Esplorare lakehouse di Microsoft Fabric
Una lakehouse si presenta come un database e si basa su un data lake usando tabelle di formato Delta. Le lakehouse combinano le funzionalità analitiche basate su SQL di un data warehouse relazionale e la flessibilità e la scalabilità di un data lake. Le lakehouse archiviano tutti i formati di dati e possono essere usate con vari strumenti di analisi e linguaggi di programmazione. Come soluzioni basate sul cloud, le lakehouse possono essere ridimensionate automaticamente e offrono disponibilità elevata e ripristino di emergenza.
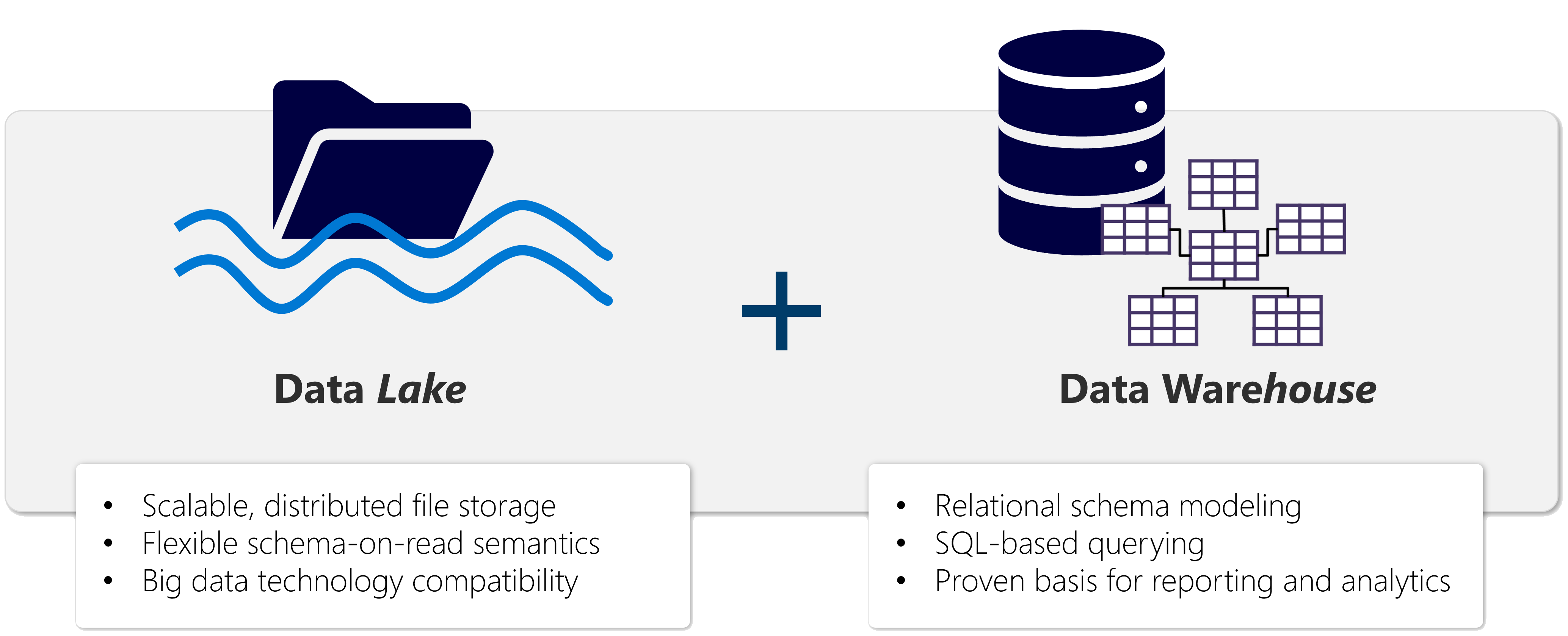
Alcuni dei vantaggi di una lakehouse includono:
- La lakehouse usa motori Spark e SQL per elaborare dati su larga scala e supportare l'apprendimento automatico o l'analisi predittiva della modellazione.
- I dati di una lakehouse sono organizzati in un formato di lettura a schema, il che significa che è necessario definire lo schema in base alle esigenze anziché disporre di uno schema predefinito.
- Le lakehouse supportano le transazioni ACID (Atomicity, Consistency, Isolation, Durability) tramite tabelle in formato Delta Lake per coerenza e integrità dei dati.
- Le lakehouse rappresentano un percorso unico per data engineer, data scientist e data anayst per accedere ai dati e usarli.
Le lakehouse sono un'ottima opzione se si vuole una soluzione di analisi scalabile che mantenga la coerenza dei dati. È importante valutare i requisiti specifici per determinare quale soluzione è la più adatta.
Caricare i dati in un lakehouse
I lakehouse di Fabric sono un elemento centrale per la soluzione di analisi. È possibile seguire il processo ETL (Extract, Transform, Load) per inserire e trasformare i dati prima di caricarli nel lakehouse.
È possibile inserire dati in molti formati comuni da varie origini, tra cui file locali, database o API. È inoltre possibile creare dei collegamenti Fabric ai dati presenti in origini esterne, ad esempio Azure Data Lake Store Gen2 o OneLake. Usare Lakehouse Explorer per esplorare file, cartelle, collegamenti e tabelle e visualizzarne il contenuto all'interno della piattaforma Fabric.
I dati inseriti possono essere trasformati e quindi caricati usando Apache Spark con notebook o Dataflows Gen2. Usare le pipeline di Data Factory per orchestrare le diverse attività ETL e trasferire i dati preparati nel lakehouse.
Nota
I flussi di dati Gen2 si basano su Power Query, uno strumento familiare agli analisti di dati che usano Excel o Power BI e che fornisce una rappresentazione visiva delle trasformazioni come alternativa alla programmazione tradizionale.
È possibile usare il lakehouse per molti motivi, tra cui:
- Analizzare con SQL.
- Eseguire il training di modelli di Machine Learning.
- Eseguire analisi sui dati in tempo reale.
- Sviluppare report in Power BI.
Proteggere un lakehouse
L'accesso a Lakehouse viene gestito tramite l'area di lavoro o la condivisione a livello di elemento. I ruoli delle aree di lavoro devono essere usati per i collaboratori poiché garantiscono l'accesso a tutti gli elementi all'interno dell'area di lavoro. La condivisione a livello di elemento è più adatta a concedere l'accesso per esigenze di sola lettura, ad esempio analisi o sviluppo di report di Power BI.
I lakehouse di Fabric supportano anche funzionalità di governance dei dati, incluse le etichette di riservatezza, e possono essere estesi tramite Microsoft Purview con il tenant di Fabric.
Nota
Per altre informazioni, vedere la documentazione Sicurezza in Microsoft Fabric.