Configurare un client di data science per lo sviluppo Python in SQL Server Machine Learning Services
Si applica a: ![]() SQL Server 2016 (13.x),
SQL Server 2016 (13.x), ![]() SQL Server 2017 (14.x) e
SQL Server 2017 (14.x) e ![]() SQL Server 2019 (15.x),
SQL Server 2019 (15.x), ![]() SQL Server 2019 (15.x) - Linux
SQL Server 2019 (15.x) - Linux
L'integrazione di Python è disponibile in SQL Server 2017 e versioni successive, quando si include l'opzione Python in un'installazione di Machine Learning Services (In-Database).
Nota
Attualmente questo articolo si applica a SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) e SQL Server 2019 (15.x) solo per Linux.
Per sviluppare e distribuire soluzioni Python per SQL Server, installare il pacchetto revoscalepy Microsoft e altre librerie Python nella workstation di sviluppo. La libreria revoscalepy, che si trova anche nell'istanza di SQL Server remota, coordina le richieste di calcolo tra i due sistemi.
Questo articolo illustra come configurare una workstation di sviluppo Python per poter interagire con un'istanza remota di SQL Server abilitata per l'integrazione di Python e Machine Learning. Dopo aver completato i passaggi descritti in questo articolo, si disporrà di librerie Python analoghe a quelle presenti in SQL Server. Si saprà anche come eseguire il push dei calcoli da una sessione di Python locale a una sessione di Python remota in SQL Server.
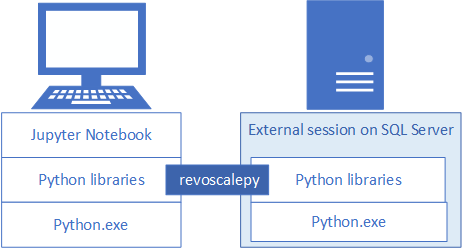
Per convalidare l'installazione, è possibile usare la soluzione Jupyter Notebook predefinita, come descritto in questo articolo, oppure collegare le librerie a PyCharm o a qualsiasi altro ambiente di sviluppo integrato (IDE) usato in genere.
Suggerimento
Per una dimostrazione video di questi esercizi, vedere Eseguire R e Python in remoto in SQL Server da Jupyter Notebook.
Strumenti di uso comune
Che si sia uno sviluppatore Python che inizia a usare SQL o uno sviluppatore SQL che inizia a usare Python e l'analisi nel database, sono necessari sia uno strumento di sviluppo Python sia un editor di query T-SQL, ad esempio SQL Server Management Studio (SSMS), per sfruttare tutte le funzionalità di analisi nel database.
Per lo sviluppo Python è possibile usare Jupyter Notebook, una soluzione fornita in bundle nella distribuzione di Anaconda installata da SQL Server. Questo articolo illustra come avviare Jupyter Notebook per poter eseguire il codice Python in locale e in remoto in SQL Server.
SSMS è una soluzione scaricabile separatamente, utile per la creazione e l'esecuzione di stored procedure in SQL Server, incluse quelle contenenti codice Python. Quasi tutto il codice Python scritto in Jupyter Notebook può essere incorporato in una stored procedure. È possibile esaminare altri argomenti di avvio rapido per informazioni su SSMS e Python incorporato.
1 - Installare i pacchetti Python
Le workstation locali devono avere le stesse versioni dei pacchetti Python di quelle presenti in SQL Server, tra cui la versione di base di Anaconda 4.2.0 con la distribuzione di Python 3.5.2 e i pacchetti specifici di Microsoft.
Uno script di installazione aggiunge tre librerie specifiche di Microsoft al client Python. Lo script installa:
- revoscalepy, usato per definire gli oggetti origine dati e il contesto di calcolo.
- microsoftml che fornisce algoritmi di Machine Learning.
- azureml si applica alle attività di operazionalizzazione associate a un contesto di server autonomo e può essere usato in modo limitato per l'analisi nel database.
Scaricare uno script di installazione. Nella pagina GitHub seguente appropriata selezionare Scarica file RAW.
https://aka.ms/mls-py installa la versione 9.2.1 dei pacchetti Microsoft Python. Questa versione corrisponde a un'istanza di SQL Server predefinita.
https://aka.ms/mls93-py installa la versione 9.3 dei pacchetti Microsoft Python.
Aprire una finestra di PowerShell con autorizzazioni di amministratore con privilegi elevati (fare clic con il pulsante destro del mouse su Esegui come amministratore).
Passare alla cartella in cui è stato scaricato il programma di installazione ed eseguire lo script. Aggiungere l'argomento della riga di comando
-InstallFolderper specificare il percorso di una cartella per le librerie. Ad esempio:cd {{download-directory}} .\Install-PyForMLS.ps1 -InstallFolder "C:\path-to-python-for-mls"
Se si omette la cartella di installazione, il valore predefinito è %ProgramFiles%\Microsoft\PyForMLS.
Il completamento dell'installazione richiede un po' di tempo. È possibile monitorare lo stato nella finestra di PowerShell. Al termine dell'installazione, sarà presente un set completo di pacchetti.
Suggerimento
È consigliabile vedere le domande frequenti su Python per Windows per informazioni generali sull'esecuzione di programmi Python in Windows.
2 - Individuare gli eseguibili
Sempre in PowerShell, elencare il contenuto della cartella di installazione per verificare che Python.exe, gli script e gli altri pacchetti siano installati.
Immettere
cd \per passare all'unità radice e quindi immettere il percorso specificato per-InstallFoldernel passaggio precedente. Se questo parametro è stato omesso durante l'installazione, il valore predefinito ècd %ProgramFiles%\Microsoft\PyForMLS.Immettere
dir *.exeper elencare gli eseguibili. Dovrebbero essere presenti python.exe, pythonw.exe e uninstall-anaconda.exe.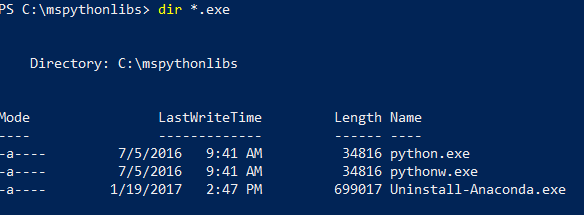
Nei sistemi con più versioni di Python, ricordarsi di usare questo eseguibile Python.exe specifico se si vuole caricare revoscalepy e altri pacchetti Microsoft.
Nota
Lo script di installazione non modifica la variabile di ambiente PATH nel computer, quindi il nuovo interprete Python e i moduli appena installati non sono automaticamente disponibili per altri strumenti. Per informazioni sul collegamento dell'interprete Python e delle librerie agli strumenti, vedere Installare un ambiente di sviluppo integrato (IDE).
3 - Aprire Jupyter Notebook
Anaconda include Jupyter Notebook. Come passaggio successivo, creare un notebook ed eseguire codice Python contenente le librerie appena installate.
Al prompt di PowerShell, sempre nella directory
%ProgramFiles%\Microsoft\PyForMLS, aprire Jupyter Notebook dalla cartella Scripts:.\Scripts\jupyter-notebookVerrà aperto un notebook nel browser predefinito in
https://localhost:8889/tree.È anche possibile avviare Jupyter Notebook facendo clic su jupyter-notebook.exe.
Selezionare New (Nuovo) e quindi Python 3.
Immettere
import revoscalepyed eseguire il comando per caricare una delle librerie specifiche di Microsoft.Immettere ed eseguire
print(revoscalepy.__version__)per restituire le informazioni sulla versione. Verrà visualizzata la versione 9.2.1 o 9.3.0. È possibile usare una di queste versioni con revoscalepy nel server.Immettere una serie di istruzioni più complesse. Questo esempio genera statistiche di riepilogo usando rx_summary su un set di dati locale. Altre funzioni ottengono il percorso dei dati di esempio e creano un oggetto origine dati per un file XDF locale.
import os from revoscalepy import rx_summary from revoscalepy import RxXdfData from revoscalepy import RxOptions sample_data_path = RxOptions.get_option("sampleDataDir") print(sample_data_path) ds = RxXdfData(os.path.join(sample_data_path, "AirlineDemoSmall.xdf")) summary = rx_summary("ArrDelay+DayOfWeek", ds) print(summary)
Lo screenshot seguente mostra l'input e una parte dell'output, tagliati per brevità.

4 - Ottenere le autorizzazioni SQL
Per connettersi a un'istanza di SQL Server per eseguire gli script e caricare i dati, è necessario disporre di un account di accesso valido nel server di database. È possibile usare un account di accesso SQL o un'autenticazione integrata di Windows. In genere è consigliabile usare l'autenticazione integrata di Windows, ma l'uso dell'account di accesso SQL è più semplice per alcuni scenari, in particolare quando lo script contiene stringhe di connessione ai dati esterni.
L'account usato per eseguire il codice deve disporre almeno dell'autorizzazione di lettura dai database usati, oltre che dell'autorizzazione speciale EXECUTE ANY EXTERNAL SCRIPT. La maggior parte degli sviluppatori richiede anche le autorizzazioni per la creazione di stored procedure e per la scrittura dei dati in tabelle contenenti dati di training o dati con punteggio.
Chiedere all'amministratore del database di configurare le autorizzazioni seguenti per l'account nel database in cui si usa Python:
- EXECUTE ANY EXTERNAL SCRIPT per eseguire Python nel server.
- Privilegi db_datareader per eseguire le query usate per il training del modello.
- db_datawriter per scrivere i dati di training o i dati con punteggio.
- db_owner per creare oggetti come stored procedure, tabelle e funzioni. Il ruolo db_owner è anche necessario per creare database di esempio e di test.
Se il codice richiede pacchetti non installati per impostazione predefinita con SQL Server, chiedere all'amministratore del database di installare i pacchetti con l'istanza. SQL Server è un ambiente sicuro e prevede restrizioni relative alla posizione in cui è possibile installare i pacchetti. L'installazione ad hoc di pacchetti come parte del codice non è consigliata, anche se si dispone dei diritti. Valutare inoltre sempre attentamente le implicazioni relative alla sicurezza prima di installare nuovi pacchetti nella libreria server.
5 - Creare dati di test
Se si hanno le autorizzazioni per creare un database nel server remoto, è possibile eseguire il codice seguente per creare il database demo Iris usato per i passaggi rimanenti di questo articolo.
5-1 - Creare il database irissql in remoto
import pyodbc
# creating a new db to load Iris sample in
new_db_name = "irissql"
connection_string = "Driver=SQL Server;Server=localhost;Database={0};Trusted_Connection=Yes;"
# you can also swap Trusted_Connection for UID={your username};PWD={your password}
cnxn = pyodbc.connect(connection_string.format("master"), autocommit=True)
cnxn.cursor().execute("IF EXISTS(SELECT * FROM sys.databases WHERE [name] = '{0}') DROP DATABASE {0}".format(new_db_name))
cnxn.cursor().execute("CREATE DATABASE " + new_db_name)
cnxn.close()
print("Database created")
5-2 - Importare l'esempio Iris da SkLearn
from sklearn import datasets
import pandas as pd
# SkLearn has the Iris sample dataset built in to the package
iris = datasets.load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
5-3 - Usare le API Revoscalepy per creare una tabella e caricare i dati Iris
from revoscalepy import RxSqlServerData, rx_data_step
# Example of using RX APIs to load data into SQL table. You can also do this with pyodbc
table_ref = RxSqlServerData(connection_string=connection_string.format(new_db_name), table="iris_data")
rx_data_step(input_data = df, output_file = table_ref, overwrite = True)
print("New Table Created: Iris")
print("Sklearn Iris sample loaded into Iris table")
6 - Testare la connessione remota
Prima di provare a eseguire il passaggio successivo, assicurarsi di disporre delle autorizzazioni per l'istanza di SQL Server e di una stringa di connessione al database di esempio Iris. Se il database non è disponibile e si hanno autorizzazioni sufficienti, è possibile creare un database usando queste istruzioni inline.
Sostituire la stringa di connessione con valori validi. Il codice di esempio usa "Driver=SQL Server;Server=localhost;Database=irissql;Trusted_Connection=Yes;", ma nel codice in uso è necessario specificare un server remoto, possibilmente con un nome di istanza e un'opzione di credenziali che esegue il mapping all'account di accesso del database.
6-1 Definire una funzione
Il codice seguente definisce una funzione che si invierà a SQL Server in un passaggio successivo. Quando viene eseguito, usa i dati e le librerie (revoscalepy, pandas, matplotlib) nel server remoto per creare grafici a dispersione del set di dati Iris. Il flusso di byte del file PNG viene restituito a Jupyter Notebook per l'esecuzione del rendering nel browser.
def send_this_func_to_sql():
from revoscalepy import RxSqlServerData, rx_import
from pandas.tools.plotting import scatter_matrix
import matplotlib.pyplot as plt
import io
# remember the scope of the variables in this func are within our SQL Server Python Runtime
connection_string = "Driver=SQL Server;Server=localhost;Database=irissql;Trusted_Connection=Yes;"
# specify a query and load into pandas dataframe df
sql_query = RxSqlServerData(connection_string=connection_string, sql_query = "select * from iris_data")
df = rx_import(sql_query)
scatter_matrix(df)
# return bytestream of image created by scatter_matrix
buf = io.BytesIO()
plt.savefig(buf, format="png")
buf.seek(0)
return buf.getvalue()
6-2 Inviare la funzione a SQL Server
In questo esempio viene creato il contesto di calcolo remoto e quindi l'esecuzione della funzione viene inviata a SQL Server con rx_exec. La funzione rx_exec è utile perché accetta un contesto di calcolo come argomento. Qualsiasi funzione che si vuole eseguire in remoto deve avere un argomento relativo al contesto di calcolo. Alcune funzioni, ad esempio rx_lin_mod supportano questo argomento direttamente. Per le operazioni che non lo supportano, è possibile usare rx_exec per recapitare il codice in un contesto di calcolo remoto.
In questo esempio non è stato necessario trasferire dati non elaborati da SQL Server a Jupyter Notebook. Tutti i calcoli vengono eseguiti nel database Iris e al client viene restituito solo il file di immagine.
from IPython import display
import matplotlib.pyplot as plt
from revoscalepy import RxInSqlServer, rx_exec
# create a remote compute context with connection to SQL Server
sql_compute_context = RxInSqlServer(connection_string=connection_string.format(new_db_name))
# use rx_exec to send the function execution to SQL Server
image = rx_exec(send_this_func_to_sql, compute_context=sql_compute_context)[0]
# only an image was returned to my jupyter client. All data remained secure and was manipulated in my db.
display.Image(data=image)
Lo screenshot seguente mostra l'input e il grafico a dispersione di output.

7 - Avviare Python dagli strumenti
Poiché gli sviluppatori lavorano spesso con più versioni di Python, il programma di installazione non aggiunge Python alla variabile di ambiente PATH. Per usare l'eseguibile e le librerie Python installati dal programma di installazione, collegare l'IDE a Python.exe nel percorso in cui sono presenti anche revoscalepy e microsoftml.
Riga di comando
Quando si esegue Python.exe da %ProgramFiles%\Microsoft\PyForMLS (o qualsiasi percorso specificato per l'installazione delle librerie client Python), si ha accesso alla distribuzione completa di Anaconda, nonché ai moduli Microsoft Python revoscalepy e microsoftml.
- Passare a
%ProgramFiles%\Microsoft\PyForMLSed eseguire Python.exe. - Aprire la guida interattiva:
help(). - Digitare il nome di un modulo al prompt della guida:
help> revoscalepy. La guida restituisce il nome, il contenuto del pacchetto, la versione e il percorso del file. - Restituire le informazioni su versione e pacchetto nel prompt help>:
revoscalepy. Premere INVIO alcune volte per uscire dalla guida. - Importare un modulo:
import revoscalepy.
Notebook di Jupyter
Questo articolo usa la soluzione predefinita Jupyter Notebook per illustrare le chiamate di funzione a revoscalepy. Se non si ha familiarità con questo strumento, lo screenshot seguente illustra la relazione tra i componenti e il funzionamento.
La cartella padre %ProgramFiles%\Microsoft\PyForMLS contiene Anaconda e i pacchetti Microsoft. Jupyter Notebook è incluso in Anaconda, nella cartella Scripts, e gli eseguibili Python vengono registrati automaticamente con Jupyter Notebook. I pacchetti disponibili in site-packages possono essere importati in un notebook, inclusi i tre pacchetti Microsoft usati per le attività di data science e Machine Learning.
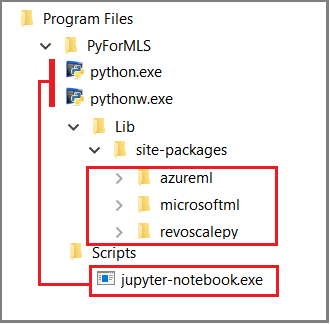
Se si usa un altro ambiente IDE, sarà necessario collegare gli eseguibili e le librerie di funzioni Python allo strumento. Le sezioni seguenti forniscono le istruzioni per gli strumenti di uso comune.
Visual Studio
Se si dispone di Python in Visual Studio, usare le opzioni di configurazione seguenti per creare un ambiente Python che include i pacchetti Microsoft Python.
| Impostazione di configurazione | value |
|---|---|
| Percorso di prefisso | %ProgramFiles%\Microsoft\PyForMLS |
| Percorso dell'interprete | %ProgramFiles%\Microsoft\PyForMLS\python.exe |
| Interprete con finestra | %ProgramFiles%\Microsoft\PyForMLS\pythonw.exe |
Per informazioni sulla configurazione di un ambiente Python, vedere Gestione di ambienti Python in Visual Studio.
PyCharm
In PyCharm impostare l'interprete sull'eseguibile Python installato.
In un nuovo progetto, in Settings (Impostazioni) selezionare Add Local (Aggiungi locale).
Immetti
%ProgramFiles%\Microsoft\PyForMLS\.
È ora possibile importare il modulo revoscalepy, microsoftml o azureml. È anche possibile scegliere Tools>Python Console (Strumenti > Console Python) per aprire una finestra interattiva.