-entity-framework>. |
| EDMGen | Quando si usa EDMGen per generare i file dal database, le chiavi esterne verranno rispettate e aggiunte al modello come tale. Per altre informazioni sulle diverse opzioni esposte da EDMGen, visitare http://msdn.microsoft.com/library/bb387165.aspx. |
| Code First | Vedere la sezione "Relazione Convention" dell'argomento Code First Conventions per informazioni su come includere proprietà di chiave esterna su oggetti dipendenti quando si usa Code First. |
2.4.2 Spostamento del modello in un assembly separato
Quando il modello viene incluso direttamente nel progetto dell'applicazione e si generano visualizzazioni tramite un evento di pre-compilazione o un modello T4, la generazione e la convalida della visualizzazione verranno eseguite ogni volta che il progetto viene ricompilato, anche se il modello non è stato modificato. Se si sposta il modello in un assembly separato e lo si fa riferimento al progetto dell'applicazione, è possibile apportare altre modifiche all'applicazione senza dover ricompilare il progetto contenente il modello.
Nota: quando si sposta il modello in assembly separati, ricordarsi di copiare i stringa di connessione per il modello nel file di configurazione dell'applicazione del progetto client.
2.4.3 Disabilitare la convalida di un modello basato su edmx
I modelli EDMX vengono convalidati in fase di compilazione, anche se il modello è invariato. Se il modello è già stato convalidato, è possibile eliminare la convalida in fase di compilazione impostando la proprietà "Validate on Build" su false nella finestra delle proprietà. Quando si modifica il mapping o il modello, è possibile riabilitare temporaneamente la convalida per verificare le modifiche.
Si noti che sono stati apportati miglioramenti delle prestazioni a Entity Framework Designer per Entity Framework 6 e il costo di "Validate on Build" è molto inferiore rispetto alle versioni precedenti della finestra di progettazione.
3 Memorizzazione nella cache in Entity Framework
Entity Framework presenta le seguenti forme di memorizzazione nella cache predefinita:
- Memorizzazione nella cache degli oggetti: ObjectStateManager integrato in un'istanza di ObjectContext tiene traccia della memoria degli oggetti recuperati usando tale istanza. Questa operazione è nota anche come cache di primo livello.
- Memorizzazione nella cache del piano di query: riutilizzo del comando dell'archivio generato quando una query viene eseguita più volte.
- Memorizzazione nella cache dei metadati: condivisione dei metadati per un modello tra connessioni diverse allo stesso modello.
Oltre alle cache fornite da Entity Framework, è anche possibile usare un tipo speciale di provider di dati ADO.NET noto come provider di wrapping per estendere Entity Framework con una cache per i risultati recuperati dal database, noti anche come memorizzazione nella cache di secondo livello.
3.1 Memorizzazione nella cache degli oggetti
Per impostazione predefinita, quando viene restituita un'entità nei risultati di una query, appena prima che EF la materializzi, ObjectContext verificherà se un'entità con la stessa chiave è già stata caricata nel relativo ObjectStateManager. Se un'entità con le stesse chiavi è già presente in Entity Framework lo includerà nei risultati della query. Anche se Entity Framework eseguirà comunque la query sul database, questo comportamento può ignorare gran parte del costo di materializzazione dell'entità più volte.
3.1.1 Recupero di entità dalla cache degli oggetti con DbContext Find
A differenza di una query regolare, il metodo Find in DbSet (API incluse per la prima volta in EF 4.1) eseguirà una ricerca in memoria prima di eseguire la query sul database. È importante notare che due diverse istanze di ObjectContext avranno due istanze ObjectStateManager diverse, vale a dire che hanno cache di oggetti separate.
Trova usa il valore della chiave primaria per tentare di trovare un'entità rilevata dal contesto. Se l'entità non è nel contesto, verrà eseguita e valutata una query sul database e viene restituito null se l'entità non viene trovata nel contesto o nel database. Si noti che Find restituisce anche entità aggiunte al contesto, ma non ancora salvate nel database.
Quando si usa Trova è necessario prendere in considerazione le prestazioni. Le chiamate a questo metodo per impostazione predefinita attiveranno una convalida della cache degli oggetti per rilevare le modifiche ancora in sospeso nel database. Questo processo può essere molto costoso se nella cache degli oggetti sono presenti un numero molto elevato di oggetti o in un oggetto grafico di grandi dimensioni aggiunto alla cache degli oggetti, ma può anche essere disabilitato. In alcuni casi, è possibile percepire su un ordine di grandezza della differenza nella chiamata al metodo Find quando si disabilita il rilevamento automatico delle modifiche. Tuttavia, un secondo ordine di grandezza viene percepito quando l'oggetto si trova effettivamente nella cache rispetto a quando l'oggetto deve essere recuperato dal database. Di seguito è riportato un grafico di esempio con misurazioni eseguite usando alcuni dei microbenchmark, espressi in millisecondi, con un carico di 5000 entità:

Esempio di Trova con rilevamento automatico delle modifiche disabilitate:
context.Configuration.AutoDetectChangesEnabled = false;
var product = context.Products.Find(productId);
context.Configuration.AutoDetectChangesEnabled = true;
...
Ciò che è necessario considerare quando si usa il metodo Find è:
- Se l'oggetto non si trova nella cache, i vantaggi di Find vengono negati, ma la sintassi è ancora più semplice rispetto a una query per chiave.
- Se il rilevamento automatico delle modifiche è abilitato, il costo del metodo Find può aumentare di un ordine di grandezza o ancora di più a seconda della complessità del modello e della quantità di entità nella cache degli oggetti.
Tenere inoltre presente che Find restituisce solo l'entità che si sta cercando e non carica automaticamente le entità associate se non sono già presenti nella cache degli oggetti. Se è necessario recuperare le entità associate, è possibile usare una query per chiave con caricamento eager. Per altre informazioni, vedere 8.1 Caricamento differita e Caricamento eager.
3.1.2 Problemi di prestazioni quando la cache degli oggetti presenta molte entità
La cache degli oggetti consente di aumentare la velocità di risposta complessiva di Entity Framework. Tuttavia, quando la cache degli oggetti ha una quantità molto elevata di entità caricate, può influire su determinate operazioni, ad esempio Add, Remove, Find, Entry, SaveChanges e altro ancora. In particolare, le operazioni che attivano una chiamata a DetectChanges saranno influenzate negativamente dalle cache di oggetti di grandi dimensioni. DetectChanges sincronizza l'oggetto grafico con il gestore dello stato dell'oggetto e le relative prestazioni determinano direttamente le dimensioni del grafico dell'oggetto. Per altre informazioni su DetectChanges, vedere Rilevamento delle modifiche nelle entità POCO.
Quando si usa Entity Framework 6, gli sviluppatori possono chiamare AddRange e RemoveRange direttamente in un oggetto DbSet, anziché eseguire l'iterazione in una raccolta e chiamare Add una sola volta per ogni istanza. Il vantaggio dell'uso dei metodi di intervallo è che il costo di DetectChanges viene pagato una sola volta per l'intero set di entità anziché una sola volta per ogni entità aggiunta.
3.2 Memorizzazione nella cache del piano di query
La prima volta che viene eseguita una query, passa attraverso il compilatore di piani interno per convertire la query concettuale nel comando store , ad esempio T-SQL che viene eseguito quando viene eseguito su SQL Server. Se la memorizzazione nella cache del piano di query è abilitata, alla successiva esecuzione della query viene recuperato il comando store direttamente dalla cache del piano di query per l'esecuzione, ignorando il compilatore del piano.
La cache del piano di query viene condivisa tra istanze ObjectContext all'interno dello stesso AppDomain. Non è necessario tenere premuto un'istanza di ObjectContext per trarre vantaggio dalla memorizzazione nella cache del piano di query.
3.2.1 Alcune note sulla memorizzazione nella cache del piano di query
- La cache dei piani di query viene condivisa per tutti i tipi di query: Entity SQL, LINQ to Entities e CompiledQuery.
- Per impostazione predefinita, la memorizzazione nella cache del piano di query è abilitata per le query Entity SQL, eseguite tramite EntityCommand o tramite ObjectQuery. È abilitato anche per impostazione predefinita per le query LINQ to Entities in Entity Framework in .NET 4.5 e in Entity Framework 6
- La memorizzazione nella cache del piano di query può essere disabilitata impostando la proprietà EnablePlanCaching (in EntityCommand o ObjectQuery) su false. Ad esempio:
var query = from customer in context.Customer
where customer.CustomerId == id
select new
{
customer.CustomerId,
customer.Name
};
ObjectQuery oQuery = query as ObjectQuery;
oQuery.EnablePlanCaching = false;
- Per le query con parametri, la modifica del valore del parametro continuerà a raggiungere la query memorizzata nella cache. Tuttavia, la modifica dei facet di un parametro (ad esempio, dimensioni, precisione o scala) raggiungerà una voce diversa nella cache.
- Quando si usa Entity SQL, la stringa di query fa parte della chiave. La modifica della query comporta voci di cache diverse, anche se le query sono equivalenti a livello funzionale. Sono incluse le modifiche apportate a maiuscole e minuscole o spazi vuoti.
- Quando si usa LINQ, la query viene elaborata per generare una parte della chiave. La modifica dell'espressione LINQ genererà quindi una chiave diversa.
- Possono essere applicate altre limitazioni tecniche; Per altri dettagli, vedere Query compilate automaticamente.
3.2.2 Algoritmo di rimozione della cache
Comprendere il funzionamento dell'algoritmo interno consente di capire quando abilitare o disabilitare la memorizzazione nella cache del piano di query. L'algoritmo di pulizia è il seguente:
- Una volta che la cache contiene un numero impostato di voci (800), si avvia un timer che esegue periodicamente (una volta al minuto) lo sweep della cache.
- Durante gli sweep della cache, le voci vengono rimosse dalla cache su base LFRU (meno frequentemente , usate di recente). Questo algoritmo prende in considerazione sia il numero di passaggi che l'età quando si decide quali voci vengono espulse.
- Alla fine di ogni sweep della cache, la cache contiene di nuovo 800 voci.
Tutte le voci della cache vengono trattate equamente quando si determinano le voci da rimuovere. Ciò significa che il comando store per una query CompiledQuery ha la stessa probabilità di rimozione del comando store per una query Entity SQL.
Si noti che il timer di rimozione della cache viene avviato quando sono presenti 800 entità nella cache, ma la cache viene spazzata solo 60 secondi dopo l'avvio di questo timer. Ciò significa che, per un massimo di 60 secondi, la cache può aumentare in modo da essere piuttosto grande.
3.2.3 Metriche di test che illustrano le prestazioni di memorizzazione nella cache dei piani di query
Per illustrare l'effetto della memorizzazione nella cache del piano di query sulle prestazioni dell'applicazione, è stato eseguito un test in cui è stata eseguita una serie di query Entity SQL sul modello Navision. Vedere l'appendice per una descrizione del modello Navision e dei tipi di query eseguite. In questo test viene prima eseguita l'iterazione dell'elenco delle query ed è possibile eseguirle una sola volta per aggiungerle alla cache (se la memorizzazione nella cache è abilitata). Questo passaggio non è previsto. Successivamente, sospendiamo il thread principale per oltre 60 secondi per consentire lo sweep della cache; infine, si scorre l'elenco una seconda volta per eseguire le query memorizzate nella cache. Inoltre, la cache dei piani di SQL Server viene scaricata prima dell'esecuzione di ogni set di query in modo che i tempi ottenuti riflettano accuratamente il vantaggio offerto dalla cache del piano di query.
3.2.3.1 Risultati dei test
| Test | EF5 non contiene cache | EF5 memorizzato nella cache | EF6 non contiene cache | EF6 memorizzato nella cache |
|---|---|---|---|---|
| Enumerazione di tutte le query 18723 | 124 | 125,4 | 124,3 | 125.3 |
| Evitare lo sweep (solo le prime 800 query, indipendentemente dalla complessità) | 41.7 | 5.5 | 40,5 | 5.4 |
| Solo le query AggregangSubtotals (178 totali, che evitano lo sweep) | 39,5 | 4.5 | 38.1 | 4.6 |
Tutti i tempi in secondi.
Morale: quando si eseguono molte query distinte (ad esempio, query create in modo dinamico), la memorizzazione nella cache non aiuta e lo svuotamento risultante della cache può mantenere le query che potrebbero trarre vantaggio dalla memorizzazione nella cache dei piani dall'uso effettivo.
Le query di aggregazioneSubtotals sono le query più complesse delle query con cui è stato testato. Come previsto, più complessa è la query, maggiore sarà il vantaggio che si noterà dalla memorizzazione nella cache del piano di query.
Poiché una query CompiledQuery è in realtà una query LINQ con il relativo piano memorizzato nella cache, il confronto di una query CompiledQuery rispetto alla query Entity SQL equivalente dovrebbe avere risultati simili. Infatti, se un'app ha molte query Entity SQL dinamiche, la compilazione della cache con query causerà anche la "decompilazione" di CompiledQueries quando vengono scaricate dalla cache. In questo scenario, le prestazioni possono essere migliorate disabilitando la memorizzazione nella cache nelle query dinamiche per assegnare priorità a CompiledQueries. Meglio ancora, naturalmente, sarebbe riscrivere l'app in modo da usare query con parametri anziché query dinamiche.
3.3 Uso di CompiledQuery per migliorare le prestazioni con le query LINQ
I test indicano che l'uso di CompiledQuery può offrire un vantaggio del 7% rispetto alle query LINQ compilate automaticamente; Ciò significa che si spenderà il 7% meno tempo per l'esecuzione del codice dallo stack di Entity Framework; non significa che l'applicazione sarà più veloce del 7%. In generale, il costo di scrittura e gestione degli oggetti CompiledQuery in EF 5.0 potrebbe non essere utile rispetto ai vantaggi. Il chilometraggio può variare, quindi esercitare questa opzione se il progetto richiede il push aggiuntivo. Si noti che CompiledQueries sono compatibili solo con i modelli derivati da ObjectContext e non compatibili con i modelli derivati da DbContext.
Per altre informazioni sulla creazione e la chiamata di un oggetto CompiledQuery, vedere Query compilate (LINQ to Entities).
Quando si usa un oggetto CompiledQuery è necessario tenere presenti due considerazioni, ovvero il requisito di usare istanze statiche e i problemi che presentano con la componibilità. Di seguito viene fornita una spiegazione approfondita di queste due considerazioni.
3.3.1 Usare istanze di CompiledQuery statiche
Poiché la compilazione di una query LINQ è un processo dispendioso in termini di tempo, non si vuole eseguire questa operazione ogni volta che è necessario recuperare i dati dal database. Le istanze compiledQuery consentono di compilare una sola volta ed eseguire più volte, ma è necessario prestare attenzione e procurarsi di riutilizzare la stessa istanza CompiledQuery ogni volta anziché compilarla più volte. L'uso di membri statici per archiviare le istanze CompiledQuery diventa necessario; in caso contrario, non vedrai alcun vantaggio.
Si supponga, ad esempio, che la pagina abbia il corpo del metodo seguente per gestire la visualizzazione dei prodotti per la categoria selezionata:
// Warning: this is the wrong way of using CompiledQuery
using (NorthwindEntities context = new NorthwindEntities())
{
string selectedCategory = this.categoriesList.SelectedValue;
var productsForCategory = CompiledQuery.Compile<NorthwindEntities, string, IQueryable<Product>>(
(NorthwindEntities nwnd, string category) =>
nwnd.Products.Where(p => p.Category.CategoryName == category)
);
this.productsGrid.DataSource = productsForCategory.Invoke(context, selectedCategory).ToList();
this.productsGrid.DataBind();
}
this.productsGrid.Visible = true;
In questo caso, si creerà una nuova istanza CompiledQuery in tempo reale ogni volta che viene chiamato il metodo. Anziché visualizzare i vantaggi delle prestazioni recuperando il comando store dalla cache del piano di query, CompiledQuery passa attraverso il compilatore di piani ogni volta che viene creata una nuova istanza. In effetti, si inquinerà la cache del piano di query con una nuova voce CompiledQuery ogni volta che viene chiamato il metodo.
Si vuole invece creare un'istanza statica della query compilata, quindi si richiama la stessa query compilata ogni volta che viene chiamato il metodo . Un modo per farlo consiste nell'aggiungere l'istanza CompiledQuery come membro del contesto dell'oggetto. È quindi possibile rendere le operazioni più pulite accedendo a CompiledQuery tramite un metodo helper:
public partial class NorthwindEntities : ObjectContext
{
private static readonly Func<NorthwindEntities, string, IEnumerable<Product>> productsForCategoryCQ = CompiledQuery.Compile(
(NorthwindEntities context, string categoryName) =>
context.Products.Where(p => p.Category.CategoryName == categoryName)
);
public IEnumerable<Product> GetProductsForCategory(string categoryName)
{
return productsForCategoryCQ.Invoke(this, categoryName).ToList();
}
Questo metodo helper viene richiamato come segue:
this.productsGrid.DataSource = context.GetProductsForCategory(selectedCategory);
3.3.2 Composizione di un oggetto CompiledQuery
La possibilità di comporre su qualsiasi query LINQ è estremamente utile; a tale scopo, è sufficiente richiamare un metodo dopo IQueryable, ad esempio Skip() o Count(). Tuttavia, questa operazione restituisce essenzialmente un nuovo oggetto IQueryable. Anche se non c'è nulla da impedire tecnicamente di comporre su un Oggetto CompiledQuery, in questo modo la generazione di un nuovo oggetto IQueryable che richiede di nuovo il passaggio attraverso il compilatore di piani.
Alcuni componenti useranno oggetti IQueryable composti per abilitare funzionalità avanzate. Ad esempio, GridView di ASP.NET può essere associato a dati a un oggetto IQueryable tramite la proprietà SelectMethod. GridView comporrà quindi questo oggetto IQueryable per consentire l'ordinamento e il paging sul modello di dati. Come si può notare, l'uso di un oggetto CompiledQuery per GridView non ha raggiunto la query compilata, ma genera una nuova query ricompilata automaticamente.
Una posizione in cui è possibile eseguire questa operazione è quando si aggiungono filtri progressivi a una query. Si supponga, ad esempio, di avere una pagina Clienti con diversi elenchi a discesa per i filtri facoltativi , ad esempio Country e OrdersCount. È possibile comporre questi filtri sui risultati IQueryable di un oggetto CompiledQuery, ma in questo modo la nuova query passa attraverso il compilatore di piani ogni volta che viene eseguita.
using (NorthwindEntities context = new NorthwindEntities())
{
IQueryable<Customer> myCustomers = context.InvokeCustomersForEmployee();
if (this.orderCountFilterList.SelectedItem.Value != defaultFilterText)
{
int orderCount = int.Parse(orderCountFilterList.SelectedValue);
myCustomers = myCustomers.Where(c => c.Orders.Count > orderCount);
}
if (this.countryFilterList.SelectedItem.Value != defaultFilterText)
{
myCustomers = myCustomers.Where(c => c.Address.Country == countryFilterList.SelectedValue);
}
this.customersGrid.DataSource = myCustomers;
this.customersGrid.DataBind();
}
Per evitare questa ricompilazione, è possibile riscrivere CompiledQuery per tenere conto dei possibili filtri:
private static readonly Func<NorthwindEntities, int, int?, string, IQueryable<Customer>> customersForEmployeeWithFiltersCQ = CompiledQuery.Compile(
(NorthwindEntities context, int empId, int? countFilter, string countryFilter) =>
context.Customers.Where(c => c.Orders.Any(o => o.EmployeeID == empId))
.Where(c => countFilter.HasValue == false || c.Orders.Count > countFilter)
.Where(c => countryFilter == null || c.Address.Country == countryFilter)
);
Che verrà richiamato nell'interfaccia utente come segue:
using (NorthwindEntities context = new NorthwindEntities())
{
int? countFilter = (this.orderCountFilterList.SelectedIndex == 0) ?
(int?)null :
int.Parse(this.orderCountFilterList.SelectedValue);
string countryFilter = (this.countryFilterList.SelectedIndex == 0) ?
null :
this.countryFilterList.SelectedValue;
IQueryable<Customer> myCustomers = context.InvokeCustomersForEmployeeWithFilters(
countFilter, countryFilter);
this.customersGrid.DataSource = myCustomers;
this.customersGrid.DataBind();
}
Un compromesso qui è che il comando dell'archivio generato avrà sempre i filtri con i controlli Null, ma questi dovrebbero essere abbastanza semplici per il server di database per ottimizzare:
...
WHERE ((0 = (CASE WHEN (@p__linq__1 IS NOT NULL) THEN cast(1 as bit) WHEN (@p__linq__1 IS NULL) THEN cast(0 as bit) END)) OR ([Project3].[C2] > @p__linq__2)) AND (@p__linq__3 IS NULL OR [Project3].[Country] = @p__linq__4)
3.4 Memorizzazione nella cache dei metadati
Entity Framework supporta anche la memorizzazione nella cache dei metadati. Si tratta essenzialmente della memorizzazione nella cache delle informazioni sul tipo e delle informazioni di mapping da tipo a database tra connessioni diverse allo stesso modello. La cache dei metadati è univoca per AppDomain.
3.4.1 Algoritmo di memorizzazione nella cache dei metadati
Le informazioni sui metadati per un modello vengono archiviate in itemCollection per ogni entità Connessione ion.
- Come nota laterale, esistono oggetti ItemCollection diversi per diverse parti del modello. Ad esempio, StoreItemCollections contiene le informazioni sul modello di database; ObjectItemCollection contiene informazioni sul modello di dati; EdmItemCollection contiene informazioni sul modello concettuale.
Se due connessioni usano la stessa stringa di connessione, condivideranno la stessa istanza itemCollection.
Equivalenti a livello funzionale ma in modo testuale diversi stringa di connessione possono comportare cache di metadati diverse. Si esegue il token stringa di connessione, quindi è sufficiente modificare l'ordine dei token in modo da generare metadati condivisi. Ma due stringa di connessione che sembrano funzionalmente uguali potrebbero non essere valutate come identiche dopo la tokenizzazione.
ItemCollection viene controllato periodicamente per l'utilizzo. Se si è determinato che un'area di lavoro non è stata eseguita di recente, verrà contrassegnata per la pulizia nella successiva sweep della cache.
La semplice creazione di un'entità Connessione ion causerà la creazione di una cache dei metadati (anche se le raccolte di elementi in esso contenute non verranno inizializzate fino all'apertura della connessione). Questa area di lavoro rimarrà in memoria finché l'algoritmo di memorizzazione nella cache non lo determina come "in uso".
Il team di consulenza clienti ha scritto un post di blog che descrive la conservazione di un riferimento a itemCollection per evitare la "deprecazione" quando si usano modelli di grandi dimensioni: <https://learn.microsoft.com/archive/blogs/appfabriccat/holding-a-reference-to-the-ef-metadataworkspace-for-wcf-services>.
3.4.2 Relazione tra la memorizzazione nella cache dei metadati e la memorizzazione nella cache del piano di query
L'istanza della cache del piano di query si trova nell'elemento ItemCollection di MetadataWorkspace dei tipi di archivio. Ciò significa che i comandi dell'archivio memorizzati nella cache verranno usati per le query su qualsiasi contesto di cui viene creata un'istanza usando un oggetto MetadataWorkspace specificato. Ciò significa anche che se sono presenti due stringhe di connessioni leggermente diverse e non corrispondono dopo il tokenizing, si avranno istanze della cache del piano di query diverse.
3.5 Memorizzazione nella cache dei risultati
Con la memorizzazione nella cache dei risultati (nota anche come "memorizzazione nella cache di secondo livello"), si mantengono i risultati delle query in una cache locale. Quando si esegue una query, si verifica prima di tutto se i risultati sono disponibili in locale prima di eseguire una query sull'archivio. Anche se la memorizzazione nella cache dei risultati non è supportata direttamente da Entity Framework, è possibile aggiungere una cache di secondo livello usando un provider di wrapping. Un provider di wrapping di esempio con una cache di secondo livello è La cache di secondo livello di Entity Framework di Alachisoft basata su NCache.
Questa implementazione della memorizzazione nella cache di secondo livello è una funzionalità inserita che viene eseguita dopo la valutazione dell'espressione LINQ (e funcletizzata) e il piano di esecuzione della query viene calcolato o recuperato dalla cache di primo livello. La cache di secondo livello archivierà quindi solo i risultati del database non elaborato, quindi la pipeline di materializzazione viene comunque eseguita in seguito.
3.5.1 Riferimenti aggiuntivi per la memorizzazione nella cache dei risultati con il provider di wrapping
- Julie Lerman ha scritto un articolo MSDN relativo alla memorizzazione nella cache di secondo livello in Entity Framework e Windows Azure che include come aggiornare il provider di wrapping di esempio per usare la memorizzazione nella cache di Windows Server AppFabric: https://msdn.microsoft.com/magazine/hh394143.aspx
- Se si usa Entity Framework 5, il blog del team include un post che descrive come eseguire le operazioni con il provider di memorizzazione nella cache per Entity Framework 5: <https://learn.microsoft.com/archive/blogs/adonet/ef-caching-with-jarek-kowalskis-provider>. Include anche un modello T4 per automatizzare l'aggiunta della memorizzazione nella cache di secondo livello al progetto.
4 Query autocompilate
Quando viene eseguita una query su un database con Entity Framework, è necessario eseguire una serie di passaggi prima di materializzare effettivamente i risultati; uno di questi passaggi è Compilazione query. Le query Entity SQL erano note per ottenere prestazioni ottimali perché vengono memorizzate automaticamente nella cache, quindi la seconda o la terza volta che si esegue la stessa query può ignorare il compilatore del piano e usare invece il piano memorizzato nella cache.
Entity Framework 5 ha introdotto anche la memorizzazione nella cache automatica per le query LINQ to Entities. Nelle edizioni precedenti di Entity Framework la creazione di un oggetto CompiledQuery per velocizzare le prestazioni era una pratica comune, in quanto ciò renderebbe la query LINQ to Entities cacheable. Poiché la memorizzazione nella cache viene eseguita automaticamente senza l'uso di un oggetto CompiledQuery, questa funzionalità è denominata "query con completamento automatico". Per altre informazioni sulla cache del piano di query e sui relativi meccanismi, vedere Memorizzazione nella cache del piano di query.
Entity Framework rileva quando una query deve essere ricompilata e lo fa quando la query viene richiamata anche se è stata compilata in precedenza. Le condizioni comuni che causano la ricompilazione della query sono:
- Modifica dell'oggetto MergeOption associato alla query. La query memorizzata nella cache non verrà usata, ma il compilatore del piano verrà eseguito di nuovo e il piano appena creato verrà memorizzato nella cache.
- Modifica del valore di ContextOptions.UseCSharpNullComparisonBehavior. Si ottiene lo stesso effetto della modifica di MergeOption.
Altre condizioni possono impedire che la query usi la cache. Esempi comuni:
- Uso di IEnumerable<T>. Contains<>(T value).
- Uso di funzioni che producono query con costanti.
- Utilizzo delle proprietà di un oggetto non mappato.
- Collegamento della query a un'altra query che richiede la ricompilazione.
4.1 Uso di IEnumerable<T>. <Contiene T>(valore T)
Entity Framework non memorizza nella cache le query che richiamano IEnumerable<T>. <Contiene T>(valore T) rispetto a una raccolta in memoria, poiché i valori della raccolta sono considerati volatili. La query di esempio seguente non verrà memorizzata nella cache, quindi verrà sempre elaborata dal compilatore di piani:
int[] ids = new int[10000];
...
using (var context = new MyContext())
{
var query = context.MyEntities
.Where(entity => ids.Contains(entity.Id));
var results = query.ToList();
...
}
Si noti che le dimensioni di IEnumerable su cui viene eseguito Contains determinano la velocità o la lentezza della compilazione della query. Le prestazioni possono risentire in modo significativo quando si usano raccolte di grandi dimensioni, ad esempio quella illustrata nell'esempio precedente.
Entity Framework 6 contiene ottimizzazioni per il modo in cui IEnumerable<T>. <Contiene T>(valore T) funziona quando vengono eseguite query. Il codice SQL generato è molto più veloce da produrre e più leggibile e nella maggior parte dei casi viene eseguito più velocemente nel server.
4.2 Uso di funzioni che producono query con costanti
Gli operatori LINQ Skip(), Take(), Contains() e DefautIfEmpty() non producono query SQL con parametri, ma inseriscono i valori passati come costanti. Per questo motivo, le query che potrebbero altrimenti essere identiche finiscono per inquinare la cache del piano di query, sia nello stack EF che nel server di database e non vengono riutilizzate a meno che non vengano usate le stesse costanti in un'esecuzione di query successiva. Ad esempio:
var id = 10;
...
using (var context = new MyContext())
{
var query = context.MyEntities.Select(entity => entity.Id).Contains(id);
var results = query.ToList();
...
}
In questo esempio, ogni volta che questa query viene eseguita con un valore diverso per ID, la query verrà compilata in un nuovo piano.
In particolare prestare attenzione all'uso di Skip e Take quando si esegue il paging. In EF6 questi metodi hanno un overload lambda che rende effettivamente riutilizzabile il piano di query memorizzato nella cache perché EF può acquisire le variabili passate a questi metodi e convertirle in SQLparameters. Ciò consente anche di mantenere la cache più pulita perché in caso contrario ogni query con una costante diversa per Skip e Take otterrebbe la propria voce della cache del piano di query.
Si consideri il codice seguente, che è non ottimale, ma è progettato solo per esemplificare questa classe di query:
var customers = context.Customers.OrderBy(c => c.LastName);
for (var i = 0; i < count; ++i)
{
var currentCustomer = customers.Skip(i).FirstOrDefault();
ProcessCustomer(currentCustomer);
}
Una versione più veloce dello stesso codice comporta la chiamata a Skip con un'espressione lambda:
var customers = context.Customers.OrderBy(c => c.LastName);
for (var i = 0; i < count; ++i)
{
var currentCustomer = customers.Skip(() => i).FirstOrDefault();
ProcessCustomer(currentCustomer);
}
Il secondo frammento di codice può essere eseguito fino al 11% più velocemente perché lo stesso piano di query viene usato ogni volta che viene eseguita la query, consentendo di risparmiare tempo cpu ed evitare di inquinare la cache delle query. Inoltre, poiché il parametro skip si trova in una chiusura, il codice potrebbe essere simile al seguente:
var i = 0;
var skippyCustomers = context.Customers.OrderBy(c => c.LastName).Skip(() => i);
for (; i < count; ++i)
{
var currentCustomer = skippyCustomers.FirstOrDefault();
ProcessCustomer(currentCustomer);
}
4.3 Uso delle proprietà di un oggetto non mappato
Quando una query usa le proprietà di un tipo di oggetto non mappato come parametro, la query non verrà memorizzata nella cache. Ad esempio:
using (var context = new MyContext())
{
var myObject = new NonMappedType();
var query = from entity in context.MyEntities
where entity.Name.StartsWith(myObject.MyProperty)
select entity;
var results = query.ToList();
...
}
In questo esempio si supponga che la classe NonMappedType non faccia parte del modello Entity. Questa query può essere modificata facilmente in modo da non usare un tipo non mappato e usare invece una variabile locale come parametro per la query:
using (var context = new MyContext())
{
var myObject = new NonMappedType();
var myValue = myObject.MyProperty;
var query = from entity in context.MyEntities
where entity.Name.StartsWith(myValue)
select entity;
var results = query.ToList();
...
}
In questo caso, la query sarà in grado di ottenere memorizzata nella cache e trarrà vantaggio dalla cache del piano di query.
4.4 Collegamento a query che richiedono la ricompilazione
Seguendo lo stesso esempio riportato in precedenza, se si dispone di una seconda query che si basa su una query che deve essere ricompilata, verrà ricompilata anche l'intera seconda query. Ecco un esempio per illustrare questo scenario:
int[] ids = new int[10000];
...
using (var context = new MyContext())
{
var firstQuery = from entity in context.MyEntities
where ids.Contains(entity.Id)
select entity;
var secondQuery = from entity in context.MyEntities
where firstQuery.Any(otherEntity => otherEntity.Id == entity.Id)
select entity;
var results = secondQuery.ToList();
...
}
L'esempio è generico, ma illustra come il collegamento a firstQuery causa l'impossibilità di memorizzare nella cache secondQuery. Se firstQuery non fosse stata una query che richiede la ricompilazione, secondQuery sarebbe stata memorizzata nella cache.
5 NoTracking Query
5.1 Disabilitazione del rilevamento delle modifiche per ridurre il sovraccarico di gestione dello stato
Se si è in uno scenario di sola lettura e si vuole evitare il sovraccarico del caricamento degli oggetti in ObjectStateManager, è possibile eseguire query "Nessun rilevamento". Il rilevamento delle modifiche può essere disabilitato a livello di query.
Si noti tuttavia che disabilitando il rilevamento delle modifiche si disattiva effettivamente la cache degli oggetti. Quando si esegue una query per un'entità, non è possibile ignorare la materializzazione eseguendo il pull dei risultati della query materializzati in precedenza da ObjectStateManager. Se si eseguono ripetutamente query per le stesse entità nello stesso contesto, è possibile che si verifichi effettivamente un vantaggio per le prestazioni dall'abilitazione del rilevamento delle modifiche.
Quando si eseguono query usando ObjectContext, le istanze objectQuery e ObjectSet memorizzano un'opzione MergeOption una volta impostata e le query composte su di esse erediteranno l'opzione MergeOption effettiva della query padre. Quando si usa DbContext, il rilevamento può essere disabilitato chiamando il modificatore AsNoTracking() in DbSet.
5.1.1 Disabilitazione del rilevamento delle modifiche per una query quando si usa DbContext
È possibile cambiare la modalità di una query su NoTracking concatenando una chiamata al metodo AsNoTracking() nella query. A differenza di ObjectQuery, le classi DbSet e DbQuery nell'API DbContext non hanno una proprietà modificabile per MergeOption.
var productsForCategory = from p in context.Products.AsNoTracking()
where p.Category.CategoryName == selectedCategory
select p;
5.1.2 Disabilitazione del rilevamento delle modifiche a livello di query tramite ObjectContext
var productsForCategory = from p in context.Products
where p.Category.CategoryName == selectedCategory
select p;
((ObjectQuery)productsForCategory).MergeOption = MergeOption.NoTracking;
5.1.3 Disabilitazione del rilevamento delle modifiche per un intero set di entità tramite ObjectContext
context.Products.MergeOption = MergeOption.NoTracking;
var productsForCategory = from p in context.Products
where p.Category.CategoryName == selectedCategory
select p;
5.2 Metriche di test che illustrano il vantaggio delle prestazioni delle query NoTracking
In questo test viene esaminato il costo del riempimento di ObjectStateManager confrontando le query Tracking con NoTracking per il modello Navision. Vedere l'appendice per una descrizione del modello Navision e dei tipi di query eseguite. In questo test viene eseguito l'iterazione dell'elenco di query ed eseguirne ognuna una sola volta. Sono state eseguite due varianti del test, una volta con le query NoTracking e una volta con l'opzione di unione predefinita "AppendOnly". Ogni variante è stata eseguita 3 volte e si prende il valore medio delle esecuzioni. Tra i test è possibile cancellare la cache delle query in SQL Server e compattare tempdb eseguendo i comandi seguenti:
- DBCC DROPCLEANBUFFERS
- DBCC FREEPROCCACHE
- DBCC SHRINKDATABA edizione Standard (tempdb, 0)
Risultati dei test, mediano oltre 3 esecuzioni:
| NO TRACKING – WORKING edizione Standard T | NO TRACKING – TIME | APPEND ONLY : WORKING edizione Standard T | APPEND ONLY – TIME | |
|---|---|---|---|---|
| Entity Framework 5 | 460361728 | 1163536 ms | 596545536 | 1273042 ms |
| Entity Framework 6 | 647127040 | 190228 ms | 832798720 | 195521 ms |
Entity Framework 5 avrà un footprint di memoria inferiore alla fine dell'esecuzione rispetto a Entity Framework 6. La memoria aggiuntiva utilizzata da Entity Framework 6 è il risultato di strutture di memoria e codice aggiuntivi che consentono nuove funzionalità e prestazioni migliori.
Esiste anche una differenza chiara nel footprint di memoria quando si usa ObjectStateManager. Entity Framework 5 ha aumentato il footprint del 30% quando si tiene traccia di tutte le entità materializzate dal database. Entity Framework 6 ha aumentato il footprint del 28% quando si esegue questa operazione.
In termini di tempo, Entity Framework 6 ha prestazioni superiori a Entity Framework 5 in questo test di un margine elevato. Entity Framework 6 ha completato il test in circa il 16% del tempo utilizzato da Entity Framework 5. Inoltre, Entity Framework 5 richiede più tempo per il completamento del 9% quando si usa ObjectStateManager. In confronto, Entity Framework 6 usa il 3% di tempo in più quando si usa ObjectStateManager.
6 Opzioni di esecuzione query
Entity Framework offre diversi modi per eseguire query. Verranno esaminate le opzioni seguenti, verranno confrontati i vantaggi e i svantaggi di ognuno e verranno esaminate le relative caratteristiche di prestazioni:
- LINQ to Entities( LINQ to Entities).
- Nessun rilevamento delle entità LINQ to Entities.
- Entity SQL su objectQuery.
- Entity SQL su EntityCommand.
- ExecuteStoreQuery.
- SqlQuery.
- CompiledQuery.
6.1 Query LINQ to Entities
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
Vantaggi
- Adatto per le operazioni CUD.
- Oggetti completamente materializzati.
- Più semplice da scrivere con la sintassi integrata nel linguaggio di programmazione.
- Buone prestazioni.
Svantaggi
- Alcune restrizioni tecniche, ad esempio:
- I modelli che usano DefaultIfEmpty per le query OUTER JOIN generano query più complesse rispetto alle semplici istruzioni OUTER JOIN in Entity SQL.
- Non è ancora possibile usare LIKE con criteri di ricerca generali.
6.2 Nessun rilevamento delle query LINQ to Entities
Quando il contesto deriva ObjectContext:
context.Products.MergeOption = MergeOption.NoTracking;
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
Quando il contesto deriva DbContext:
var q = context.Products.AsNoTracking()
.Where(p => p.Category.CategoryName == "Beverages");
Vantaggi
- Prestazioni migliorate rispetto alle normali query LINQ.
- Oggetti completamente materializzati.
- Più semplice da scrivere con la sintassi integrata nel linguaggio di programmazione.
Svantaggi
- Non adatto per le operazioni CUD.
- Alcune restrizioni tecniche, ad esempio:
- I modelli che usano DefaultIfEmpty per le query OUTER JOIN generano query più complesse rispetto alle semplici istruzioni OUTER JOIN in Entity SQL.
- Non è ancora possibile usare LIKE con criteri di ricerca generali.
Si noti che le query sulle proprietà scalari del progetto non vengono rilevate anche se noTracking non è specificato. Ad esempio:
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages").Select(p => new { p.ProductName });
Questa query specifica in modo esplicito non è NoTracking, ma poiché non materializza un tipo noto al gestore dello stato dell'oggetto, il risultato materializzato non viene rilevato.
6.3 Entity SQL su objectQuery
ObjectQuery<Product> products = context.Products.Where("it.Category.CategoryName = 'Beverages'");
Vantaggi
- Adatto per le operazioni CUD.
- Oggetti completamente materializzati.
- Supporta la memorizzazione nella cache del piano di query.
Svantaggi
- Include stringhe di query testuali che sono più soggette a errori utente rispetto ai costrutti di query incorporati nel linguaggio.
6.4 Entity SQL su un comando di entità
EntityCommand cmd = eConn.CreateCommand();
cmd.CommandText = "Select p From NorthwindEntities.Products As p Where p.Category.CategoryName = 'Beverages'";
using (EntityDataReader reader = cmd.ExecuteReader(CommandBehavior.SequentialAccess))
{
while (reader.Read())
{
// manually 'materialize' the product
}
}
Vantaggi
- Supporta la memorizzazione nella cache dei piani di query in .NET 4.0 (la memorizzazione nella cache dei piani è supportata da tutti gli altri tipi di query in .NET 4.5).
Svantaggi
- Include stringhe di query testuali che sono più soggette a errori utente rispetto ai costrutti di query incorporati nel linguaggio.
- Non adatto per le operazioni CUD.
- I risultati non vengono materializzati automaticamente e devono essere letti dal lettore dati.
6.5 SqlQuery e ExecuteStoreQuery
SqlQuery nel database:
// use this to obtain entities and not track them
var q1 = context.Database.SqlQuery<Product>("select * from products");
SqlQuery in DbSet:
// use this to obtain entities and have them tracked
var q2 = context.Products.SqlQuery("select * from products");
ExecuteStoreQuery:
var beverages = context.ExecuteStoreQuery<Product>(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued, P.DiscontinuedDate
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
Vantaggi
- Prestazioni generalmente più veloci perché il compilatore del piano viene ignorato.
- Oggetti completamente materializzati.
- Adatto per le operazioni CUD quando viene usato da DbSet.
Svantaggi
- La query è testuale e soggetta a errori.
- La query è associata a un back-end specifico usando la semantica di archiviazione anziché la semantica concettuale.
- Quando l'ereditarietà è presente, la query eseguita manualmente deve tenere conto delle condizioni di mapping per il tipo richiesto.
6.6 CompiledQuery
private static readonly Func<NorthwindEntities, string, IQueryable<Product>> productsForCategoryCQ = CompiledQuery.Compile(
(NorthwindEntities context, string categoryName) =>
context.Products.Where(p => p.Category.CategoryName == categoryName)
);
…
var q = context.InvokeProductsForCategoryCQ("Beverages");
Vantaggi
- Offre fino a un miglioramento delle prestazioni del 7% rispetto alle normali query LINQ.
- Oggetti completamente materializzati.
- Adatto per le operazioni CUD.
Svantaggi
- Maggiore complessità e sovraccarico di programmazione.
- Il miglioramento delle prestazioni viene perso durante la composizione di una query compilata.
- Alcune query LINQ non possono essere scritte come CompiledQuery, ad esempio proiezioni di tipi anonimi.
6.7 Confronto delle prestazioni di diverse opzioni di query
Microbenchmark semplici in cui la creazione del contesto non è stata messa al test. È stata misurata una query di 5000 volte per un set di entità non memorizzate nella cache in un ambiente controllato. Questi numeri devono essere presi con un avviso: non riflettono i numeri effettivi prodotti da un'applicazione, ma sono invece una misurazione molto accurata della quantità di prestazioni che c'è quando diverse opzioni di query vengono confrontate apples-to-apples, escludendo il costo di creazione di un nuovo contesto.
| EF | Test | Ora (ms) | Memoria |
|---|---|---|---|
| EF5 | ObjectContext ESQL | 2414 | 38801408 |
| EF5 | ObjectContext Linq Query | 2692 | 38277120 |
| EF5 | DbContext Linq Query No Tracking | 2818 | 41840640 |
| EF5 | DbContext Linq Query | 2930 | 41771008 |
| EF5 | ObjectContext Linq Query No Tracking | 3013 | 38412288 |
| EF6 | ObjectContext ESQL | 2059 | 46039040 |
| EF6 | ObjectContext Linq Query | 3074 | 45248512 |
| EF6 | DbContext Linq Query No Tracking | 3125 | 47575040 |
| EF6 | DbContext Linq Query | 3420 | 47652864 |
| EF6 | ObjectContext Linq Query No Tracking | 3593 | 45260800 |
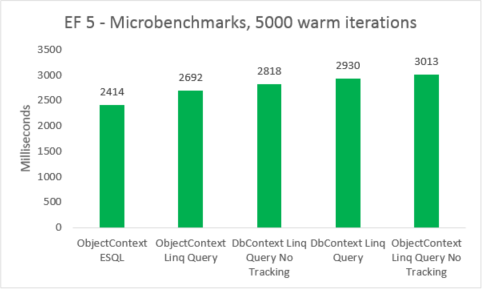
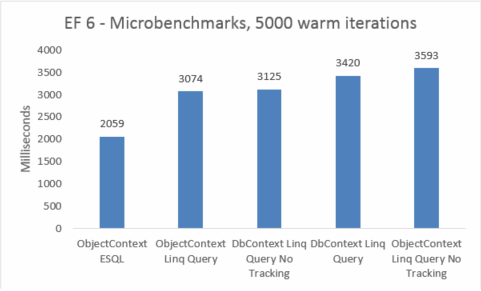
I microbenchmark sono molto sensibili alle piccole modifiche nel codice. In questo caso, la differenza tra i costi di Entity Framework 5 e Entity Framework 6 è dovuta all'aggiunta di intercettazioni e miglioramenti transazionali. Questi numeri di microbenchmark, tuttavia, sono una visione amplificata in un frammento molto piccolo delle operazioni eseguite da Entity Framework. Gli scenari reali di query ad accesso frequente non dovrebbero visualizzare una regressione delle prestazioni durante l'aggiornamento da Entity Framework 5 a Entity Framework 6.
Per confrontare le prestazioni reali delle diverse opzioni di query, sono state create 5 varianti di test separate in cui si usa un'opzione di query diversa per selezionare tutti i prodotti il cui nome di categoria è "Bevande". Ogni iterazione include il costo della creazione del contesto e il costo della materializzazione di tutte le entità restituite. 10 iterazioni vengono eseguite senza tempo prima di prendere la somma di 1000 iterazioni temporali. I risultati visualizzati sono l'esecuzione mediata da 5 esecuzioni di ogni test. Per altre informazioni, vedere Appendice B che include il codice per il test.
| EF | Test | Ora (ms) | Memoria |
|---|---|---|---|
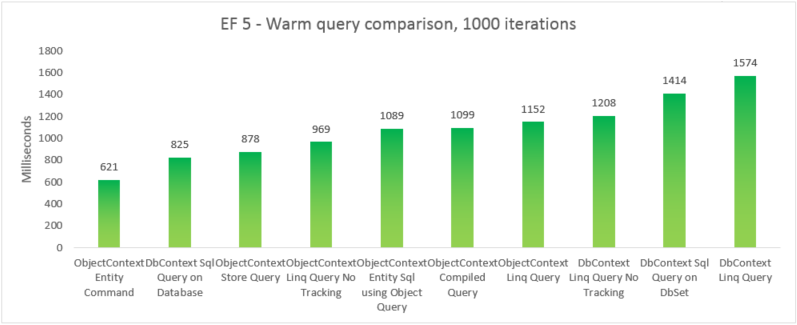
| EF5 | Comando entità ObjectContext | 621 | 39350272 |
| EF5 | Query SQL DbContext nel database | 825 | 37519360 |
| EF5 | ObjectContext Store Query | 878 | 39460864 |
| EF5 | ObjectContext Linq Query No Tracking | 969 | 38293504 |
| EF5 | ObjectContext Entity Sql con Query oggetto | 1089 | 38981632 |
| EF5 | Query compilata ObjectContext | 1099 | 38682624 |
| EF5 | ObjectContext Linq Query | 1152 | 38178816 |
| EF5 | DbContext Linq Query No Tracking | 1208 | 41803776 |
| EF5 | Query SQL DbContext in DbSet | 1414 | 37982208 |
| EF5 | DbContext Linq Query | 1574 | 41738240 |
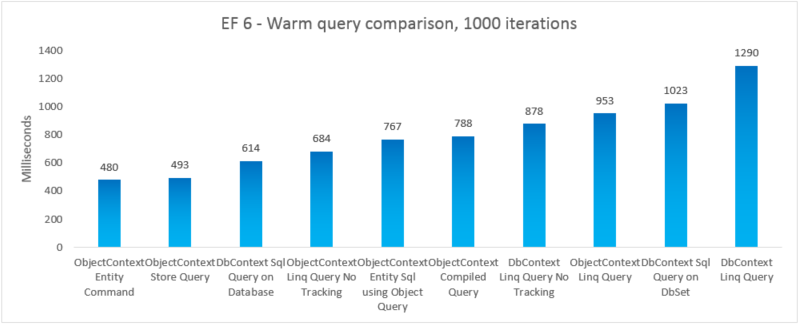
| EF6 | Comando entità ObjectContext | 480 | 47247360 |
| EF6 | ObjectContext Store Query | 493 | 46739456 |
| EF6 | Query SQL DbContext nel database | 614 | 41607168 |
| EF6 | ObjectContext Linq Query No Tracking | 684 | 46333952 |
| EF6 | ObjectContext Entity Sql con Query oggetto | 767 | 48865280 |
| EF6 | Query compilata ObjectContext | 788 | 48467968 |
| EF6 | DbContext Linq Query No Tracking | 878 | 47554560 |
| EF6 | ObjectContext Linq Query | 953 | 47632384 |
| EF6 | Query SQL DbContext in DbSet | 1023 | 41992192 |
| EF6 | DbContext Linq Query | 1290 | 47529984 |
Nota
Per completezza, è stata inclusa una variante in cui viene eseguita una query Entity SQL in un EntityCommand. Tuttavia, poiché i risultati non vengono materializzati per tali query, il confronto non è necessariamente apples-to-apples. Il test include un'approssimazione vicina alla materializzazione per provare a rendere il confronto più equo.
In questo caso end-to-end, Entity Framework 6 supera Entity Framework 5 a causa di miglioramenti delle prestazioni apportati in diverse parti dello stack, tra cui un'inizializzazione DbContext molto più leggera e ricerche T MetadataCollection<più> veloci.
7 Considerazioni sulle prestazioni in fase di progettazione
7.1 Strategie di ereditarietà
Un'altra considerazione sulle prestazioni quando si usa Entity Framework è la strategia di ereditarietà usata. Entity Framework supporta 3 tipi di ereditarietà di base e le relative combinazioni:
- Tabella per gerarchia ( TPH): dove ogni set di ereditarietà esegue il mapping a una tabella con una colonna discriminatoria per indicare quale particolare tipo nella gerarchia viene rappresentato nella riga.
- Tabella per tipo (TPT): dove ogni tipo ha una propria tabella nel database; Le tabelle figlio definiscono solo le colonne che la tabella padre non contiene.
- Tabella per classe (TPC): dove ogni tipo ha una propria tabella completa nel database; Le tabelle figlio definiscono tutti i relativi campi, inclusi quelli definiti nei tipi padre.
Se il modello usa l'ereditarietà TPT, le query generate saranno più complesse di quelle generate con le altre strategie di ereditarietà, che potrebbero comportare tempi di esecuzione più lunghi nell'archivio. La generazione di query su un modello TPT richiederà in genere più tempo e materializzerà gli oggetti risultanti.
Vedere il post di blog MSDN "Considerazioni sulle prestazioni quando si usa L'ereditarietà TPT (tabella per tipo) in Entity Framework". <https://learn.microsoft.com/archive/blogs/adonet/performance-considerations-when-using-tpt-table-per-type-inheritance-in-the-entity-framework>
7.1.1 Evitare TPT nelle applicazioni Model First o Code First
Quando si crea un modello su un database esistente con uno schema TPT, non sono disponibili molte opzioni. Tuttavia, quando si crea un'applicazione usando Model First o Code First, è consigliabile evitare l'ereditarietà TPT per problemi di prestazioni.
Quando si usa Model First nella Creazione guidata entità, si otterrà TPT per qualsiasi ereditarietà nel modello. Se si vuole passare a una strategia di ereditarietà TPH con Model First, è possibile usare "Entity Designer Database Generation Power Pack" disponibile da Visual Studio Gallery ( <http://visualstudiogallery.msdn.microsoft.com/df3541c3-d833-4b65-b942-989e7ec74c87/>).
Quando si usa Code First per configurare il mapping di un modello con ereditarietà, EF userà TPH per impostazione predefinita, pertanto tutte le entità nella gerarchia di ereditarietà verranno mappate alla stessa tabella. Per altri dettagli, vedere la sezione "Mapping con l'API Fluent" dell'articolo "Code First in Entity Framework4.1" in MSDN Magazine ( http://msdn.microsoft.com/magazine/hh126815.aspx).
7.2 Aggiornamento da EF4 per migliorare il tempo di generazione del modello
Un miglioramento specifico di SQL Server per l'algoritmo che genera il livello di archiviazione (SSDL) del modello è disponibile in Entity Framework 5 e 6 e come aggiornamento a Entity Framework 4 quando viene installato Visual Studio 2010 SP1. I risultati del test seguenti illustrano il miglioramento durante la generazione di un modello molto grande, in questo caso il modello Navision. Per altri dettagli su di esso, vedere Appendice C.
Il modello contiene 1005 set di entità e set di associazioni 4227.
| Configurazione | Scomposizione del tempo usata |
|---|---|
| Visual Studio 2010, Entity Framework 4 | Generazione SSDL: 2 ore 27 min Generazione mapping: 1 secondo Generazione CSDL: 1 secondo Generazione ObjectLayer: 1 secondo Generazione visualizzazione: 2 h 14 min |
| Visual Studio 2010 SP1, Entity Framework 4 | Generazione SSDL: 1 secondo Generazione mapping: 1 secondo Generazione CSDL: 1 secondo Generazione ObjectLayer: 1 secondo Generazione visualizzazione: 1 ora 53 min |
| Visual Studio 2013, Entity Framework 5 | Generazione SSDL: 1 secondo Generazione mapping: 1 secondo Generazione CSDL: 1 secondo Generazione ObjectLayer: 1 secondo Generazione visualizzazione: 65 minuti |
| Visual Studio 2013, Entity Framework 6 | Generazione SSDL: 1 secondo Generazione mapping: 1 secondo Generazione CSDL: 1 secondo Generazione ObjectLayer: 1 secondo Generazione visualizzazione: 28 secondi. |
Vale la pena notare che durante la generazione di SSDL, il carico è quasi interamente dedicato a SQL Server, mentre il computer di sviluppo client è in attesa che i risultati vengano restituiti dal server. Gli amministratori di database dovrebbero apprezzare in modo particolare questo miglioramento. Vale anche la pena notare che essenzialmente l'intero costo della generazione di modelli avviene ora in Generazione di viste.
7.3 Suddivisione di modelli di grandi dimensioni con il primo database e il modello
Con l'aumentare delle dimensioni del modello, l'area di progettazione diventa ingombra e difficile da usare. In genere si considera un modello con più di 300 entità troppo grandi per usare in modo efficace la finestra di progettazione. Il post di blog seguente descrive diverse opzioni per la suddivisione di modelli di grandi dimensioni: <https://learn.microsoft.com/archive/blogs/adonet/working-with-large-models-in-entity-framework-part-2>.
Il post è stato scritto per la prima versione di Entity Framework, ma i passaggi sono ancora validi.
7.4 Considerazioni sulle prestazioni con il controllo origine dati entità
Sono stati riscontrati casi in test di prestazioni e stress multithread in cui le prestazioni di un'applicazione Web che usano il controllo EntityDataSource peggiorano significativamente. La causa sottostante è che EntityDataSource chiama ripetutamente MetadataWorkspace.LoadFromAssembly negli assembly a cui fa riferimento l'applicazione Web per individuare i tipi da usare come entità.
La soluzione consiste nell'impostare ContextTypeName di EntityDataSource sul nome del tipo della classe ObjectContext derivata. In questo modo viene disattivato il meccanismo che analizza tutti gli assembly a cui si fa riferimento per i tipi di entità.
L'impostazione del campo ContextTypeName impedisce inoltre un problema funzionale in cui EntityDataSource in .NET 4.0 genera un'eccezione ReflectionTypeLoadException quando non riesce a caricare un tipo da un assembly tramite reflection. Questo problema è stato risolto in .NET 4.5.
7.5 Entità POCO e proxy di rilevamento delle modifiche
Entity Framework consente di usare classi di dati personalizzate insieme al modello di dati senza apportare modifiche alle classi di dati stesse. Pertanto è possibile pertanto utilizzare oggetti POCO (Plain-Old CLR Object), ad esempio gli oggetti di dominio esistenti, con il modello di dati. Queste classi di dati POCO (note anche come oggetti non conformi alla persistenza), mappate a entità definite in un modello di dati, supportano la maggior parte delle stesse query, inserimento, aggiornamento ed eliminazione dei comportamenti dei tipi di entità generati dagli strumenti entity Data Model.
Entity Framework può anche creare classi proxy derivate dai tipi POCO, che vengono usate per abilitare funzionalità come il caricamento differita e il rilevamento automatico delle modifiche nelle entità POCO. Le classi POCO devono soddisfare determinati requisiti per consentire a Entity Framework di usare proxy, come descritto di seguito: http://msdn.microsoft.com/library/dd468057.aspx.
I proxy di rilevamento delle probabilità riceveranno una notifica al gestore dello stato dell'oggetto ogni volta che una delle proprietà delle entità ha modificato il valore, quindi Entity Framework conosce sempre lo stato effettivo delle entità. A tale scopo, aggiungere eventi di notifica al corpo dei metodi setter delle proprietà e fare in modo che il gestore dello stato dell'oggetto eselabori tali eventi. Si noti che la creazione di un'entità proxy in genere sarà più costosa rispetto alla creazione di un'entità POCO non proxy a causa del set aggiunto di eventi creati da Entity Framework.
Quando un'entità POCO non dispone di un proxy di rilevamento modifiche, le modifiche vengono trovate confrontando il contenuto delle entità con una copia di uno stato salvato precedente. Questo confronto approfondito diventerà un processo lungo quando si dispone di molte entità nel contesto o quando le entità hanno una quantità molto elevata di proprietà, anche se nessuna di esse è cambiata dopo l'ultimo confronto.
In sintesi: si pagherà un riscontro delle prestazioni durante la creazione del proxy di rilevamento modifiche, ma il rilevamento delle modifiche consente di velocizzare il processo di rilevamento delle modifiche quando le entità hanno molte proprietà o quando si dispone di molte entità nel modello. Per le entità con un numero ridotto di proprietà in cui la quantità di entità non aumenta troppo, la presenza di proxy di rilevamento modifiche potrebbe non essere molto vantaggiosa.
8 Caricamento di entità correlate
8.1 Caricamento differita rispetto al caricamento eager
Entity Framework offre diversi modi per caricare le entità correlate all'entità di destinazione. Ad esempio, quando si esegue una query per Products, esistono diversi modi in cui gli ordini correlati verranno caricati in Object State Manager. Dal punto di vista delle prestazioni, la domanda più importante da considerare quando si caricano entità correlate sarà se usare caricamento differita o caricamento eager.
Quando si usa Eager Loading, le entità correlate vengono caricate insieme al set di entità di destinazione. Usare un'istruzione Include nella query per indicare le entità correlate da inserire.
Quando si usa Caricamento differita, la query iniziale inserisce solo il set di entità di destinazione. Tuttavia, ogni volta che si accede a una proprietà di navigazione, viene eseguita un'altra query sull'archivio per caricare l'entità correlata.
Dopo il caricamento di un'entità, eventuali altre query per l'entità lo caricheranno direttamente da Object State Manager, indipendentemente dal caricamento differita o dal caricamento eager.
8.2 Come scegliere tra caricamento differita e caricamento eager
L'aspetto importante è che si capisce la differenza tra Caricamento differita e Caricamento Eager in modo da poter fare la scelta corretta per l'applicazione. Ciò consentirà di valutare il compromesso tra più richieste rispetto al database rispetto a una singola richiesta che può contenere un payload di grandi dimensioni. Potrebbe essere opportuno usare il caricamento eager in alcune parti dell'applicazione e il caricamento differita in altre parti.
Come esempio di ciò che accade sotto le quinte, si supponga di voler eseguire una query per i clienti che risiedono nel Regno Unito e il loro numero di ordini.
Uso del caricamento eager
using (NorthwindEntities context = new NorthwindEntities())
{
var ukCustomers = context.Customers.Include(c => c.Orders).Where(c => c.Address.Country == "UK");
var chosenCustomer = AskUserToPickCustomer(ukCustomers);
Console.WriteLine("Customer Id: {0} has {1} orders", customer.CustomerID, customer.Orders.Count);
}
Uso del caricamento differita
using (NorthwindEntities context = new NorthwindEntities())
{
context.ContextOptions.LazyLoadingEnabled = true;
//Notice that the Include method call is missing in the query
var ukCustomers = context.Customers.Where(c => c.Address.Country == "UK");
var chosenCustomer = AskUserToPickCustomer(ukCustomers);
Console.WriteLine("Customer Id: {0} has {1} orders", customer.CustomerID, customer.Orders.Count);
}
Quando si usa il caricamento eager, si eseguirà una singola query che restituisce tutti i clienti e tutti gli ordini. Il comando store è simile al seguente:
SELECT
[Project1].[C1] AS [C1],
[Project1].[CustomerID] AS [CustomerID],
[Project1].[CompanyName] AS [CompanyName],
[Project1].[ContactName] AS [ContactName],
[Project1].[ContactTitle] AS [ContactTitle],
[Project1].[Address] AS [Address],
[Project1].[City] AS [City],
[Project1].[Region] AS [Region],
[Project1].[PostalCode] AS [PostalCode],
[Project1].[Country] AS [Country],
[Project1].[Phone] AS [Phone],
[Project1].[Fax] AS [Fax],
[Project1].[C2] AS [C2],
[Project1].[OrderID] AS [OrderID],
[Project1].[CustomerID1] AS [CustomerID1],
[Project1].[EmployeeID] AS [EmployeeID],
[Project1].[OrderDate] AS [OrderDate],
[Project1].[RequiredDate] AS [RequiredDate],
[Project1].[ShippedDate] AS [ShippedDate],
[Project1].[ShipVia] AS [ShipVia],
[Project1].[Freight] AS [Freight],
[Project1].[ShipName] AS [ShipName],
[Project1].[ShipAddress] AS [ShipAddress],
[Project1].[ShipCity] AS [ShipCity],
[Project1].[ShipRegion] AS [ShipRegion],
[Project1].[ShipPostalCode] AS [ShipPostalCode],
[Project1].[ShipCountry] AS [ShipCountry]
FROM ( SELECT
[Extent1].[CustomerID] AS [CustomerID],
[Extent1].[CompanyName] AS [CompanyName],
[Extent1].[ContactName] AS [ContactName],
[Extent1].[ContactTitle] AS [ContactTitle],
[Extent1].[Address] AS [Address],
[Extent1].[City] AS [City],
[Extent1].[Region] AS [Region],
[Extent1].[PostalCode] AS [PostalCode],
[Extent1].[Country] AS [Country],
[Extent1].[Phone] AS [Phone],
[Extent1].[Fax] AS [Fax],
1 AS [C1],
[Extent2].[OrderID] AS [OrderID],
[Extent2].[CustomerID] AS [CustomerID1],
[Extent2].[EmployeeID] AS [EmployeeID],
[Extent2].[OrderDate] AS [OrderDate],
[Extent2].[RequiredDate] AS [RequiredDate],
[Extent2].[ShippedDate] AS [ShippedDate],
[Extent2].[ShipVia] AS [ShipVia],
[Extent2].[Freight] AS [Freight],
[Extent2].[ShipName] AS [ShipName],
[Extent2].[ShipAddress] AS [ShipAddress],
[Extent2].[ShipCity] AS [ShipCity],
[Extent2].[ShipRegion] AS [ShipRegion],
[Extent2].[ShipPostalCode] AS [ShipPostalCode],
[Extent2].[ShipCountry] AS [ShipCountry],
CASE WHEN ([Extent2].[OrderID] IS NULL) THEN CAST(NULL AS int) ELSE 1 END AS [C2]
FROM [dbo].[Customers] AS [Extent1]
LEFT OUTER JOIN [dbo].[Orders] AS [Extent2] ON [Extent1].[CustomerID] = [Extent2].[CustomerID]
WHERE N'UK' = [Extent1].[Country]
) AS [Project1]
ORDER BY [Project1].[CustomerID] ASC, [Project1].[C2] ASC
Quando si usa il caricamento differita, inizialmente si eseguirà la query seguente:
SELECT
[Extent1].[CustomerID] AS [CustomerID],
[Extent1].[CompanyName] AS [CompanyName],
[Extent1].[ContactName] AS [ContactName],
[Extent1].[ContactTitle] AS [ContactTitle],
[Extent1].[Address] AS [Address],
[Extent1].[City] AS [City],
[Extent1].[Region] AS [Region],
[Extent1].[PostalCode] AS [PostalCode],
[Extent1].[Country] AS [Country],
[Extent1].[Phone] AS [Phone],
[Extent1].[Fax] AS [Fax]
FROM [dbo].[Customers] AS [Extent1]
WHERE N'UK' = [Extent1].[Country]
Ogni volta che si accede alla proprietà di navigazione Orders di un cliente, viene eseguita un'altra query simile alla seguente nello Store:
exec sp_executesql N'SELECT
[Extent1].[OrderID] AS [OrderID],
[Extent1].[CustomerID] AS [CustomerID],
[Extent1].[EmployeeID] AS [EmployeeID],
[Extent1].[OrderDate] AS [OrderDate],
[Extent1].[RequiredDate] AS [RequiredDate],
[Extent1].[ShippedDate] AS [ShippedDate],
[Extent1].[ShipVia] AS [ShipVia],
[Extent1].[Freight] AS [Freight],
[Extent1].[ShipName] AS [ShipName],
[Extent1].[ShipAddress] AS [ShipAddress],
[Extent1].[ShipCity] AS [ShipCity],
[Extent1].[ShipRegion] AS [ShipRegion],
[Extent1].[ShipPostalCode] AS [ShipPostalCode],
[Extent1].[ShipCountry] AS [ShipCountry]
FROM [dbo].[Orders] AS [Extent1]
WHERE [Extent1].[CustomerID] = @EntityKeyValue1',N'@EntityKeyValue1 nchar(5)',@EntityKeyValue1=N'AROUT'
Per altre informazioni, vedere Caricamento di oggetti correlati.
8.2.1 Caricamento differita rispetto al foglio informativo Caricamento eager
Non c'è niente di simile a uno-size-fits-all per scegliere il caricamento eager rispetto al caricamento differita. Provare prima a comprendere le differenze tra entrambe le strategie in modo da poter fare una decisione ben informata; Considerare anche se il codice si adatta a uno degli scenari seguenti:
| Scenario | Il nostro suggerimento |
|---|---|
| È necessario accedere a molte proprietà di navigazione dalle entità recuperate? | No - Entrambe le opzioni probabilmente lo faranno. Tuttavia, se il payload che la query sta portando non è troppo grande, è possibile che si verifichino vantaggi in termini di prestazioni usando il caricamento Eager perché richiederà meno round trip di rete per materializzare gli oggetti. Sì : se è necessario accedere a molte proprietà di navigazione dalle entità, è necessario usare più istruzioni di inclusione nella query con il caricamento Eager. Maggiore sarà il numero di entità incluse, maggiore sarà il payload restituito dalla query. Dopo aver incluso tre o più entità nella query, è consigliabile passare al caricamento differita. |
| Si sa esattamente quali dati saranno necessari in fase di esecuzione? | No - Il caricamento differita sarà migliore per te. In caso contrario, è possibile che si verifichino query per i dati che non saranno necessari. Sì - Il caricamento eager è probabilmente la tua migliore scommessa, che aiuterà a caricare interi set più velocemente. Se la query richiede il recupero di una quantità molto elevata di dati e questo diventa troppo lento, provare invece a caricare lazy. |
| Il codice in esecuzione è lontano dal database? (maggiore latenza di rete) | No : quando la latenza di rete non è un problema, l'uso del caricamento differita può semplificare il codice. Tenere presente che la topologia dell'applicazione può cambiare, quindi non concedere la prossimità del database. Sì : quando la rete è un problema, è possibile decidere solo cosa si adatta meglio allo scenario. In genere il caricamento Eager sarà migliore perché richiede meno round trip. |
8.2.2 Problemi di prestazioni con più include
Quando si sentono domande sulle prestazioni che comportano problemi di tempo di risposta del server, l'origine del problema è spesso query con più istruzioni Include. Anche se l'inclusione di entità correlate in una query è potente, è importante comprendere cosa accade sotto le quinte.
Per una query con più istruzioni Include in esso contenute è necessario un tempo relativamente lungo per passare attraverso il compilatore di piani interno per produrre il comando store. La maggior parte di questo tempo viene impiegato per tentare di ottimizzare la query risultante. Il comando dell'archivio generato conterrà un outer join o un'unione per ogni inclusione, a seconda del mapping. Le query di questo tipo indurranno grafici connessi di grandi dimensioni dal database in un singolo payload, che eseguirà l'acerbate di eventuali problemi di larghezza di banda, soprattutto quando si verifica una notevole ridondanza nel payload( ad esempio, quando vengono usati più livelli di inclusione per attraversare le associazioni nella direzione uno-a-molti).
È possibile verificare i casi in cui le query restituiscono payload eccessivamente di grandi dimensioni accedendo al TSQL sottostante per la query usando ToTraceString ed eseguendo il comando store in SQL Server Management Studio per visualizzare le dimensioni del payload. In questi casi è possibile provare a ridurre il numero di istruzioni Include nella query per inserire solo i dati necessari. In alternativa, è possibile suddividere la query in una sequenza più piccola di sottoquery, ad esempio:
Prima di interrompere la query:
using (NorthwindEntities context = new NorthwindEntities())
{
var customers = from c in context.Customers.Include(c => c.Orders)
where c.LastName.StartsWith(lastNameParameter)
select c;
foreach (Customer customer in customers)
{
...
}
}
Dopo l'interruzione della query:
using (NorthwindEntities context = new NorthwindEntities())
{
var orders = from o in context.Orders
where o.Customer.LastName.StartsWith(lastNameParameter)
select o;
orders.Load();
var customers = from c in context.Customers
where c.LastName.StartsWith(lastNameParameter)
select c;
foreach (Customer customer in customers)
{
...
}
}
Questo funzionerà solo sulle query rilevate, poiché si usa la possibilità che il contesto debba eseguire automaticamente la risoluzione delle identità e la correzione dell'associazione.
Come per il caricamento differita, il compromesso sarà maggiore per le query per payload più piccoli. È anche possibile usare le proiezioni di singole proprietà per selezionare in modo esplicito solo i dati necessari da ogni entità, ma in questo caso non verranno caricati entità e gli aggiornamenti non saranno supportati.
8.2.3 Soluzione alternativa per ottenere il caricamento differita delle proprietà
Entity Framework attualmente non supporta il caricamento differita di proprietà scalari o complesse. Tuttavia, nei casi in cui si dispone di una tabella che include un oggetto di grandi dimensioni, ad esempio un BLOB, è possibile usare la suddivisione delle tabelle per separare le proprietà di grandi dimensioni in un'entità separata. Si supponga, ad esempio, di avere una tabella Product che include una colonna di foto varbinary. Se non è spesso necessario accedere a questa proprietà nelle query, è possibile usare la suddivisione delle tabelle per inserire solo le parti dell'entità necessarie normalmente. L'entità che rappresenta la foto del prodotto verrà caricata solo quando è necessaria in modo esplicito.
Una risorsa valida che illustra come abilitare la suddivisione delle tabelle è il post di blog "Suddivisione tabelle in Entity Framework" di Gil Fink: <http://blogs.microsoft.co.il/blogs/gilf/archive/2009/10/13/table-splitting-in-entity-framework.aspx>.
9 Altre considerazioni
9.1 Garbage Collection server
Alcuni utenti potrebbero riscontrare conflitti di risorse che limitano il parallelismo previsto quando Il Garbage Collector non è configurato correttamente. Ogni volta che EF viene usato in uno scenario multithreading o in qualsiasi applicazione simile a un sistema lato server, assicurarsi di abilitare Server Garbage Collection. Questa operazione viene eseguita tramite una semplice impostazione nel file di configurazione dell'applicazione:
<?xmlversion="1.0" encoding="utf-8" ?>
<configuration>
<runtime>
<gcServer enabled="true" />
</runtime>
</configuration>
Ciò dovrebbe ridurre la contesa del thread e aumentare la velocità effettiva fino al 30% negli scenari saturi della CPU. In generale, è consigliabile testare sempre il comportamento dell'applicazione usando la Garbage Collection classica (ottimizzata per scenari lato interfaccia utente e lato client) e Garbage Collection del server.
9.2 AutoDetectChanges
Come accennato in precedenza, Entity Framework potrebbe mostrare problemi di prestazioni quando la cache degli oggetti ha molte entità. Alcune operazioni, ad esempio Add, Remove, Find, Entry e SaveChanges, attivano chiamate a DetectChanges che potrebbero utilizzare una grande quantità di CPU in base alla dimensione della cache degli oggetti. Il motivo è che la cache degli oggetti e il gestore dello stato dell'oggetto tentano di rimanere sincronizzati il più possibile in ogni operazione eseguita in un contesto in modo che i dati prodotti siano corretti in un'ampia gamma di scenari.
In genere è consigliabile lasciare abilitato il rilevamento automatico delle modifiche di Entity Framework per l'intera durata dell'applicazione. Se lo scenario è influenzato negativamente dall'utilizzo elevato della CPU e i profili indicano che la causa è la chiamata a DetectChanges, valutare la possibilità di disattivare temporaneamente AutoDetectChanges nella parte sensibile del codice:
try
{
context.Configuration.AutoDetectChangesEnabled = false;
var product = context.Products.Find(productId);
...
}
finally
{
context.Configuration.AutoDetectChangesEnabled = true;
}
Prima di disattivare AutoDetectChanges, è utile comprendere che ciò potrebbe causare la perdita di Entity Framework per tenere traccia di determinate informazioni sulle modifiche apportate alle entità. Se gestito in modo non corretto, ciò potrebbe causare incoerenza dei dati nell'applicazione. Per altre informazioni sulla disattivazione di AutoDetectChanges, vedere <http://blog.oneunicorn.com/2012/03/12/secrets-of-detectchanges-part-3-switching-off-automatic-detectchanges/>.
9.3 Contesto per richiesta
I contesti di Entity Framework devono essere usati come istanze di breve durata per offrire l'esperienza di prestazioni ottimale. Si prevede che i contesti siano di breve durata e rimossi e, di conseguenza, sono stati implementati per essere molto leggeri e riutilizzare i metadati quando possibile. Negli scenari Web è importante tenere presente questo aspetto e non avere un contesto per più della durata di una singola richiesta. Analogamente, in scenari non Web, il contesto deve essere rimosso in base alla comprensione dei diversi livelli di memorizzazione nella cache in Entity Framework. In generale, è consigliabile evitare di avere un'istanza di contesto per tutta la durata dell'applicazione, nonché i contesti per thread e contesti statici.
9.4 Semantica null del database
Entity Framework per impostazione predefinita genererà codice SQL con semantica di confronto null C#. Si consideri la query di esempio seguente:
int? categoryId = 7;
int? supplierId = 8;
decimal? unitPrice = 0;
short? unitsInStock = 100;
short? unitsOnOrder = 20;
short? reorderLevel = null;
var q = from p incontext.Products
where p.Category.CategoryName == "Beverages"
|| (p.CategoryID == categoryId
|| p.SupplierID == supplierId
|| p.UnitPrice == unitPrice
|| p.UnitsInStock == unitsInStock
|| p.UnitsOnOrder == unitsOnOrder
|| p.ReorderLevel == reorderLevel)
select p;
var r = q.ToList();
In questo esempio viene confrontato un numero di variabili nullable con proprietà nullable nell'entità, ad esempio SupplierID e UnitPrice. Sql generato per questa query chiederà se il valore del parametro è uguale al valore della colonna o se entrambi i valori del parametro e della colonna sono Null. In questo modo il server di database gestisce i valori Null e offre un'esperienza C# coerente su diversi fornitori di database. D'altra parte, il codice generato è un po ' contorto e potrebbe non funzionare correttamente quando la quantità di confronti nell'istruzione where della query aumenta fino a un numero elevato.
Un modo per gestire questa situazione consiste nell'usare la semantica null del database. Si noti che questo comportamento potrebbe essere potenzialmente diverso rispetto alla semantica Null C#, poiché ora Entity Framework genererà sql più semplice che espone il modo in cui il motore di database gestisce i valori Null. La semantica Null del database può essere attivata per contesto con una singola riga di configurazione rispetto alla configurazione del contesto:
context.Configuration.UseDatabaseNullSemantics = true;
Le query di piccole e medie dimensioni non visualizzeranno un miglioramento delle prestazioni percepibile quando si usa la semantica Null del database, ma la differenza diventerà più evidente nelle query con un numero elevato di potenziali confronti Null.
Nella query di esempio precedente, la differenza di prestazioni è inferiore al 2% in un microbenchmark in esecuzione in un ambiente controllato.
9.5 Asincrono
Entity Framework 6 ha introdotto il supporto delle operazioni asincrone durante l'esecuzione in .NET 4.5 o versione successiva. Nella maggior parte dei casi, le applicazioni con contese correlate alle operazioni di I/O trarranno il massimo vantaggio dall'uso di query asincrone e operazioni di salvataggio. Se l'applicazione non subisce conflitti di I/O, l'uso di asincrona, nei casi migliori, viene eseguito in modo sincrono e restituisce il risultato nella stessa quantità di tempo di una chiamata sincrona o, nel peggiore dei casi, semplicemente rinviare l'esecuzione a un'attività asincrona e aggiungere tempo aggiuntivo al completamento dello scenario.
Per informazioni sul funzionamento della programmazione asincrona che consente di decidere se async migliorerà le prestazioni dell'applicazione, vedere Programmazione asincrona con Async e Await. Per altre informazioni sull'uso di operazioni asincrone in Entity Framework, vedere Query asincrona e Salva.
9.6 NGEN
Entity Framework 6 non è disponibile nell'installazione predefinita di .NET Framework. Di conseguenza, gli assembly di Entity Framework non sono NGEN per impostazione predefinita, il che significa che tutto il codice di Entity Framework è soggetto agli stessi costi JIT'ing di qualsiasi altro assembly MSIL. Ciò potrebbe compromettere l'esperienza F5 durante lo sviluppo e l'avvio a freddo dell'applicazione negli ambienti di produzione. Per ridurre i costi di CPU e memoria di JIT, è consigliabile usare NGEN per le immagini di Entity Framework in base alle esigenze. Per altre informazioni su come migliorare le prestazioni di avvio di Entity Framework 6 con NGEN, vedere Miglioramento delle prestazioni di avvio con NGen.
9.7 Code First e EDMX
I motivi di Entity Framework relativi al problema di mancata corrispondenza tra la programmazione orientata agli oggetti e i database relazionali hanno una rappresentazione in memoria del modello concettuale (gli oggetti), lo schema di archiviazione (il database) e un mapping tra i due. Questi metadati sono denominati Entity Data Model o EDM per brevità. Da questo EDM, Entity Framework deriva le visualizzazioni per eseguire il round trip dei dati dagli oggetti in memoria al database e tornare indietro.
Quando Entity Framework viene usato con un file EDMX che specifica formalmente il modello concettuale, lo schema di archiviazione e il mapping, la fase di caricamento del modello deve solo verificare che l'EDM sia corretto (ad esempio, assicurarsi che non siano presenti mapping), quindi generare le visualizzazioni, quindi convalidare le visualizzazioni e disporre di questi metadati pronti per l'uso. Solo in seguito è possibile eseguire una query o salvare nuovi dati nell'archivio dati.
L'approccio Code First è, al suo centro, un sofisticato generatore di Entity Data Model. Entity Framework deve produrre un EDM dal codice fornito; a tale scopo, analizzando le classi coinvolte nel modello, applicando convenzioni e configurando il modello tramite l'API Fluent. Dopo la compilazione dell'EDM, Entity Framework si comporta essenzialmente come se fosse presente un file EDMX nel progetto. Di conseguenza, la compilazione del modello da Code First aggiunge complessità aggiuntive che si traduce in un tempo di avvio più lento per Entity Framework rispetto alla presenza di edMX. Il costo dipende completamente dalle dimensioni e dalla complessità del modello in fase di compilazione.
Quando si sceglie di usare EDMX rispetto a Code First, è importante sapere che la flessibilità introdotta da Code First aumenta il costo della compilazione del modello per la prima volta. Se l'applicazione può sopportare il costo di questo caricamento per la prima volta, in genere Code First sarà il modo migliore per procedere.
10 Analisi delle prestazioni
10.1 Uso del profiler di Visual Studio
Se si verificano problemi di prestazioni con Entity Framework, è possibile usare un profiler come quello integrato in Visual Studio per vedere dove l'applicazione sta trascorrendo il tempo. Questo è lo strumento usato per generare i grafici a torta nel post di blog "Esplorazione delle prestazioni del ADO.NET Entity Framework - Parte 1" ( <https://learn.microsoft.com/archive/blogs/adonet/exploring-the-performance-of-the-ado-net-entity-framework-part-1>) che mostra dove Entity Framework impiega il tempo durante le query ad accesso sporadico e ad accesso frequente.
Il post di blog "Profiling Entity Framework using the Visual Studio 2010 Profiler" (Profiling Entity Framework using the Visual Studio 2010 Profiler) (Profiling Entity Framework using the Visual Studio 2010 Profiler) (Profiling Entity Framework using the Visual Studio 2010 Profiler) (Profiling Entity Framework using the Visual Studio 2010 Profiler) (Profiling Entity Framework using the Visual Studio 2010 Profiler) (Profiling Entity Framework using the Visual Studio 2010 Profiler) (Profiling Entity Framework using the Visual Studio 2010 Profiler) (Profiling Entity Framework using <https://learn.microsoft.com/archive/blogs/dmcat/profiling-entity-framework-using-the-visual-studio-2010-profiler>. Questo post è stato scritto per un'applicazione Windows. Se è necessario profilare un'applicazione Web, gli strumenti di Windows Performance Recorder (WPR) e Windows analizzatore prestazioni (WPA) possono funzionare meglio che lavorare da Visual Studio. WPR e WPA fanno parte di Windows Performance Toolkit, incluso in Windows Assessment and Deployment Kit.
10.2 Profilatura di applicazioni/database
Gli strumenti come il profiler integrato in Visual Studio indicano dove l'applicazione sta trascorrendo del tempo. È disponibile un altro tipo di profiler che esegue l'analisi dinamica dell'applicazione in esecuzione, in produzione o pre-produzione a seconda delle esigenze e cerca errori comuni e anti-modelli di accesso al database.
Due profiler disponibili in commercio sono Entity Framework Profiler ( <http://efprof.com>) e ORMProfiler ( <http://ormprofiler.com>).
Se l'applicazione è un'applicazione MVC usando Code First, è possibile usare Il MiniProfiler di StackExchange. Scott Hanselman descrive questo strumento nel suo blog all'indirizzo: <http://www.hanselman.com/blog/NuGetPackageOfTheWeek9ASPNETMiniProfilerFromStackExchangeRocksYourWorld.aspx>.
Per altre informazioni sulla profilatura dell'attività del database dell'applicazione, vedere l'articolo MSDN Magazine di Julie Lerman intitolato Profiling Database Activity in the Entity Framework ( Attività del database di profilatura in Entity Framework).
10.3 Logger di database
Se si usa Entity Framework 6, è consigliabile usare anche la funzionalità di registrazione predefinita. La proprietà Database del contesto può essere incaricata di registrare l'attività tramite una semplice configurazione una riga:
using (var context = newQueryComparison.DbC.NorthwindEntities())
{
context.Database.Log = Console.WriteLine;
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
In questo esempio l'attività del database verrà registrata nella console, ma la proprietà Log può essere configurata per chiamare qualsiasi delegato della stringa> di azione<.
Se si vuole abilitare la registrazione del database senza ricompilare e si usa Entity Framework 6.1 o versione successiva, è possibile farlo aggiungendo un intercettore nel file web.config o app.config dell'applicazione.
<interceptors>
<interceptor type="System.Data.Entity.Infrastructure.Interception.DatabaseLogger, EntityFramework">
<parameters>
<parameter value="C:\Path\To\My\LogOutput.txt"/>
</parameters>
</interceptor>
</interceptors>
Per altre informazioni su come aggiungere la registrazione senza ricompilare passare a <http://blog.oneunicorn.com/2014/02/09/ef-6-1-turning-on-logging-without-recompiling/>.
11 Appendice
11.1 A. Ambiente di test
Questo ambiente usa una configurazione di 2 computer con il database in un computer separato dall'applicazione client. I computer si trovano nello stesso rack, quindi la latenza di rete è relativamente bassa, ma più realistica di un ambiente a computer singolo.
11.1.1 Server app
11.1.1.1 Ambiente software
- Ambiente software di Entity Framework 4
- Nome sistema operativo: Windows Server 2008 R2 Enterprise SP1.
- Visual Studio 2010 - Ultimate.
- Visual Studio 2010 SP1 (solo per alcuni confronti).
- Entity Framework 5 e 6 Ambiente software
- Nome sistema operativo: Windows 8.1 Enterprise
- Visual Studio 2013 - Ultimate.
11.1.1.2 Ambiente hardware
- Processore doppio: CPU Intel(R) Xeon(R) L5520 W3530 a 2,27 GHz, 2261 Mhz8 GHz, 4 core, 84 processori logici.
- RamRAM da 2412 GB.
- 136 GB SCSI250GB unità SATA 7200 rpm 3GB/s suddivisa in 4 partizioni.
11.1.2 Server di database
11.1.2.1 Ambiente software
- Nome sistema operativo: Windows Server 2008 R28.1 Enterprise SP1.
- SQL Server 2008 R22012.
11.1.2.2 Ambiente hardware
- Processore singolo: Intel(R) Xeon(R) CPU L5520 a 2,27 GHz, 2261 MhzES-1620 0 a 3,60 GHz, 4 core, 8 processori logici.
- RamRAM da 824 GB.
- 465 GB ATA500GB unità SATA 7200 rpm 6GB/s suddivisa in 4 partizioni.
11.2 B. Test di confronto delle prestazioni delle query
Il modello Northwind è stato usato per eseguire questi test. È stato generato dal database usando Entity Framework Designer. È stato quindi usato il codice seguente per confrontare le prestazioni delle opzioni di esecuzione delle query:
using System;
using System.Collections.Generic;
using System.Data;
using System.Data.Common;
using System.Data.Entity.Infrastructure;
using System.Data.EntityClient;
using System.Data.Objects;
using System.Linq;
namespace QueryComparison
{
public partial class NorthwindEntities : ObjectContext
{
private static readonly Func<NorthwindEntities, string, IQueryable<Product>> productsForCategoryCQ = CompiledQuery.Compile(
(NorthwindEntities context, string categoryName) =>
context.Products.Where(p => p.Category.CategoryName == categoryName)
);
public IQueryable<Product> InvokeProductsForCategoryCQ(string categoryName)
{
return productsForCategoryCQ(this, categoryName);
}
}
public class QueryTypePerfComparison
{
private static string entityConnectionStr = @"metadata=res://*/Northwind.csdl|res://*/Northwind.ssdl|res://*/Northwind.msl;provider=System.Data.SqlClient;provider connection string='data source=.;initial catalog=Northwind;integrated security=True;multipleactiveresultsets=True;App=EntityFramework'";
public void LINQIncludingContextCreation()
{
using (NorthwindEntities context = new NorthwindEntities())
{
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
public void LINQNoTracking()
{
using (NorthwindEntities context = new NorthwindEntities())
{
context.Products.MergeOption = MergeOption.NoTracking;
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
public void CompiledQuery()
{
using (NorthwindEntities context = new NorthwindEntities())
{
var q = context.InvokeProductsForCategoryCQ("Beverages");
q.ToList();
}
}
public void ObjectQuery()
{
using (NorthwindEntities context = new NorthwindEntities())
{
ObjectQuery<Product> products = context.Products.Where("it.Category.CategoryName = 'Beverages'");
products.ToList();
}
}
public void EntityCommand()
{
using (EntityConnection eConn = new EntityConnection(entityConnectionStr))
{
eConn.Open();
EntityCommand cmd = eConn.CreateCommand();
cmd.CommandText = "Select p From NorthwindEntities.Products As p Where p.Category.CategoryName = 'Beverages'";
using (EntityDataReader reader = cmd.ExecuteReader(CommandBehavior.SequentialAccess))
{
List<Product> productsList = new List<Product>();
while (reader.Read())
{
DbDataRecord record = (DbDataRecord)reader.GetValue(0);
// 'materialize' the product by accessing each field and value. Because we are materializing products, we won't have any nested data readers or records.
int fieldCount = record.FieldCount;
// Treat all products as Product, even if they are the subtype DiscontinuedProduct.
Product product = new Product();
product.ProductID = record.GetInt32(0);
product.ProductName = record.GetString(1);
product.SupplierID = record.GetInt32(2);
product.CategoryID = record.GetInt32(3);
product.QuantityPerUnit = record.GetString(4);
product.UnitPrice = record.GetDecimal(5);
product.UnitsInStock = record.GetInt16(6);
product.UnitsOnOrder = record.GetInt16(7);
product.ReorderLevel = record.GetInt16(8);
product.Discontinued = record.GetBoolean(9);
productsList.Add(product);
}
}
}
}
public void ExecuteStoreQuery()
{
using (NorthwindEntities context = new NorthwindEntities())
{
ObjectResult<Product> beverages = context.ExecuteStoreQuery<Product>(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
beverages.ToList();
}
}
public void ExecuteStoreQueryDbContext()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var beverages = context.Database.SqlQuery\<QueryComparison.DbC.Product>(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
beverages.ToList();
}
}
public void ExecuteStoreQueryDbSet()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var beverages = context.Products.SqlQuery(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
beverages.ToList();
}
}
public void LINQIncludingContextCreationDbContext()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
public void LINQNoTrackingDbContext()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var q = context.Products.AsNoTracking().Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
}
}
11.3 C. Modello Navision
Il database Navision è un database di grandi dimensioni usato per demo di Microsoft Dynamics – NAV. Il modello concettuale generato contiene 1005 set di entità e 4227 set di associazioni. Il modello usato nel test è "flat" e non è stata aggiunta alcuna ereditarietà.
11.3.1 Query usate per i test Navision
L'elenco di query usato con il modello Navision contiene 3 categorie di query Entity SQL:
11.3.1.1 Ricerca
Query di ricerca semplice senza aggregazioni
- Conteggio: 16232
- Esempio:
<Query complexity="Lookup">
<CommandText>Select value distinct top(4) e.Idle_Time From NavisionFKContext.Session as e</CommandText>
</Query>
11.3.1.2 SingleAggregating
Query bi normale con più aggregazioni, ma nessun subtotale (singola query)
- Conteggio: 2313
- Esempio:
<Query complexity="SingleAggregating">
<CommandText>NavisionFK.MDF_SessionLogin_Time_Max()</CommandText>
</Query>
Dove MDF_SessionLogin_Time_Max() è definito nel modello come:
<Function Name="MDF_SessionLogin_Time_Max" ReturnType="Collection(DateTime)">
<DefiningExpression>SELECT VALUE Edm.Min(E.Login_Time) FROM NavisionFKContext.Session as E</DefiningExpression>
</Function>
11.3.1.3 AggregazioneSubtotals
Query bi con aggregazioni e subtotali (tramite unione tutti)
- Conteggio: 178
- Esempio:
<Query complexity="AggregatingSubtotals">
<CommandText>
using NavisionFK;
function AmountConsumed(entities Collection([CRONUS_International_Ltd__Zone])) as
(
Edm.Sum(select value N.Block_Movement FROM entities as E, E.CRONUS_International_Ltd__Bin as N)
)
function AmountConsumed(P1 Edm.Int32) as
(
AmountConsumed(select value e from NavisionFKContext.CRONUS_International_Ltd__Zone as e where e.Zone_Ranking = P1)
)
----------------------------------------------------------------------------------------------------------------------
(
select top(10) Zone_Ranking, Cross_Dock_Bin_Zone, AmountConsumed(GroupPartition(E))
from NavisionFKContext.CRONUS_International_Ltd__Zone as E
where AmountConsumed(E.Zone_Ranking) > @MinAmountConsumed
group by E.Zone_Ranking, E.Cross_Dock_Bin_Zone
)
union all
(
select top(10) Zone_Ranking, Cast(null as Edm.Byte) as P2, AmountConsumed(GroupPartition(E))
from NavisionFKContext.CRONUS_International_Ltd__Zone as E
where AmountConsumed(E.Zone_Ranking) > @MinAmountConsumed
group by E.Zone_Ranking
)
union all
{
Row(Cast(null as Edm.Int32) as P1, Cast(null as Edm.Byte) as P2, AmountConsumed(select value E
from NavisionFKContext.CRONUS_International_Ltd__Zone as E
where AmountConsumed(E.Zone_Ranking) > @MinAmountConsumed))
}</CommandText>
<Parameters>
<Parameter Name="MinAmountConsumed" DbType="Int32" Value="10000" />
</Parameters>
</Query>