Esplorare una soluzione per la disponibilità elevata e il ripristino di emergenza in una distribuzione IaaS
Sono disponibili diverse combinazioni di funzionalità che è possibile distribuire in Azure per IaaS. In questa sezione vengono illustrati cinque esempi comuni di architetture basate su SQL Server per la disponibilità elevata e il ripristino di emergenza (HADR) in Azure.
Esempio 1 di disponibilità elevata su singola area - Gruppi di disponibilità Always On
Se è necessaria solo la disponibilità elevata, senza il ripristino di emergenza, la configurazione di un gruppo di disponibilità è uno dei metodi più diffusi, indipendentemente da dove viene eseguito SQL Server. L'immagine seguente offre un esempio dell'aspetto che può assumere un gruppo di disponibilità in una singola area.
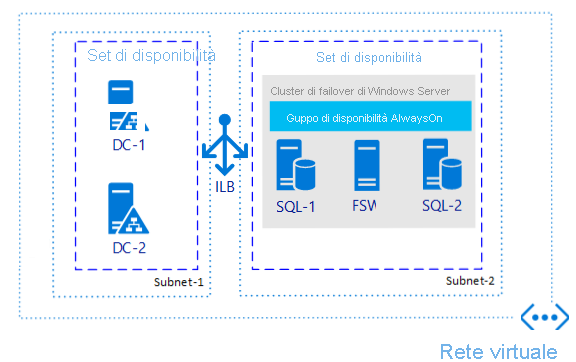
Perché vale la pena prendere in considerazione questa architettura?
Questa architettura protegge i dati dalla creazione di più copie in macchine virtuali diverse.
Se implementata correttamente, questa architettura consente di soddisfare l'obiettivo del tempo di ripristino (RTO) e l'obiettivo del punto di ripristino (RPO) con una perdita di dati minima.
Questa architettura offre un metodo semplice e standardizzato che consente alle applicazioni di accedere alle repliche primarie e secondarie, se è previsto l'uso di repliche di sola lettura.
Questa architettura consente di usufruire di maggiore disponibilità negli scenari di applicazione delle patch.
Questa architettura non necessita di alcuna risorsa di archiviazione condivisa ed è quindi meno complicata rispetto all'uso di un'istanza del cluster di failover.
Esempio 2 di disponibilità elevata su singola area - Istanza del cluster di failover Always On
Prima dell'introduzione dei gruppi di disponibilità, le istanze del cluster di failover rappresentavano il modo più comune per implementare la disponibilità elevata di SQL Server. Le istanze di questo tipo erano però progettate per infrastrutture in cui erano prevalenti le distribuzioni fisiche. In un mondo virtualizzato, le istanze del cluster di failover non offrono lo stesso livello di protezione che si può ottenere per l'hardware fisico, poiché accade raramente che una macchina virtuale abbia un problema. Le istanze del cluster di failover erano progettate per proteggere da guasti delle schede di rete o dei dischi, che normalmente non accadono in Azure.
Detto questo, anche le istanze del cluster di failover hanno un loro posto nell'architettura di Azure. Purché si abbiano le giuste aspettative riguardo a ciò che si può effettivamente ottenere, un'istanza del cluster di failover offre una soluzione del tutto accettabile. L'immagine seguente, tratta dalla documentazione di Microsoft, illustra l'aspetto generale che può avere la distribuzione di un'istanza del cluster di failover quando si usa Spazi di archiviazione diretta.
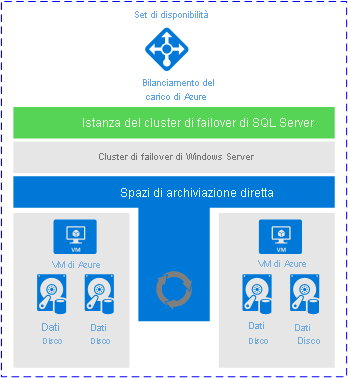
Perché vale la pena prendere in considerazione questa architettura?
Le istanze del cluster di failover sono ancora una soluzione diffusa per la disponibilità.
La questione dell'archiviazione condivisa sta migliorando grazie all'introduzione di funzionalità come il disco condiviso di Azure.
Questa architettura soddisfa la maggior parte delle esigenze di RTO e RPO per la disponibilità elevata (sebbene il ripristino di emergenza non venga gestito).
Questa architettura offre un metodo semplice e standardizzato per le applicazioni che accedono all'istanza in cluster di SQL Server.
Questa architettura consente di usufruire di maggiore disponibilità negli scenari di applicazione delle patch.
Esempio 1 di ripristino di emergenza - Gruppo di disponibilità Always On su più aree o ibrido
Se si usano i gruppi di disponibilità, un'opzione è quella di configurare il gruppo di disponibilità su più aree di Azure o eventualmente come architettura ibrida. In questo modo, tutti i nodi che contengono le repliche partecipano allo stesso cluster di failover di Windows Server (WSFC, Windows Server Failover Cluster) e si presuppone una connettività di rete efficace, soprattutto nel caso di una configurazione ibrida. Uno degli aspetti più rilevanti da considerare sarebbe la risorsa di controllo per il cluster WSFC. Questa architettura richiederebbe la disponibilità di Active Directory Domain Services e DNS in ogni area e possibilmente anche in locale, nel caso di una soluzione ibrida. L'immagine seguente illustra l'aspetto che può avere un singolo gruppo di disponibilità configurato in due posizioni quando viene usato Windows Server.

Perché vale la pena prendere in considerazione questa architettura?
Questa architettura è una soluzione collaudata. Non è diversa da quella in cui sono presenti due data center in una topologia basata su gruppi di disponibilità.
Questa architettura funziona con le edizioni Standard ed Enterprise di SQL Server.
I gruppi di disponibilità forniscono naturalmente ridondanza con copie aggiuntive dei dati.
Questa architettura è basata su un'unica funzionalità che fornisce disponibilità elevata e ripristino di emergenza
Esempio 2 di ripristino di emergenza - Gruppo di disponibilità distribuito
Un gruppo di disponibilità distribuito è una funzionalità disponibile solo per l'edizione Enterprise, introdotta in SQL Server 2016. Questo gruppo di disponibilità è diverso da quelli tradizionali. Anziché avere un cluster WSFC sottostante, in cui tutti i nodi contengono repliche che partecipano a uno stesso gruppo di disponibilità, come descritto nell'esempio precedente, un gruppo di disponibilità distribuito è costituito da più gruppi di disponibilità. La replica primaria contenente il database di lettura-scrittura è definita replica primaria globale. La replica primaria del secondo gruppo di disponibilità è detta replica d'inoltro e mantiene sincronizzate le repliche secondarie del gruppo di disponibilità. In sostanza, si tratta di un gruppo di disponibilità per gruppi di disponibilità.
Questa architettura consente di gestire più facilmente elementi come il quorum, perché ogni cluster è in grado di gestire il proprio quorum, ovvero ha uno specifico server di controllo. Un gruppo di disponibilità distribuito funziona indipendentemente dal fatto che venga usato Azure per tutte le risorse o che venga usata un'architettura ibrida.
L'immagine seguente mostra un esempio di configurazione di gruppo di disponibilità distribuito. Sono presenti due cluster WSFC. Si può immaginare che ciascuno si trovi in un'area di Azure diversa oppure che uno sia in locale e l'altro in Azure. Ogni cluster WSFC ha un gruppo di disponibilità con due repliche. La replica primaria globale nel gruppo di disponibilità 1 mantiene sincronizzate la replica secondaria dello stesso gruppo e la replica d'inoltro. Quest'ultima è anche la replica secondaria del gruppo di disponibilità 2 e mantiene sincronizzata la replica secondaria dello stesso gruppo.
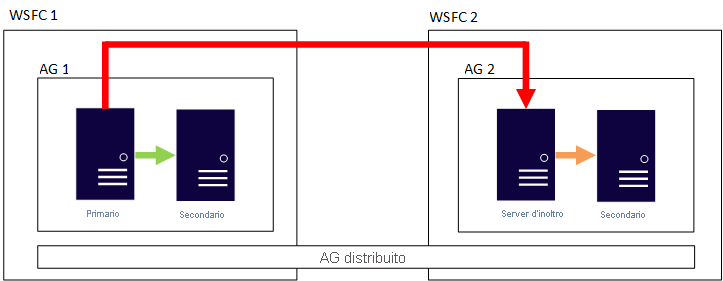
Perché vale la pena prendere in considerazione questa architettura?
Questa architettura separa il cluster WSFC come singolo punto di guasto nel caso in cui tutti i nodi perdano la comunicazione.
In questa architettura, una replica primaria non mantiene sincronizzate tutte le repliche secondarie.
Questa architettura può fornire failback da una posizione a un'altra.
Esempio di ripristino di emergenza 3 - Log shipping
Il log shipping è uno dei più vecchi metodi HADR per la configurazione del ripristino di emergenza per SQL Server. Come descritto in precedenza, l'unità di misura è data dal backup del log delle transazioni. A meno che non sia stato pianificato il passaggio a un warm standby per evitare perdite di dati, è molto probabile che si verifichi una perdita di dati. Nel caso di un ripristino di emergenza, è sempre meglio presupporre che si verifichi una perdita di dati, seppur minima. L'immagine seguente, tratta dalla documentazione di Microsoft, illustra un esempio di topologia di log shipping.
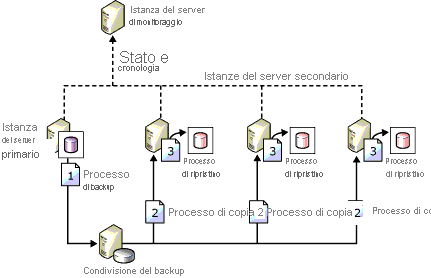
Perché vale la pena prendere in considerazione questa architettura?
Il log shipping è una funzionalità collaudata, in uso da oltre 20 anni.
Il log shipping è facile da distribuire e amministrare perché si basa sui processi di backup e ripristino.
Il log shipping è tollerante alle reti che non sono robuste.
Il log shipping soddisfa la maggior parte degli obiettivi di RTO e RPO per il ripristino di emergenza.
Il log shipping è un modo efficace per proteggere le istanze del cluster di failover.
Esempio 4 di ripristino di emergenza - Azure Site Recovery
Per coloro che non vogliono implementare una soluzione di ripristino di emergenza basata su SQL Server, Azure Site Recovery rappresenta una possibile alternativa. La maggior parte dei professionisti dei dati, tuttavia, preferisce un approccio incentrato sul database poiché in genere avrà un RPO inferiore.
L'immagine seguente, tratta dalla documentazione di Microsoft, mostra l'area del portale di Azure in cui configurare la replica per Azure Site Recovery.
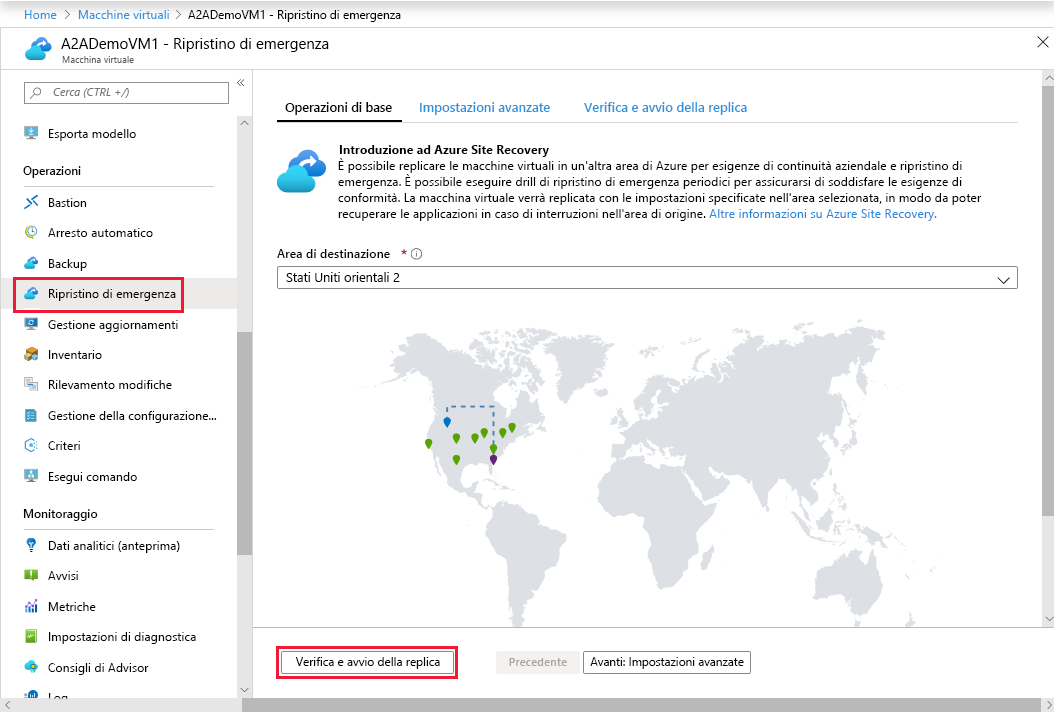
Perché vale la pena prendere in considerazione questa architettura?
Azure Site Recovery non funziona solo con SQL Server.
Azure Site Recovery può soddisfare le esigenze di RTO ed eventualmente anche quelle di RPO.
Azure Site Recovery viene fornito come componente della piattaforma Azure.