Runtime di Apache Spark in Fabric
Il runtime di Microsoft Fabric è una piattaforma integrata di Azure basata su Apache Spark che consente l'esecuzione e la gestione di esperienze di ingegneria dei dati e data science. Combina componenti chiave di origini interne e open source, offrendo ai clienti una soluzione completa. Per semplicità, si fa riferimento al runtime di Microsoft Fabric basato su Apache Spark come runtime di Fabric.
Principali componenti del runtime di Fabric:
Apache Spark: una potente libreria di elaborazione distribuita open source che consente attività di elaborazione e analisi dei dati su larga scala. Apache Spark offre una piattaforma versatile e ad alte prestazioni per esperienze di ingegneria dei dati e data science.
Delta Lake è un livello di archiviazione open source che porta transazioni ACID e altre funzionalità di affidabilità dei dati in Apache Spark. Integrato all'interno del runtime di Fabric, Delta Lake migliora le funzionalità di elaborazione dei dati e garantisce la coerenza dei dati tra più operazioni simultanee.
Il motore di esecuzione nativo è un miglioramento trasformativo per i carichi di lavoro Apache Spark, offrendo miglioramenti significativi delle prestazioni eseguendo direttamente query Spark nell'infrastruttura lakehouse. Integrato senza problemi, non richiede modifiche al codice ed evita il blocco del fornitore, supportando sia i formati Parquet che Delta nelle API Apache Spark in Runtime 1.3 (Spark 3.5). Questo motore aumenta la velocità delle query fino a quattro volte più veloce rispetto a OSS Spark tradizionale, come illustrato dal benchmark TPC-DS 1TB, riducendo i costi operativi e migliorando l'efficienza in varie attività di dati, tra cui inserimento dati, ETL, analisi e query interattive. Basato su Velox e Apache Gluten di Meta, ottimizza l'uso delle risorse durante la gestione di diversi scenari di elaborazione dei dati.
Pacchetti a livello predefinito per i pacchetti Java/Scala, Python e R che supportano diversi ambienti e linguaggi di programmazione. Questi pacchetti vengono installati e configurati automaticamente, consentendo agli sviluppatori di applicare i propri linguaggi di programmazione preferiti per le attività di elaborazione dati.
Il runtime di Microsoft Fabric è basato su un solido sistema operativo open source, garantendo la compatibilità con varie configurazioni hardware e requisiti di sistema.
Di seguito è riportato un confronto completo dei componenti chiave, tra cui le versioni di Apache Spark, i sistemi operativi supportati, Java, Scala, Python, Delta Lake e R, per i runtime basati su Apache Spark all'interno della piattaforma Microsoft Fabric.
Suggerimento
Usare sempre la versione di runtime ga più recente per il carico di lavoro di produzione, che attualmente è Runtime 1.3.
| Runtime 1.1 | Runtime 1.2 | Runtime 1.3 | |
|---|---|---|---|
| Apache Spark | 3.3.1 | 3.4.1 | 3.5.0 |
| Sistema operativo | Ubuntu 18.04 | Mariner 2.0 | Mariner 2.0 |
| Java | 8 | 11 | 11 |
| Scala | 2.12.15 | 2.12.17 | 2.12.17 |
| Python | 3.10 | 3.10 | 3.11 |
| Delta Lake | 2.2.0 | 2.4.0 | 3.2 |
| R | 4.2.2 | 4.2.2 | 4.4.1 |
Visitare Runtime 1.1, Runtime 1.2 o Runtime 1.3 per esplorare dettagli, nuove funzionalità, miglioramenti e scenari di migrazione per la versione del runtime specifica.
Ottimizzazioni di Fabric
In Microsoft Fabric, sia il motore di Spark che le implementazioni di Delta Lake incorporano ottimizzazioni e funzionalità specifiche della piattaforma. Queste funzionalità sono progettate per l'uso di integrazioni native all'interno della piattaforma. È importante tenere presente che tutte queste funzionalità possono essere disabilitate per ottenere funzionalità di Spark e Delta Lake standard. I runtime di Fabric per Apache Spark includono:
- La versione open source completa di Apache Spark.
- Una raccolta di quasi 100 miglioramenti distingi delle prestazioni delle query predefiniti. Questi miglioramenti includono funzionalità come la memorizzazione nella cache delle partizioni (abilitazione della cache partizioni FileSystem per ridurre le chiamate del metastore) e Cross Join, fino alla proiezione di sottoquery scalare.
- Cache intelligente incorporata.
All'interno del runtime di Fabric per Apache Spark e Delta Lake, sono disponibili funzionalità di scrittura native che assolvono a due scopi principali:
- Offrono prestazioni differenziate per la scrittura di carichi di lavoro, ottimizzando il processo di scrittura.
- Per impostazione predefinita, includono l'ottimizzazione V-Order dei file Delta Parquet. L'ottimizzazione V-Order di Delta Lake è fondamentale per offrire prestazioni di lettura superiori in tutti i motori di Fabric. Per una comprensione più approfondita del funzionamento e delle modalità di gestione, vedere l'articolo dedicato sull'ottimizzazione delle tabelle Delta Lake e V-Order.
Supporto di più runtime
Fabric supporta più runtime, offrendo agli utenti la flessibilità di passare facilmente da uno all'altro, riducendo al minimo il rischio di incompatibilità o interruzioni.
Per impostazione predefinita, tutte le nuove aree di lavoro usano la versione di runtime più recente, attualmente runtime 1.3.
Per modificare la versione di runtime a livello di area di lavoro, vai a Impostazioni area di lavoro>Ingegneria/Scienza dei dati>Impostazioni Spark. Nella scheda Ambiente, selezionare la versione di runtime desiderata dalle opzioni disponibili. Selezionare Salva per confermare la selezione.
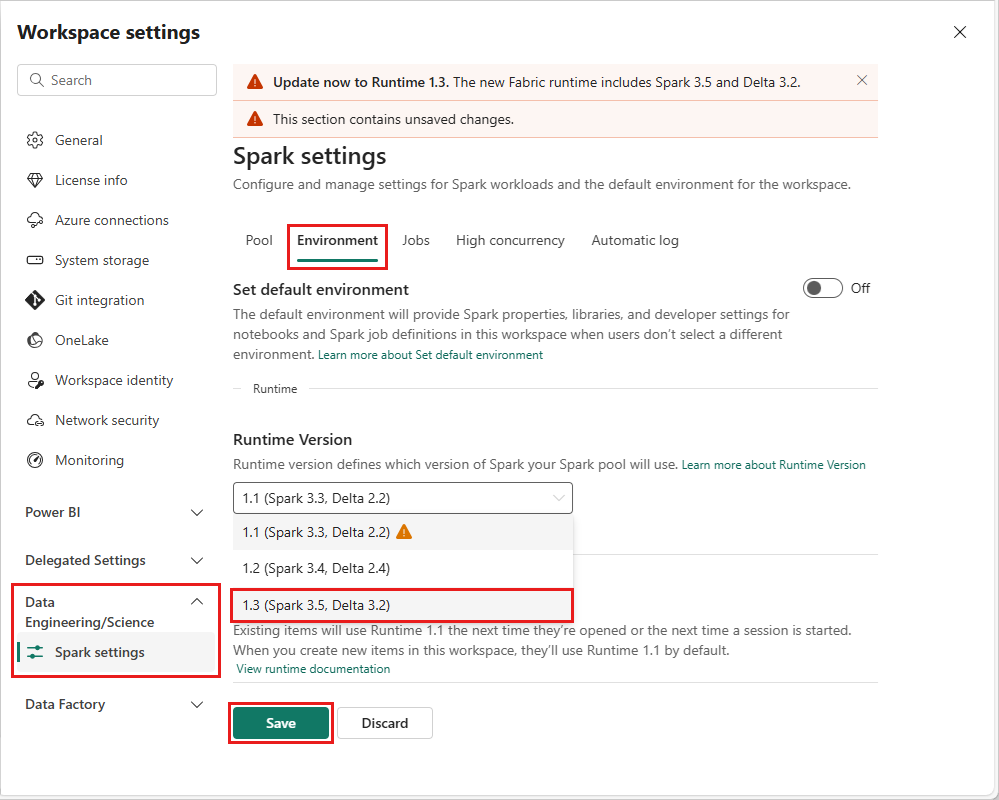
Dopo aver apportato questa modifica, tutti gli elementi creati dal sistema all'interno dell'area di lavoro, inclusi lakehouse, SJD e notebook, funzioneranno usando la versione del runtime a livello di area di lavoro appena selezionata a partire dalla sessione di Spark successiva. Se attualmente si usa un notebook con una sessione esistente per un processo o qualsiasi attività correlata a lakehouse, la sessione di Spark continua senza cambiare. Tuttavia, a partire dalla sessione o dal processo successivo, verrà applicata la versione del runtime selezionata.
Conseguenze delle modifiche del runtime nelle impostazioni di Spark
In generale, si intende eseguire la migrazione di tutte le impostazioni di Spark. Tuttavia, se si identifica che l'impostazione di Spark non è compatibile con il runtime B, viene generato un messaggio di avviso e non si impedisce l'implementazione dell'impostazione.
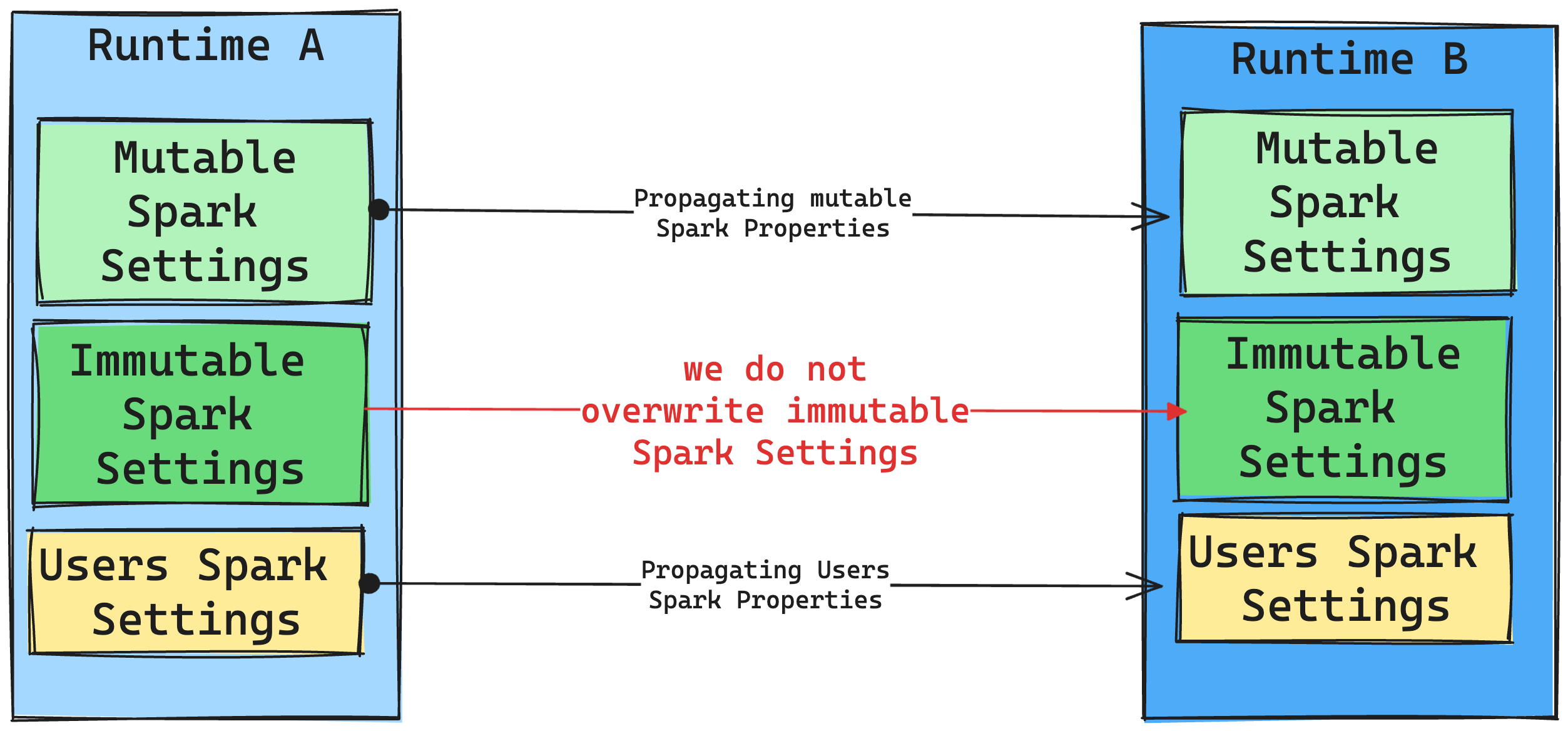
Conseguenze delle modifiche del runtime sulla gestione delle librerie
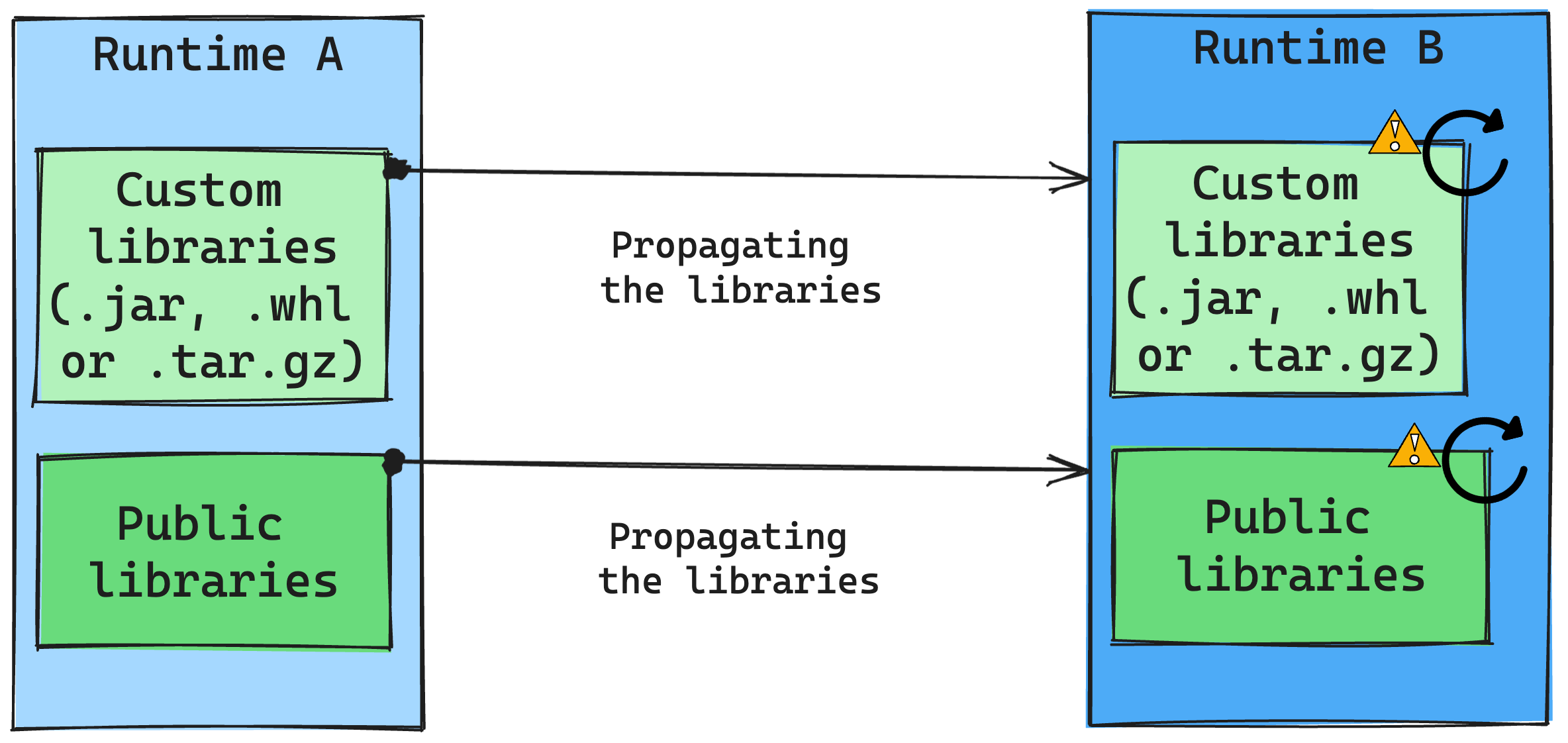
In generale, l'approccio consiste nell’eseguire la migrazione di tutte le librerie dal runtime A al runtime B, inclusi runtime pubblici e personalizzati. Se le versioni di Python e R rimangono invariate, le librerie dovrebbero funzionare correttamente. Per i file JAR, tuttavia, esiste una probabilità significativa che non funzionino a causa di alterazioni nelle dipendenze e altri fattori, ad esempio le modifiche in Scala, Java, Spark e nel sistema operativo.
L'utente è responsabile dell'aggiornamento o della sostituzione di tutte le librerie che non funzionano con il Runtime B. Se si verifica un conflitto, il che implica che il Runtime B include una libreria originariamente nel in Runtime A, il sistema di gestione delle librerie tenterà di creare la dipendenza necessaria per il Runtime B in base alle impostazioni dell'utente. Tuttavia, il processo di compilazione avrà esito negativo se si verifica un conflitto. Nel log degli errori gli utenti possono vedere quali librerie causano conflitti e apportare modifiche alle relative versioni o specifiche.
Aggiornare il protocollo Delta Lake
Le funzionalità Delta Lake sono sempre compatibili con le versioni precedenti, garantendo che le tabelle create in una versione di Delta Lake inferiore possano interagire senza problemi con le versioni successive. Tuttavia, quando determinate funzionalità sono abilitate, ad esempio usando il metodo delta.upgradeTableProtocol(minReaderVersion, minWriterVersion), la compatibilità con versioni di Delta Lake inferiori potrebbe essere compromessa. In questi casi, è essenziale modificare i carichi di lavoro che fanno riferimento alle tabelle aggiornate per allinearsi a una versione di Delta Lake che mantiene la compatibilità.
Ogni tabella Delta è associata a una specifica del protocollo che definisce le funzionalità supportate. Le applicazioni che interagiscono con la tabella, per la lettura o la scrittura, si basano su questa specifica del protocollo per determinare se sono compatibili con il set di funzionalità della tabella. Se un'applicazione non è in grado di gestire una funzionalità elencata come supportata nel protocollo della tabella, non è possibile leggere o scrivere in tale tabella.
La specifica del protocollo è suddivisa in due componenti distinti: il protocollo di lettura e il protocollo di scrittura. Visitare la pagina "In che modo Delta Lake gestisce la compatibilità delle funzionalità?" per leggere i dettagli su di esso.

Gli utenti possono eseguire il comando delta.upgradeTableProtocol(minReaderVersion, minWriterVersion) all'interno dell'ambiente PySpark e in Spark SQL e Scala. Questo comando consente di avviare un aggiornamento nella tabella Delta.
È essenziale tenere presente che quando si esegue l'aggiornamento, gli utenti ricevono un avviso indicante che l'aggiornamento della versione del protocollo Delta è un processo irreversibile. Ciò implica che una volta eseguito, l'aggiornamento non può essere annullato.
Gli aggiornamenti delle versioni del protocollo possono influire sulla compatibilità dei lettori e/o dei writer delle tabelle Delta Lake esistenti. Pertanto, è consigliabile procedere con cautela e aggiornare la versione del protocollo solo quando necessario, ad esempio quando si adottano nuove funzionalità in Delta Lake.
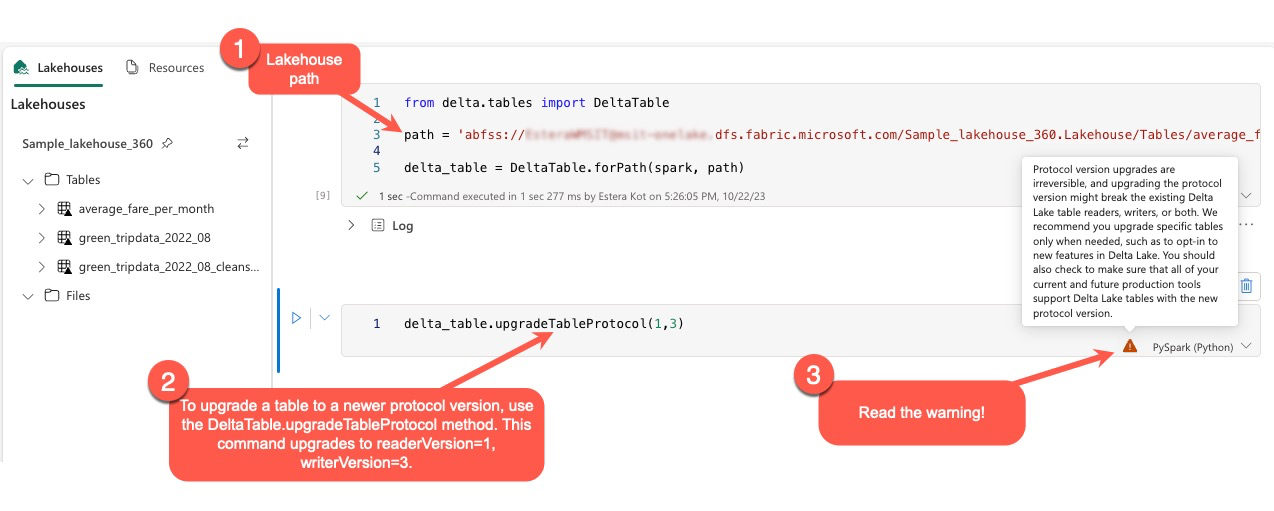
Inoltre, gli utenti devono assicurarsi che tutti i carichi di lavoro e i processi di produzione attuali e futuri siano compatibili con le tabelle Delta Lake con la nuova versione del protocollo, per garantire una transizione senza problemi e prevenire potenziali interruzioni.
Modifiche a Delta 2.2 e Delta 2.4
Nell'ultimo runtime di Fabric, versione 1.3 e nel runtime di Fabric versione 1.2, il formato tabella predefinito (spark.sql.sources.default) ora è delta. Nelle versioni precedenti del runtime versione 1.1 di Fabric e in tutti i runtime di Synapse per Apache Spark contenenti Spark 3.3 o versioni precedenti, il formato tabella predefinito è stato definito parquet. Controllare la tabella con i dettagli di configurazione di Apache Spark per individuare le differenze tra Azure Synapse Analytics e Microsoft Fabric.
Per tutte le tabelle create con Spark SQL, PySpark, Scala Spark e Spark R, ogni volta che il tipo di tabella viene omesso, la tabella verrà creata come delta per impostazione predefinita. Se gli script impostano in modo esplicito il formato tabella, questo verrà rispettato. Il comando USING DELTA nei comandi di creazione tabella Spark diventa ridondante.
Gli script che prevedono o presuppongono un formato tabella Parquet devono essere rivisti. I comandi seguenti non sono supportati nelle tabelle Delta:
ANALYZE TABLE $partitionedTableName PARTITION (p1) COMPUTE STATISTICSALTER TABLE $partitionedTableName ADD PARTITION (p1=3)ALTER TABLE DROP PARTITIONALTER TABLE RECOVER PARTITIONSALTER TABLE SET SERDEPROPERTIESLOAD DATAINSERT OVERWRITE DIRECTORYSHOW CREATE TABLECREATE TABLE LIKE