Assegnazione dei punteggi ai modelli di apprendimento automatico con PREDICT in Microsoft Fabric
Microsoft Fabric consente agli utenti di rendere operativi i modelli di Machine Learning con la funzione PREDICT scalabile. Questa funzione supporta l'assegnazione dei punteggi batch in qualsiasi motore di calcolo. Gli utenti possono generare stime batch direttamente da un notebook di Microsoft Fabric o dalla pagina dell'elemento di un determinato modello di Machine Learning.
In questo articolo si apprenderà come applicare PREDICT scrivendo codice manualmente o usando un'esperienza guidata dell'interfaccia utente che gestisce automaticamente l'assegnazione dei punteggi batch.
Prerequisiti
Ottenere una sottoscrizione di Microsoft Fabric. In alternativa, iscriversi per ottenere una versione di valutazione di Microsoft Fabric gratuita.
Accedere a Microsoft Fabric.
Usare l’opzione esperienza sul lato sinistro della home page per passare all'esperienza Science di Synapse.

Limiti
- La funzione PREDICT è attualmente supportata per questo set limitato di versioni del modello di Machine Learning:
- CatBoost
- Keras
- LightGBM
- ONNX
- Prophet
- PyTorch
- Sklearn
- Spark
- Statsmodels
- TensorFlow
- XGBoost
- PREDICT richiede di salvare i modelli di Machine Learning nel formato MLflow, con le relative firme popolate
- PREDICT non supporta i modelli di Machine Learning con input o output multi-tensor
Chiamare PREDICT da un notebook
PREDICT supporta i modelli in pacchetto MLflow nel Registro di sistema di Microsoft Fabric. Se nell'area di lavoro esiste un modello di Machine Learning già sottoposto a training e registrato, è possibile passare al passaggio 2. In caso contrario, il passaggio 1 fornisce codice di esempio che consente di eseguire il training di un modello di regressione logistica di esempio. È possibile usare questo modello per generare stime batch alla fine della procedura.
Eseguire il training di un modello di Machine Learning e registrarlo con MLflow. L'esempio di codice successivo usa l'API MLflow per creare un esperimento di Machine Learning e quindi avvia un'esecuzione MLflow per un modello di regressione logistica scikit-learn. La versione del modello viene quindi archiviata e registrata nel Registro di sistema di Microsoft Fabric. Per altre informazioni sui modelli di training e sul rilevamento di esperimenti personalizzati, vedere l'articolo su come eseguire il training dei modelli di Machine Learning con la risorsa scikit-learn .
import mlflow import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.datasets import load_diabetes from mlflow.models.signature import infer_signature mlflow.set_experiment("diabetes-demo") with mlflow.start_run() as run: lr = LogisticRegression() data = load_diabetes(as_frame=True) lr.fit(data.data, data.target) signature = infer_signature(data.data, data.target) mlflow.sklearn.log_model( lr, "diabetes-model", signature=signature, registered_model_name="diabetes-model" )Caricare i dati di test in un dataframe Spark. Per generare stime batch con il modello di Machine Learning sottoposto a training nel passaggio precedente, sono necessari dati di test sotto forma di dataframe Spark. Nel codice seguente sostituire il valore della
testvariabile con i propri dati.# You can substitute "test" below with your own data test = spark.createDataFrame(data.frame.drop(['target'], axis=1))Creare un oggetto
MLFlowTransformerper caricare il modello di Machine Learning per l'inferenza. Per creare unMLFlowTransformeroggetto per generare stime batch, è necessario eseguire queste azioni:- specificare le
testcolonne dataframe necessarie come input del modello (in questo caso, tutte) - scegliere un nome per la nuova colonna di output (in questo caso,
predictions) - specificare il nome del modello e la versione del modello corretti per la generazione di tali stime.
Se si usa un modello di Machine Learning personalizzato, sostituire i valori per le colonne di input, il nome della colonna di output, il nome del modello e la versione del modello.
from synapse.ml.predict import MLFlowTransformer # You can substitute values below for your own input columns, # output column name, model name, and model version model = MLFlowTransformer( inputCols=test.columns, outputCol='predictions', modelName='diabetes-model', modelVersion=1 )- specificare le
Generare stime usando la funzione PREDICT. Per richiamare la funzione PREDICT, usare l'API Transformer, l'API SQL Spark o una funzione definita dall'utente PySpark. Le sezioni seguenti illustrano come generare stime batch con i dati di test e il modello di Machine Learning definiti nei passaggi precedenti, usando i diversi metodi per richiamare la funzione PREDICT.
PREDICT con l'API Transformer
Questo codice richiama la funzione PREDICT con l'API Transformer. Se si usa un modello di Machine Learning personalizzato, sostituire i valori per il modello e i dati di test.
# You can substitute "model" and "test" below with values
# for your own model and test data
model.transform(test).show()
PREDICT con l'API SPARK SQL
Questo codice richiama la funzione PREDICT con l'API SPARK SQL. Se si usa un modello di Machine Learning personalizzato, sostituire i valori per model_name, model_versione features con il nome del modello, la versione del modello e le colonne delle funzionalità.
Nota
L'uso dell'API SQL Spark per la generazione di stime richiede comunque la creazione di un MLFlowTransformer oggetto (come illustrato nel passaggio 3).
from pyspark.ml.feature import SQLTransformer
# You can substitute "model_name," "model_version," and "features"
# with values for your own model name, model version, and feature columns
model_name = 'diabetes-model'
model_version = 1
features = test.columns
sqlt = SQLTransformer().setStatement(
f"SELECT PREDICT('{model_name}/{model_version}', {','.join(features)}) as predictions FROM __THIS__")
# You can substitute "test" below with your own test data
sqlt.transform(test).show()
PREDICT con una funzione definita dall'utente
Questo codice richiama la funzione PREDICT con una funzione definita dall'utente PySpark. Se si usa un modello di Machine Learning personalizzato, sostituire i valori per il modello e le funzionalità.
from pyspark.sql.functions import col, pandas_udf, udf, lit
# You can substitute "model" and "features" below with your own values
my_udf = model.to_udf()
features = test.columns
test.withColumn("PREDICT", my_udf(*[col(f) for f in features])).show()
Generare il codice PREDICT dalla pagina dell'elemento di un modello di Machine Learning
Dalla pagina dell'elemento di qualsiasi modello di Machine Learning è possibile scegliere una di queste opzioni per avviare la generazione di stime batch per una versione specifica del modello, con la funzione PREDICT:
- Copiare un modello di codice in un notebook e personalizzare manualmente i parametri
- Usare un'esperienza di interfaccia utente guidata per generare codice PREDICT
Usare un'esperienza di interfaccia utente guidata
L'esperienza dell'interfaccia utente guidata illustra i passaggi seguenti:
- Selezionare i dati di origine per l'assegnazione dei punteggi
- Eseguire correttamente il mapping dei dati agli input del modello di Machine Learning
- Specificare la destinazione per gli output del modello
- Creare un notebook che usa PREDICT per generare e archiviare i risultati della stima
Per usare l'esperienza guidata,
Passare alla pagina dell'elemento per una determinata versione del modello di Machine Learning.
Nell'elenco a discesa Applica questa versione selezionare Applica questo modello nella procedura guidata.

Nel passaggio "Select input table" (Seleziona tabella di input) viene visualizzata la finestra "Apply ML model predictions" (Applica stime del modello di Machine Learning).
Selezionare una tabella di input da una lakehouse nell'area di lavoro corrente.

Selezionare Avanti per passare al passaggio "Mappa colonne di input".
Eseguire il mapping dei nomi delle colonne dalla tabella di origine ai campi di input del modello di Machine Learning, estratti dalla firma del modello. È necessario specificare una colonna di input per tutti i campi obbligatori del modello. Inoltre, i tipi di dati della colonna di origine devono corrispondere ai tipi di dati previsti del modello.
Suggerimento
La procedura guidata prepopola questo mapping se i nomi delle colonne della tabella di input corrispondono ai nomi di colonna registrati nella firma del modello di Machine Learning.
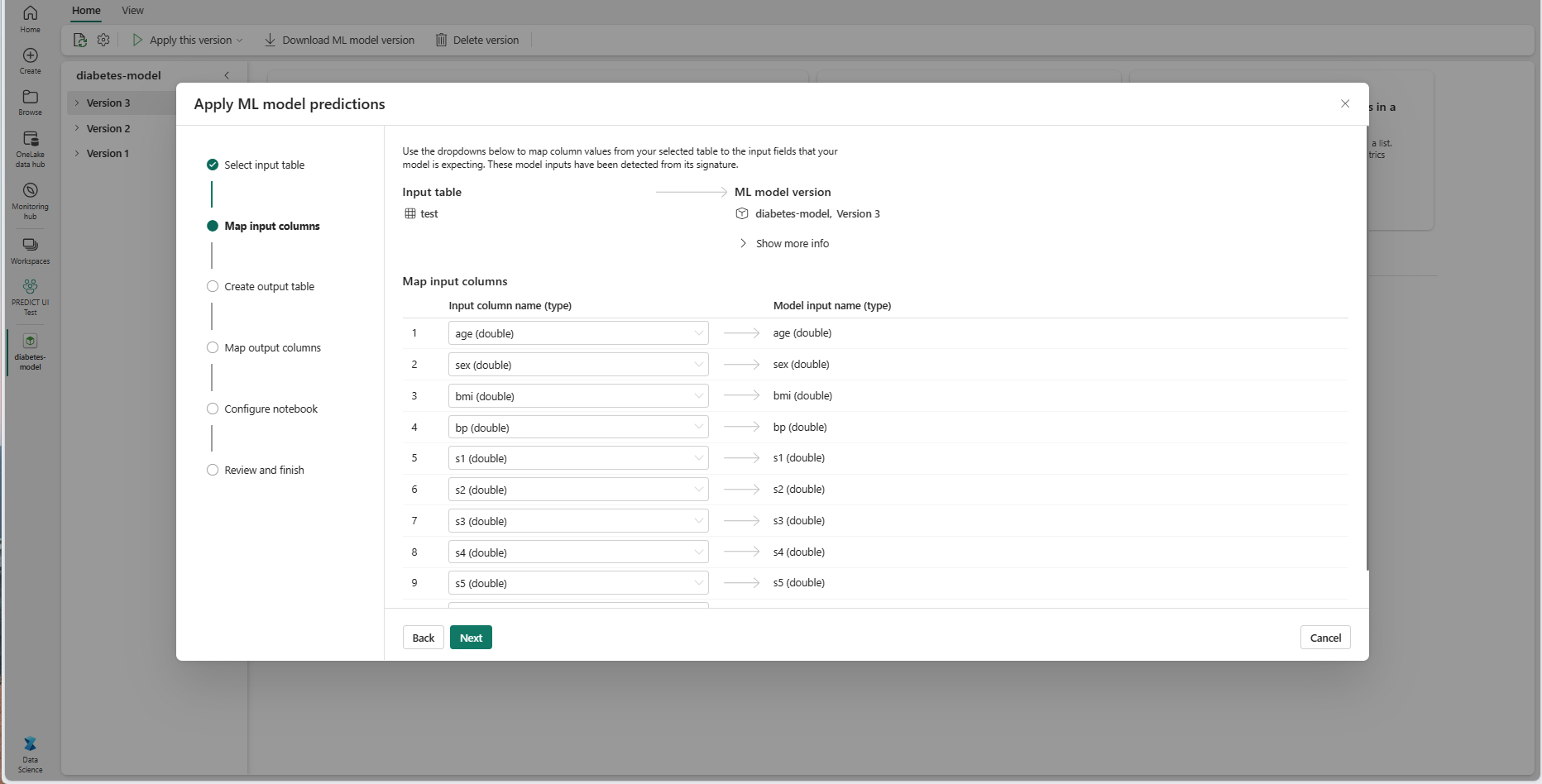
Selezionare Avanti per passare al passaggio "Crea tabella di output".
Specificare un nome per una nuova tabella all'interno del lakehouse selezionato dell'area di lavoro corrente. Questa tabella di output archivia i valori di input del modello di Machine Learning e aggiunge i valori di stima a tale tabella. Per impostazione predefinita, la tabella di output viene creata nella stessa lakehouse della tabella di input. È possibile modificare il lakehouse di destinazione.
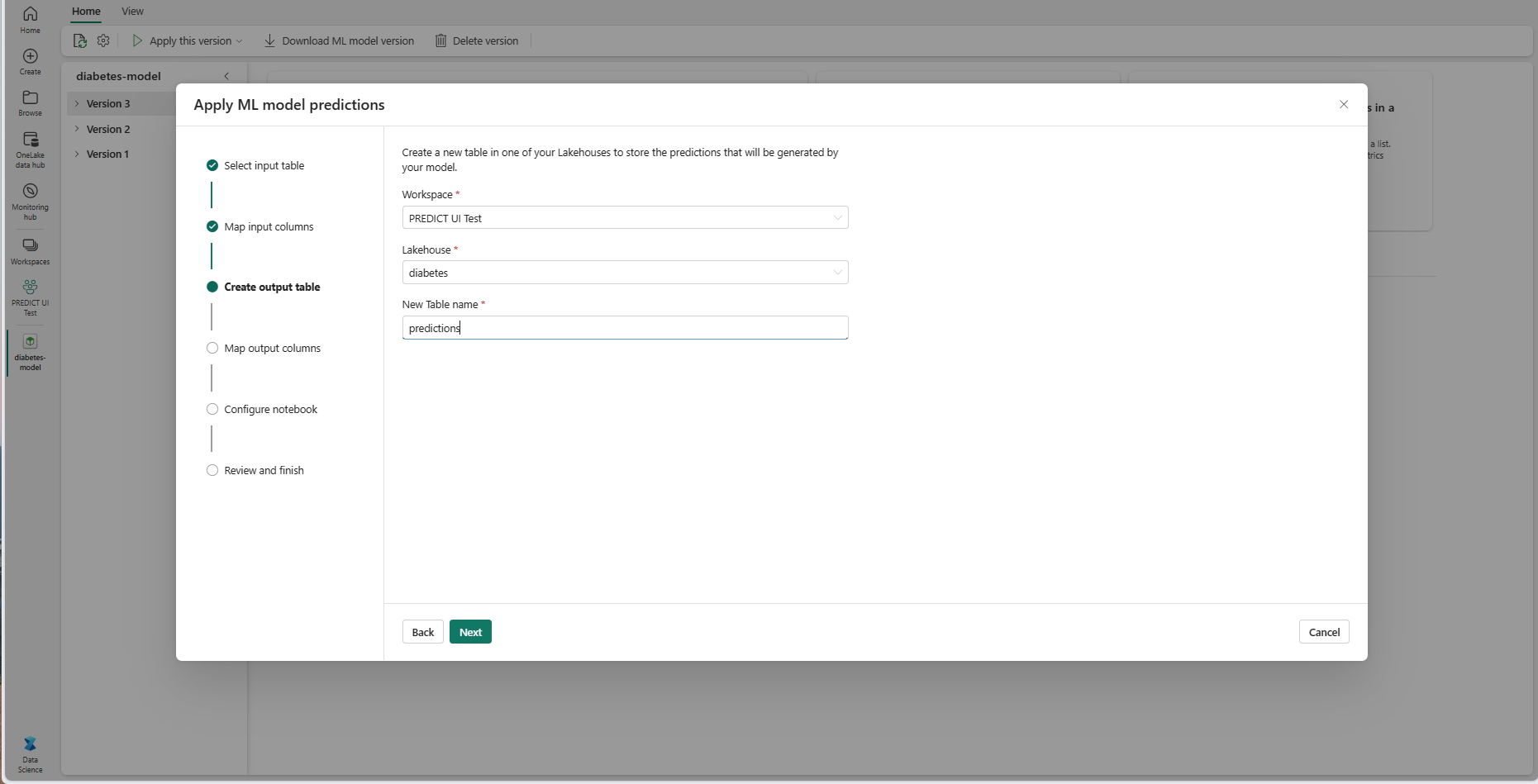
Selezionare Avanti per passare al passaggio "Mappa colonne di output".
Usare i campi di testo forniti per denominare le colonne della tabella di output in cui sono archiviate le stime del modello di Machine Learning.

Selezionare Avanti per passare al passaggio "Configura notebook".
Specificare un nome per un nuovo notebook che esegue il codice PREDICT generato. La procedura guidata visualizza un'anteprima del codice generato in questo passaggio. Se si vuole, è possibile copiare il codice negli Appunti e incollarlo in un notebook esistente.
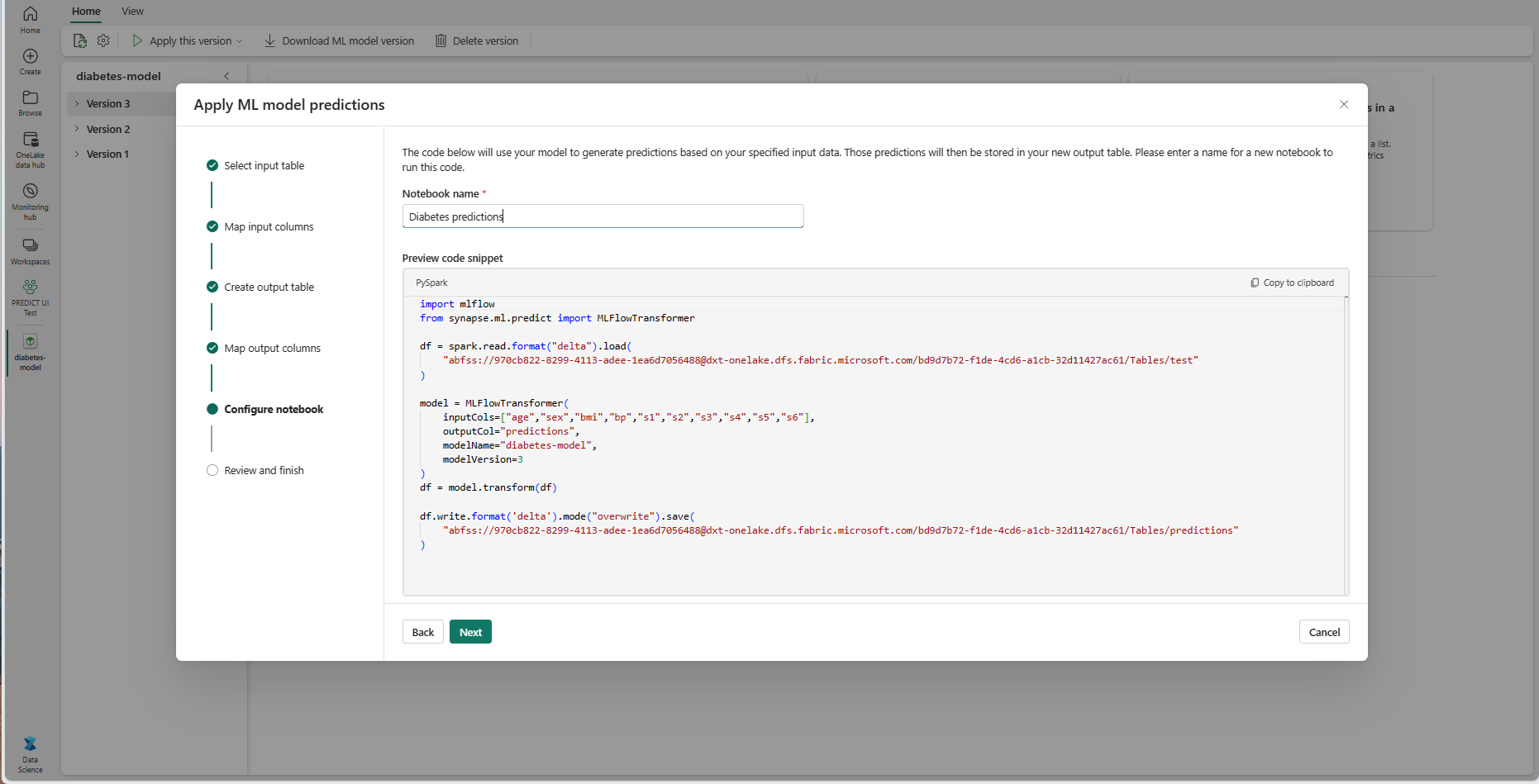
Selezionare Avanti per passare al passaggio "Rivedi e termina".
Esaminare i dettagli nella pagina di riepilogo e selezionare Crea notebook per aggiungere il nuovo notebook con il codice generato all'area di lavoro. Si passa direttamente a quel notebook, in cui è possibile eseguire il codice per generare e archiviare stime.








Usare un modello di codice personalizzabile
Per usare un modello di codice per la generazione di stime batch:
- Passare alla pagina dell'elemento per una determinata versione del modello di Machine Learning.
- Selezionare Copia codice da applicare nell'elenco a discesa Applica questa versione. La selezione consente di copiare un modello di codice personalizzabile.
È possibile incollare questo modello di codice in un notebook per generare stime batch con il modello di Machine Learning. Per eseguire correttamente il modello di codice, è necessario sostituire manualmente i valori seguenti:
<INPUT_TABLE>: percorso del file per la tabella che fornisce input al modello di Machine Learning<INPUT_COLS>: matrice di nomi di colonna dalla tabella di input da inserire nel modello di Machine Learning<OUTPUT_COLS>: nome di una nuova colonna nella tabella di output in cui sono archiviate le stime<MODEL_NAME>: nome del modello di Machine Learning da usare per la generazione di stime<MODEL_VERSION>: versione del modello di Machine Learning da usare per la generazione di stime<OUTPUT_TABLE>: percorso del file per la tabella in cui sono archiviate le stime

import mlflow
from synapse.ml.predict import MLFlowTransformer
df = spark.read.format("delta").load(
<INPUT_TABLE> # Your input table filepath here
)
model = MLFlowTransformer(
inputCols=<INPUT_COLS>, # Your input columns here
outputCol=<OUTPUT_COLS>, # Your new column name here
modelName=<MODEL_NAME>, # Your ML model name here
modelVersion=<MODEL_VERSION> # Your ML model version here
)
df = model.transform(df)
df.write.format('delta').mode("overwrite").save(
<OUTPUT_TABLE> # Your output table filepath here
)