Configurare in un'attività di Copia della pipeline di dati
Questo articolo illustra come usare l'attività di copia in Azure Data Factory per copiare dati da e in un database Oracle.
Configurazione supportata
Per la configurazione di ogni scheda nell'attività Copy, leggere le rispettive sezioni seguenti.
Generali
Per configurare la scheda di impostazioni Generali, vedere la guida alle impostazioni Generali.
Origine
Le proprietà seguenti sono supportate per Oracle nella scheda Origine di un'attività di copia.

Per ogni oggetto sono necessarie le proprietà seguenti:
- Connessione: selezionare una connessione al database Oracle dall'elenco delle connessioni. Se non esiste alcuna connessione, creare una nuova connessione al database Oracle selezionando Altro nella parte inferiore dell'elenco di connessioni.
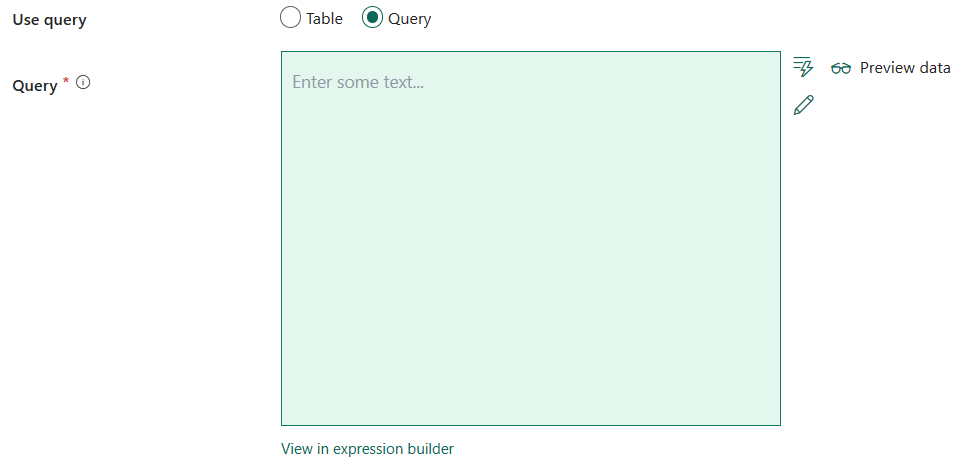
- Usare query: selezionare da tabella o query.
Se si seleziona Tabella:
Tabella: specificare il nome della tabella di destinazione nel database. Selezionare la tabella dall'elenco a discesa oppure selezionare Inserire manualmente per immettere lo schema e il nome della tabella.

Se si seleziona Query:
Query: Specificare la query SQL per leggere i dati. Ad esempio:
SELECT * FROM MyTable.Quando si abilita il carico partizionato, è necessario associare tutti i parametri di partizione predefiniti corrispondenti nella query. Per gli esempi, vedere la sezione Copia parallela da Oracle.
Sotto Avanzate, è possibile specificare i campi seguenti:
Opzioni di partizionamento: Specifica le opzioni di partizionamento dei dati usate per caricare i dati da Oracle. Quando è abilitata un'opzione di partizione (diversa da Nessuno), il grado di parallelismo per il caricamento simultaneo di dati da un database Oracle è controllato dal valore Grado di parallelismo di copia presente nella scheda delle impostazioni dell'attività di copia.
Se si seleziona Nessuno, si sceglie di non usare la partizione.
Se si seleziona Partizioni fisiche della tabella:
Nomi partizione: specifica l’elenco di partizioni fisiche da copiare.
Se si usa una query per recuperare i dati di origine, associare
?DfTabularPartitionNamenella clausola WHERE. Per un esempio, vedere la sezione Copia parallela da Oracle.
Se si seleziona Intervallo dinamico:
Nome colonna partizione: specifica il nome della colonna di origine nel tipo Integer che verrà usata dal partizionamento dell'intervallo per la copia parallela. Se non specificato, la chiave primaria della tabella viene rilevata automaticamente e usata come colonna di partizione.
Se si usa una query per recuperare i dati di origine, associare
?DfRangePartitionColumnNamenella clausola WHERE. Per un esempio, vedere la sezione Copia parallela da Oracle.Limite superiore della partizione: specificare il valore massimo della colonna della partizione per copiare i dati.
Se si usa una query per recuperare i dati di origine, associare
?DfRangePartitionUpboundnella clausola WHERE. Per un esempio, vedere la sezione Copia parallela da Oracle.Limite inferiore della partizione: specifica il valore minimo della colonna di partizione da cui copiare i dati.
Se si usa una query per recuperare i dati di origine, associare
?DfRangePartitionLowboundnella clausola WHERE. Per un esempio, vedere la sezione Copia parallela da Oracle.
Timeout query (minuti): specifica il timeout per l'esecuzione del comando di query, il valore predefinito è 120 minuti. Se per questa proprietà è impostato un parametro, i valori consentiti sono intervalli di tempo, ad esempio "02:00:00" (120 minuti).
Colonne aggiuntive: aggiungere altre colonne di dati per archiviare il percorso relativo o il valore statico dei file di origine. L'espressione è supportata per la seconda opzione.


Destinazione
Le proprietà seguenti sono supportate per Oracle nella scheda Destinazione di un'attività di copia.

Per ogni oggetto sono necessarie le proprietà seguenti:
- Connessione: selezionare una connessione al database Oracle dall'elenco delle connessioni. Se la connessione non esiste, creare una nuova connessione al database Oracle selezionando Altro nella parte inferiore dell'elenco di connessioni.
- Tabella: selezionare la tabella nel database dall'elenco a discesa. In alternativa, selezionare Immettere manualmente per immettere lo schema e il nome della tabella.
Sotto Avanzate, è possibile specificare i campi seguenti:
- Script della pre-copia: Specificare una query SQL per l'attività Copy da eseguire prima di scrivere i dati in Database di Azure per PostgreSQL in ogni esecuzione. È possibile usare questa proprietà per pulire i dati precaricati.
- Timeout del batch di scrittura: il tempo di attesa per il completamento dell'operazione di inserimento batch prima del timeout. Il valore consentito è timespan. Ad esempio "00:30:00" (30 minuti).
- Dimensioni batch di scrittura: specificare il numero di righe da inserire nella tabella di database Oracle per batch. Il valore consentito è integer (numero di righe). Il valore predefinito è 10.000.
- Connessioni massime simultanee: il limite massimo di connessioni simultanee stabilite all'archivio dati durante l'esecuzione dell'attività. Specificare un valore solo quando si desidera limitare le connessioni simultanee.
Mapping
Per la configurazione della scheda Mapping, accedere a Configurare i mapping nella scheda Mapping.
Impostazione
Per la configurazione della scheda Impostazioni, vedere Configurare le altre impostazioni nella scheda Impostazioni.
Copia parallela da Oracle
Il connettore Oracle fornisce il partizionamento dei dati predefinito per copiare dati da Oracle in parallelo. È possibile trovare le opzioni di partizionamento dei dati nella tabella Origine dell'attività Copy.
Quando si abilita la copia partizionata, il servizio esegue query parallele sull'origine Oracle per caricare i dati in base alle partizioni. Il grado di parallelismo è controllato dall'impostazione Grado di parallelismo della copia nella scheda Impostazioni attività di copia. Ad esempio, se si imposta il grado di parallelismo della copia su quattro, il servizio genera ed esegue simultaneamente quattro query basate sull'opzione di partizione e sulle impostazioni specificate e ogni query recupera una parte dei dati dal database Oracle.
È consigliabile abilitare la copia parallela con il partizionamento dei dati, soprattutto quando si caricano grandi quantità di dati dal database Oracle. Di seguito sono riportate le configurazioni consigliate per i diversi scenari. Quando si copiano dati in un archivio dati basato su file, è consigliabile scrivere in una cartella come file multipli (specificare solo il nome della cartella); in tal caso, le prestazioni risultano migliori rispetto alla scrittura in un singolo file.
| Scenario | Impostazioni consigliate |
|---|---|
| Caricamento completo da una tabella di grandi dimensioni, con partizioni fisiche. | Opzione di partizione: partizioni fisiche della tabella. Durante l'esecuzione, il servizio rileva automaticamente le partizioni fisiche e copia i dati in base alle partizioni. |
| Caricamento completo da una tabella di grandi dimensioni, senza partizioni fisiche, con una colonna di numeri interi per il partizionamento dei dati. | Opzioni di partizione: partizione a intervalli dinamici. Colonna di partizione: specificare la colonna usata per il partizionamento dei dati. Se non è specificato, viene usata la colonna della chiave primaria. |
| Caricare una grande quantità di dati usando una query personalizzata, con partizioni fisiche. | Opzione di partizione: partizioni fisiche della tabella. Query: SELECT * FROM <TABLENAME> PARTITION("?DfTabularPartitionName") WHERE <your_additional_where_clause>. Nome partizione: specificare i nomi della partizione da cui copiare i dati. Se non specificato, il servizio rileva automaticamente le partizioni fisiche nella tabella specificata nel set di dati Oracle. Durante l'esecuzione, il servizio sostituisce ?DfTabularPartitionName con il nome effettivo della partizione e lo invia a Oracle. |
| Caricare una grande quantità di dati usando una query personalizzata, senza partizioni fisiche, con una colonna di numeri interi per il partizionamento dei dati. | Opzioni di partizione: partizione a intervalli dinamici. Query: SELECT * FROM <TABLENAME> WHERE ?DfRangePartitionColumnName <= ?DfRangePartitionUpbound AND ?DfRangePartitionColumnName >= ?DfRangePartitionLowbound AND <your_additional_where_clause>.Colonna di partizione: specificare la colonna usata per il partizionamento dei dati. È possibile partizionare la colonna con il tipo di dati Integer. Limite superiore della partizione e limite inferiore della partizione: specificare se si desidera filtrare in base alla colonna di partizione per recuperare i dati solo tra l'intervallo inferiore e quello superiore. Durante l'esecuzione, il servizio sostituisce ?DfRangePartitionColumnName, ?DfRangePartitionUpbounde ?DfRangePartitionLowbound con il nome della colonna e gli intervalli di valori effettivi per ogni partizione e li invia a Oracle. Ad esempio, se la colonna di partizione "ID" è impostata con il limite inferiore su 1 e il limite superiore su 80 e la copia parallela su 4, il servizio recupera i dati da 4 partizioni. Gli ID sono rispettivamente compresi tra [1, 20], [21, 40], [41, 60] e [61, 80]. |
Suggerimento
Quando si copiano dati da una tabella non partizionata, è possibile usare l'opzione di partizione "Intervallo dinamico" per eseguire il partizionamento su una colonna integer. Se i dati di origine non hanno tale tipo di colonna, è possibile sfruttare la funzione ORA_HASH nella query di origine per generare una colonna e usarla come colonna di partizione.
Tabella di riepilogo
Le tabelle seguenti contengono altre informazioni sull'attività di copia nel database Oracle.
Informazioni sull'origine
| Nome | Descrizione | valore | Richiesto | Proprietà script JSON |
|---|---|---|---|---|
| Connessione | Connessione all'archivio dei dati di origine. | <connessione al database Oracle> | Sì | connection |
| Usa query | Modalità di lettura dei dati dal database Oracle. Applicare la tabella per leggere i dati dalla tabella specificata o applicare Query per leggere i dati usando query SQL. | • Tabella • Query |
Sì | / |
| Per le tabelle | ||||
| Nome schema | Nome dello schema. | < nome dello schema > | No | schema |
| Nome tabella | Nome della tabella. | < nome alla tua tabella > | No | table |
| Per Query | ||||
| Query | Usare la query SQL personalizzata per leggere i dati. Un esempio è SELECT * FROM MyTable. Quando si abilita il carico partizionato, è necessario associare tutti i parametri di partizione predefiniti corrispondenti nella query. Per gli esempi, vedere la sezione Copia parallela da Oracle. |
< Query SQL > | No | oracleReaderQuery |
| Opzione partizione | Specifica le opzioni di partizionamento dei dati usate per caricare i dati da Oracle. | • Nessuno (impostazione predefinita) • Partizioni fisiche della tabella • Intervallo dinamico |
No | / |
| Per le Partizioni fisiche della tabella | ||||
| Nomi della partizione | Elenco di partizioni fisiche da copiare. Se si usa una query per recuperare i dati di origine, associare ?DfTabularPartitionName nella clausola WHERE. |
< Nomi della partizione > | No | partitionNames |
| Per l’Intervallo dinamico | ||||
| Nome colonna di partizione | Specifica il nome della colonna di origine nel tipo Integer che verrà usata dal partizionamento dell'intervallo per la copia parallela. Se non specificato, la chiave primaria della tabella viene rilevata automaticamente e usata come colonna di partizione. Se si usa una query per recuperare i dati di origine, associare ?DfRangePartitionColumnName nella clausola WHERE. Per un esempio, vedere la sezione Copia parallela da Oracle. |
< nomi delle colonne di partizione > | No | partitionColumnName |
| Limite superiore della partizione | Specificare il valore massimo della colonna della partizione per copiare i dati. Se si usa una query per recuperare i dati di origine, eseguire l'hook ?DfRangePartitionUpbound nella clausola WHERE. Per un esempio, vedere la sezione Copia parallela da Oracle. |
< limite superiore della partizione > | No | partitionUpperBound |
| Limite inferiore della partizione | Specificare il valore minimo della colonna di partizione per copiare i dati. Se si usa una query per recuperare i dati di origine, eseguire l'hook ?DfRangePartitionLowbound nella clausola WHERE. Per un esempio, vedere la sezione Copia parallela da Oracle. |
< limite inferiore della partizione > | No | partitionLowerBound |
| Timeout query | Il timeout per l'esecuzione del comando di query, il valore predefinito è 120 minuti. | timespan | No | queryTimeout |
| Colonne aggiuntive | Aggiungere altre colonne di dati per archiviare il percorso relativo o il valore statico dei file di origine. L'espressione è supportata per la seconda opzione. | • Name • Valore |
No | additionalColumns: • name • value |
Informazioni sulla destinazione
| Nome | Descrizione | valore | Richiesto | Proprietà script JSON |
|---|---|---|---|---|
| Connessione | Connessione all'archivio dati di destinazione. | <connessione al database Oracle> | Sì | connection |
| Tabella | Tabella dei dati di destinazione. | <nome della tabella di destinazione> | Sì | / |
| Nome schema | Nome dello schema. | < nome dello schema > | Sì | schema |
| Nome tabella | Nome della tabella. | < nome alla tua tabella > | Sì | table |
| Script di pre-copia | Specificare una query SQL per l'attività Copy da eseguire prima di scrivere i dati in Database di Azure per PostgreSQL in ogni esecuzione. È possibile usare questa proprietà per pulire i dati precaricati. | < script di pre-copia > | No | preCopyScript |
| Timeout del batch di scrittura | Tempo di attesa per l'operazione di inserimento batch da completare prima del timeout. | timespan | No | writeBatchTimeout |
| Dimensioni batch di scrittura | Il numero di righe da inserire nella tabella SQL per batch. | integer (il valore predefinito è 10.000) |
No | writeBatchSize |
| Numero massimo di connessioni simultanee | Limite massimo di connessioni simultanee stabilite all'archivio dati durante l'esecuzione dell'attività. Specificare un valore solo quando si desidera limitare le connessioni simultanee. | < numero massimo di connessioni simultanee > | No | maxConcurrentConnections |