Creare un'architettura e una strategia a disponibilità elevata per SharePoint Server
SI APPLICA A: 2013 2016 2019 Subscription Edition
2013 2016 2019 Subscription Edition  SharePoint in Microsoft 365
SharePoint in Microsoft 365
Una strategia di disponibilità elevata è un requisito importante per un ambiente di produzione SharePoint Server. Una strategia end-to-end include processi operativi, governance della piattaforma, architettura e soluzioni tecniche. In questo articolo vengono analizzati gli aspetti architetturali e tecnici della disponibilità elevata. Nelle indicazioni vengono illustrati specifici elementi di progettazione di SharePoint, nonché le opzioni tecniche che determineranno la strategia per la disponibilità elevata.
Nota
[!NOTA] Disponibilità elevata e ripristino di emergenza sono concetti diversi. Sebbene vi sia una sovrapposizione tra pianificazione e soluzioni, di fatto sono sottoinsiemi della continuità aziendale. Scopo della disponibilità elevata è fornire resilienza nell'ambito del data center principale e del tempo di inattività pianificato. Scopo del ripristino di emergenza è consentire all'organizzazione di riprendere le operazioni dei computer in un data center secondario quando un'emergenza nel data center principale rende l'infrastruttura inutilizzabile. Per informazioni sul ripristino di emergenza per SharePoint Server, vedere Scegliere una strategia di ripristino di emergenza per SharePoint Server.
Il termine "disponibilità elevata" viene in genere utilizzato per descrivere la capacità di un sistema di continuare a operare e fornire risorse agli utenti quando si verifica un errore in una o più delle seguenti categorie di un dominio di errore: hardware, software o applicazione. Il livello di disponibilità viene espresso come misura della percentuale di tempo per cui un sistema rimane operativo per supportare le funzioni aziendali. Il livello di disponibilità richiesto varia da un'organizzazione all'altra. Anche se questo requisito può variare tra le diverse business unit, un contratto di servizio considera l'organizzazione nel suo complesso. Dal punto di vista degli utenti, una farm di SharePoint è disponibile quando gli utenti possono accedere alla farm e usare le funzionalità e i servizi che devono avere per svolgere il proprio lavoro.
Una farm di SharePoint a disponibilità elevata presenta i seguenti obiettivi e caratteristiche:
La progettazione della farm riduce i potenziali punti di errore. Poiché è improbabile che sia possibile eliminarli tutti, la strategia complessiva deve essere rivolta alla gestione di un evento di errore.
Gli eventi di failover sono semplici da gestire e hanno un impatto minimo sulle attività degli utenti.
La farm non interrompe completamente le attività, ma continua a operare a capacità ridotta.
La farm è resiliente. Gli incidenti con impatto sul servizio sono rari e, nel caso in cui si verifichino, vengono adottate misure tempestive ed efficaci.
Introduzione
Prima di creare una strategia e un'architettura a disponibilità elevata per l'ambiente SharePoint in uso, è necessario definire e quantificare gli obiettivi in fatto di disponibilità. Questi obiettivi riflettono la misura in cui l'organizzazione dipende da SharePoint Server e l'impatto che una perdita di servizio può avere sulle operazioni dell'organizzazione. L'impatto della perdita di servizio dipende dalla natura (totale o parziale) e dalla durata della perdita stessa.
Una strategia di elevata disponibilità davvero efficiente deve riflettere le specifiche esigenze dell'organizzazione. Deve inoltre bilanciare in modo ottimale i processi aziendali e i contratti di servizio da un lato e la disponibilità di soluzioni tecniche, le funzionalità di supporto IT e i costi delle infrastrutture dall'altro.
Una volta identificati i requisiti di disponibilità dell'organizzazione, è possibile iniziare a creare una strategia e una progettazione a disponibilità elevata per ridurre il rischio di tempi di inattività e diminuzione delle operazioni. Per raggiungere gli obiettivi fissati, i professionisti IT che progettano e sviluppano sistemi a disponibilità elevata si attengono ai seguenti principi guida:
Eliminazione dei singoli punti di errore sia per ciascun dominio di errore sia per l'intero sistema a ogni possibile livello (sistema operativo, software e applicazione SharePoint).
Implementazione di soluzioni molto veloci per il rilevamento, l'isolamento e la risoluzione degli errori.
Le soluzioni a disponibilità elevata hanno un ambito vasto e forniscono un insieme di risorse condivise a livello di sistema che vengono integrate per fornire i servizi necessari predefiniti. La soluzione utilizza differenti combinazioni di elementi hardware e software per ridurre al minimo i tempi di inattività e ripristinare i servizi in caso di errore del sistema o di parte di esso.
Una soluzione a tolleranza di errore è basata su hardware e utilizza elementi appositamente creati per rilevare gli errori e attivare istantaneamente un componente ridondante. Tale componente può essere costituito da un processore, una scheda di memoria, un alimentatore o un sottosistema I/O o di archiviazione. L'attivazione di un componente ridondante assicura un elevato livello di servizio.
Un'analisi costi-benefici delle soluzioni a tolleranza di errore e di quelle a disponibilità elevata consente alle organizzazioni di creare una strategia per raggiungere gli obiettivi di disponibilità per la farm di SharePoint in uso. In genere, nella scelta tra le due soluzioni, a maggiori vantaggi corrisponde un aumento dei costi.
Il processo di implementazione di una soluzione a disponibilità elevata è uno degli investimenti più costosi per una farm di SharePoint. Con l'aumentare del livello di disponibilità e del numero di sistemi che si desidera rendere altamente disponibili, aumentano anche la complessità e il costo della soluzione a disponibilità elevata.
I progressi ottenuti nella tecnologia di virtualizzazione consentono alle organizzazioni di utilizzare computer virtuali come sistemi sostitutivi da attivare in modalità hot, warm o cold. I computer virtuali possono fornire le stesse funzionalità. La virtualizzazione può assicurare flessibilità e contenimento dei costi. È tuttavia necessario verificare che una macchina virtuale sia in grado di gestire il carico di lavoro del computer fisico che sostituisce.
Creare un'architettura di farm in grado di supportare la disponibilità elevata
Nella figura seguente viene mostrato in che modo è possibile distribuire e configurare diverse parti di un ambiente di SharePoint per aumentare la disponibilità di una farm. In questo esempio viene mostrato anche il modo in cui la ridondanza può gestire i domini di errore.
Nota
[!NOTA] L'esempio non è completo. Non vengono infatti mostrati tutti i domini di errore e i componenti hardware a tolleranza di errore.
Esempi di ridondanza in una topologia di farm per gestire i punti di errore
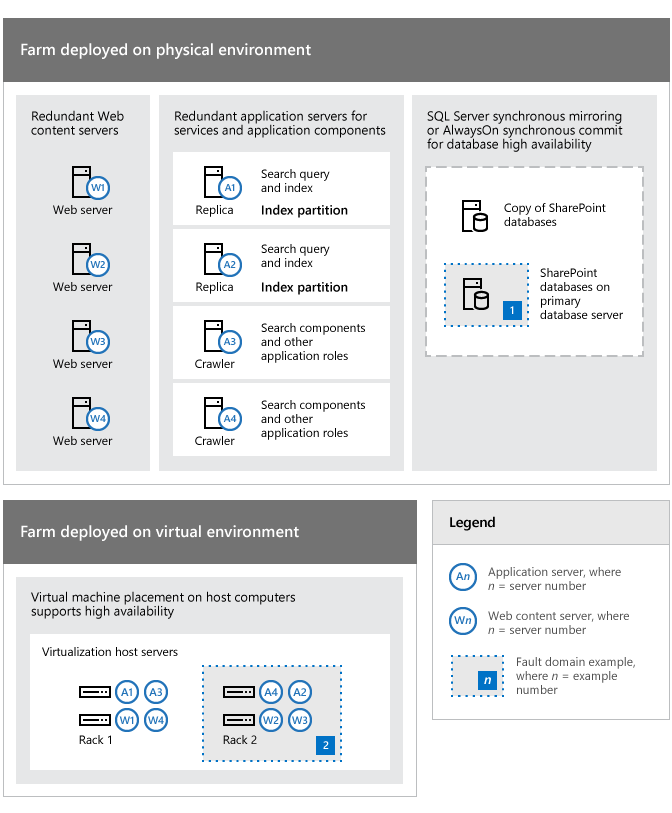
Facendo riferimento alla topologia illustrata nella figura precedente, notare quanto segue:
Nell'esempio, i server della farm possono essere computer fisici o macchine virtuali distribuite su server host Hyper-V. Il principio di identificazione e risposta ai punti di errore è valido per entrambi i tipi di ambiente.
Per la distribuzione di contenuto vengono utilizzati quattro server (W1-W4) e questa ridondanza aumenta la disponibilità in caso di errore di uno o più server. Questo livello di ridondanza consente alla farm di continuare le operazioni anche durante l'esecuzione di aggiornamenti software.
Quattro server applicazioni (A1-A4) migliorano la disponibilità di servizi della farm e componenti di applicazioni specifiche, ad esempio di ricerca. Componenti e ruoli di ricerca sono ridondanti.
I server di database della farm sono ridondanti e l'elevata disponibilità dei database può essere ottenuta utilizzando il mirroring o il clustering dei database stessi.
In un ambiente virtuale le macchine virtuali si trovano su server host Hyper-V separati per eliminare un singolo punto di errore. Questo approccio al posizionamento delle macchine virtuali segue le linee guida delle procedure consigliate per la disponibilità e le prestazioni.
Il server di database principale (indicato con 1) e il rack 2 (indicato con 2), contenente due dei computer host di virtualizzazione, sono identificati come domini di errore per mostrare il modo in cui la farm e l'infrastruttura possono essere considerate come una raccolta di domini di errore. Questo mostra come eseguire un'analisi approfondita dell'ambiente in uso per sviluppare una strategia complessiva e una valutazione del rapporto costi/benefici.
Altri ruoli e servizi della farm
Nell'esempio non sono inclusi tutti i ruoli, i servizi e le applicazioni di servizio che possono essere eseguiti in una specifica farm di SharePoint. Non è possibile adottare un approccio generico alla disponibilità elevata per tutti gli elementi di una farm di SharePoint. Di seguito sono riportate alcune importanti esclusioni all'utilizzo di un approccio standard alla disponibilità elevata:
Per il servizio cache distribuita sono necessarie considerazioni speciali durante il failover. Per ulteriori informazioni, vedere Pianificare il servizio cache distribuita e Gestire il servizio cache distribuita in SharePoint Server.
Il flusso di lavoro di SharePoint richiede l'aggiornamento cumulativo 3 per Workflow Manager 1.0. Configurare per SharePoint Server 2016 lo stesso flusso di lavoro per SharePoint Server 2013. Per ulteriori informazioni, vedere Descrizione dell'aggiornamento cumulativo 3 per Workflow Manager 1.0 e Configurazione di un'istanza di Workflow a disponibilità elevata in Gestione flusso di lavoro 1.0.
Nota
[!NOTA] La configurazione del flusso di lavoro per SharePoint Server 2016 non è cambiata da SharePoint Server 2013. È necessario installare l'aggiornamento cumulativo 3 per Workflow Manager 1.0.
Anche se le applicazioni di servizio possono essere eseguite su più computer (pratica consigliata), alcune hanno requisiti di installazione e configurazione univoci per quanto riguarda la disponibilità elevata. L'applicazione Profili utente è un esempio ben conosciuto.
Utilizzare la tolleranza di errore nella soluzione a disponibilità elevata
Dopo aver progettato un'architettura in grado di supportare ruoli e carichi di lavoro a disponibilità elevata, è possibile utilizzare componenti a tolleranza di errore per aumentare la disponibilità. Le soluzioni a tolleranza di errore sono disponibili nell'intera infrastruttura, inclusi i database.
Infrastruttura a tolleranza di errore
La tolleranza di errore è immediatamente disponibile per quasi tutti i componenti hardware dell'infrastruttura di una farm di SharePoint. Come parte del progetto a disponibilità elevata, è importante determinare quali parti dell'infrastruttura devono essere a tolleranza di errore, eseguendo la valutazione da un punto di vista operativo ed economico. Il fatto che sia possibile rendere a tolleranza di errore ogni parte dell'infrastruttura non implica la necessità di tale scelta.
Server e database a tolleranza di errore
Poiché la piattaforma SharePoint e i carichi di lavoro delle relative applicazioni dipendono dalla disponibilità e dall'affidabilità di tutti i database di SharePoint, i database a disponibilità elevata rappresentano un aspetto estremamente importante della strategia a disponibilità elevata. È possibile utilizzare le seguenti funzionalità come soluzioni a tolleranza di errore per server di database e database di SharePoint:
Clustering di failover di SQL Server (istanze del cluster di failover Always On in SQL Server 2014 con Service Pack 1 (SP1)) e SQL Server 2012
Gruppi di disponibilità AlwaysOn
Mirroring di database a disponibilità elevata SQL Server
Informazioni sulle istanze del cluster di failover AlwaysOn e sui gruppi di disponibilità AlwaysOn
Per un cluster di failover è necessario spazio di archiviazione su disco condiviso tra due computer. In una configurazione a due nodi, i computer sono configurati come attivo/passivo, scelta che fornisce un'istanza completamente ridondante sul nodo principale. Il nodo passivo viene portato online solo in caso di errore del nodo principale. Il disco condiviso viene reso disponibile a un solo computer alla volta. Tipicamente, per questa configurazione è richiesto il numero maggiore di componenti hardware aggiuntivi. In SQL Server 2014 (SP1) e SQL Server 2012 questo tipo di configurazione del cluster è un'istanza del cluster di failover AlwaysOn ed è un modo specifico per installare SQL Server. A causa dei requisiti della configurazione, non è possibile implementare un'installazione standard di SQL Server e modificarla facilmente in una FCI (Failover Cluster Instance).
Un gruppo di disponibilità Always On è una tecnologia diversa in SQL Server 2014 (SP1) e SQL Server 2012 (si consideri un discendente del mirroring del database) che usa alcune funzionalità esposte da Clustering Windows. Questa tecnologia, tuttavia, non richiede uno spazio di archiviazione su disco condiviso e sui computer di un gruppo di disponibilità non è necessario che sia installata una configurazione speciale di SQL Server. Dopo l'aggiunta di un server di database a un cluster Windows, è abbastanza semplice abilitare i gruppi di disponibilità AlwaysOn e quindi configurare il gruppo di disponibilità desiderato.
In sintesi, qualsiasi server che esegue SQL Server 2014 (SP1) e SQL Server 2012 Enterprise Edition può usare i gruppi di disponibilità AlwaysOn aggiungendo un cluster e configurando il gruppo di disponibilità. I cluster di failover AlwaysOn richiedono passaggi hardware e di configurazione speciali per configurare istanze del cluster di failover. Ognuna di queste tecnologie ha il suo uso per ambienti specifici, ed entrambi sono concorrenti complementari. Per ulteriori informazioni su queste funzionalità, vedere Soluzioni a disponibilità elevata (SQL Server). Per informazioni su quale tecnologia di disponibilità di SQL Server usare, vedere Continuità aziendale e ripristino del database - SQL Server.
Importante
[!IMPORTANTE] Poiché ciascuna opzione SQL Server a disponibilità elevata presenta funzionalità, punti di forza e punti di debolezza specifici, un'opzione non è necessariamente migliore di un'altra. Ad esempio, in un determinato scenario che usa gruppi di disponibilità Always On, ridurre al minimo la perdita di dati potrebbe essere migliore di qualsiasi miglioramento delle prestazioni ottenuto da Istanze del cluster di failover AlwaysOn. È necessario scegliere una soluzione a disponibilità elevata sulla base delle specifiche necessità dell'azienda e dei requisiti dell'infrastruttura IT.
I database di SharePoint costituiscono un fattore determinante nella selezione di un'opzione SQL Server. È necessario comprendere le caratteristiche dei database di SharePoint Server. Ciascun database può avere requisiti o vincoli specifici che determineranno la soluzione SQL Server a tolleranza di errore appropriata e completamente supportata nell'ambiente di produzione. Si consiglia di fare riferimento ai seguenti articoli:
Tipi di database e relative descrizioni in SharePoint Server
Opzioni di disponibilità elevata e di ripristino di emergenza supportate per database di SharePoint
Clustering di failover di SQL Server
Cluster di failover offre supporto alla disponibilità per un'istanza di SQL Server su SQL Server 2014 (SP1) o SQL Server 2012.
Un cluster di failover è una combinazione di uno o più nodi o server e di due o più dischi condivisi. Anche se un'istanza di cluster di failover viene visualizzata come un unico computer, tale istanza fornisce il failover da un nodo all'altro nel caso in cui quello corrente non sia più disponibile. È possibile eseguire SharePoint Server su qualsiasi combinazione di nodi attivi e passivi in un cluster supportato da SQL Server.
In SharePoint Server il cluster viene considerato un tutto unico. Di conseguenza, in SharePoint Server il failover è un'operazione automatica e semplice.
Nota
Quando si verifica un failover, pianificato o meno, le connessioni vengono interrotte ed è necessario ripristinarle durante la transizione da un nodo di cluster all'altro.
Per informazioni dettagliate sul clustering di failover di SQL Server, vedere Istanze del cluster di failover AlwaysOn (SQL Server).
Gruppi di disponibilità AlwaysOn di SQL Server e mirroring del database di SQL Server
Il vantaggio principale dei gruppi di disponibilità Always On di SQL Server e del mirroring del database di SQL Server è che offrono ridondanza dei dati completa o quasi completa a seconda di come vengono configurati per l'elaborazione delle transazioni. Oltre a ridurre al minimo la perdita di dati, il failover automatico diminuisce sensibilmente il tempo di inattività per i database di produzione.
Importante
Anche se SQL Server 2016, SQL Server 2014 (SP1) e SQL Server 2012 supportano il mirroring del database, questa funzionalità è pianificata per essere deprecata. È consigliabile evitare di usare questa funzionalità nelle nuove attività di sviluppo. Pianificare la modifica delle applicazioni che attualmente usano questa funzionalità. Usare invece i gruppi di disponibilità AlwaysOn.
Gruppi di disponibilità AlwaysOn
La funzionalità Gruppi di disponibilità Always On di SQL Server è una soluzione a disponibilità elevata e ripristino di emergenza che offre un'alternativa a livello aziendale al mirroring del database. I gruppi di disponibilità Always On supportano un ambiente di failover per uno o più database utente contenuti in una raccolta definita dall'utente. Questa raccolta, ovvero un gruppo di disponibilità, è costituita dai seguenti componenti:
Repliche, ovvero un set discreto di database utente, denominati database di disponibilità, gestiti come singola unità. Un gruppo di disponibilità supporta una replica primaria e un massimo di quattro repliche secondarie.
Un'istanza specifica di SQL Server per ospitare ogni replica e mantenere una copia locale di ogni database appartenente al gruppo di disponibilità.
Quando viene eseguito il failover di un gruppo di disponibilità a un'istanza di destinazione o a un server di destinazione, viene eseguito il failover anche di tutti i database del gruppo. Poiché SQL Server 2014 (SP1) e SQL Server 2012 possono ospitare più gruppi di disponibilità in un singolo server, è possibile configurare Always On per il failover alle istanze di SQL Server in server diversi. In tal modo si riduce la necessità di disporre di server di standby ad alte prestazioni inattivi per gestire l'intero carico del server primario e questo è uno dei principali vantaggi derivanti dall'utilizzo di gruppi di disponibilità.
Nota
I problemi relativi a un database, che ad esempio diventa sospetto a seguito della perdita di un file di dati, dell'eliminazione di un database o del danneggiamento di un log delle transazioni, non causano un failover.
Per altre informazioni sui vantaggi offerti dai gruppi di disponibilità Always On e una panoramica della terminologia dei gruppi di disponibilità Always On, vedere Gruppi di disponibilità AlwaysOn (SQL Server).
Mirroring di database
Nota
Anche se SQL Server 2016, SQL Server 2014 (SP1) e SQL Server 2012 supportano il mirroring del database, questa funzionalità è pianificata per essere deprecata. È consigliabile evitare di usare questa funzionalità nelle nuove attività di sviluppo. Pianificare la modifica delle applicazioni che attualmente usano questa funzionalità. Usare invece i gruppi di disponibilità AlwaysOn.
Il mirroring di database fornisce la ridondanza dei database mantenendo una copia con mirroring dei database stessi sul server di database principale. Il mirroring viene implementato per i singoli database e funziona soltanto per quelli che utilizzano il modello di recupero con registrazione completa.
Nota
Esistono due modalità operative di mirroring. Una, la modalità ad alta sicurezza, opera in modo sincrono. Nella modalità ad alta sicurezza, quando si avvia una sessione, il server mirror sincronizza il database mirror e quello principale il più velocemente possibile. Non appena i database sono sincronizzati, viene scritta una transazione nel log del server secondario e tale transazione viene poi replicata. Il controllo torna al server principale non appena la transazione viene avanzata. L'altra modalità di mirroring è a prestazioni elevate, che usa l'operazione asincrona per ridurre la latenza delle transazioni, a costo di una maggiore perdita di dati.
In una farm di SharePoint per il mirroring a disponibilità elevata è necessario utilizzare la modalità ad alta sicurezza con failover automatico. Per il mirroring ad alta sicurezza dei database sono necessarie tre istanze di server: una principale, una mirror e una di controllo. Il server di controllo consente a SQL Server di eseguire automaticamente il failover dal server principale al server mirror. In genere, per il failover dal database principale a quello mirror sono necessari alcuni secondi.
Per informazioni di carattere generale sul mirroring di database, vedere Mirroring di database.
Importante
Non è possibile eseguire il mirroring di database configurati per l'utilizzo del provider di archivi BLOB remoti FILESTREAM di SQL Server
Confronto tra strategie di disponibilità e ripristino dei database per una singola farm
La scelta di una tecnologia SQL Server per la disponibilità elevata e il ripristino di emergenza dovrebbe essere basata sugli obiettivi aziendali in termini di punto di ripristino (RPO, Recovery Point Objective) e di tempo di ripristino (RTO, Recovery Time Objective). Anche se i parametri RPO e RTO sono normalmente associati al ripristino di emergenza, alcuni eventi di errore che esulano dall'ambito di un'emergenza richiedono il ripristino da supporti di backup locali al data center principale.
Importante
[!IMPORTANTE] A seconda del particolare database, diversi database di SharePoint Server supportano soltanto specifiche opzioni SQL Server a disponibilità elevata. Per ulteriori informazioni, vedere Opzioni di disponibilità elevata e di ripristino di emergenza supportate per database di SharePoint.
Nella tabella seguente viene presentato un confronto generale tra i risultati RPO e RTO ottenuti dalle soluzioni SQL Server disponibili.
Nota
[!NOTA] I tempi indicati nella tabella hanno lo scopo di mettere a confronto le opzioni di database. In pratica, tutti i tempi indicati dipendono dal carico di lavoro, dal volume di dati e dalle procedure di failover.
Confronto tra RPO e RTO in base alla tecnologia di database
| Soluzione SQL Server | Potenziale perdita di dati (RPO) | Potenziale tempo di ripristino (RTO) | Failover automatico |
Secondari leggibili Nota: SharePoint Server supporta repliche secondarie leggibili per l'utilizzo del runtime. Per altre informazioni, vedere Aggiornamento cumulativo di Office 2013 per aprile 2014 ed Eseguire una farm che usa database di sola lettura in SharePoint Server. |
|---|---|---|---|---|
| Gruppo di disponibilità Always On (commit sincrono) |
Zero |
Secondi |
Sì |
0 - 2 |
| Gruppo di disponibilità Always On (commit asincrono) |
Secondi |
Minuti |
No |
0 - 4 |
| Istanza del cluster di failover AlwaysOn |
Non applicabile Una FCI non fornisce protezione dei dati. L'entità della perdita di dati dipende dall'implementazione del sistema di archiviazione. |
Da secondi a minuti |
Sì |
Non applicabile |
| Mirroring di database - Alta sicurezza (modalità sincrona + server di controllo) |
Zero |
Secondi |
Sì |
Non applicabile |
| Mirroring di database - Elevate prestazioni (modalità asincrona) |
Secondi |
Minuti |
No |
Non applicabile |
| Backup, copia, ripristino |
Ore o zero se dopo l'errore è possibile accedere alla coda del log. |
Da ore a giorni |
No |
Non durante un ripristino |
Confronto tra cluster SQL Server, gruppo di disponibilità AlwaysOn e mirror del database
| Procedura | Cluster di failover di SQL Server | Gruppo di disponibilità Always On di SQL Server 2014 (SP1) e SQL Server 2012 | Mirroring a disponibilità elevata di SQL Server |
|---|---|---|---|
| Tempo prima del failover |
Il membro del cluster subentra quasi immediatamente dopo l'errore. Durante l'attivazione del nodo del cluster, si verifica un rallentamento. |
La replica subentra quasi immediatamente dopo l'errore. Durante l'attivazione della replica secondaria, si verifica un rallentamento. |
Il mirror subentra non appena la coda di ripetizione viene elaborata. |
| Coerenza transazionale |
Sì |
Sì |
Sì |
| Concorrenza transazionale |
Sì |
Sì |
Sì |
| Tempo prima del ripristino |
Tempo prima del ripristino più breve rispetto al gruppo di disponibilità. |
Tempo prima del ripristino maggiore rispetto a un cluster di failover, ma più breve rispetto a una soluzione con mirroring. |
Tempo prima del ripristino leggermente maggiore rispetto a un cluster o a un gruppo di disponibilità. |
| Passaggi necessari per il failover |
I nodi del database rilevano automaticamente un errore. SharePoint Server fa riferimento al cluster in modo che il failover venga eseguito automaticamente e senza problemi. |
Il listener del gruppo di disponibilità rileva automaticamente un errore e il failover viene eseguito automaticamente e senza problemi. |
Il database rileva automaticamente un errore. SharePoint Server conosce la posizione del server mirror, se quest'ultimo è stato configurato in modo corretto per l'esecuzione automatica del failover. |
| Protezione da errori di archiviazione |
Il cluster di failover non fornisce la protezione dei dati. L'entità della perdita di dati dipende dall'implementazione del sistema di archiviazione. In un ambiente SAN, ad esempio, sono presenti componenti ridondanti quali numerosi percorsi file, RAID e riserve a caldo. |
Protegge dagli errori di archiviazione perché la replica primaria scrive nei dischi locali sulle repliche secondarie. |
Protegge dagli errori di archiviazione perché sia il server di database principale sia il server mirror scrivono nei dischi locali. |
| Tipi di archiviazione supportati |
Richiede una soluzione di archiviazione condivisa, più costosa di una dedicata. |
Può utilizzare soluzioni di archiviazione collegate direttamente, meno costose. |
Può utilizzare soluzioni di archiviazione collegate direttamente, meno costose. |
| Requisiti per il percorso |
I membri del cluster devono trovarsi nella stessa subnet. Note: Non si applica a SQL Server 2014 (SP1) e SQL Server 2012. |
Le repliche possono trovarsi su subnet diverse, poiché la latenza non determina problemi di prestazioni. |
I server principale, mirror e di controllo devono trovarsi sulla stessa LAN (fino a 1 millisecondo di latenza round trip). |
| Modello di ripristino |
Si consiglia il modello di recupero con registrazione completa di SQL Server. È possibile utilizzare il modello di recupero con registrazione minima di SQL Server. Tuttavia, in caso di errore del cluster, l'unico punto di ripristino disponibile è l'ultimo backup completo. |
Richiede il modello di recupero con registrazione completa di SQL Server 2014 (SP1) e SQL Server 2012. |
Richiede il modello di recupero con registrazione completa di SQL Server. |
| Sovraccarico delle prestazioni |
Durante un failover è possibile che si verifichi un peggioramento delle prestazioni. Per la durata del failover il server non sarà disponibile e le connessioni verranno interrotte, per essere poi ristabilite sul nuovo nodo attivo. |
I gruppi di disponibilità Always On introducono la latenza transazionale a causa del commit sincrono nelle repliche secondarie. L'entità della latenza dipende dal numero di repliche secondarie da sincronizzare. Il sovraccarico della memoria e del processore è maggiore rispetto al clustering ma minore rispetto al mirroring. |
Poiché avviene in modalità sincrona, il mirroring a disponibilità elevata determina una latenza transazionale. Richiede inoltre memoria aggiuntiva e causa un sovraccarico del processore. |
| Sovraccarico operativo |
Impostato e gestito a livello di server. |
Il sovraccarico operativo è maggiore rispetto al clustering e al mirroring. Always On richiede un sovraccarico a livello di server di database di SQL Server oltre al livello di Windows Server. Nota: gli oggetti di livello server, quali account di accesso e processi agente, devono essere gestiti manualmente. Se si aggiungono database del contenuto, è necessario aggiungerli a un gruppo di disponibilità e quindi sincronizzare la replica primaria con quelle secondarie. In un ambiente farm di SharePoint sono necessari diversi passaggi di configurazione per garantire che la stringa di connessione di SharePoint Server venga associata correttamente al nome del listener del gruppo di disponibilità. |
Il sovraccarico operativo è maggiore rispetto al clustering. Deve essere impostato e gestito per tutti i database. La riconfigurazione dopo il failover è manuale. Nota: gli oggetti di livello server, quali account di accesso e processi agente, devono essere gestiti manualmente. Se si aggiungono database del contenuto, è necessario aggiungerli al server principale e quindi sincronizzare quest'ultimo con il server mirror. |
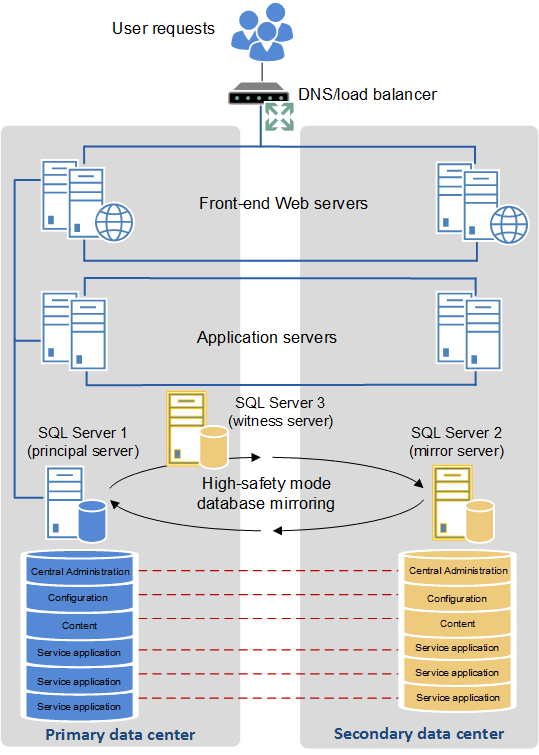
Configurare due data center come singola farm (farm "estesa") per fornire disponibilità elevata
Alcune organizzazioni hanno data center che si trovano a breve distanza l'uno dall'altro, connessi da collegamenti in fibra ottica con larghezza di banda elevata. Quando questo ambiente è disponibile, è possibile configurare i due data center come una singola farm. Questa topologia distribuita di farm è denominata farm "estesa".
Per consentire a un'architettura di farm estesa di operare come una soluzione a disponibilità elevata supportata, è necessario che siano soddisfatti i requisiti seguenti:
Presenza di una latenza intra-farm altamente coerente pari a <1 ms (unidirezionale), 99,9% del tempo durante un periodo di dieci minuti. La latenza intra-farm è comunemente definita come latenza tra i server Web front-end e i server di database.
La velocità della larghezza di banda deve essere di almeno 1 gigabit al secondo.
Per fornire la tolleranza di errore in una farm estesa, seguire le indicazioni sulle procedure consigliate per la configurazione di applicazioni di servizio e database ridondanti.
Nella figura riportata di seguito è illustrata una farm estesa.
Farm estesa
Integrare operazioni di backup e ripristino in una strategia di disponibilità elevata
Nella strategia di disponibilità elevata è necessario includere le operazioni di backup e ripristino appropriate per garantire che la farm di SharePoint sia resiliente. Quando si verifica un incidente, ad esempio un errore su un supporto o un errore utente, è necessario essere in grado di ripristinare in modo tempestivo le parti interessate dell'ambiente farm o dei dati della farm. Una soluzione di backup e ripristino efficiente deve consentire di raggiungere gli obiettivi RTO (Recovery Time Objective) e RPO (Recovery Point Objective) definiti.
Vedere anche
Concetti
Concetti relativi a ripristino di emergenza e disponibilità elevata in SharePoint Server
Scegliere una strategia di ripristino di emergenza per SharePoint Server