Tracciare istogrammi in Python
Si applica a: ![]() SQL Server
SQL Server ![]() Database SQL di Azure
Database SQL di Azure ![]() Istanza gestita di SQL di Azure
Istanza gestita di SQL di Azure
Questo articolo descrive come tracciare un grafico dei dati usando il pacchetto Python pandas'.hist(). Un database SQL è l'origine usata per visualizzare gli intervalli di dati dell'istogramma con valori consecutivi non sovrapposti.
Prerequisiti
SQL Server Management Studio per il ripristino del database di esempio in Istanza gestita di SQL di Azure.
Azure Data Studio. Per eseguire l'installazione, vedere Azure Data Studio.
Ripristinare il database DW di esempio per ottenere i dati di esempio usati in questo articolo.
Verificare il database ripristinato
È possibile verificare che il database ripristinato sia disponibile eseguendo una query sulla tabella Person.CountryRegion:
USE AdventureWorksDW;
SELECT * FROM Person.CountryRegion;
Installare i pacchetti Python
Scaricare e installare Azure Data Studio.
Installare i pacchetti Python seguenti:
pyodbcpandassqlalchemymatplotlib
Per installare questi pacchetti:
- Nel notebook di Azure Data Studio selezionare Gestisci pacchetti.
- Nel riquadro Gestisci pacchetti selezionare la scheda Aggiungi nuovo.
- Per ognuno dei seguenti pacchetti immettere il nome del pacchetto, selezionare Cerca, quindi selezionare Installa.
Tracciare un istogramma
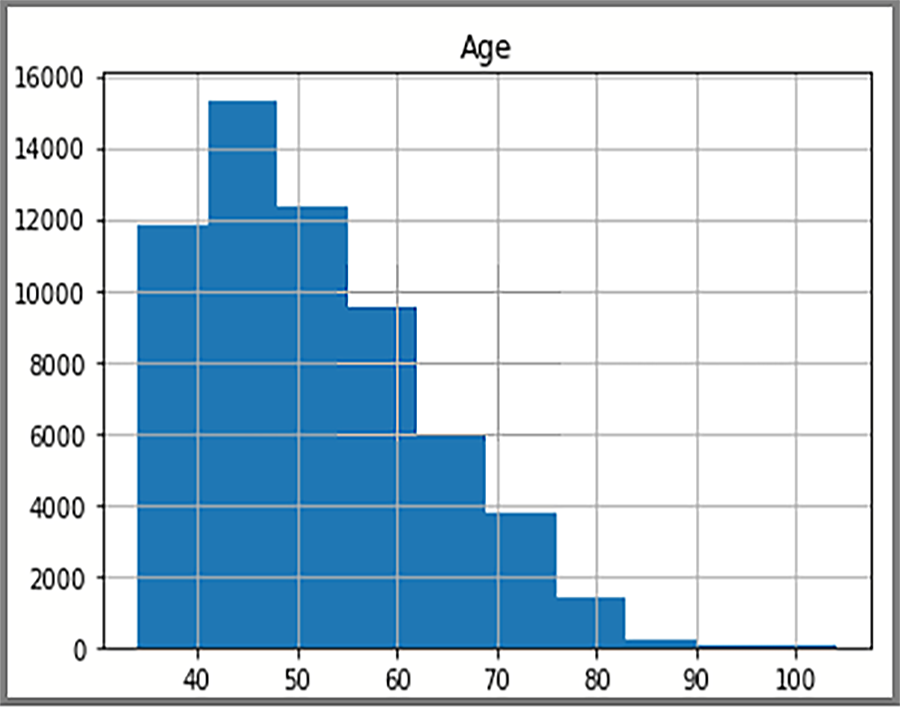
I dati distribuiti visualizzati nell'istogramma sono basati su una query SQL di AdventureWorksDW2022. L'istogramma visualizza i dati e la frequenza dei valori dei dati.
Modificare le variabili della stringa di connessione "server", "database", "username" e "password" per la connessione al database SQL Server.
Per creare un nuovo notebook:
- In Azure Data Studio selezionare File e quindi Nuovo notebook.
- Nel notebook selezionare il kernel Python3 e quindi +Codice.
- Incollare il codice nel notebook e selezionare Esegui tutti.
import pyodbc
import pandas as pd
import matplotlib
import sqlalchemy
from sqlalchemy import create_engine
matplotlib.use('TkAgg', force=True)
from matplotlib import pyplot as plt
# Some other example server values are
# server = 'localhost\sqlexpress' # for a named instance
# server = 'myserver,port' # to specify an alternate port
server = 'servername'
database = 'AdventureWorksDW2022'
username = 'yourusername'
password = 'databasename'
url = 'mssql+pyodbc://{user}:{passwd}@{host}:{port}/{db}?driver=SQL+Server'.format(user=username, passwd=password, host=server, port=port, db=database)
engine = create_engine(url)
sql = "SELECT DATEDIFF(year, c.BirthDate, GETDATE()) AS Age FROM [dbo].[FactInternetSales] s INNER JOIN dbo.DimCustomer c ON s.CustomerKey = c.CustomerKey"
df = pd.read_sql(sql, engine)
df.hist(bins=50)
plt.show()
Il grafico mostrerà la distribuzione dell'età dei clienti nella tabella FactInternetSales.