Copia rapida in Dataflows Gen2
Questo articolo descrive la funzionalità di copia rapida in Dataflows Gen2 per Data Factory in Microsoft Fabric. I flussi di dati consentono di inserire e trasformare i dati. Con l'introduzione della scalabilità orizzontale del flusso di dati con il calcolo SQL DW, è possibile trasformare i dati su larga scala. Tuttavia, i dati devono prima essere inseriti. Con l'introduzione della copia rapida, è possibile inserire terabyte di dati con l'esperienza semplice dei flussi di dati, ma con il back-end scalabile dell'attività Copy della pipeline.
Dopo aver abilitato questa funzionalità, i flussi di dati cambiano automaticamente il back-end quando le dimensioni dei dati superano una determinata soglia, senza dover modificare alcun elemento durante la creazione dei flussi di dati. Dopo l'aggiornamento di un flusso di dati, è possibile controllare la cronologia degli aggiornamenti per verificare se è stata usata una copia rapida durante l'esecuzione esaminando il tipo di motore visualizzato.
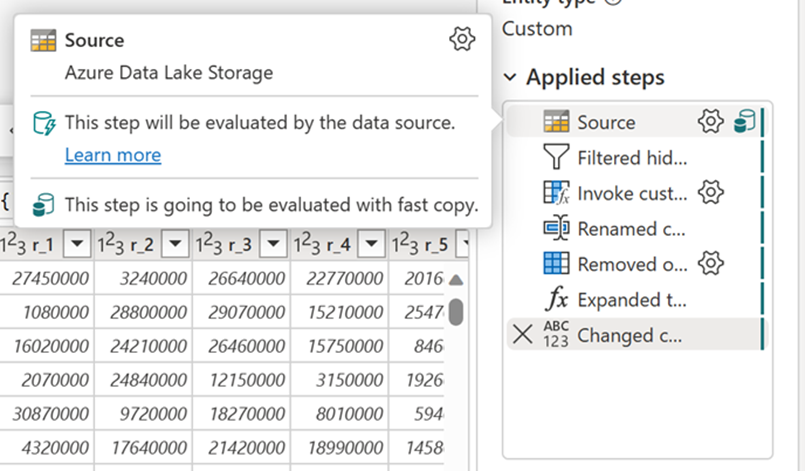
Con l'opzione Richiedi copia rapida abilitata, l'aggiornamento del flusso di dati viene annullato se non viene usata la copia rapida. Ciò consente di evitare di attendere che un timeout di aggiornamento continui. Questo comportamento può essere utile anche in una sessione di debug per testare il comportamento del flusso di dati con i dati riducendo il tempo di attesa. Usando gli indicatori di copia rapida nel riquadro dei passaggi della query, è possibile verificare facilmente se la query può essere eseguita con una copia rapida.
Prerequisiti
- È necessario avere una capacità Fabric.
- Per i dati dei file, i file sono in formato .csv o parquet di almeno 100 MB e archiviati in un account di archiviazione Azure Data Lake Storage (ADLS) Gen2 o Blob.
- Per il database, inclusi il database SQL di Azure e PostgreSQL, 5 milioni di righe o più di dati nell'origine dati.
Nota
È possibile ignorare la soglia per forzare la copia rapida selezionando l'impostazione "Richiedi copia rapida".
Supporto dei connettori
La copia rapida è attualmente supportata per i connettori Dataflow Gen2 seguenti:
- ADLS Gen2
- Archiviazione BLOB
- DB di Azure SQL
- Lakehouse
- PostgreSQL
- Server SQL in locale
- Magazzino
- Oracle
- Snowflake
L'attività Copy supporta solo alcune trasformazioni durante la connessione a un'origine file:
- Combina file
- Seleziona colonne
- Modificare i tipi di dati
- Rinominare una colonna
- Rimuovere una colonna
È comunque possibile applicare altre trasformazioni suddividendo i passaggi di inserimento e trasformazione in query separate. La prima query recupera effettivamente i dati e la seconda query fa riferimento ai risultati in modo che sia possibile usare il calcolo DW. Per le origini SQL, è supportata qualsiasi trasformazione che fa parte della query nativa.
Quando si carica direttamente la query in una destinazione di output, attualmente sono supportate solo le destinazioni Lakehouse. Se si vuole usare un'altra destinazione di output, è possibile preparare prima la query e farvi riferimento in un secondo momento.
Come usare la copia rapida
Passare all'endpoint di Fabric appropriato.
Passare a un'area di lavoro Premium e creare un dataflow Gen2.
Nella scheda Home del nuovo flusso di dati selezionare Opzioni:
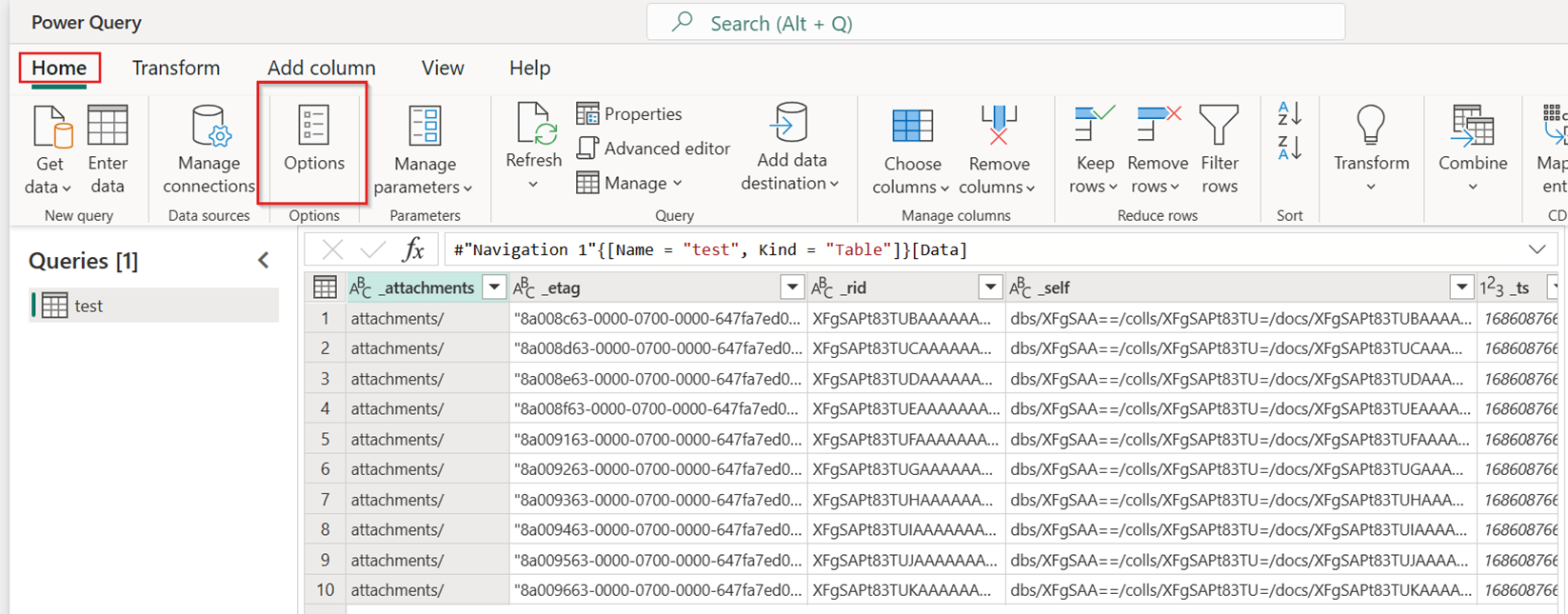
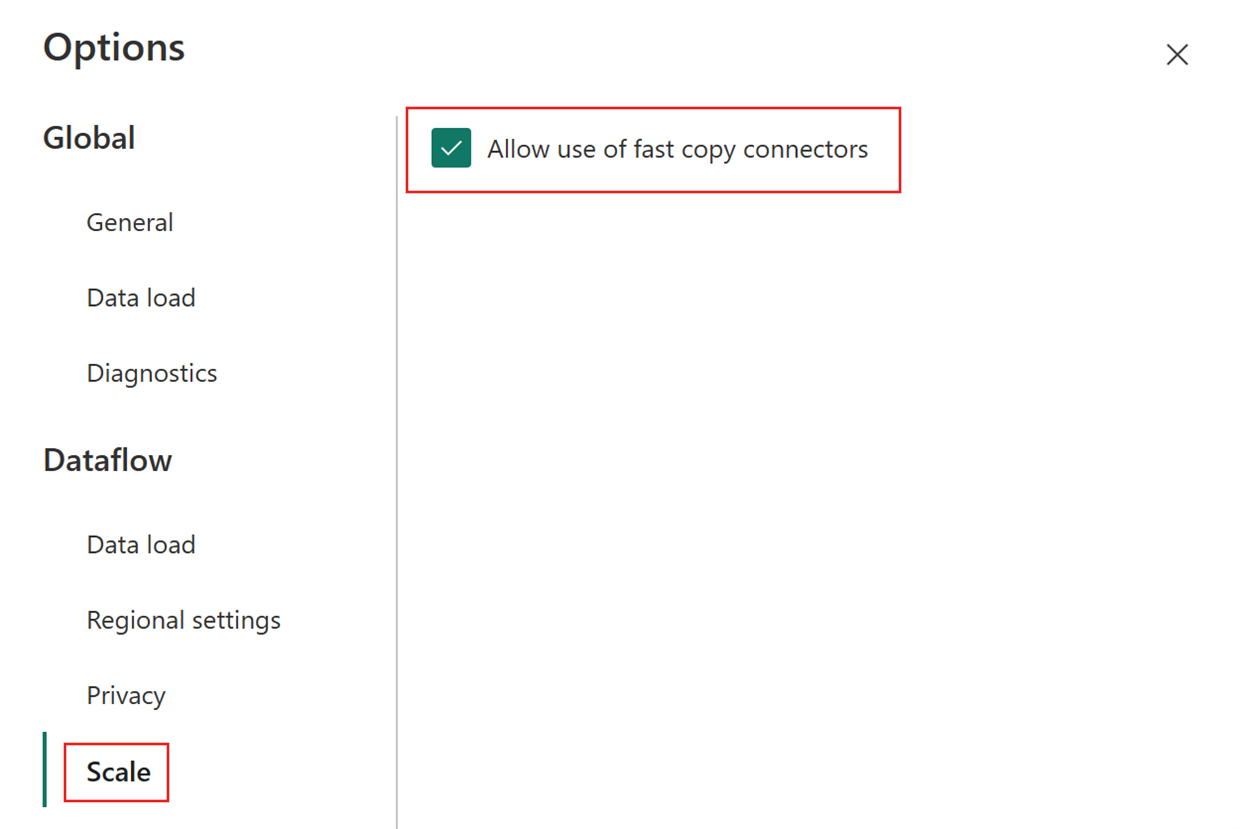
Scegliere quindi la scheda Scala nella finestra di dialogo Opzioni e selezionare la casella di controllo Consenti l'uso di connettori di copia rapida per attivare la copia rapida. Chiudere quindi la finestra di dialogo Opzioni.
Selezionare Recupera dati e quindi scegliere l'origine ADLS Gen2 e immettere i dettagli per il contenitore.
Usare la funzionalità Combina file.

Per garantire la copia rapida, applicare solo le trasformazioni elencate nella sezione Supporto del connettore di questo articolo. Se è necessario applicare altre trasformazioni, preparare prima i dati e fare riferimento alla query in un secondo momento. Eseguire altre trasformazioni nella query a cui si fa riferimento.
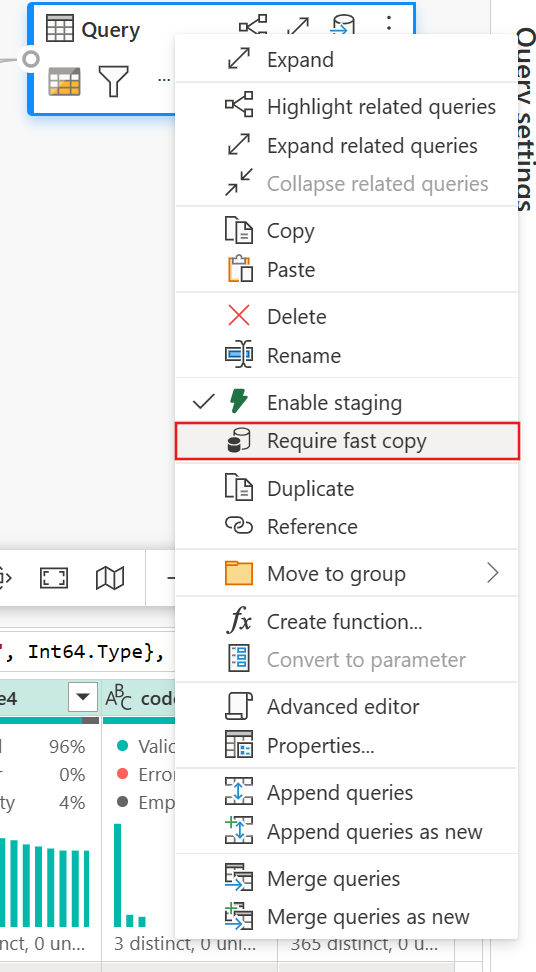
(Facoltativo) È possibile impostare l'opzione Richiedi copia rapida per la query facendo clic con il pulsante destro del mouse su di essa per selezionare e abilitare tale opzione.
(Facoltativo) Attualmente, è possibile configurare una Lakehouse solo come destinazione di output. Per qualsiasi altra destinazione, preparare la query e farvi riferimento in un secondo momento in un'altra query in cui è possibile eseguire l'output in qualsiasi origine.
Controllare gli indicatori di copia rapida per verificare se la query può essere eseguita con una copia rapida. In tal caso, il tipo di motore mostra CopyActivity.

Pubblicare il flusso di dati.
Controllare dopo il completamento dell'aggiornamento per confermare che è stata usata la copia rapida.

Come suddividere la query per sfruttare la copia rapida
Per prestazioni ottimali durante l'elaborazione di grandi volumi di dati con Dataflow Gen2, utilizzare la funzionalità di copia rapida per prima caricare i dati nella fase di staging, quindi trasformarli su larga scala con l'elaborazione SQL DW. Questo approccio migliora significativamente le prestazioni end-to-end.
Per implementare questo, gli indicatori di copia rapida possono guidarti a suddividere la query in due parti: ingestione dei dati nello staging e trasformazione su larga scala con il calcolo SQL DW. È consigliabile trasferire quanto più possibile della valutazione di una query a Fast Copy che può essere usato per l'ingestione dei dati. Quando gli indicatori di Fast Copy mostrano che i passaggi rimanenti non possono essere eseguiti da Fast Copy, è possibile suddividere il resto della query con l'abilitazione della gestione temporanea.
Indicatori di diagnostica delle fasi
| Indicatore | Icona | Descrizione |
|---|---|---|
| Questo passaggio verrà valutato con la copia rapida | 
|
L'indicatore di Copia rapida indica che la query supporta la copia rapida fino a questo passaggio. |
| Questo passaggio non è supportato dalla copia rapida | 
|
L'indicatore Copia rapida mostra che questo passaggio non supporta La copia rapida. |
| Uno o più passaggi nella tua query non sono supportati da una query rapida | 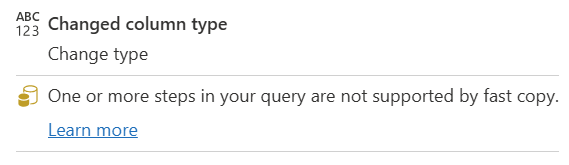
|
L'indicatore Copia rapida mostra che alcuni passaggi di questa query supportano La copia rapida, mentre altri non lo sono. Per ottimizzare, si consiglia di dividere la query: i passaggi gialli (potenzialmente supportati da Copia rapida) e i passaggi rossi (non supportati). |
Linee guida dettagliate
Dopo aver completato la logica di trasformazione dei dati in Dataflow Gen2, l'indicatore Di copia rapida valuta ogni passaggio per determinare il numero di passaggi che possono sfruttare La copia rapida per ottenere prestazioni migliori.
Nell'esempio seguente l'ultimo passaggio mostra il rosso, a indicare che il passaggio con Group By non è supportato da Copia rapida. Tuttavia, tutti i passaggi precedenti evidenziati in giallo possono essere potenzialmente supportati da Fast Copy.
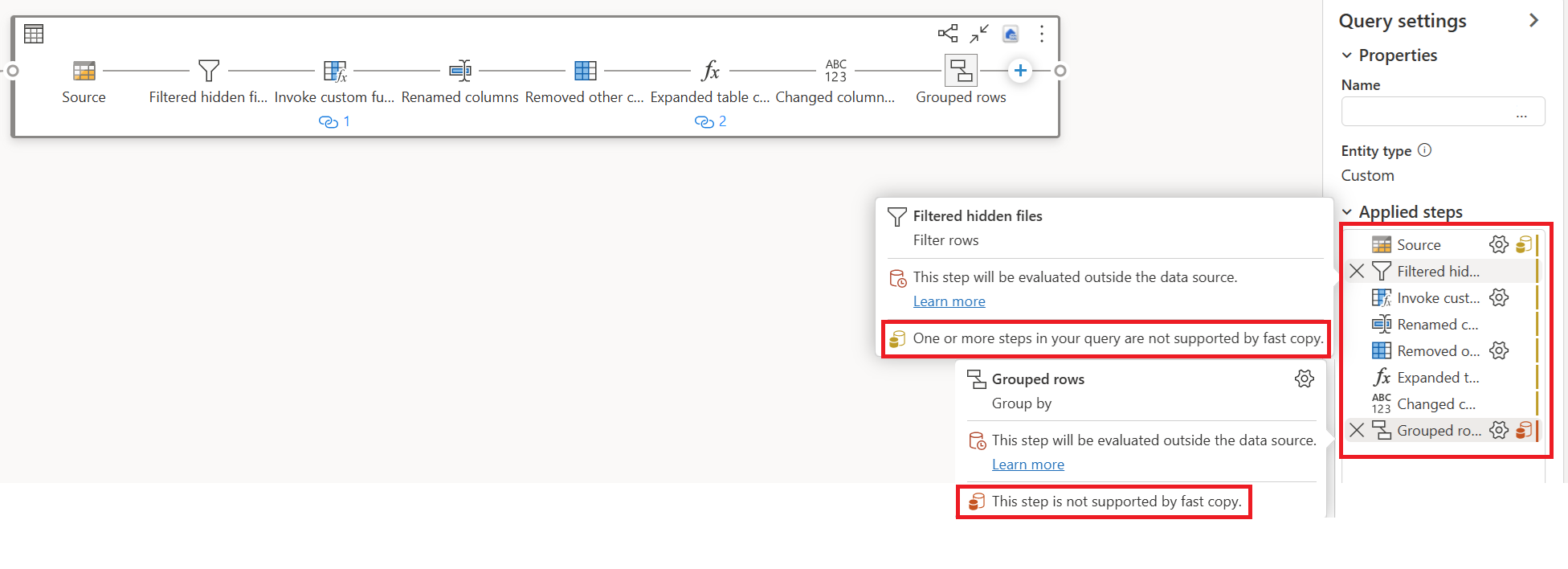
In questo momento, se si pubblica e si esegue direttamente Dataflow Gen2, non userà il motore di copia rapida per caricare i dati come illustrato di seguito:
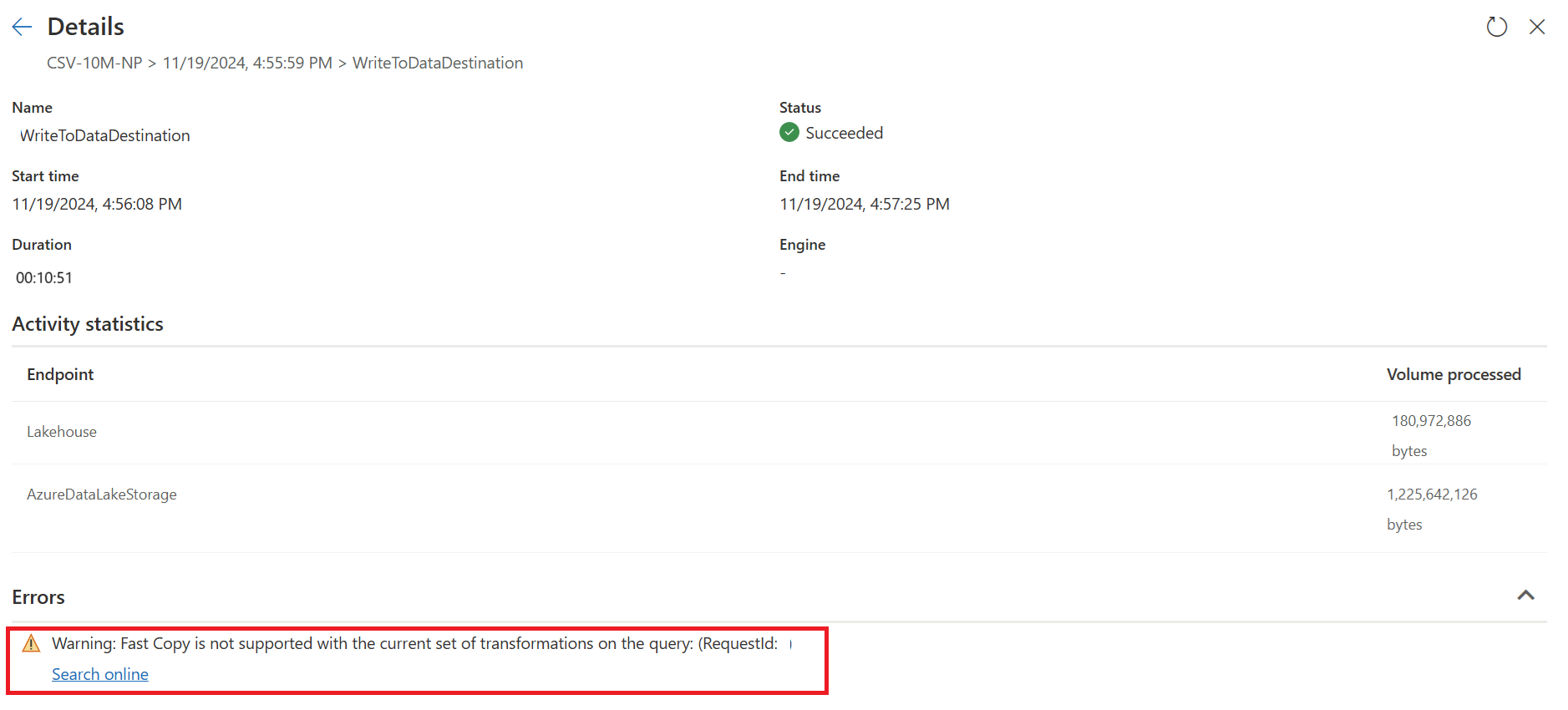
Per usare il motore di copia rapida e migliorare le prestazioni di "Dataflow Gen2", può suddividere la query in due parti: l'inserimento dei dati nell'area di staging e la trasformazione su larga scala con l'utilizzo del calcolo SQL DW, come indicato di seguito.
Rimuovere le trasformazioni (che mostrano il rosso) che non sono supportate da Copia rapida, insieme alla destinazione (se definita).
L'indicatore Copia Rapida ora mostra il verde per i passaggi rimanenti, ciò significa che la prima query può sfruttare Copia Rapida per ottenere prestazioni migliori.
Selezionare Azione per la prima query, quindi scegliere Abilita gestione temporanea e riferimento.
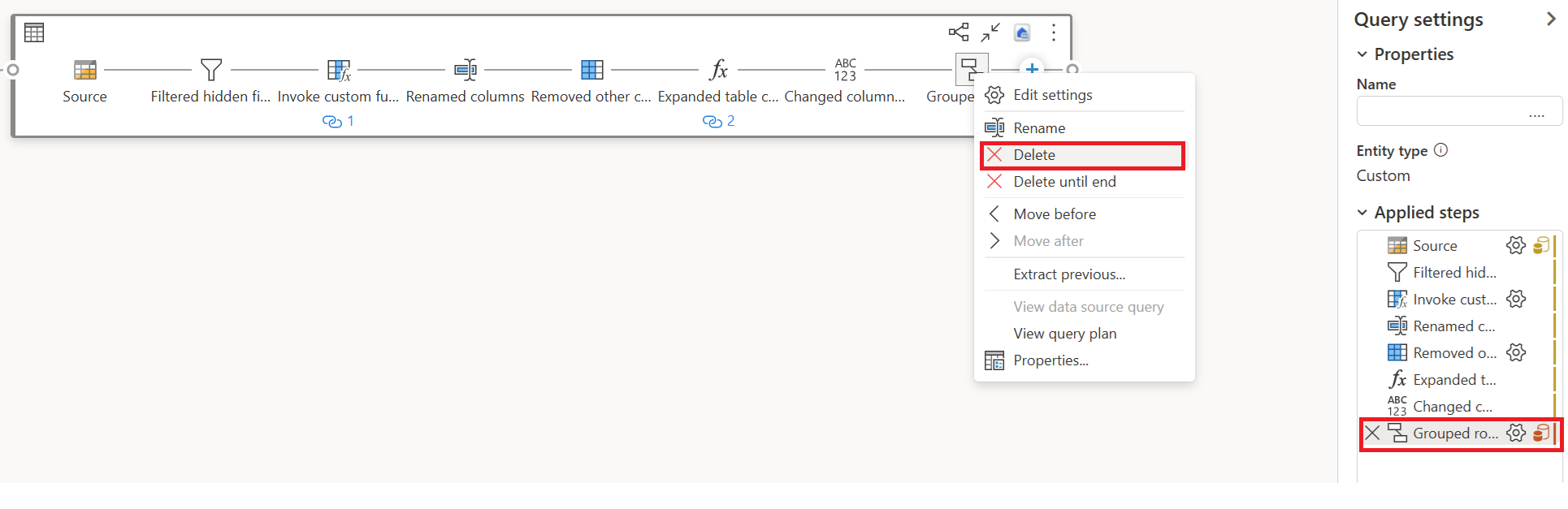
In una nuova query a cui viene fatto riferimento, è stata letta la trasformazione "Raggruppa per" e la destinazione (se applicabile).
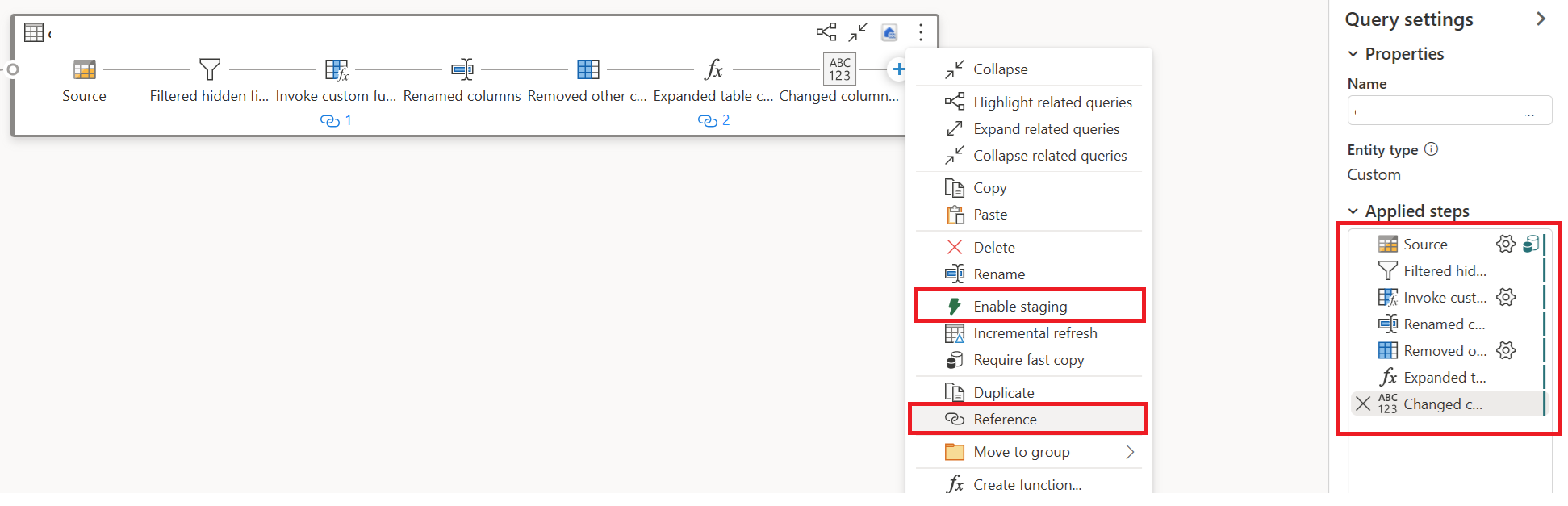
Pubblica e aggiorna il tuo Dataflow Gen2. Verranno ora visualizzate due query in Dataflow Gen2 e la durata complessiva è notevolmente ridotta.
La prima query inserisce i dati nell'area di staging utilizzando Fast Copy.
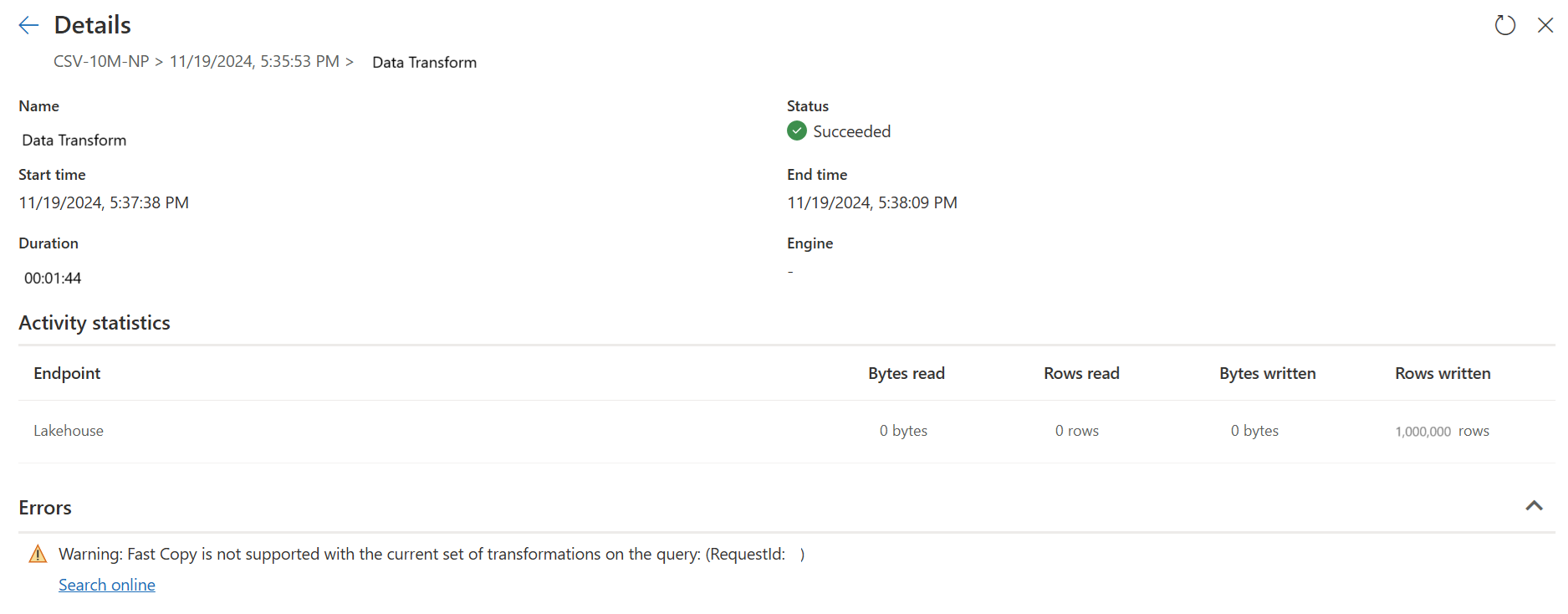
La seconda query esegue trasformazioni su larga scala usando il calcolo SQL DW.
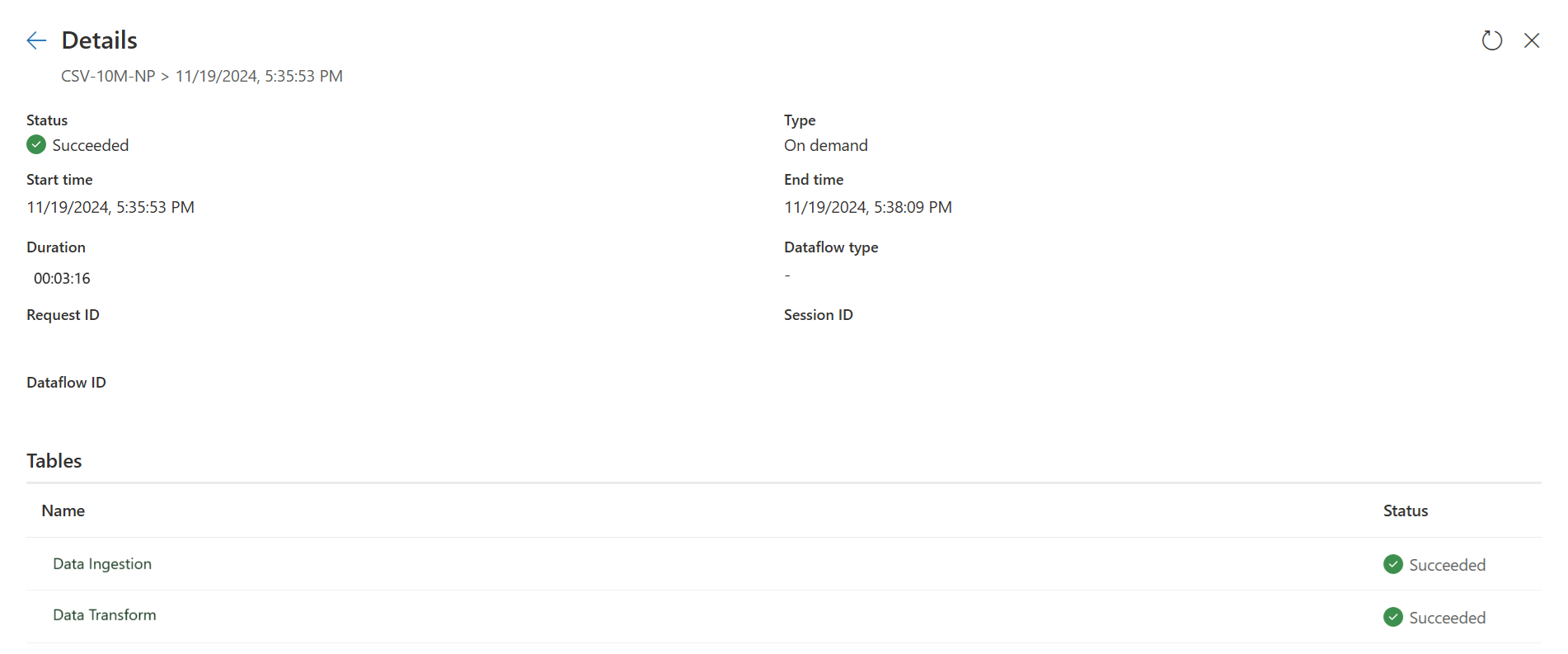
Prima query:
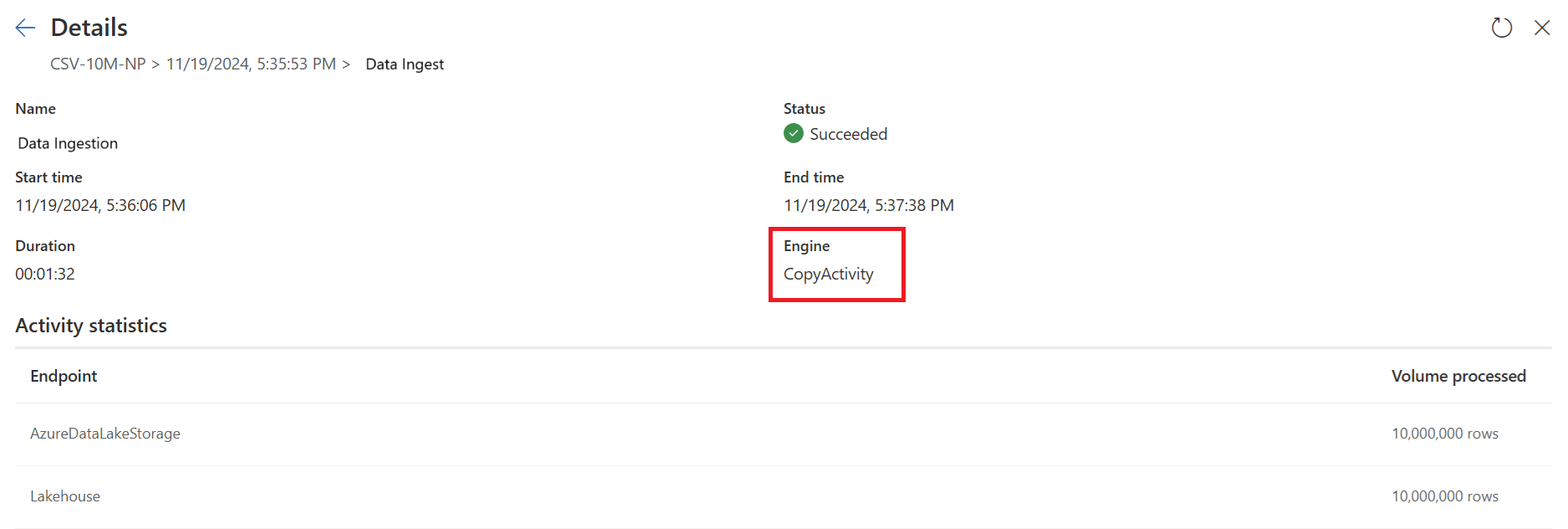
La seconda query:
Limitazioni note
- Per supportare Fast Copy è necessario un gateway dati locale versione 3000.214.2 o successiva.
- Il gateway VNet non è supportato.
- La scrittura di dati in una tabella esistente in Lakehouse non è supportata.
- Lo schema fisso non è supportato.