TripPin parte 5 - Paging
Questa esercitazione in più parti illustra la creazione di una nuova estensione dell'origine dati per Power Query. L'esercitazione è destinata a essere eseguita in sequenza: ogni lezione si basa sul connettore creato nelle lezioni precedenti, aggiungendo in modo incrementale nuove funzionalità al connettore.
In questa lezione verranno illustrate le procedure seguenti:
- Aggiungere il supporto per il paging al connettore
Molte API REST restituiscono dati in "pagine", richiedendo ai client di effettuare più richieste per unire i risultati. Anche se esistono alcune convenzioni comuni per l'impaginazione (ad esempio RFC 5988), in genere varia da API a API. Per fortuna, TripPin è un servizio OData e lo standard OData definisce un modo per eseguire l'impaginazione usando i valori odata.nextLink restituiti nel corpo della risposta.
Per semplificare le iterazioni precedenti del connettore, la funzione non riconosceva la TripPin.Feed pagina. È stato semplicemente analizzato il codice JSON restituito dalla richiesta e formattato come tabella. Coloro che hanno familiarità con il protocollo OData potrebbero aver notato che sono stati fatti molti presupposti non corretti nel formato della risposta , ad esempio supponendo che sia presente un campo contenente una value matrice di record.
In questa lezione si migliora la logica di gestione delle risposte rendendola compatibile con la pagina. Le esercitazioni future rendono la logica di gestione della pagina più affidabile e in grado di gestire più formati di risposta (inclusi gli errori del servizio).
Nota
Non è necessario implementare la logica di paging personalizzata con i connettori basati su OData.Feed, perché gestisce tutto automaticamente.
Elenco di controllo per il paging
Quando si implementa il supporto per il paging, è necessario conoscere le informazioni seguenti sull'API:
- Come si richiede la pagina successiva dei dati?
- Il meccanismo di paging prevede il calcolo dei valori o l'estrazione dell'URL per la pagina successiva dalla risposta?
- Come sai quando interrompere il paging?
- Sono presenti parametri correlati al paging di cui tenere conto? (ad esempio "dimensioni pagina")
La risposta a queste domande influisce sul modo in cui si implementa la logica di paging. Anche se è presente una quantità di riutilizzo del codice tra implementazioni di paging, ad esempio l'uso di Table.GenerateByPage, la maggior parte dei connettori finisce per richiedere logica personalizzata.
Nota
Questa lezione contiene la logica di paging per un servizio OData, che segue un formato specifico. Controllare la documentazione relativa all'API per determinare le modifiche che sarà necessario apportare nel connettore per supportare il formato di paging.
Panoramica del paging OData
Il paging OData è basato sulle annotazioni nextLink contenute nel payload della risposta. Il valore nextLink contiene l'URL della pagina successiva di dati. Si saprà se è presente un'altra pagina di dati cercando un odata.nextLink campo nell'oggetto più esterno nella risposta. Se non è presente alcun odata.nextLink campo, tutti i dati sono stati letti.
{
"odata.context": "...",
"odata.count": 37,
"value": [
{ },
{ },
{ }
],
"odata.nextLink": "...?$skiptoken=342r89"
}
Alcuni servizi OData consentono ai client di fornire una preferenza massima per le dimensioni della pagina, ma spetta al servizio se rispettarlo o meno. Power Query deve essere in grado di gestire le risposte di qualsiasi dimensione, quindi non è necessario preoccuparsi di specificare una preferenza per le dimensioni della pagina. È possibile supportare qualsiasi tipo di eccezione generata dal servizio.
Altre informazioni sul paging basato su server sono disponibili nella specifica OData.
Test di TripPin
Prima di correggere l'implementazione del paging, verificare il comportamento corrente dell'estensione dell'esercitazione precedente. La query di test seguente recupera la tabella Persone e aggiunge una colonna di indice per visualizzare il numero di righe corrente.
let
source = TripPin.Contents(),
data = source{[Name="People"]}[Data],
withRowCount = Table.AddIndexColumn(data, "Index")
in
withRowCount
Attivare Fiddler ed eseguire la query in Power Query SDK. Si noti che la query restituisce una tabella con otto righe (indice da 0 a 7).
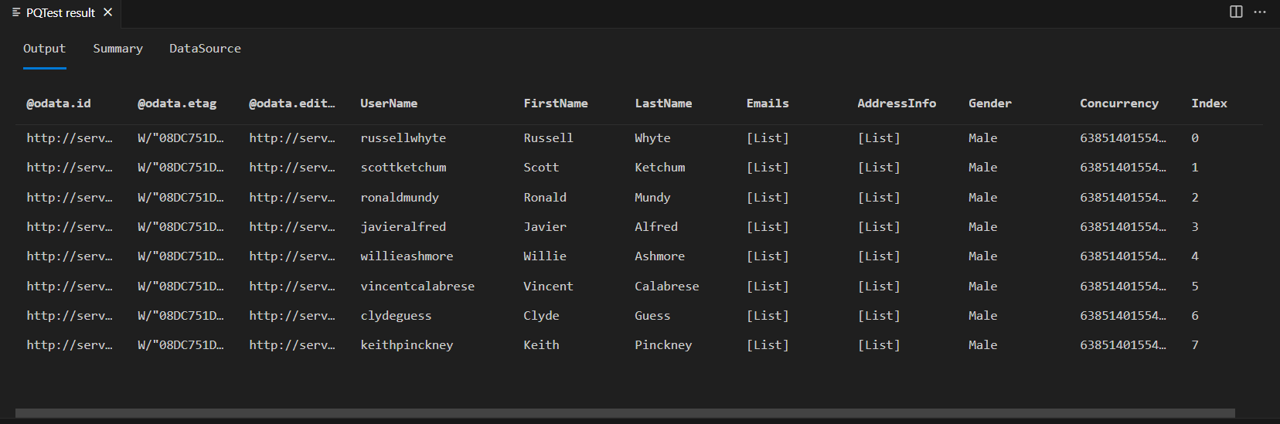
Se si esamina il corpo della risposta di fiddler, si noterà che contiene effettivamente un @odata.nextLink campo, a indicare che sono disponibili più pagine di dati.
{
"@odata.context": "https://services.odata.org/V4/TripPinService/$metadata#People",
"@odata.nextLink": "https://services.odata.org/v4/TripPinService/People?%24skiptoken=8",
"value": [
{ },
{ },
{ }
]
}
Implementazione del paging per TripPin
Verranno apportate le modifiche seguenti all'estensione:
- Importare la funzione comune
Table.GenerateByPage - Aggiungere una
GetAllPagesByNextLinkfunzione che usaTable.GenerateByPageper associare tutte le pagine - Aggiungere una
GetPagefunzione in grado di leggere una singola pagina di dati - Aggiungere una
GetNextLinkfunzione per estrarre l'URL successivo dalla risposta - Aggiornare
TripPin.Feedper usare le nuove funzioni lettore di pagine
Nota
Come indicato in precedenza in questa esercitazione, la logica di paging varia tra le origini dati. L'implementazione tenta di suddividere la logica in funzioni che devono essere riutilizzabili per le origini che usano i collegamenti successivi restituiti nella risposta.
Table.GenerateByPage
Per combinare (potenzialmente) più pagine restituite dall'origine in una singola tabella, si userà Table.GenerateByPage. Questa funzione accetta come argomento una getNextPage funzione che deve eseguire solo ciò che suggerisce il nome: recuperare la pagina successiva di dati. Table.GenerateByPage chiamerà ripetutamente la getNextPage funzione, ogni volta che passa i risultati prodotti l'ultima volta che è stato chiamato, fino a quando non torna null a segnalare che non sono disponibili più pagine.
Poiché questa funzione non fa parte della libreria standard di Power Query, è necessario copiarne il codice sorgente nel file con estensione pq.
Implementazione di GetAllPagesByNextLink
Il corpo della GetAllPagesByNextLink funzione implementa l'argomento getNextPage della funzione per Table.GenerateByPage. Chiamerà la GetPage funzione e recupererà l'URL per la pagina successiva di dati dal NextLink campo del meta record dalla chiamata precedente.
// Read all pages of data.
// After every page, we check the "NextLink" record on the metadata of the previous request.
// Table.GenerateByPage will keep asking for more pages until we return null.
GetAllPagesByNextLink = (url as text) as table =>
Table.GenerateByPage((previous) =>
let
// if previous is null, then this is our first page of data
nextLink = if (previous = null) then url else Value.Metadata(previous)[NextLink]?,
// if NextLink was set to null by the previous call, we know we have no more data
page = if (nextLink <> null) then GetPage(nextLink) else null
in
page
);
Implementazione di GetPage
La GetPage funzione userà Web.Contents per recuperare una singola pagina di dati dal servizio TripPin e convertire la risposta in una tabella. Passa la risposta da Web.Contents alla GetNextLink funzione per estrarre l'URL della pagina successiva e la imposta sul meta record della tabella restituita (pagina di dati).
Questa implementazione è una versione leggermente modificata della TripPin.Feed chiamata dalle esercitazioni precedenti.
GetPage = (url as text) as table =>
let
response = Web.Contents(url, [ Headers = DefaultRequestHeaders ]),
body = Json.Document(response),
nextLink = GetNextLink(body),
data = Table.FromRecords(body[value])
in
data meta [NextLink = nextLink];
Implementazione di GetNextLink
La GetNextLink funzione controlla semplicemente il corpo della risposta per un @odata.nextLink campo e ne restituisce il valore.
// In this implementation, 'response' will be the parsed body of the response after the call to Json.Document.
// Look for the '@odata.nextLink' field and simply return null if it doesn't exist.
GetNextLink = (response) as nullable text => Record.FieldOrDefault(response, "@odata.nextLink");
Combinazione delle funzionalità
Il passaggio finale per implementare la logica di paging consiste nell'aggiornare TripPin.Feed per usare le nuove funzioni. Per il momento, si sta semplicemente chiamando a GetAllPagesByNextLink, ma nelle esercitazioni successive si aggiungeranno nuove funzionalità, ad esempio l'applicazione di uno schema e la logica dei parametri di query.
TripPin.Feed = (url as text) as table => GetAllPagesByNextLink(url);
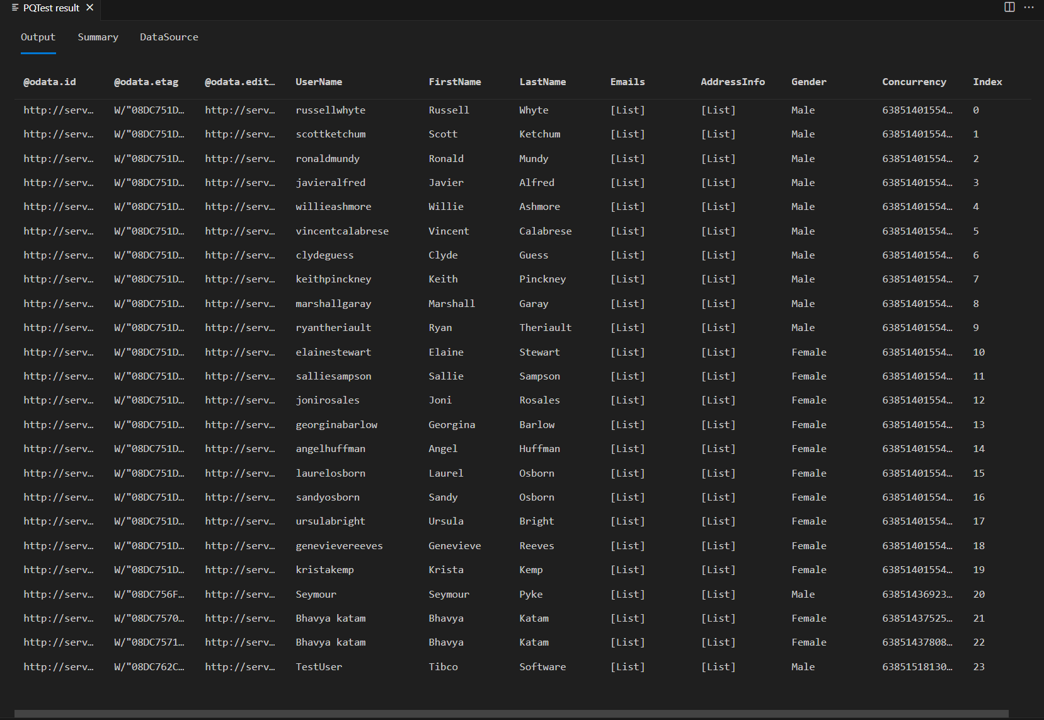
Se si esegue nuovamente la stessa query di test precedente nell'esercitazione, verrà visualizzato il lettore di pagine in azione. Si noterà anche che nella risposta sono presenti 24 righe anziché otto.
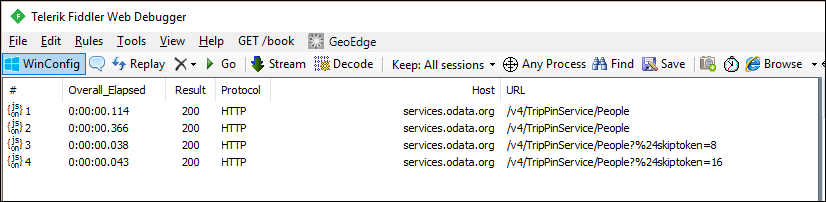
Se si esaminano le richieste in fiddler, dovrebbero ora essere visualizzate richieste separate per ogni pagina di dati.
Nota
Si noteranno richieste duplicate per la prima pagina di dati dal servizio, che non è ideale. La richiesta aggiuntiva è il risultato del comportamento di controllo dello schema del motore M. Ignorare questo problema per il momento e risolverlo nell'esercitazione successiva, in cui verrà applicato uno schema esplicito.
Conclusione
Questa lezione ha illustrato come implementare il supporto della paginazione per un'API REST. Anche se la logica varia probabilmente tra le API, il modello stabilito qui dovrebbe essere riutilizzabile con modifiche minime.
Nella lezione successiva si esaminerà come applicare uno schema esplicito ai dati, oltre ai tipi di dati semplici text e number che si ottengono da Json.Document.