Scenari più avanzati per la telemetria
Nota
Questo articolo userà aspirare dashboard per l'illustrazione. Se si preferisce usare altri strumenti, vedere la documentazione dello strumento in uso nelle istruzioni di installazione.
Chiamata automatica di funzioni
La chiamata automatica delle funzioni è una funzionalità del kernel semantico che consente al kernel di eseguire automaticamente le funzioni quando il modello risponde con le chiamate di funzione e fornisce i risultati al modello. Questa funzionalità è utile per gli scenari in cui una query richiede più iterazioni di chiamate di funzione per ottenere una risposta finale in linguaggio naturale. Per altri dettagli, vedere questi esempi di GitHub.
Nota
La chiamata a funzioni non è supportata da tutti i modelli.
Suggerimento
Si sente il termine "strumenti" e "chiamata di strumenti" talvolta usato in modo intercambiabile con "funzioni" e "chiamata di funzione".
Prerequisiti
- Distribuzione del completamento della chat OpenAI di Azure che supporta la chiamata a funzioni.
- Docker
- La versione più recente di .Net SDK per il sistema operativo.
- Distribuzione del completamento della chat OpenAI di Azure che supporta la chiamata a funzioni.
- Docker
- Python 3.10, 3.11 o 3.12 installato nel computer.
Nota
L'osservabilità del kernel semantico non è ancora disponibile per Java.
Attrezzaggio
Creare un nuovo progetto di applicazione console
In un terminale eseguire il comando seguente per creare una nuova applicazione console in C#:
dotnet new console -n TelemetryAutoFunctionCallingQuickstart
Passare alla directory del progetto appena creata al termine del comando.
Installare i pacchetti necessari
Kernel semantico
dotnet add package Microsoft.SemanticKernelUtilità di esportazione della console OpenTelemetry
dotnet add package OpenTelemetry.Exporter.OpenTelemetryProtocol
Creare una semplice applicazione con il kernel semantico
Dalla directory del progetto aprire il file con l'editor Program.cs preferito. Verrà creata una semplice applicazione che usa il kernel semantico per inviare una richiesta a un modello di completamento della chat. Sostituire il contenuto esistente con il codice seguente e immettere i valori obbligatori per deploymentName, endpointe apiKey:
using System.ComponentModel;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Logging;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using OpenTelemetry;
using OpenTelemetry.Logs;
using OpenTelemetry.Metrics;
using OpenTelemetry.Resources;
using OpenTelemetry.Trace;
namespace TelemetryAutoFunctionCallingQuickstart
{
class BookingPlugin
{
[KernelFunction("FindAvailableRooms")]
[Description("Finds available conference rooms for today.")]
public async Task<List<string>> FindAvailableRoomsAsync()
{
// Simulate a remote call to a booking system.
await Task.Delay(1000);
return ["Room 101", "Room 201", "Room 301"];
}
[KernelFunction("BookRoom")]
[Description("Books a conference room.")]
public async Task<string> BookRoomAsync(string room)
{
// Simulate a remote call to a booking system.
await Task.Delay(1000);
return $"Room {room} booked.";
}
}
class Program
{
static async Task Main(string[] args)
{
// Endpoint to the Aspire Dashboard
var endpoint = "http://localhost:4317";
var resourceBuilder = ResourceBuilder
.CreateDefault()
.AddService("TelemetryAspireDashboardQuickstart");
// Enable model diagnostics with sensitive data.
AppContext.SetSwitch("Microsoft.SemanticKernel.Experimental.GenAI.EnableOTelDiagnosticsSensitive", true);
using var traceProvider = Sdk.CreateTracerProviderBuilder()
.SetResourceBuilder(resourceBuilder)
.AddSource("Microsoft.SemanticKernel*")
.AddOtlpExporter(options => options.Endpoint = new Uri(endpoint))
.Build();
using var meterProvider = Sdk.CreateMeterProviderBuilder()
.SetResourceBuilder(resourceBuilder)
.AddMeter("Microsoft.SemanticKernel*")
.AddOtlpExporter(options => options.Endpoint = new Uri(endpoint))
.Build();
using var loggerFactory = LoggerFactory.Create(builder =>
{
// Add OpenTelemetry as a logging provider
builder.AddOpenTelemetry(options =>
{
options.SetResourceBuilder(resourceBuilder);
options.AddOtlpExporter(options => options.Endpoint = new Uri(endpoint));
// Format log messages. This is default to false.
options.IncludeFormattedMessage = true;
options.IncludeScopes = true;
});
builder.SetMinimumLevel(LogLevel.Information);
});
IKernelBuilder builder = Kernel.CreateBuilder();
builder.Services.AddSingleton(loggerFactory);
builder.AddAzureOpenAIChatCompletion(
deploymentName: "your-deployment-name",
endpoint: "your-azure-openai-endpoint",
apiKey: "your-azure-openai-api-key"
);
builder.Plugins.AddFromType<BookingPlugin>();
Kernel kernel = builder.Build();
var answer = await kernel.InvokePromptAsync(
"Reserve a conference room for me today.",
new KernelArguments(
new OpenAIPromptExecutionSettings {
ToolCallBehavior = ToolCallBehavior.AutoInvokeKernelFunctions
}
)
);
Console.WriteLine(answer);
}
}
}
Nel codice precedente viene prima definito un plug-in fittizio di prenotazione della sala riunioni con due funzioni: FindAvailableRoomsAsync e BookRoomAsync. Si crea quindi una semplice applicazione console che registra il plug-in nel kernel e si chiede al kernel di chiamare automaticamente le funzioni quando necessario.
Creare un nuovo ambiente virtuale Python
python -m venv telemetry-auto-function-calling-quickstart
Attivare l'ambiente virtuale.
telemetry-auto-function-calling-quickstart\Scripts\activate
Installare i pacchetti necessari
pip install semantic-kernel opentelemetry-exporter-otlp-proto-grpc
Creare uno script Python semplice con il kernel semantico
Creare un nuovo script Python e aprirlo con l'editor preferito.
New-Item -Path telemetry_auto_function_calling_quickstart.py -ItemType file
Verrà creato un semplice script Python che usa il kernel semantico per inviare una richiesta a un modello di completamento della chat. Sostituire il contenuto esistente con il codice seguente e immettere i valori obbligatori per deployment_name, endpointe api_key:
import asyncio
import logging
from typing import Annotated
from opentelemetry._logs import set_logger_provider
from opentelemetry.exporter.otlp.proto.grpc._log_exporter import OTLPLogExporter
from opentelemetry.exporter.otlp.proto.grpc.metric_exporter import OTLPMetricExporter
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.metrics import set_meter_provider
from opentelemetry.sdk._logs import LoggerProvider, LoggingHandler
from opentelemetry.sdk._logs.export import BatchLogRecordProcessor
from opentelemetry.sdk.metrics import MeterProvider
from opentelemetry.sdk.metrics.export import PeriodicExportingMetricReader
from opentelemetry.sdk.metrics.view import DropAggregation, View
from opentelemetry.sdk.resources import Resource
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.semconv.resource import ResourceAttributes
from opentelemetry.trace import set_tracer_provider
from semantic_kernel import Kernel
from semantic_kernel.connectors.ai.function_choice_behavior import FunctionChoiceBehavior
from semantic_kernel.connectors.ai.open_ai import AzureChatCompletion
from semantic_kernel.connectors.ai.prompt_execution_settings import PromptExecutionSettings
from semantic_kernel.functions.kernel_arguments import KernelArguments
from semantic_kernel.functions.kernel_function_decorator import kernel_function
class BookingPlugin:
@kernel_function(
name="find_available_rooms",
description="Find available conference rooms for today.",
)
def find_available_rooms(self,) -> Annotated[list[str], "A list of available rooms."]:
return ["Room 101", "Room 201", "Room 301"]
@kernel_function(
name="book_room",
description="Book a conference room.",
)
def book_room(self, room: str) -> Annotated[str, "A confirmation message."]:
return f"Room {room} booked."
# Endpoint to the Aspire Dashboard
endpoint = "http://localhost:4317"
# Create a resource to represent the service/sample
resource = Resource.create({ResourceAttributes.SERVICE_NAME: "telemetry-aspire-dashboard-quickstart"})
def set_up_logging():
exporter = OTLPLogExporter(endpoint=endpoint)
# Create and set a global logger provider for the application.
logger_provider = LoggerProvider(resource=resource)
# Log processors are initialized with an exporter which is responsible
# for sending the telemetry data to a particular backend.
logger_provider.add_log_record_processor(BatchLogRecordProcessor(exporter))
# Sets the global default logger provider
set_logger_provider(logger_provider)
# Create a logging handler to write logging records, in OTLP format, to the exporter.
handler = LoggingHandler()
# Add filters to the handler to only process records from semantic_kernel.
handler.addFilter(logging.Filter("semantic_kernel"))
# Attach the handler to the root logger. `getLogger()` with no arguments returns the root logger.
# Events from all child loggers will be processed by this handler.
logger = logging.getLogger()
logger.addHandler(handler)
logger.setLevel(logging.INFO)
def set_up_tracing():
exporter = OTLPSpanExporter(endpoint=endpoint)
# Initialize a trace provider for the application. This is a factory for creating tracers.
tracer_provider = TracerProvider(resource=resource)
# Span processors are initialized with an exporter which is responsible
# for sending the telemetry data to a particular backend.
tracer_provider.add_span_processor(BatchSpanProcessor(exporter))
# Sets the global default tracer provider
set_tracer_provider(tracer_provider)
def set_up_metrics():
exporter = OTLPMetricExporter(endpoint=endpoint)
# Initialize a metric provider for the application. This is a factory for creating meters.
meter_provider = MeterProvider(
metric_readers=[PeriodicExportingMetricReader(exporter, export_interval_millis=5000)],
resource=resource,
views=[
# Dropping all instrument names except for those starting with "semantic_kernel"
View(instrument_name="*", aggregation=DropAggregation()),
View(instrument_name="semantic_kernel*"),
],
)
# Sets the global default meter provider
set_meter_provider(meter_provider)
# This must be done before any other telemetry calls
set_up_logging()
set_up_tracing()
set_up_metrics()
async def main():
# Create a kernel and add a service
kernel = Kernel()
kernel.add_service(AzureChatCompletion(
api_key="your-azure-openai-api-key",
endpoint="your-azure-openai-endpoint",
deployment_name="your-deployment-name"
))
kernel.add_plugin(BookingPlugin(), "BookingPlugin")
answer = await kernel.invoke_prompt(
"Reserve a conference room for me today.",
arguments=KernelArguments(
settings=PromptExecutionSettings(
function_choice_behavior=FunctionChoiceBehavior.Auto(),
),
),
)
print(answer)
if __name__ == "__main__":
asyncio.run(main())
Nel codice precedente viene prima definito un plug-in fittizio di prenotazione della sala riunioni con due funzioni: find_available_rooms e book_room. Viene quindi creato uno script Python semplice che registra il plug-in nel kernel e viene chiesto al kernel di chiamare automaticamente le funzioni quando necessario.
Variabili di ambiente
Per altre informazioni sulla configurazione delle variabili di ambiente necessarie per consentire al kernel di generare intervalli per i connettori di intelligenza artificiale, vedere questo articolo .
Nota
L'osservabilità del kernel semantico non è ancora disponibile per Java.
Avviare il dashboard aspirare
Seguire le istruzioni riportate qui per avviare il dashboard. Quando il dashboard è in esecuzione, aprire un browser e passare a http://localhost:18888 per accedere al dashboard.
Run
Eseguire l'applicazione console con il comando seguente:
dotnet run
Eseguire lo script Python con il comando seguente:
python telemetry_auto_function_calling_quickstart.py
Nota
L'osservabilità del kernel semantico non è ancora disponibile per Java.
L'output è simile al seguente:
Room 101 has been successfully booked for you today.
Esaminare i dati di telemetria
Dopo aver eseguito l'applicazione, passare al dashboard per esaminare i dati di telemetria.
Trovare la traccia per l'applicazione nella scheda Tracce . Nella traccia devono essere presenti cinque intervalli:
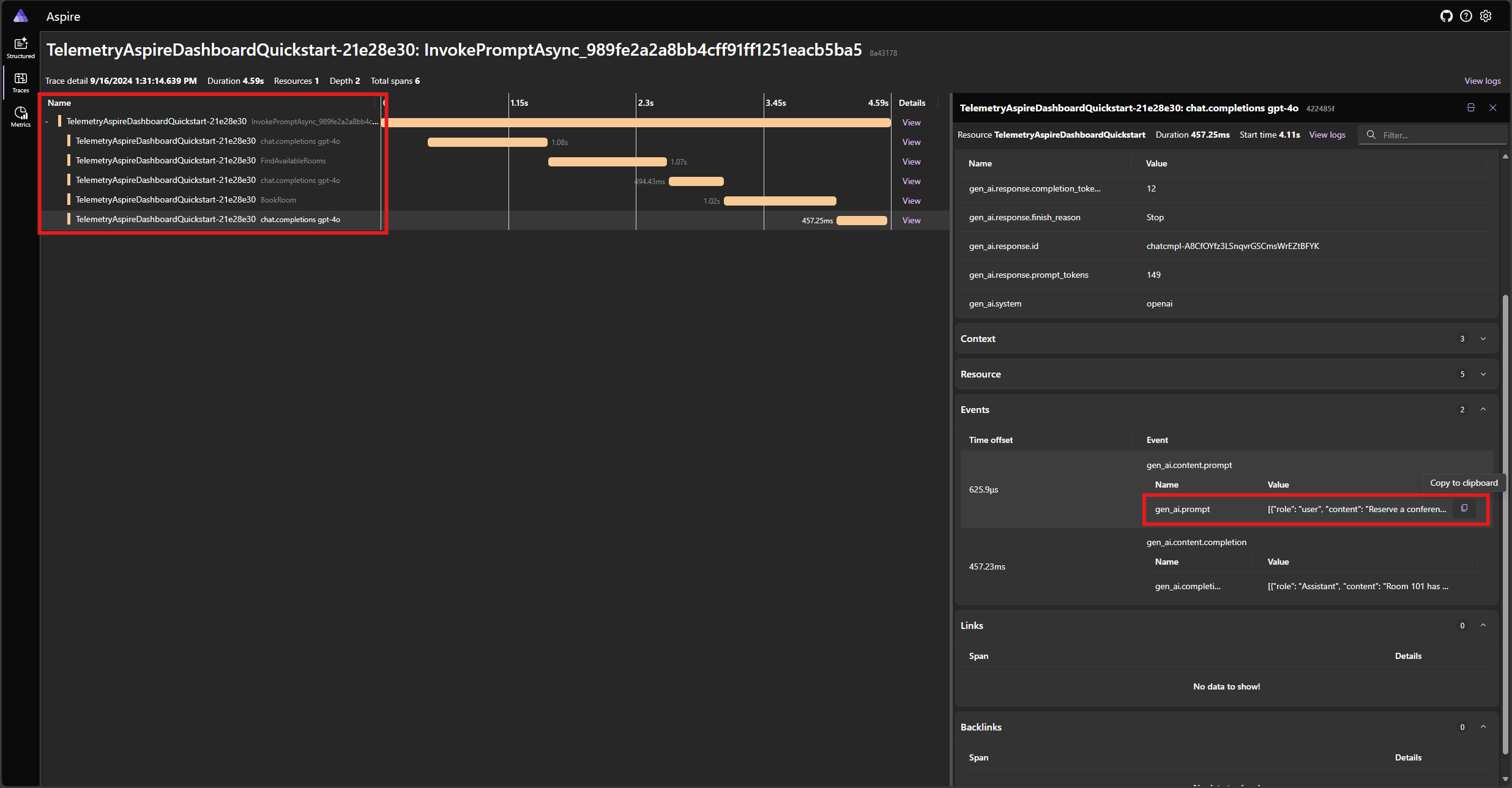
Questi 5 intervalli rappresentano le operazioni interne del kernel con chiamate di funzione automatica abilitate. Richiama innanzitutto il modello, che richiede una chiamata di funzione. Il kernel esegue quindi automaticamente la funzione FindAvailableRoomsAsync e restituisce il risultato al modello. Il modello richiede quindi un'altra chiamata di funzione per effettuare una prenotazione e il kernel esegue automaticamente la funzione BookRoomAsync e restituisce il risultato al modello. Infine, il modello restituisce una risposta in linguaggio naturale all'utente.
Se si fa clic sull'ultimo intervallo e si cerca il prompt nell'evento gen_ai.content.prompt , verrà visualizzato un aspetto simile al seguente:
[
{ "role": "user", "content": "Reserve a conference room for me today." },
{
"role": "Assistant",
"content": null,
"tool_calls": [
{
"id": "call_NtKi0OgOllJj1StLkOmJU8cP",
"function": { "arguments": {}, "name": "FindAvailableRooms" },
"type": "function"
}
]
},
{
"role": "tool",
"content": "[\u0022Room 101\u0022,\u0022Room 201\u0022,\u0022Room 301\u0022]"
},
{
"role": "Assistant",
"content": null,
"tool_calls": [
{
"id": "call_mjQfnZXLbqp4Wb3F2xySds7q",
"function": { "arguments": { "room": "Room 101" }, "name": "BookRoom" },
"type": "function"
}
]
},
{ "role": "tool", "content": "Room Room 101 booked." }
]
Questa è la cronologia delle chat che viene compilata come modello e il kernel interagiscono tra loro. Questo viene inviato al modello nell'ultima iterazione per ottenere una risposta in linguaggio naturale.
Trovare la traccia per l'applicazione nella scheda Tracce . È necessario cinque intervalli nella traccia raggruppata sotto l'intervallo AutoFunctionInvocationLoop :
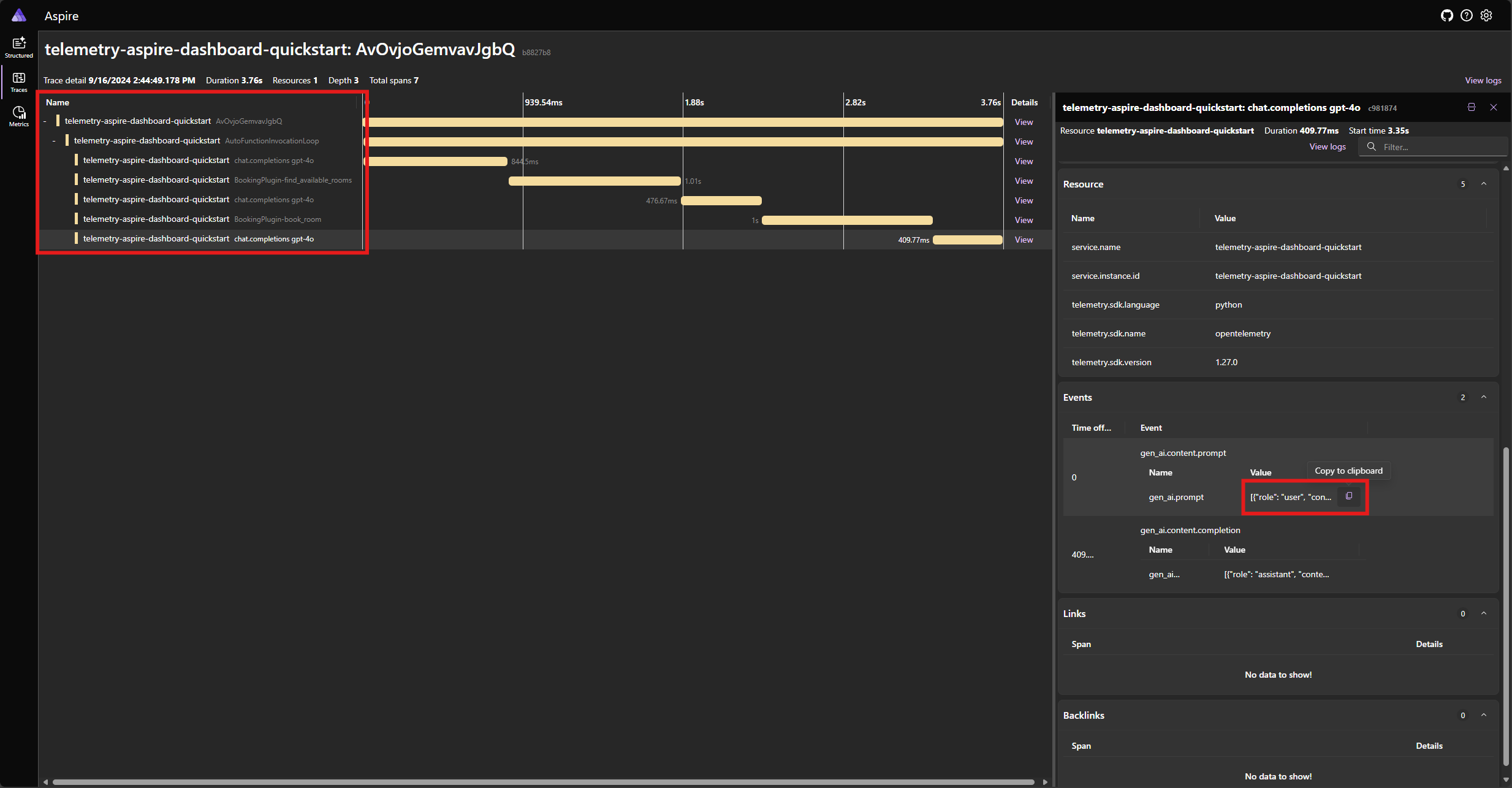
Questi 5 intervalli rappresentano le operazioni interne del kernel con chiamate di funzione automatica abilitate. Richiama innanzitutto il modello, che richiede una chiamata di funzione. Il kernel esegue quindi automaticamente la funzione find_available_rooms e restituisce il risultato al modello. Il modello richiede quindi un'altra chiamata di funzione per effettuare una prenotazione e il kernel esegue automaticamente la funzione book_room e restituisce il risultato al modello. Infine, il modello restituisce una risposta in linguaggio naturale all'utente.
Se si fa clic sull'ultimo intervallo e si cerca il prompt nell'evento gen_ai.content.prompt , verrà visualizzato un aspetto simile al seguente:
[
{ "role": "user", "content": "Reserve a conference room for me today." },
{
"role": "assistant",
"tool_calls": [
{
"id": "call_ypqO5v6uTRlYH9sPTjvkGec8",
"type": "function",
"function": {
"name": "BookingPlugin-find_available_rooms",
"arguments": "{}"
}
}
]
},
{
"role": "tool",
"content": "['Room 101', 'Room 201', 'Room 301']",
"tool_call_id": "call_ypqO5v6uTRlYH9sPTjvkGec8"
},
{
"role": "assistant",
"tool_calls": [
{
"id": "call_XDZGeTfNiWRpYKoHoH9TZRoX",
"type": "function",
"function": {
"name": "BookingPlugin-book_room",
"arguments": "{\"room\":\"Room 101\"}"
}
}
]
},
{
"role": "tool",
"content": "Room Room 101 booked.",
"tool_call_id": "call_XDZGeTfNiWRpYKoHoH9TZRoX"
}
]
Questa è la cronologia delle chat che viene compilata come modello e il kernel interagiscono tra loro. Questo viene inviato al modello nell'ultima iterazione per ottenere una risposta in linguaggio naturale.
Nota
L'osservabilità del kernel semantico non è ancora disponibile per Java.
Gestione degli errori
Se si verifica un errore durante l'esecuzione di una funzione, il kernel intercetta automaticamente l'errore e restituisce un messaggio di errore al modello. Il modello può quindi usare questo messaggio di errore per fornire una risposta in linguaggio naturale all'utente.
Modificare la BookRoomAsync funzione nel codice C# per simulare un errore:
[KernelFunction("BookRoom")]
[Description("Books a conference room.")]
public async Task<string> BookRoomAsync(string room)
{
// Simulate a remote call to a booking system.
await Task.Delay(1000);
throw new Exception("Room is not available.");
}
Eseguire di nuovo l'applicazione e osservare la traccia nel dashboard. Verrà visualizzato l'intervallo che rappresenta la chiamata di funzione del kernel con un errore:
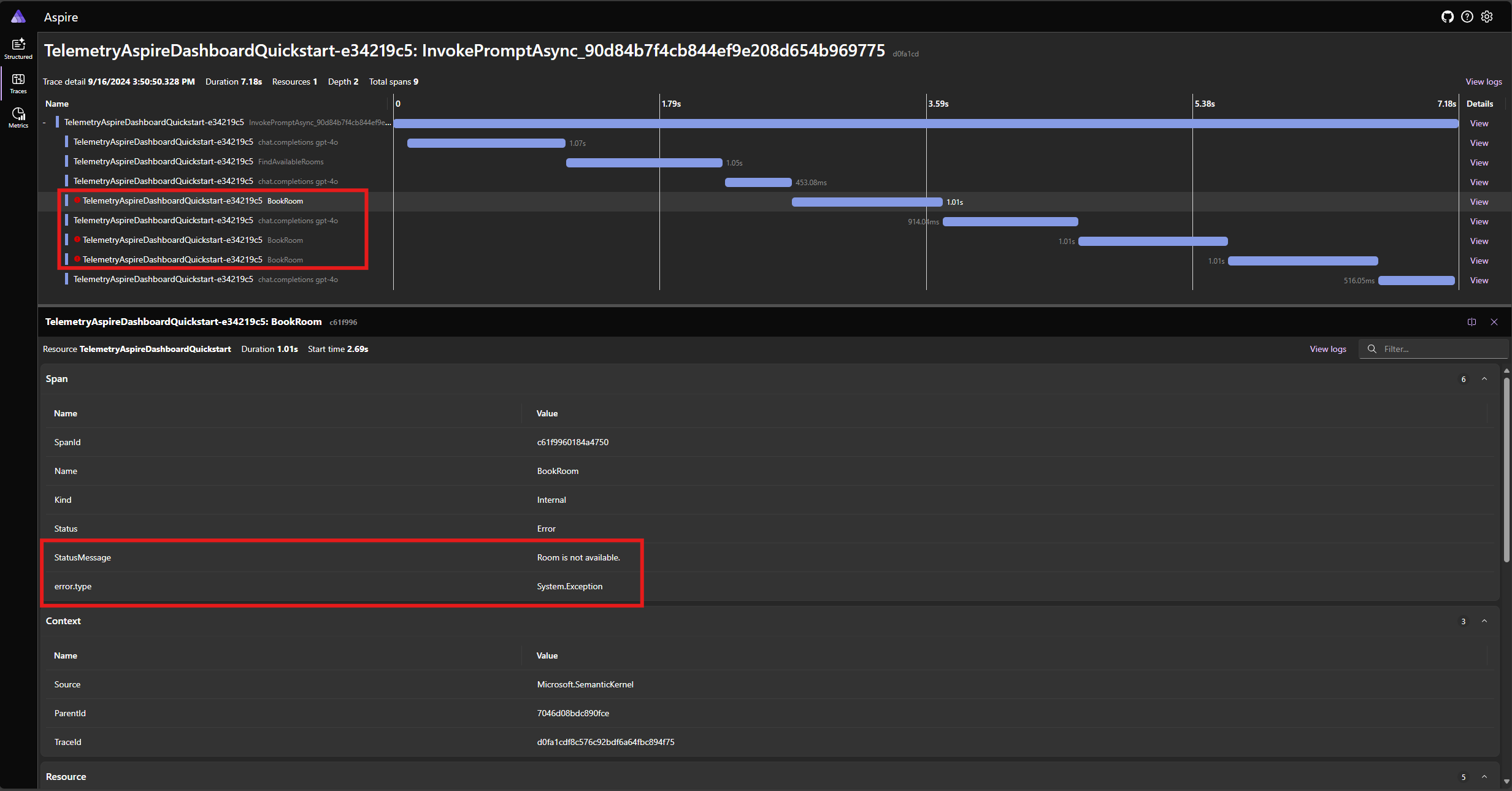
Nota
È molto probabile che le risposte del modello all'errore possano variare ogni volta che si esegue l'applicazione, perché il modello è stocastico. Si potrebbe vedere il modello riservando tutte e tre le camere contemporaneamente, o riservando una la prima volta, quindi riservando gli altri due la seconda volta, ecc.
Modificare la book_room funzione nel codice Python per simulare un errore:
@kernel_function(
name="book_room",
description="Book a conference room.",
)
async def book_room(self, room: str) -> Annotated[str, "A confirmation message."]:
# Simulate a remote call to a booking system
await asyncio.sleep(1)
raise Exception("Room is not available.")
Eseguire di nuovo l'applicazione e osservare la traccia nel dashboard. Verrà visualizzato l'intervallo che rappresenta la chiamata di funzione del kernel con un errore e l'analisi dello stack:
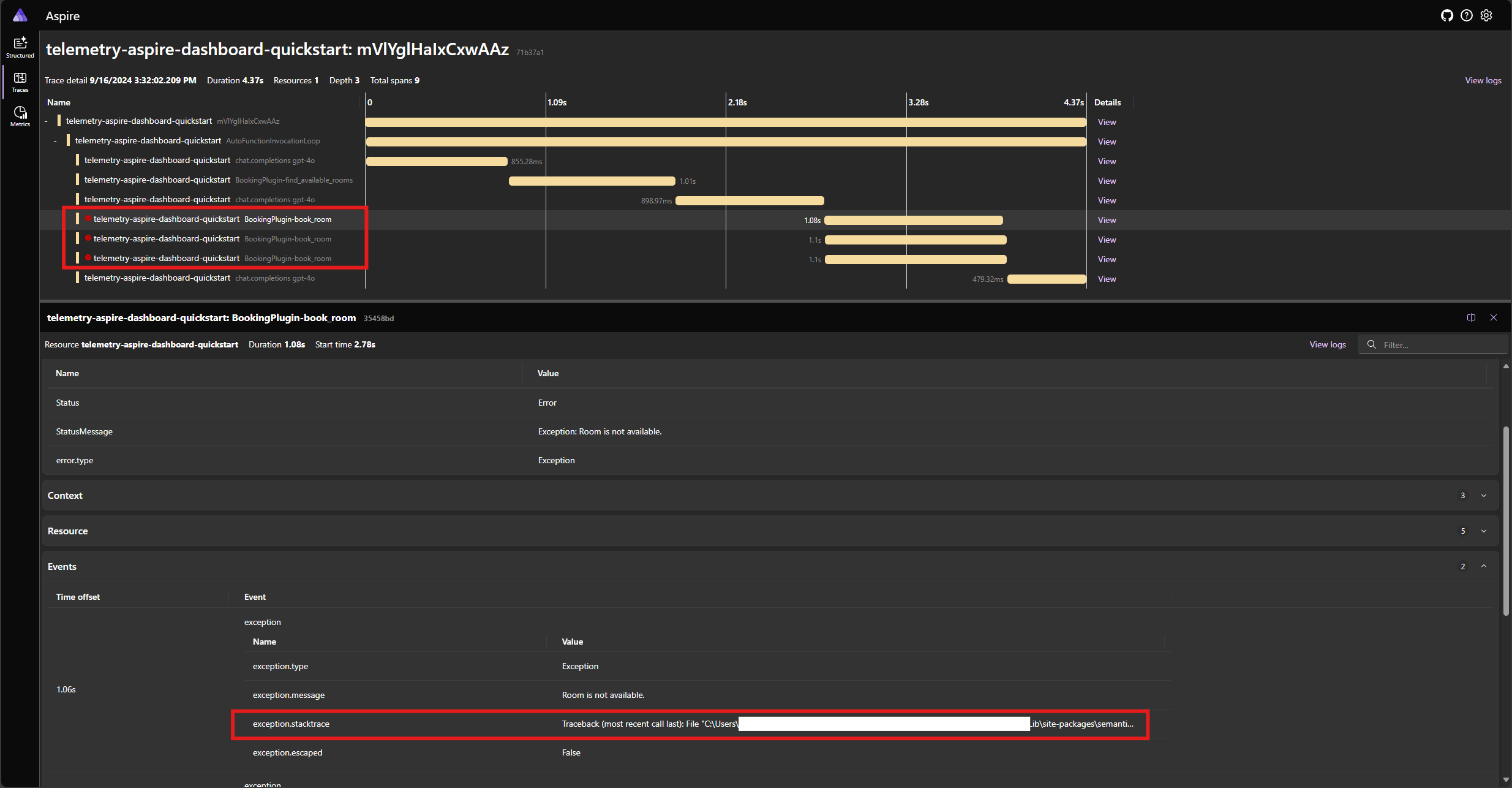
Nota
È molto probabile che le risposte del modello all'errore possano variare ogni volta che si esegue l'applicazione, perché il modello è stocastico. Si potrebbe vedere il modello riservando tutte e tre le camere contemporaneamente, o riservando una la prima volta, quindi riservando gli altri due la seconda volta, ecc.
Nota
L'osservabilità del kernel semantico non è ancora disponibile per Java.
Passaggi successivi e ulteriore lettura
Nell'ambiente di produzione, i servizi possono ottenere un numero elevato di richieste. Il kernel semantico genererà una grande quantità di dati di telemetria. alcuni dei quali potrebbero non essere utili per il caso d'uso e introdurranno costi non necessari per archiviare i dati. È possibile usare la funzionalità di campionamento per ridurre la quantità di dati di telemetria raccolti.
L'osservabilità nel kernel semantico è costantemente migliorata. È possibile trovare gli aggiornamenti più recenti e le nuove funzionalità nel repository GitHub.