Esplorare l'elaborazione dei dati analitici
Per l'elaborazione dei dati analitici vengono in genere usati sistemi di sola lettura (o principalmente di lettura) che archiviano grandi volumi di dati cronologici o metriche aziendali. Le analisi possono essere basate su uno snapshot dei dati in un determinato momento o su una serie di snapshot.
Gli specifici dettagli per un sistema di elaborazione analitica possono variare in base alla specifica soluzione, ma un'architettura comune per l'analisi su scala aziendale è simile alla seguente:
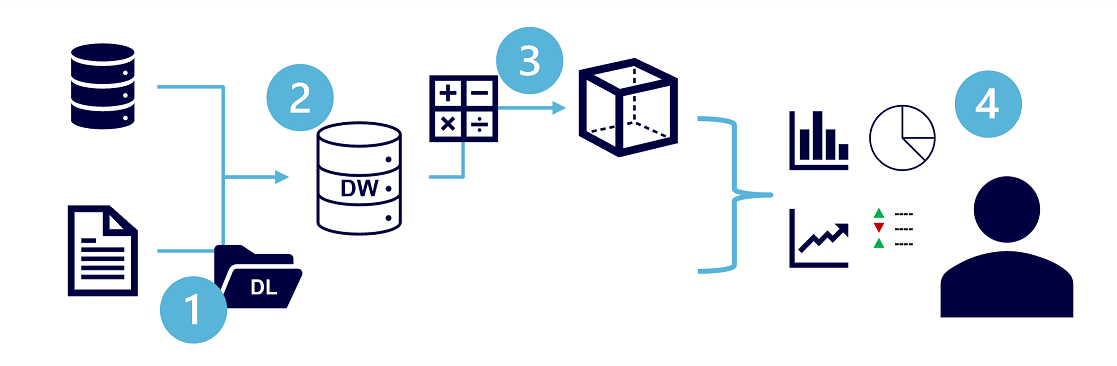
- I dati operativi vengono estratti, trasformati e caricati (ETL) in un data lake per l'analisi.
- I dati vengono caricati in uno schema di tabelle, costituito in genere da un data lakehouse basato su Spark con astrazioni tabulari sui file nel data lake o da un data warehouse con un motore SQL completamente relazionale.
- I dati presenti nel data warehouse possono essere aggregati e caricati in un modello OLAP (Online Analytics Processing) o in un cubo. I valori numerici aggregati (misure) provenienti dalle tabelle dei fatti vengono calcolati in base alle intersezioni delle tabelle delle dimensioni. Ad esempio, è possibile calcolare i totali dei ricavi delle vendite per data, cliente e prodotto.
- I dati inclusi nel data lake, nel data warehouse e nel modello analitico possono essere sottoposti a query in modo da produrre report, visualizzazioni e dashboard.
L'uso di data lake è una pratica comune per gli scenari di elaborazione analitica dei dati su larga scala, in cui è necessario raccogliere e analizzare un volume elevato di dati basati su file.
I data warehouses rappresentano il modo stabilito per archiviare i dati in uno schema relazionale ottimizzato per le operazioni di lettura, principalmente per supportare la creazione di report e la visualizzazione dei dati. I data lakehouse sono un'innovazione più recente che combina l'archiviazione flessibile e scalabile di un data lake con la semantica di query relazionale di un data warehouse. Lo schema di tabelle può richiedere una denormalizzazione dei dati in un'origine dati OLTP, introducendo una duplicazione per rendere più veloce l'esecuzione di query.
Un modello OLAP è un tipo aggregato di archiviazione dati ottimizzato per carichi di lavoro analitici. Le aggregazioni di dati vengono eseguite in diverse dimensioni a livelli diversi, così da consentire le operazioni di drill-up/down necessarie per visualizzare le aggregazioni a più livelli gerarchici, ad esempio per trovare le vendite totali in base all'area geografica, alla città o a un singolo indirizzo. Poiché i dati OLAP sono pre-aggregati, le query che restituiscono i riepiloghi in essi contenuti possono essere eseguite rapidamente.
Diversi tipi di utenti possono eseguire operazioni analitiche sui dati in diverse fasi dell'architettura complessiva. Ad esempio:
- Gli scienziati dei dati possono lavorare direttamente con i file di dati in un data lake per esplorare e modellare i dati.
- Gli analisti dei dati possono eseguire query sulle tabelle direttamente nel data warehouse per produrre report e visualizzazioni complesse.
- Gli utenti aziendali possono usare dati pre-aggregati in un modello analitico sotto forma di report o dashboard.