Distribuire un cluster Big Data di SQL Server in modalità Active Directory
Questo articolo descrive come distribuire un cluster Big Data di SQL Server in modalità Active Directory. La procedura descritta in questo articolo richiede l'accesso a un dominio di Active Directory. Prima di procedere, è necessario soddisfare i requisiti indicati in Distribuire cluster Big Data di SQL Server in modalità Active Directory.
Importante
Il componente aggiuntivo per i cluster Big Data di Microsoft SQL Server 2019 verrà ritirato. Il supporto per i cluster Big Data di SQL Server 2019 terminerà il 28 febbraio 2025. Tutti gli utenti esistenti di SQL Server 2019 con Software Assurance saranno completamente supportati nella piattaforma e fino a quel momento il software continuerà a ricevere aggiornamenti cumulativi di SQL Server. Per altre informazioni, vedere il post di blog relativo all'annuncio e Opzioni per i Big Data nella piattaforma Microsoft SQL Server.
Preparare la distribuzione
Per la distribuzione di un cluster Big Data con l'integrazione di Active Directory, è necessario fornire alcune informazioni aggiuntive per la creazione degli oggetti correlati ai cluster Big Data in Active Directory.
Usando il profilo kubeadm-prod (o openshift-prod a partire dalla versione CU5), verranno automaticamente immessi i segnaposto per le informazioni relative alla sicurezza e all'endpoint necessarie per l'integrazione di Active Directory.
Inoltre, è necessario fornire le credenziali che verranno usate dai cluster Big Data per creare gli oggetti necessari in Active Directory. Queste credenziali vengono fornite come variabili di ambiente.
Traffico e porte
Verificare che tutti i firewall o le applicazioni di terze parti consentano le porte necessarie per la comunicazione con Active Directory.
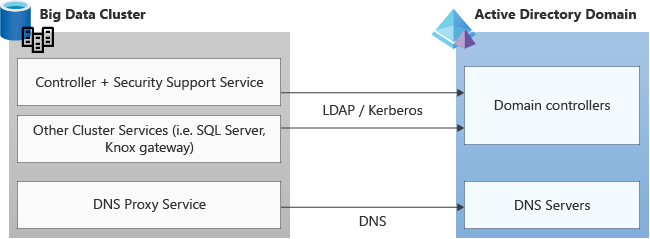
Le richieste vengono effettuate su questi protocolli da e verso i servizi cluster Kubernetes al dominio di Active Directory e di conseguenza devono essere consentite in ingresso e in uscita in qualsiasi firewall o applicazione di terze parti in ascolto sulle porte necessarie per TCP e UDP. Numeri di porta standard usati da Active Directory:
| Service | Porta |
|---|---|
| DNS | 53 |
| LDAP LDAPS |
389 636 |
| Kerberos | 88 |
| Protocollo di modifica password Kerberos/Active Directory | 464 |
| Porta del catalogo globale tramite LDAP tramite LDAPS |
3268 3269 |
Impostare le variabili di ambiente di sicurezza
Le variabili di ambiente seguenti forniscono le credenziali per l'account del servizio di dominio dei cluster Big Data, che verrà usato per configurare l'integrazione di Active Directory. Questo account viene usato anche dai cluster Big Data per gestire gli oggetti di Active Directory correlati in futuro.
export DOMAIN_SERVICE_ACCOUNT_USERNAME=<AD principal account name>
export DOMAIN_SERVICE_ACCOUNT_PASSWORD=<AD principal password>
Fornire parametri di sicurezza e dell'endpoint
Oltre alle variabili di ambiente per le credenziali, è necessario fornire anche le informazioni sulla sicurezza e sull'endpoint per il funzionamento dell'integrazione di Active Directory. I parametri necessari sono inclusi automaticamente nel profilo di distribuzione kubeadm-prod/openshift-prod.
Per l'integrazione di Active Directory sono necessari i parametri seguenti. Aggiungere questi parametri ai file control.json e bdc.json usando i comandi config replace mostrati più avanti in questo articolo. Tutti gli esempi seguenti usano il dominio di esempio contoso.local.
security.activeDirectory.ouDistinguishedName: nome distinto di un'unità organizzativa (OU) in cui verranno aggiunti tutti gli account Active Directory creati tramite la distribuzione del cluster. Se il dominio è denominatocontoso.local, il nome distinto dell'unità organizzativa è:OU=BDC,DC=contoso,DC=local.security.activeDirectory.dnsIpAddresses: contiene l'elenco di indirizzi IP dei server DNS del dominio.security.activeDirectory.domainControllerFullyQualifiedDns: elenco di FQDN del controller di dominio. Il nome di dominio completo contiene il nome computer/host del controller di dominio. Se sono presenti più controller di dominio, è possibile fornirne un elenco qui. Esempio:HOSTNAME.CONTOSO.LOCAL.Importante
Quando più controller di dominio gestiscono un dominio, usare il controller di dominio primario (PDC) come prima voce nell'elenco
domainControllerFullyQualifiedDnsdella configurazione di sicurezza. Per ottenere il nome PDC, digitarenetdom query fsmonel prompt dei comandi, quindi premere INVIO.security.activeDirectory.realmParametro facoltativo: nella maggior parte dei casi, l'area di autenticazione corrisponde al nome di dominio. Per i casi in cui sono diversi, usare questo parametro per definire il nome dell'area di autenticazione, ad esempioCONTOSO.LOCAL. Il valore specificato per questo parametro deve essere completo.security.activeDirectory.netbiosDomainNameParametro facoltativo: si tratta del nome NETBIOS del dominio di Active Directory. Nella maggior parte dei casi, sarà la prima etichetta del nome di dominio di Active Directory. Per i casi in cui differisce, usare questo parametro per definire il nome di dominio NETBIOS. Questo valore non deve contenere punti. In genere questo nome viene usato per qualificare gli account utente nel dominio. Ad esempio, CONTOSO\user, dove CONTOSO è il nome di dominio NETBIOS.Nota
Il supporto per una configurazione in cui il nome di dominio di Active Directory è diverso dal nome NETBIOS del dominio di Active Directory usando security.activeDirectory.netbiosDomainName è disponibile a partire da SQL Server 2019 CU9.
security.activeDirectory.domainDnsName: nome del dominio DNS che verrà usato per il cluster, ad esempiocontoso.local.security.activeDirectory.clusterAdmins: questo parametro accetta un solo gruppo di AD. L'ambito del gruppo di AD deve essere universale o globale. I membri di questo gruppo avranno il ruolo del clusterbdcAdminche concederà autorizzazioni di amministratore nel cluster. Questo significa che avranno autorizzazionisysadminin SQL Server, autorizzazionisuperuserin HDFS e autorizzazioni di amministratore quando connessi all'endpoint del controller.Importante
Creare questo gruppo in AD prima dell'avvio della distribuzione. Se l'ambito di questo gruppo di AD è il dominio, la distribuzione locale ha esito negativo.
security.activeDirectory.clusterUsers: elenco dei gruppi di Active Directory che sono utenti normali (senza autorizzazioni di amministratore) nel cluster Big Data. L'elenco può includere gruppi di AD che hanno come ambito gruppi globali o universali. Non possono essere gruppi locali di dominio.
I gruppi di AD in questo elenco sono associati al ruolo del cluster Big Data bdcUser e necessitano dell'accesso a SQL Server (vedere Autorizzazioni di SQL Server) o HDFS (vedere Guida alle autorizzazioni per HDFS). Quando sono connessi all'endpoint del controller, questi utenti possono elencare solo gli endpoint disponibili nel cluster usando il comando azdata bdc endpoint list.
Per informazioni dettagliate su come aggiornare i gruppi di Active Directory per queste impostazioni, vedere Gestire l'accesso ai cluster Big Data in modalità Active Directory.
Suggerimento
Per abilitare l'esperienza di esplorazione HDFS quando si è connessi all'istanza master di SQL Server in Azure Data Studio, è necessario concedere a un utente con ruolo bdcUser le autorizzazioni VIEW SERVER STATE perché Azure Data Studio usa il DMV sys.dm_cluster_endpoints per ottenere l'endpoint del gateway Knox richiesto per la connessione a HDFS.
Importante
Creare questi gruppi in AD prima che venga avviata la distribuzione. Se l'ambito per uno di questi gruppi di AD è locale al dominio, la distribuzione non riesce.
Importante
Se gli utenti del dominio hanno un numero elevato di appartenenze ai gruppi, è consigliabile modificare i valori per l'impostazione del gateway httpserver.requestHeaderBuffer (il valore predefinito è 8192) e l'impostazione HDFS hadoop.security.group.mapping.ldap.search.group.hierarchy.levels (il valore predefinito è 10), usando il file di configurazione della distribuzione bdc.json personalizzato. Si tratta di una procedura consigliata per evitare i timeout di connessione al gateway e/o le risposte HTTP con un codice di stato 431 (Campi intestazione richiesta troppo grandi). Di seguito è riportata una sezione del file di configurazione che mostra come definire i valori di queste impostazioni e indica i valori consigliati per un numero maggiore di appartenenze ai gruppi:
{
...
"spec": {
"resources": {
...
"gateway": {
"spec": {
"replicas": 1,
"endpoints": [{...}],
"settings": {
"gateway-site.gateway.httpserver.requestHeaderBuffer": "65536"
}
}
},
...
},
"services": {
...
"hdfs": {
"resources": [...],
"settings": {
"core-site.hadoop.security.group.mapping.ldap.search.group.hierarchy.levels": "4"
}
},
...
}
}
}
security.activeDirectory.enableAES Optional parameterParametro facoltativo: valore booleano che indica se è necessario abilitare AES 128 e AES 256 negli account Active Directory generati automaticamente. Il valore predefinito èfalse. Quando questo parametro è impostato sutrue, i flag "Questo account supporta la crittografia AES 128 bit Kerberos" e "Questo account supporta la crittografia AES 256 bit Kerberos" saranno selezionati negli oggetti di Active Directory generati automaticamente durante la distribuzione dei cluster Big Data.
Nota
Il parametro security.activeDirectory.enableAES è disponibile a partire dai cluster Big Data di SQL Server CU13. Se la versione del cluster Big Data è precedente alla CU13, sono necessari i passaggi seguenti:
- Eseguire il comando
azdata bdc rotate -n <your-cluster-name>, che ruota i keytab nel cluster, in modo da garantire che le voci AES nei keytab siano corrette. Per altre informazioni, vedere azdata bdc. Inoltre,azdata bdc rotateruota le password degli oggetti di Active Directory generati automaticamente durante la distribuzione iniziale nella OU specificata. - Impostare i flag "Questo account supporta la crittografia AES 128 bit Kerberos" e "Questo account supporta la crittografia AES 256 bit Kerberos" in ogni oggetto di Active Directory generato automaticamente nella OU fornita durante la distribuzione iniziale dei cluster Big Data. A questo scopo, è possibile eseguire lo script
Get-ADUser -Filter * -SearchBase '<OU Path>' | Set-ADUser -replace @{ 'msDS-SupportedEncryptionTypes' = '24' }di PowerShell seguente nel controller di dominio, che imposta i campi AES in ogni account nella OU specificata nel parametro<OU Path>.
Importante
Creare i gruppi specificati per le impostazioni di seguito in Active Directory prima dell'inizio della distribuzione. Se l'ambito per uno di questi gruppi di AD è locale al dominio, la distribuzione non riesce.
security.activeDirectory.appOwnersParametro facoltativo: elenco dei gruppi di Active Directory che hanno le autorizzazioni necessarie per creare, eliminare ed eseguire qualsiasi applicazione. L'elenco può includere gruppi di AD che hanno come ambito gruppi globali o universali. Non possono essere gruppi locali di dominio.security.activeDirectory.appReadersParametro facoltativo: elenco dei gruppi di Active Directory che hanno le autorizzazioni necessarie per eseguire qualsiasi applicazione. L'elenco può includere gruppi di AD che hanno come ambito gruppi globali o universali. Non possono essere gruppi locali di dominio.
La tabella seguente mostra il modello di autorizzazione per la gestione delle applicazioni:
| Ruoli autorizzati | Comando dell'interfaccia della riga di comando Azure Data (azdata) |
|---|---|
| appOwner | azdata app create |
| appOwner | azdata app update |
| appOwner, appReader | azdata app list |
| appOwner, appReader | azdata app describe |
| appOwner | azdata app delete |
| appOwner, appReader | azdata app run |
security.activeDirectory.subdomain: Parametro opzionale questo parametro è stato introdotto in SQL Server 2019 CU5 per supportare la distribuzione di più cluster Big Data nello stesso dominio. Usando questa impostazione, è possibile specificare nomi DNS diversi per ogni cluster Big Data distribuito. Se il valore di questo parametro non è specificato nella sezione relativa ad Active Directory del filecontrol.json, per impostazione predefinita verrà usato il nome del cluster Big Data (uguale al nome dello spazio dei nomi Kubernetes) per calcolare il valore dell'impostazione del sottodominio.Nota
Il valore passato tramite l'impostazione del sottodominio non è un nuovo dominio di Active Directory, ma solo un dominio DNS usato internamente dal cluster Big Data.
Importante
A partire dalla versione SQL Server 2019 CU5, è necessario installare o aggiornare la versione più recente dell'interfaccia della riga di comando Azure Data (
azdata) per poter utilizzare queste nuove funzionalità e distribuire più cluster Big Data nello stesso dominio.Per altre informazioni sulla distribuzione di più cluster Big Data nello stesso dominio di Active Directory, vedere Distribuire cluster Big Data di SQL Server in modalità Active Directory.
security.activeDirectory.accountPrefix: Parametro opzionale questo parametro è stato introdotto in SQL Server 2019 CU5 per supportare la distribuzione di più cluster Big Data nello stesso dominio. Questa impostazione garantisce l'univocità dei nomi degli account per vari servizi dei cluster Big Data, che devono essere diversi tra due cluster. La personalizzazione del nome del prefisso dell'account è facoltativa. Per impostazione predefinita, come prefisso dell'account viene usato il nome del sottodominio. Se il nome del sottodominio supera i 12 caratteri, come prefisso dell'account vengono usati i primi 12 caratteri del nome del sottodominio.Nota
Active Directory impone il limite di 20 caratteri per i nomi degli account. Il cluster Big Data deve usare 8 dei caratteri per distinguere pod e StatefulSet. Rimangono così al massimo 12 caratteri per il prefisso dell'account.
Controllare l'ambito del gruppo AD per determinare se è DomainLocal.
Se il file di configurazione della distribuzione non è stato ancora inizializzato, è possibile eseguire questo comando per ottenere una copia della configurazione. Gli esempi seguenti usano il profilo kubeadm-prod, ma la stessa procedura è applicabile a openshift-prod.
azdata bdc config init --source kubeadm-prod --target custom-prod-kubeadm
Per impostare i parametri precedenti nel file control.json, usare i comandi dell'interfaccia della riga di comando Azure Data (azdata) seguenti. I comandi sostituiscono la configurazione e forniscono i valori personalizzati prima della distribuzione.
Importante
Nella versione SQL Server 2019 CU2 la struttura della sezione relativa alla configurazione della sicurezza nel profilo di distribuzione è cambiata leggermente e tutte le impostazioni di Active Directory correlate si trovano nella nuova sezione activeDirectory nell'albero json in security nel file control.json.
Nota
Oltre a fornire valori diversi per il sottodominio come descritto in questa sezione, è necessario usare anche numeri di porta diversi per gli endpoint dei cluster Big Data quando si distribuiscono più cluster Big Data nello stesso cluster Kubernetes. Questi numeri di porta sono configurabili in fase di distribuzione tramite i profili di configurazione della distribuzione.
L'esempio seguente si basa sull'uso di SQL Server 2019 CU2. Illustra come sostituire i valori di parametri correlati ad Active Directory nella configurazione della distribuzione. I dettagli del dominio di seguito sono valori di esempio.
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.activeDirectory.ouDistinguishedName=OU\=bdc\,DC\=contoso\,DC\=local"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.activeDirectory.dnsIpAddresses=[\"10.100.10.100\"]"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.activeDirectory.domainControllerFullyQualifiedDns=[\"HOSTNAME.CONTOSO.LOCAL\"]"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.activeDirectory.domainDnsName=contoso.local"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.activeDirectory.clusterAdmins=[\"bdcadminsgroup\"]"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.activeDirectory.clusterUsers=[\"bdcusersgroup\"]"
#Example for providing multiple clusterUser groups: [\"bdcusergroup1\",\"bdcusergroup2\"]
Facoltativamente, solo a partire da SQL Server 2019 CU5, è possibile sostituire i valori predefiniti per le impostazioni subdomain e accountPrefix.
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.activeDirectory.subdomain=[\"bdctest\"]"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.activeDirectory.accountPrefix=[\"bdctest\"]"
Analogamente, nelle versioni precedenti a SQL Server 2019 CU2, è possibile eseguire:
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.ouDistinguishedName=OU\=bdc\,DC\=contoso\,DC\=local"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.dnsIpAddresses=[\"10.100.10.100\"]"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.domainControllerFullyQualifiedDns=[\"HOSTNAME.CONTOSO.LOCAL\"]"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.domainDnsName=contoso.local"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.clusterAdmins=[\"bdcadminsgroup\"]"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.clusterUsers=[\"bdcusersgroup\"]"
#Example for providing multiple clusterUser groups: [\"bdcusergroup1\",\"bdcusergroup2\"]
Oltre alle informazioni precedenti, è necessario fornire anche i nomi DNS per i diversi endpoint del cluster. In fase di distribuzione verranno automaticamente create le voci DNS che usano i nomi DNS specificati nel server DNS. Questi nomi verranno usati durante la connessione ai diversi endpoint del cluster. Ad esempio, se il nome DNS per l'istanza master SQL è mastersql, considerando che il sottodominio userà il valore predefinito del nome del cluster in control.json, sarà possibile usare mastersql.contoso.local,31433 o mastersql.mssql-cluster.contoso.local,31433 (a seconda dei valori specificati nei file di configurazione della distribuzione per i nomi DNS degli endpoint) per connettersi all'istanza master dagli strumenti.
# DNS names for Big Data Clusters services
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.spec.endpoints[0].dnsName=<controller DNS name>.contoso.local"
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.spec.endpoints[1].dnsName=<monitoring services DNS name>.<Domain name. e.g. contoso.local>"
azdata bdc config replace -c custom-prod-kubeadm/bdc.json -j "$.spec.resources.master.spec.endpoints[0].dnsName=<SQL Master Primary DNS name>.<Domain name. e.g. contoso.local>"
azdata bdc config replace -c custom-prod-kubeadm/bdc.json -j "$.spec.resources.master.spec.endpoints[1].dnsName=<SQL Master Secondary DNS name>.<Domain name. e.g. contoso.local>"
azdata bdc config replace -c custom-prod-kubeadm/bdc.json -j "$.spec.resources.gateway.spec.endpoints[0].dnsName=<Gateway (Knox) DNS name>.<Domain name. e.g. contoso.local>"
azdata bdc config replace -c custom-prod-kubeadm/bdc.json -j "$.spec.resources.appproxy.spec.endpoints[0].dnsName=<app proxy DNS name>.<Domain name. e.g. contoso.local>"
Importante
È possibile usare nomi DNS degli endpoint personalizzati purché siano completi e non siano in conflitto tra due cluster Big Data distribuiti nello stesso dominio. Facoltativamente, è possibile usare il valore del parametro subdomain per assicurarsi che i nomi DNS siano diversi tra i cluster. Ad esempio:
# DNS names for Big Data Clusters services
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.spec.endpoints[0].dnsName=<controller DNS name>.<subdomain e.g. mssql-cluster>.contoso.local"
Qui è possibile trovare uno script di esempio per la distribuzione di un cluster Big Data di SQL Server in un cluster Kubernetes a nodo singolo (kubeadm) con l'integrazione di AD.
Nota
Il nuovo parametro subdomain introdotto con l'aggiornamento potrebbe non essere utilizzabile in alcuni scenari, ad esempio quando è necessario distribuire una versione precedente alla CU5 ed è già stata aggiornata l'interfaccia della riga di comando Azure Data (azdata). Questo scenario è altamente improbabile, ma se è necessario ripristinare il comportamento precedente alla versione CU5, è possibile impostare il parametro useSubdomain su false nella sezione relativa ad Active Directory di control.json. Il comando da usare è il seguente:
azdata bdc config replace -c custom-prod-kubeadm/control.json -j "$.security.activeDirectory.useSubdomain=false"
A questo punto, sono stati impostati tutti i parametri necessari per una distribuzione di cluster Big Data con l'integrazione di Active Directory.
È ora possibile distribuire il cluster Big Data integrato con Active Directory usando il comando dell'interfaccia della riga di comando Azure Data (azdata) e il profilo di distribuzione kubeadm-prod. Per la documentazione completa su come distribuire cluster Big Data, vedere Come distribuire cluster Big Data di SQL Server in Kubernetes.
Verificare la voce DNS inversa per il controller di dominio
Assicurarsi che sia presente una voce DNS inversa (record PTR) per il controller di dominio stesso, registrata nel server DNS. A questo scopo, è possibile eseguire nslookup dell'indirizzo IP del controller di dominio per verificare che possa essere risolto nel nome di dominio completo del controller di dominio.
Problemi noti e limitazioni
Limitazioni da tenere presenti in SQL Server 2019 CU5
Attualmente, il dashboard Ricerca log e il dashboard Metriche non supportano l'autenticazione di Active Directory. Per l'autenticazione a questi dashboard è possibile usare il nome utente e la password di base impostati in fase di distribuzione. Tutti gli altri endpoint del cluster supportano l'autenticazione di Active Directory.
La modalità Active Directory sicura funziona attualmente solo negli ambienti di distribuzione
kubeadmeopenshifte non nel servizio Azure Kubernetes o in Azure Red Hat OpenShift. I profili di distribuzionekubeadm-prodeopenshift-prodincludono le sezioni di sicurezza per impostazione predefinita.Prima della versione SQL Server 2019 CU5, è consentito un solo cluster Big Data per dominio (Active Directory). La presenza di più cluster Big Data per dominio è una funzionalità disponibile a partire dalla versione CU5.
Nessuno dei gruppi AD specificati nelle configurazioni di sicurezza può avere l'ambito DomainLocal. È possibile controllare l'ambito di un gruppo di Active Directory seguendo queste istruzioni.
Gli account Active Directory che possono essere usati per accedere al cluster Big Data sono consentiti dallo stesso dominio configurato per i cluster Big Data di SQL Server. L'abilitazione di account di accesso da altri domini attendibili non è supportata.
Passaggi successivi
Connettersi a cluster Big Data di SQL Server: modalità Active Directory
Risolvere i problemi di integrazione di Active Directory di cluster Big Data di SQL Server
Distribuire cluster Big Data di SQL Server in modalità Active Directory