Monitorare lo stato di cluster Big Data tramite Azure Data Studio
Questo articolo illustra come visualizzare lo stato di un cluster Big Data usando Azure Data Studio.
Importante
Il componente aggiuntivo per i cluster Big Data di Microsoft SQL Server 2019 verrà ritirato. Il supporto per i cluster Big Data di SQL Server 2019 terminerà il 28 febbraio 2025. Tutti gli utenti esistenti di SQL Server 2019 con Software Assurance saranno completamente supportati nella piattaforma e fino a quel momento il software continuerà a ricevere aggiornamenti cumulativi di SQL Server. Per altre informazioni, vedere il post di blog relativo all'annuncio e Opzioni per i Big Data nella piattaforma Microsoft SQL Server.
Usare Azure Data Studio
Dopo aver scaricato la versione più recente della build Insider di Azure Data Studio, e possibile visualizzare gli endpoint di servizio e lo stato di un cluster Big Data con il dashboard dei cluster Big Data di SQL Server. Alcune delle funzionalità seguenti sono inizialmente disponibili solo per la build Insider di Azure Data Studio.
Creare prima di tutto una connessione al cluster Big Data in Azure Data Studio. Per altre informazioni, vedere Connettersi a un cluster Big Data di SQL Server con Azure Data Studio.
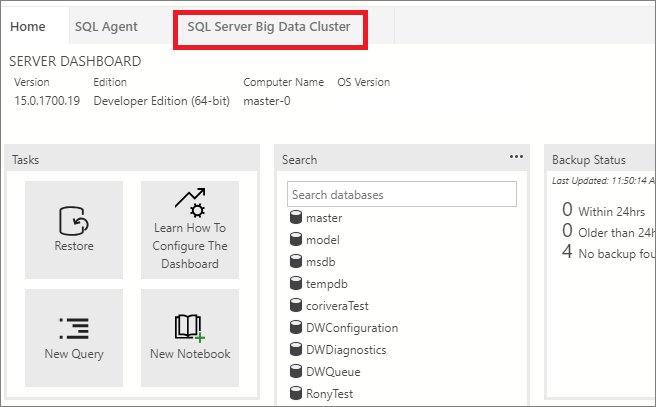
Fare clic con il pulsante destro del mouse sull'endpoint del cluster Big Data e selezionare Gestisci.

Selezionare la scheda SQL Server Big Data Cluster (Cluster Big Data di SQL Server) per accedere al dashboard dei cluster Big Data.
Endpoint di servizio
È importante poter accedere facilmente ai vari servizi all'interno di un cluster Big Data. Il dashboard dei cluster Big Data fornisce una tabella degli endpoint di servizio che consente di visualizzare e copiare gli endpoint.
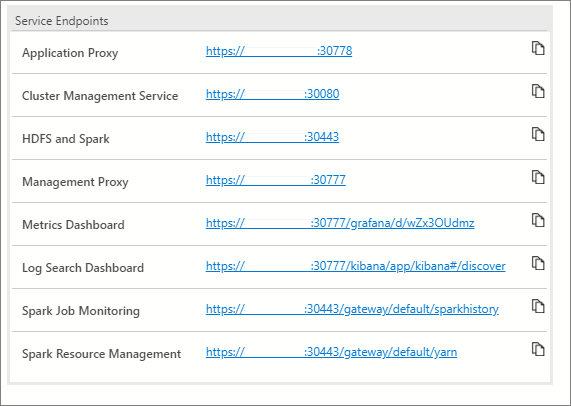
Questi servizi elencano gli endpoint che è possibile copiare e incollare quando è necessario per la connessione ai servizi. È possibile, ad esempio, selezionare l'icona di copia a destra dell'endpoint e quindi incollare quanto copiato in una finestra di testo che richiede tale endpoint. L'endpoint del servizio di gestione cluster è necessario per eseguire il notebook relativo allo stato del cluster.
Dashboard
La tabella degli endpoint di servizio espone anche diversi dashboard per il monitoraggio:
- Metriche (Grafana)
- Log (Kibana)
- Monitoraggio di processi Spark
- Gestione di risorse di Spark
È possibile selezionare direttamente questi collegamenti. Verrà richiesto di eseguire l'autenticazione quando si accede a questi dashboard. Per i dashboard delle metriche e dei log, fornire le credenziali di amministratore del controller impostate in fase di distribuzione usando le variabili di ambiente AZDATA_USERNAME e AZDATA_PASSWORD. I dashboard Spark useranno le credenziali del gateway (Knox), ovvero l'identità di Active Directory in un cluster integrato con AD o AZDATA_USERNAME e AZDATA_PASSWORD se si usa l'autenticazione di base nel cluster.
A partire da SQL Server 2019 (15.x) CU5, quando si distribuisce un nuovo cluster con l'autenticazione di base, tutti gli endpoint, incluso il gateway, usano AZDATA_USERNAME e AZDATA_PASSWORD. Gli endpoint nei cluster aggiornati a CU5 continuano a usare root come nome utente per la connessione all'endpoint del gateway. Questa modifica non si applica alle distribuzioni che usano l'autenticazione Active Directory. Vedere Credenziali per l'accesso ai servizi tramite l'endpoint del gateway nelle note sulla versione.
Notebook relativo allo stato del cluster
È anche possibile visualizzare lo stato del cluster Big Data avviando il notebook relativo allo stato del cluster. Per avviare il notebook, selezionare la task Stato cluster.

Prima di iniziare, è necessario disporre di quanto segue:
- Nome del cluster Big Data
- Nome utente del controller
- Password del controller
- Endpoint controller
Il nome predefinito del cluster Big Data è mssql-cluster, a meno che non sia stato personalizzato durante la distribuzione. È possibile trovare l'endpoint controller nel dashboard dei cluster Big Data nella tabella relativa agli endpoint di servizio. L'endpoint è elencato come Cluster Management Service (Servizio di gestione cluster). Se non si conoscono le credenziali, rivolgersi all'amministratore che ha distribuito il cluster.
Selezionare Esegui celle sulla barra degli strumenti superiore.
Seguire le indicazioni di richiesta delle credenziali. Premere INVIO dopo aver digitato ogni credenziale per il nome del cluster Big Data, il nome utente del controller e la password del controller.
Nota
Se non è disponibile un file di configurazione con i Big Data, verrà richiesto l'endpoint controller. Digitare o incollare l'endpoint e quindi premere INVIO per continuare.
Se la connessione viene stabilita correttamente, nel resto del notebook verrà visualizzato l'output di ogni componente del cluster Big Data. Quando si vuole eseguire di nuovo una determinata cella di codice, passare il puntatore sulla cella di codice e selezionare l'icona Esegui.