Integrare Databricks Unity Catalog con OneLake
Questo scenario illustra come integrare le tabelle Delta esterne di Unity Catalog a OneLake usando i collegamenti. Dopo aver completato questa esercitazione, sarà possibile sincronizzare automaticamente le tabelle Delta esterne di Unity Catalog in una lakehouse di Microsoft Fabric.
Prerequisiti
Prima di connettersi, è necessario disporre di:
- Un’area di lavoro Fabric.
- Una lakehouse Fabric nell'area di lavoro.
- Tabelle Delta esterne di Unity Catalog create nell'area di lavoro di Databricks di Azure.
Configurare la connessione per la memorizzazione cloud
Prima di tutto, esaminare i percorsi di archiviazione in Azure Data Lake Storage Gen2 (ADLS Gen2) usati dalle tabelle di Unity Catalog. Questa connessione per la memorizzazione cloud viene usata dai collegamenti OneLake. Per creare una connessione cloud al percorso di archiviazione di Unity Catalog appropriato:
Creare una connessione di memorizzazione cloud usata dalle tabelle di Unity Catalog. Vedere come configurare una connessione ADLS Gen2.
Dopo aver creato la connessione, ottenere l'ID connessione selezionando Impostazioni
 >Gestisci connessioni e gateway>Connessioni>Impostazioni.
>Gestisci connessioni e gateway>Connessioni>Impostazioni.
Nota
Concedere agli utenti l’accesso diretto a livello di archiviazione alla sede di archiviazione esterna in ADLS Gen2 non rispetta le autorizzazioni concesse né i controlli effettuati da Unity Catalog. L'accesso diretto ignora il controllo, la derivazione e altre funzioni di sicurezza/monitoraggio di Unity Catalog, tra cui il controllo di accesso e le autorizzazioni. È tua responsabilità gestire l'accesso diretto all'archiviazione tramite ADLS Gen2 e garantire che gli utenti dispongano delle autorizzazioni appropriate concesse tramite Fabric. Evitare tutti gli scenari che concedono l'accesso in scrittura a livello di archiviazione diretta per i bucket che archiviano tabelle gestite di Databricks. La modifica, l'eliminazione o l'evoluzione di qualsiasi oggetto direttamente tramite l'archiviazione gestita originariamente da Unity Catalog può causare un danneggiamento dei dati.
Eseguire il notebook
Dopo aver ottenuto l'ID connessione cloud, integrare le tabelle di Unity Catalog nella lakehouse Fabric come indicato di seguito:
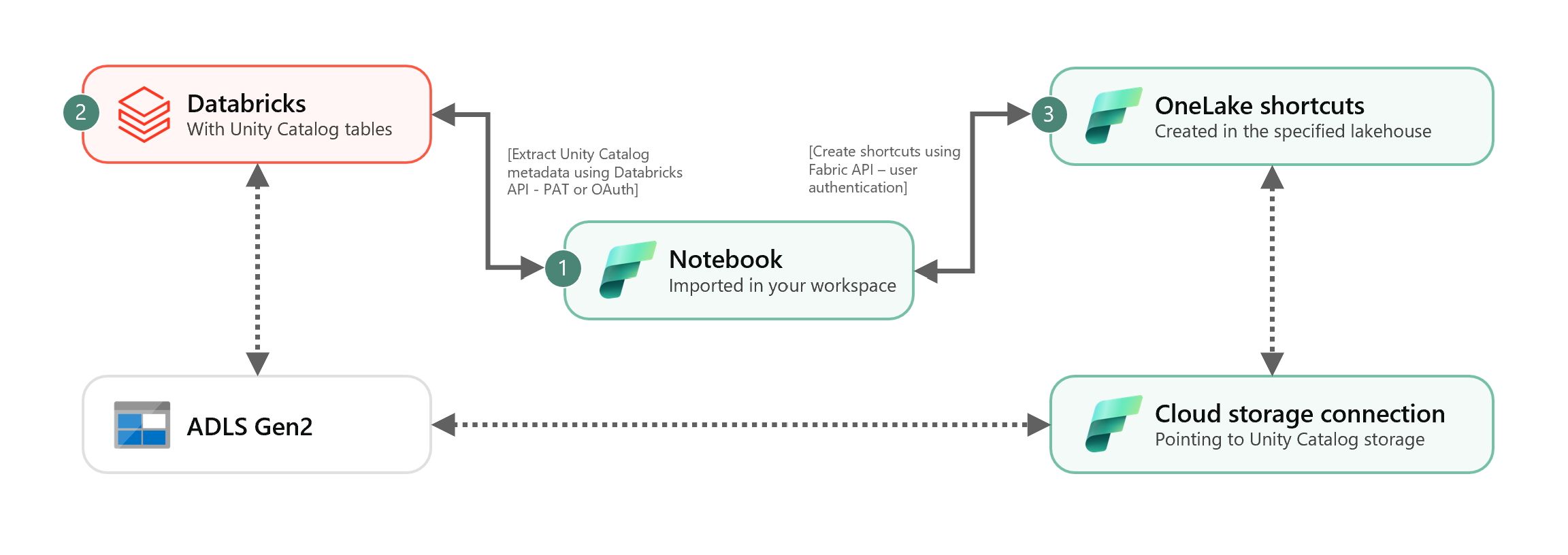
Importare il notebook di sincronizzazione nell'area di lavoro Fabric. Questo notebook esporta tutti i metadati da un determinato catalogo e gli schemi delle tabelle di Unity Catalog nel metastore.
Configurare i parametri nella prima cella del notebook per integrare le tabelle di Unity Catalog. L'API Databricks, autenticata tramite token PAT, viene usata per esportare le tabelle di Unity Catalog. Il frammento di codice seguente viene usato per configurare i parametri di origine (Unity Catalog) e destinazione (OneLake). Assicurarsi di sostituire i valori con i propri.
# Databricks workspace dbx_workspace = "<databricks_workspace_url>" dbx_token = "<pat_token>" # Unity Catalog dbx_uc_catalog = "catalog1" dbx_uc_schemas = '["schema1", "schema2"]' # Fabric fab_workspace_id = "<workspace_id>" fab_lakehouse_id = "<lakehouse_id>" fab_shortcut_connection_id = "<connection_id>" # If True, UC table renames and deletes will be considered fab_consider_dbx_uc_table_changes = TrueEseguire tutte le celle del notebook per avviare la sincronizzazione delle tabelle Delta di Unity Catalog con OneLake usando i collegamenti. Una volta completato il notebook, i collegamenti alle tabelle Delta di Unity Catalog sono disponibili nella lakehouse, nell'endpoint di Analisi SQL e nel modello semantico.
Pianificare un notebook
Se si vuole eseguire il notebook a intervalli regolari per integrare le tabelle Delta di Unity Catalog in OneLake senza risincronizzarle/rieseguirle manualmente, è possibile pianificare il notebook o usare un'attività notebook in una pipeline di dati all'interno della Data Factory di Fabric.
In quest'ultimo scenario, se si vogliono passare parametri dalla pipeline di dati, designare la prima cella del notebook come cella del parametro alternanza e specificare i parametri appropriati nella pipeline.

Altre considerazioni
- Per gli scenari di produzione, è consigliabile usare Databricks OAuth per l'autenticazione e Azure Key Vault per gestire i segreti. Ad esempio, è possibile usare le utilità delle credenziali MSSparkUtils per accedere ai segreti di Key Vault.
- Il notebook funziona con le tabelle Delta esterne di Unity Catalog. Se si usano più percorsi di archiviazione cloud per le tabelle di Unity Catalog, ad esempio più di un ADLS Gen2, è consigliabile eseguire il notebook separatamente da ogni connessione cloud.
- Non sono supportate le tabelle Delta gestite da Unity Catalog, le viste, le viste materializzate, le tabelle di streaming e le tabelle non Delta.
- Le modifiche apportate agli schemi delle tabelle di Unity Catalog, ad esempio l'aggiunta/eliminazione di colonne, vengono riflesse automaticamente nei collegamenti. Tuttavia, alcuni aggiornamenti come la ridenominazione e l'eliminazione della tabella di Unity Catalog richiedono una risincronizzazione/riesecuzione del notebook. Questo valore viene considerato secondo il parametro
fab_consider_dbx_uc_table_changes. - Per gli scenari di scrittura, l'uso dello stesso livello di archiviazione tra motori di calcolo diversi può comportare conseguenze impreviste. Assicurarsi di comprendere le implicazioni quando si usano diversi motori di calcolo e versioni di runtime di Apache Spark.