Estendere Smart Store Analytics
Gli utenti esperti di Smart Store Analytics possono accedere ai dati e alle analisi pertinenti dal proprio data lake storage. L'accesso può avvenire tramite qualsiasi altro servizio o applicazione che supporti Microsoft Azure Data Lake Storage e la definizione di Common Data Model, ad esempio, Microsoft Azure Synapse Analytics, Microsoft Azure Data Factory o Microsoft Power BI.
Importante
Devi usare Microsoft Azure Data Lake Storage Gen2 poiché Microsoft Azure Data Lake Storage Gen1 sarà incompatibile.
Il modello di dati di Smart Store Analytics è conforme ai Azure Synapse modelli di database per la vendita al dettaglio, è ottimizzato con le specifiche di Smart Store Analytics e semplifica la connessione di altre applicazioni ai dati del data lake.
Struttura del data lake di Smart Store Analytics
Il data lake di Smart Store Analytics segue la definizione di Common Data Model (metadati di Common Data Model).
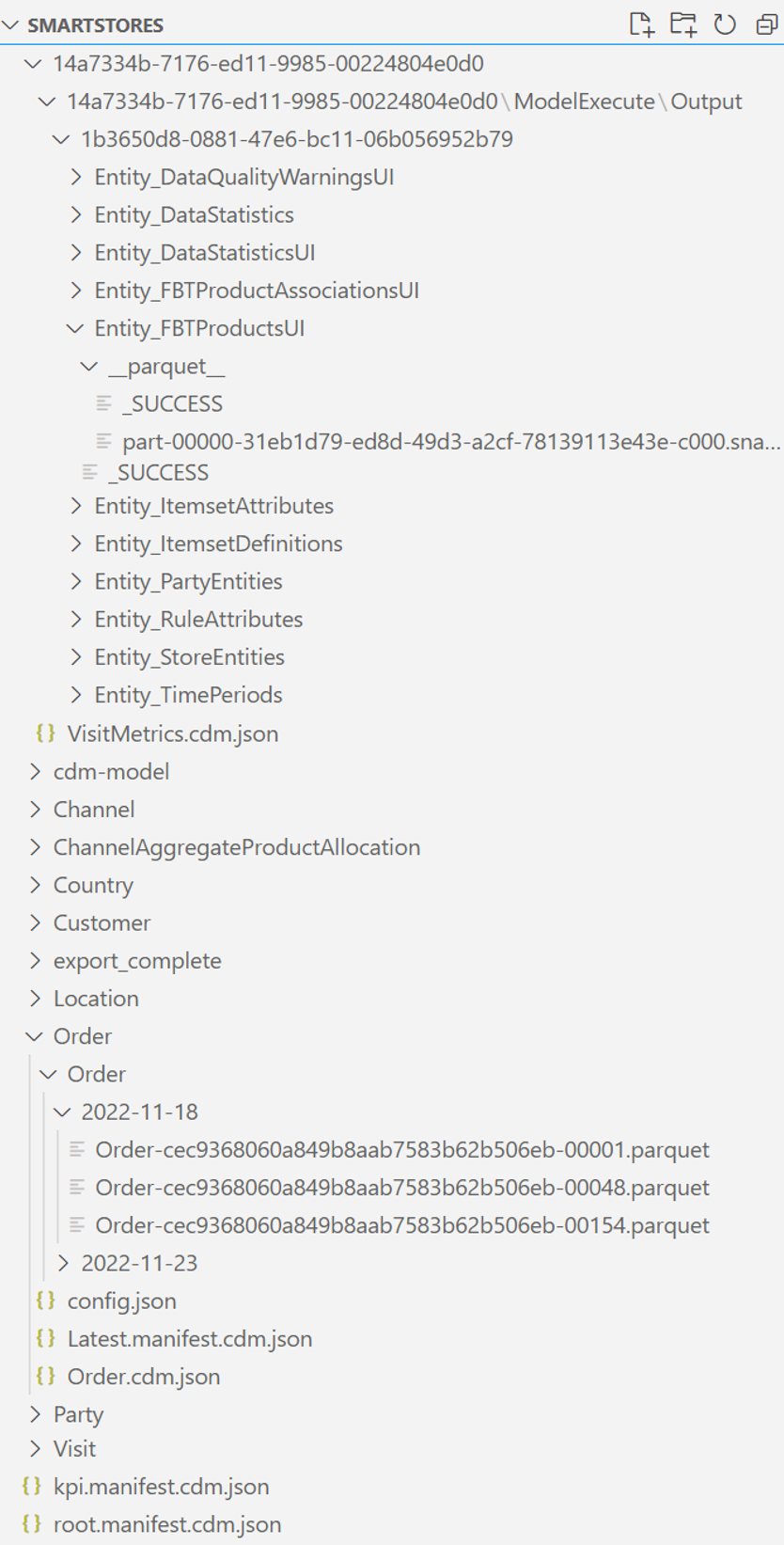
La cartella radice è denominata smartstores/. Nella cartella radice sono presenti due snapshot di dati:
Dati trasformati dal fornitore dello smart store (dati dello smart store non elaborati)
Il manifesto Common Data Model radice per i dati non elaborati è root.manifest.cdm.json. Il file manifesto fa riferimento ai file dello schema e ai file di dati effettivi che si trovano nelle sottocartelle (denominate dopo le tabelle), ad esempio, smartstores/Order/.
La sottocartella di ogni tabella contiene:
schema file, che definisce i metadati della tabella nel formato table-name.cdm.json, ad esempio, Order.cdm.json
file di dati, noti anche come partizioni di dati o record di tabelle, in formato parquet, ad esempio Ordine-cec9368060a849b8aab7583b62b506eb-00001.parquet
Dati generati dai moduli Retail Analytical e IA dai dati non elaborati dello smart store
Tutti i dati generati si trovano in una cartella denominata GUID, ad esempio, smartstores/14a7334b-7176-ed11-9985-00224804e0d0/. Il manifesto Common Data Model radice per questi dati è kpi.manifest.cdm.json. Il file manifest fa riferimento ai file dello schema e ai file di dati effettivi che si trovano nella cartella denominata GUID.
La cartella denominata GUID contiene:
File dello schema per ogni tabella, che definisce i metadati, le colonne e i tipi della tabella nel formato table-name.cdm.json, ad esempio, OrderMetrics.cdm.json
File di dati, noti anche come partizioni di dati o record di tabelle, in formato parquet, ad esempio part-00000-1e110bf0-6474-400b-b40a-086fce9f8e2a-c000.snappy.parquet
Importante
Secondo il contratto di metadati del Common Data Model, gli utenti hanno bisogno di dati solo dai file manifest.cdm.json . Non devono interpretare la struttura delle cartelle o altri file interni presenti nel data lake.
Utilizzo del data lake di Smart Store Analytics
Ecco alcuni esempi di dati sincronizzati in informazioni dettagliate/analitiche generate da Microsoft Cloud for Retail.
Pipeline di dati con Microsoft Azure Data Factory
Per creare una pipeline di dati:
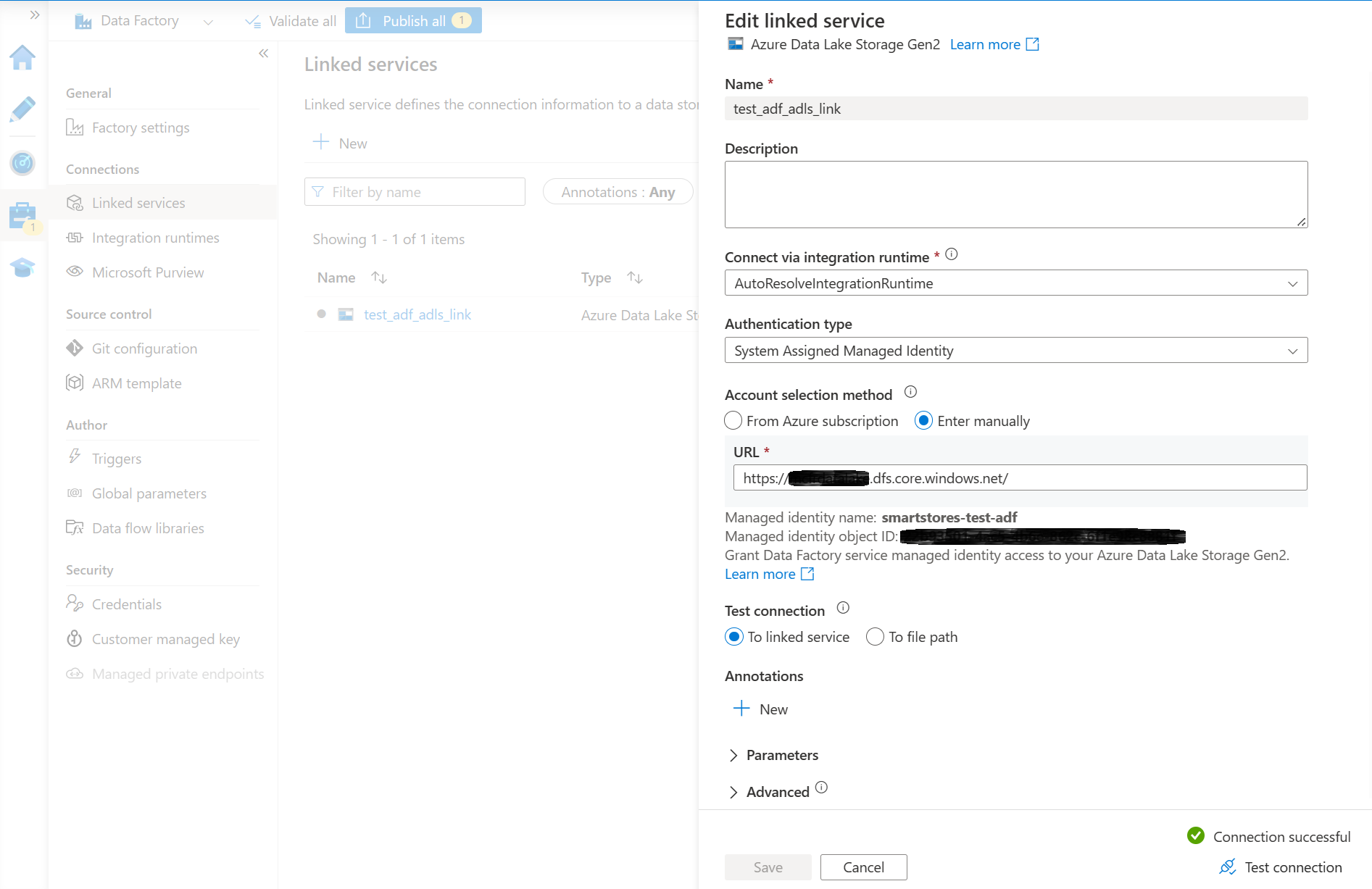
- Crea un'istanza di Azure Data Factory e collegala al data lake storage di Smart Store Analytics. È consigliabile avere un servizio collegato con un test di connessione completato.
Nota
Il modo più semplice per connettere un'istanza di Azure Data Factory a Azure Data Lake Storage è assegnare un ruolo di collaboratore a un'identità gestita di Azure Data Factory nell'account Azure Data Lake Storage. Vedi Documentazione di Azure Data Factory per dettagli.
- Seleziona Pubblica tutto per pubblicare il nuovo collegamento.
Creare una pipeline di dati con Microsoft Azure Data Factory
Per creare una pipeline di copia per la cartella smartstores/ come origine, procedi come segue:
- Nella sezione Autore, seleziona Nuovo flusso di dati per creare un nuovo flusso di dati.
- Avvia il debug per un controllo più rapido della configurazione della pipeline.
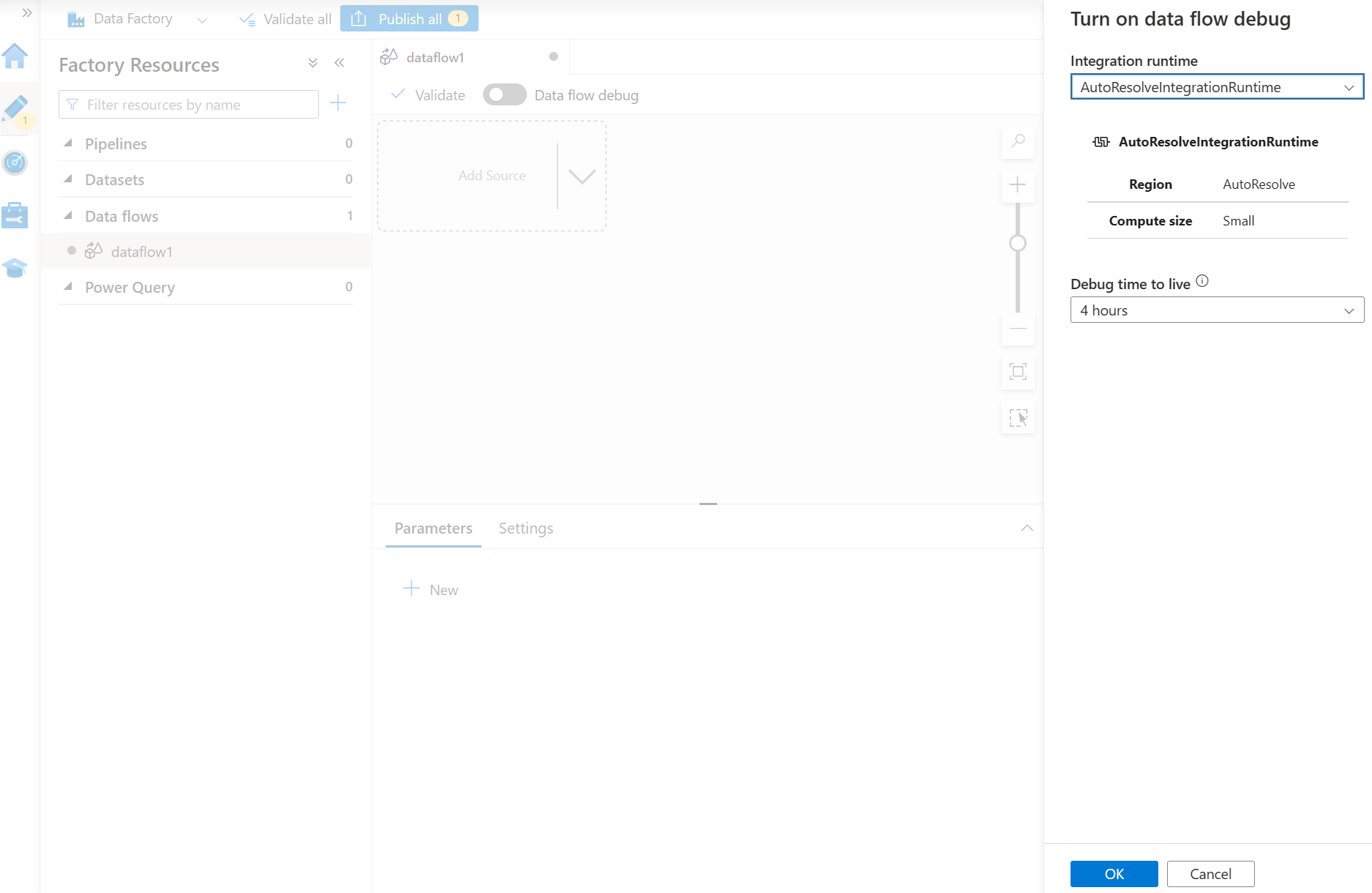
- Configura le impostazioni dell'origine come segue:
- Per il tipo di origine, seleziona Inline
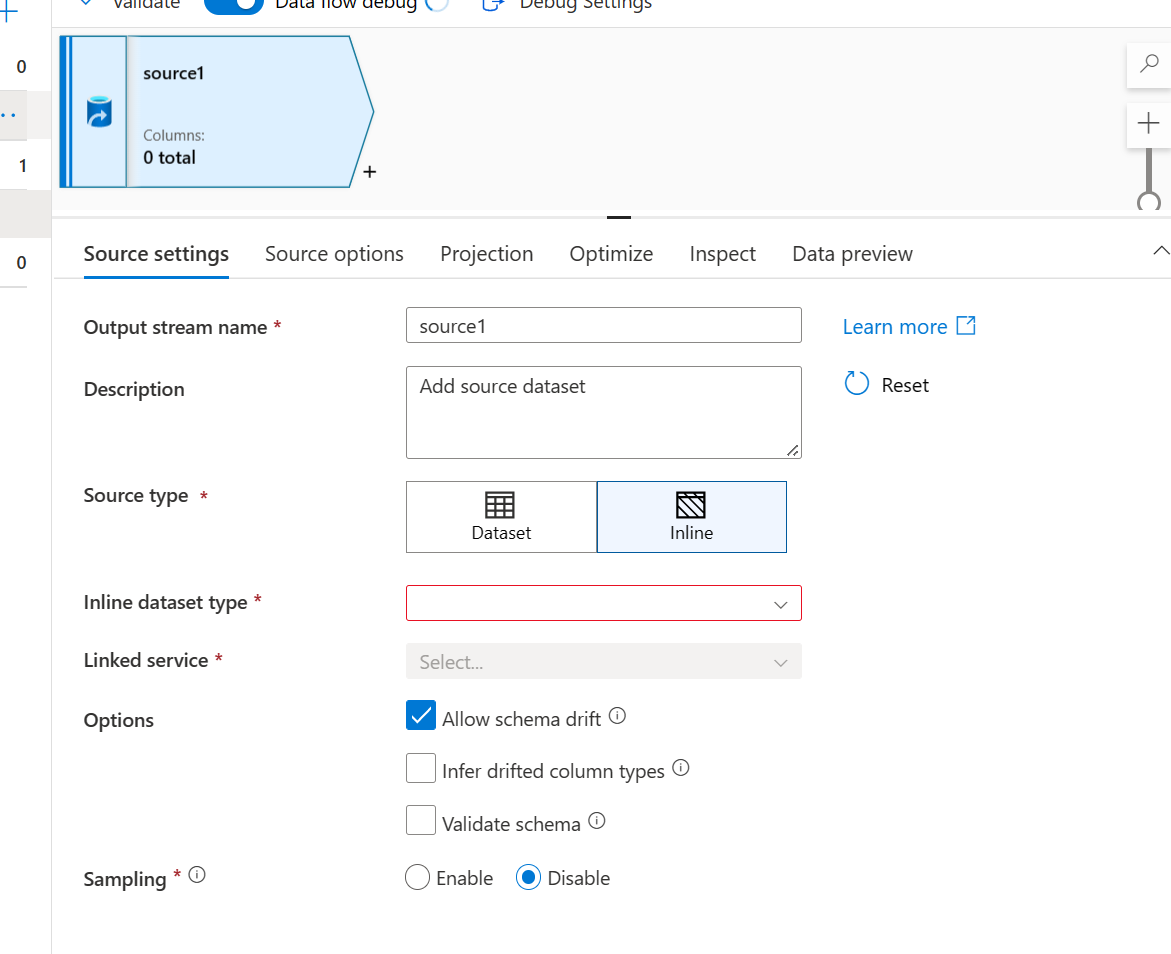
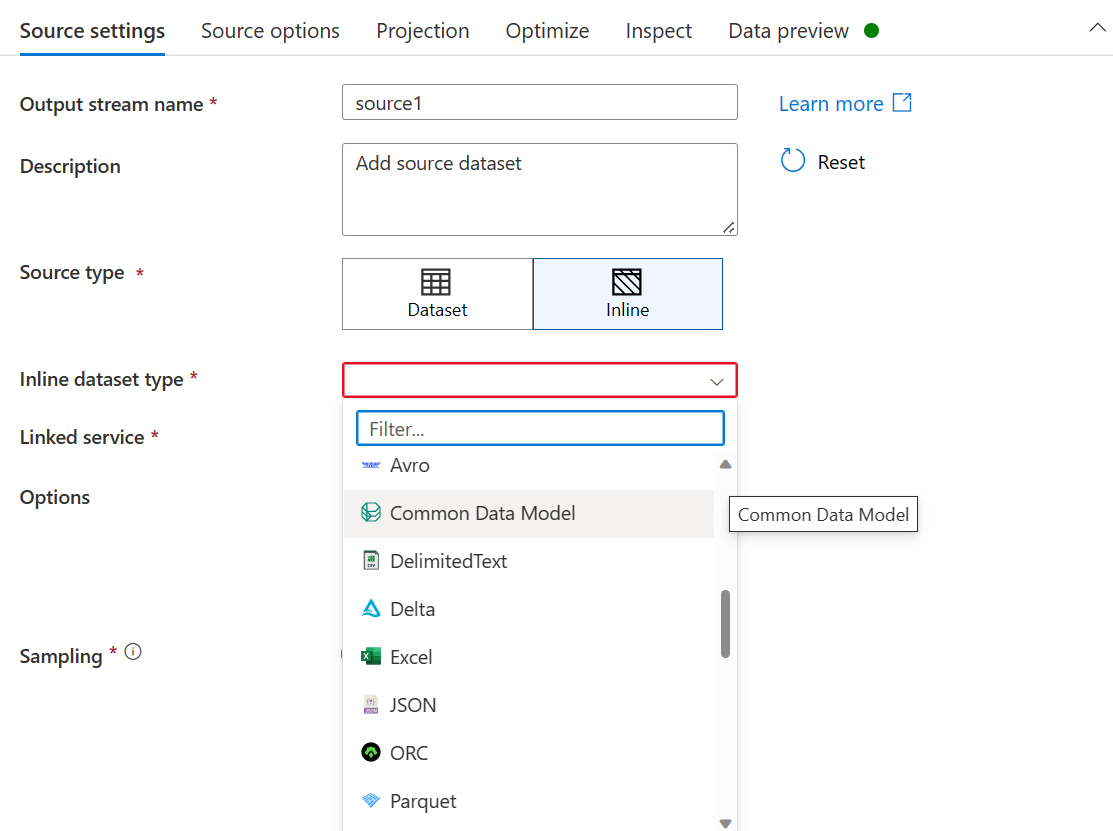
- Per il tipo di set di dati Inline, seleziona Common Data Model
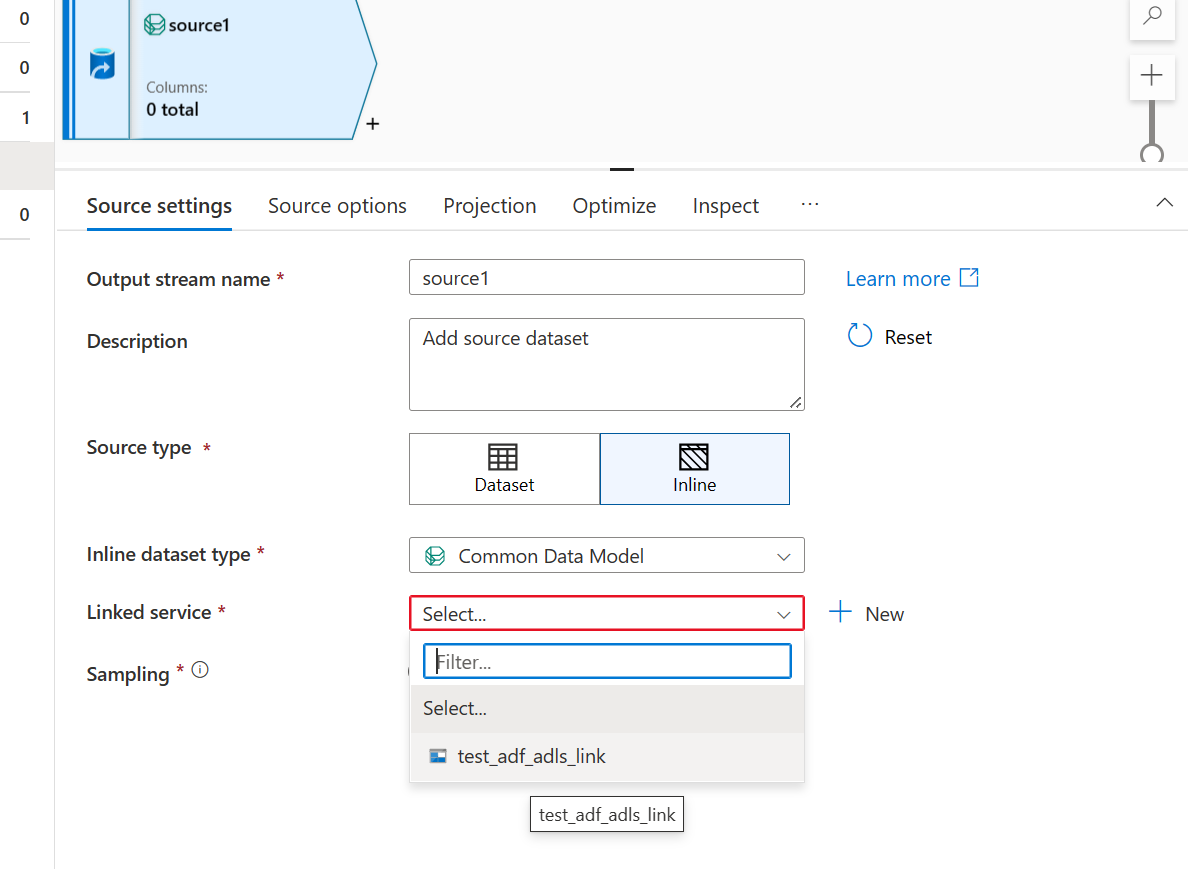
- Utilizza il collegamento Azure Data Lake Storage creato per il data lake di Smart Store Analytics.
- Nella sezione Opzioni di origine, imposta l'origine dello schema Common Data Model come segue:
- Seleziona Manifesto come formato di metadati.
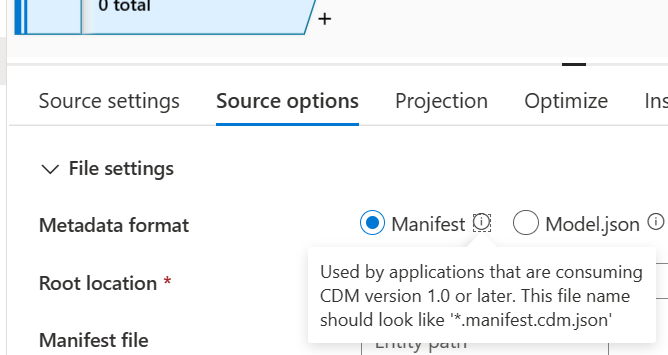
Nella posizione radice, cerca e seleziona la cartella smartstore.
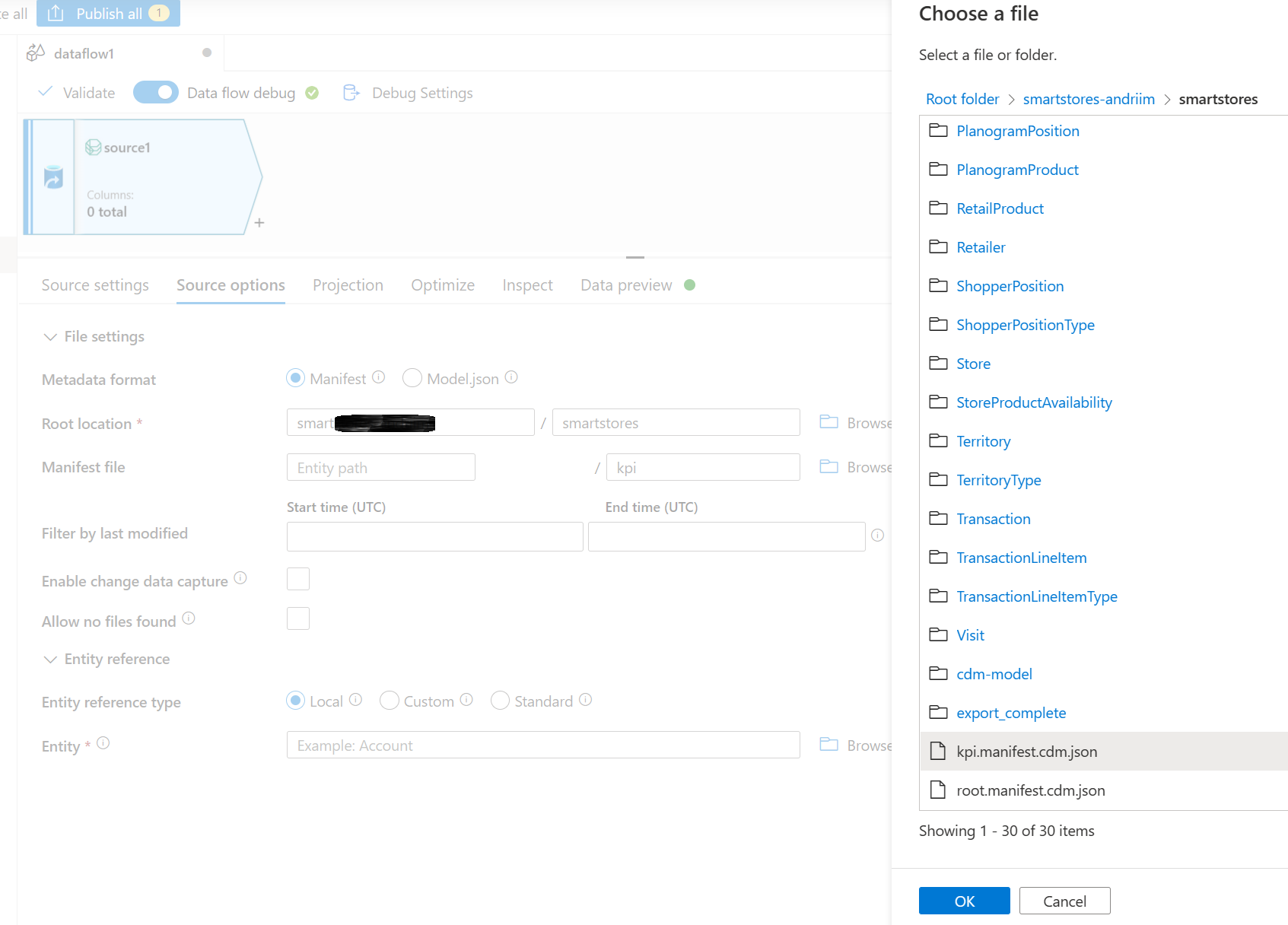
Nella sezione File manifesto, esplora per selezionare il manifesto radice obbligatorio. Seleziona il file radice i dati analitici e di AI Insights, kpi.manifest.cdm.json.
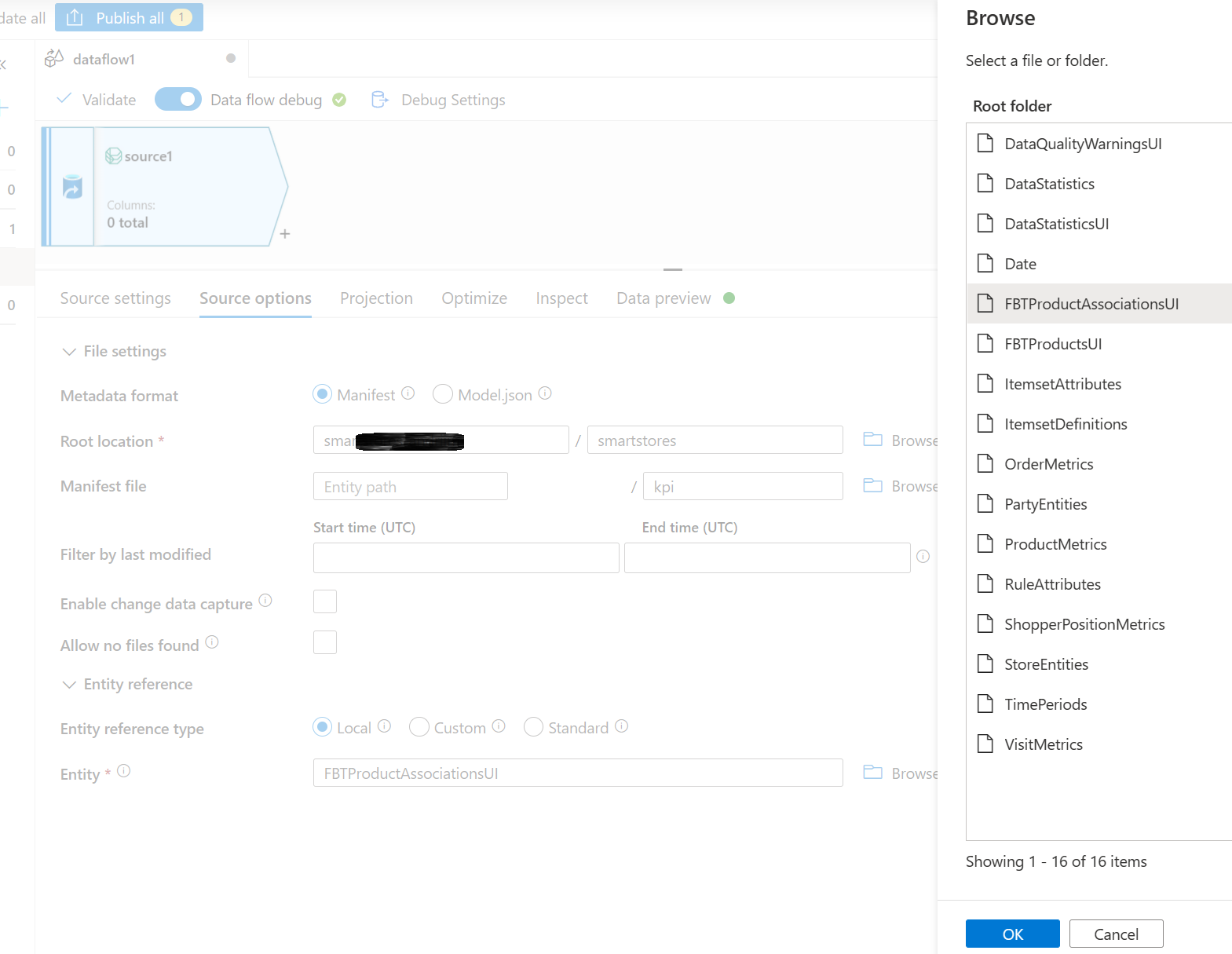
Nella sezione Entità, seleziona l'entità (tabella) che devi copiare/trasformare, ad esempio, FBTProductAssociationsUI dal pacchetto Spesso acquistati insieme.
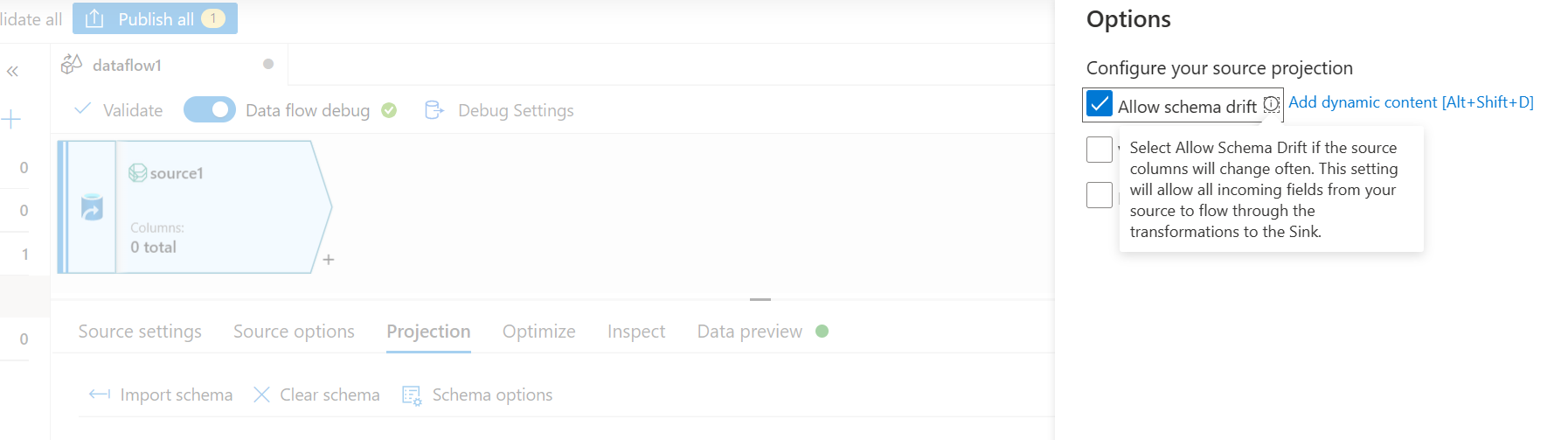
- Nella scheda Proiezione, seleziona Consenti spostamento dello schema. Questa selezione farà in modo che lo schema non venga convalidato all'origine ma si sposterà verso altri passaggi di trasformazione/sink.
- Nella scheda Anteprima dati seleziona Ricarica per convalidare la configurazione dell'origine dati.
Aggiungi un passaggio sink: imposta i parametri e il mapping dei dati secondo necessità per il tuo scenario.
Per pubblicare le modifiche, seleziona Pubblica.