Configurazione dei pool di avvio in Microsoft Fabric
In questo articolo, viene illustrato come personalizzare i pool di avvio in Microsoft Fabric per i carichi di lavoro di analisi. I pool di avvio sono un modo semplice e veloce per usare Spark nella piattaforma Microsoft Fabric in pochi secondi. È possibile usare immediatamente le sessioni Spark invece di attendere che Spark configuri automaticamente i nodi, per cui è possibile eseguire altre operazioni con i dati e ottenere informazioni dettagliate in maniera più rapida.
I pool di avvio hanno cluster Spark sempre attivi e pronti per le richieste. Usano nodi di medie dimensioni e possono essere ridimensionati in base ai requisiti del carico di lavoro.
È possibile specificare il numero massimo di nodi per la scalabilità automatica in base ai requisiti del carico di lavoro di Data Science o Ingegneria dei dati. In base ai nodi massimi configurati, il sistema acquisisce e ritira in modo dinamico i nodi man mano che cambiano i requisiti di calcolo del processo, il che comporta una scalabilità efficiente e prestazioni migliorate.
È anche possibile impostare il limite massimo per gli executor nei pool di avvio e con l'allocazione dinamica abilitata, il sistema adatta il numero di executor a seconda del volume di dati e delle esigenze di calcolo a livello di processo. Questo processo consente di concentrarsi sui carichi di lavoro senza doversi preoccupare dell'ottimizzazione delle prestazioni e della gestione delle risorse.
Nota
Per personalizzare un pool di avvio, è necessario l'accesso da amministratore all'area di lavoro.
Configurare pool di avvio
Per gestire il pool di avvio associato all'area di lavoro:
Andare all'area di lavoro e scegliere le Impostazioni dell'area di lavoro.
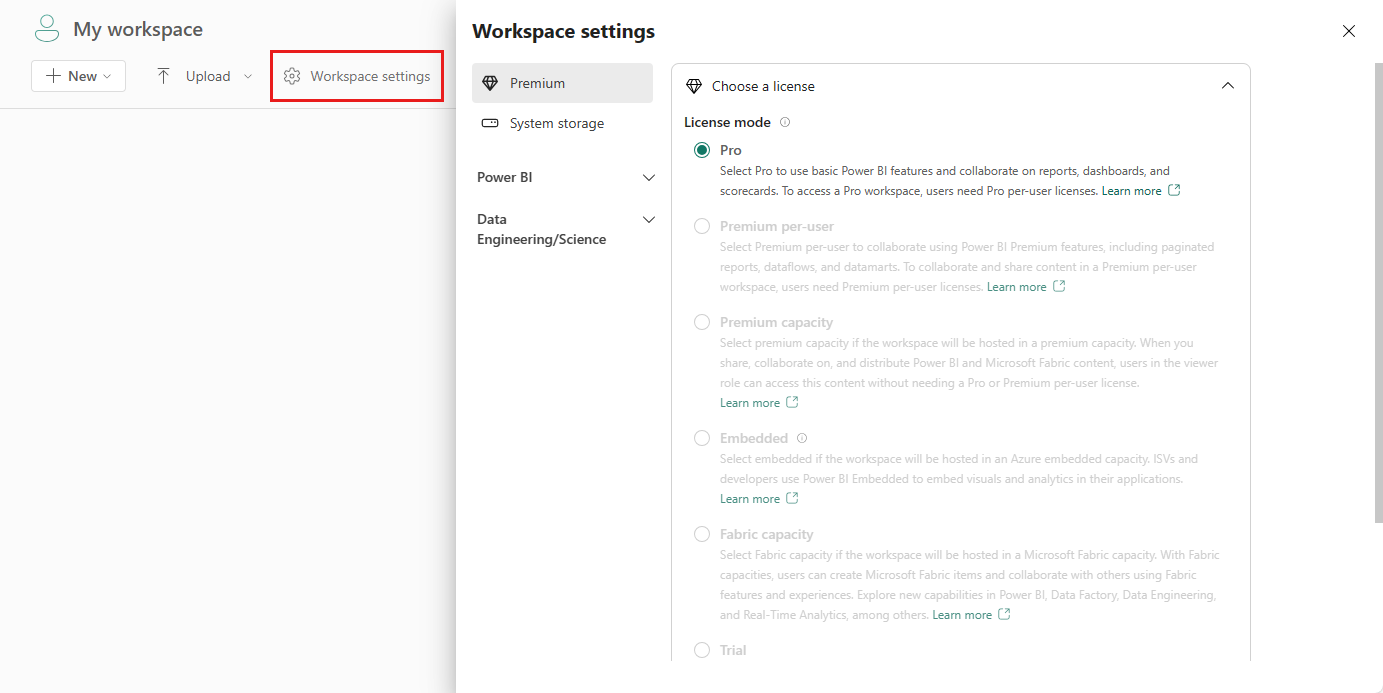
Poi, selezionare l'opzione Ingegneria dei dati/Data Science per espandere il menu.
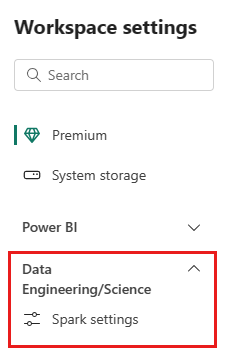
Selezionare l'opzione StarterPool.
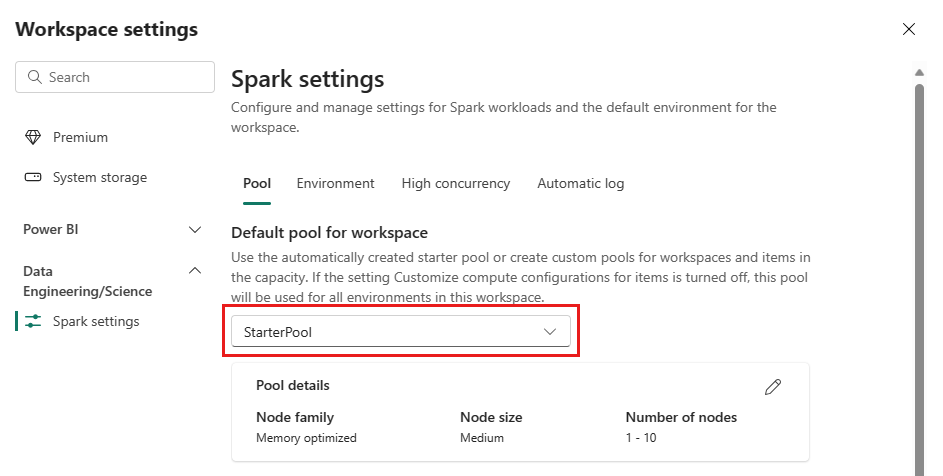
È possibile impostare la configurazione di nodo massimo per i pool di avvio su un numero consentito in base alla capacità acquistata o ridurre la configurazione predefinita del nodo massimo su un valore inferiore quando si eseguono carichi di lavoro più piccoli.
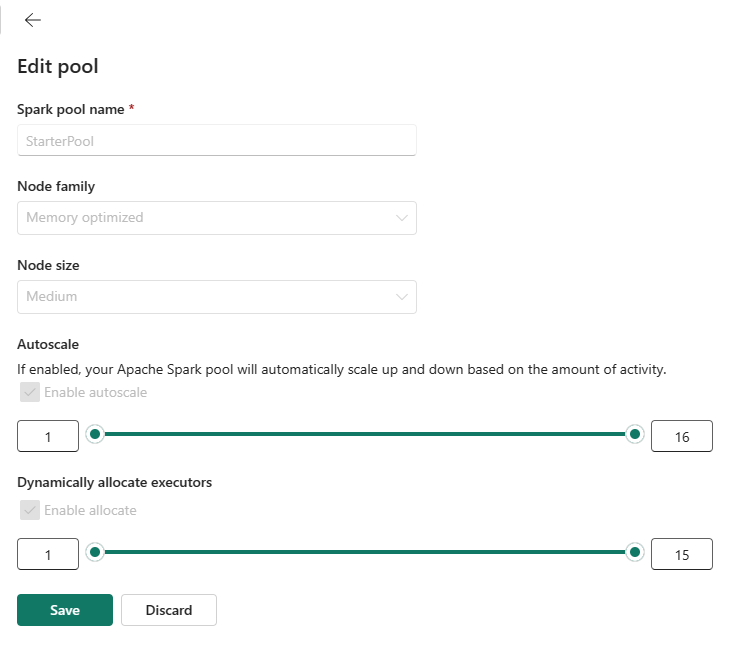

La sezione seguente elenca varie configurazioni predefinite e i limiti del nodo massimo supportati per i pool di avvio in base agli SKU della capacità di Microsoft Fabric:
| Nome SKU | Unità di capacità | VCore di Spark | Dimensioni nodo | Nodi massimi predefiniti | Numero massimo di nodi |
|---|---|---|---|---|---|
| F2 | 2 | 4 | Medio | 1 | 1 |
| F4 | 4 | 8 | Medio | 1 | 1 |
| F8 | 8 | 16 | Medio | 2 | 2 |
| F16 | 16 | 32 | Medio | 3 | 4 |
| F32 | 32 | 64 | Medio | 8 | 8 |
| F64 | 64 | 128 | Medio | 10 | 16 |
| (Capacità della versione di valutazione) | 64 | 128 | Medio | 10 | 16 |
| F128 | 128 | 256 | Medio | 10 | 32 |
| F256 | 256 | 512 | Medio | 10 | 64 |
| F512 | 512 | 1024 | Medio | 10 | 128 |
| F1024 | 1024 | 2048 | Medio | 10 | 200 |
| F2048 | 2048 | 4096 | Medio | 10 | 200 |
Nota
Per personalizzare un pool di avvio, è necessario l'accesso da amministratore all'area di lavoro.
Contenuto correlato
- Per ulteriori informazioni, consultare la documentazione pubblica di Apache Spark.
- Introduzione alle impostazioni di amministrazione dell'area di lavoro di Spark in Microsoft Fabric.