Esercizio - Disponibilità elevata e ripristino di emergenza - Istanza gestita di SQL abilitata per Azure Arc
Importante
I moduli di questo percorso di apprendimento sono da seguire in successione. Per completare questo esercizio, è necessario completare prima i moduli precedenti di questo percorso.
Esercizio 1 - Configurazione di repliche secondarie leggibili
In questo esercizio verranno configurate e utilizzate secondarie leggibili per sfruttare la replica secondaria per i carichi di lavoro di sola lettura.
Aprire Azure Data Studio.
Espandere la scheda Connessioni.
Espandere Controller Azure Arc.
Espandere il controller dei dati.
Configurare i dettagli seguenti per l’istanza gestita di SQL abilitata per business critical Tier Arc:
$Env:SQLMIName = 'enter Business Critical Tier SQL Managed Instance Name here' $Env:MyNamespace = 'enter data controller namespace here' $Env:MyReadableSecondaries = 2Eseguire il comando seguente per esaminare la configurazione corrente di Istanza gestita di SQL abilitata per Arc. Cercare le repliche per esaminare la configurazione corrente:
az sql mi-arc show -n $Env:SQLMIName ` --k8s-namespace $Env:MyNamespace ` --use-k8s"replicas": [ { "availabilityMode": "SYNCHRONOUS_COMMIT", "connectedState": "CONNECTED", "replicaName": "ae-msl-sqlmi2-0", "role": "PRIMARY", "secondaryRoleAllowConnections": "ALL", "synchronizationState": "HEALTHY" }, { "availabilityMode": "SYNCHRONOUS_COMMIT", "connectedState": "CONNECTED", "replicaName": "ae-msl-sqlmi2-1", "role": "SECONDARY", "secondaryRoleAllowConnections": "ALL", "synchronizationState": "HEALTHY" }, { "availabilityMode": "SYNCHRONOUS_COMMIT", "connectedState": "CONNECTED", "replicaName": "ae-msl-sqlmi2-2", "role": "SECONDARY", "secondaryRoleAllowConnections": "NO", "synchronizationState": "HEALTHY" } ]Eseguire il comando seguente per configurare due database secondarie leggibili:
az sql mi-arc update --name $Env:SQLMIName ` --readable-secondaries $Env:MyReadableSecondaries ` --k8s-namespace $Env:MyNamespace ` --use-k8s
Eseguire di nuovo il passaggio 6 per visualizzare la nuova configurazione. Sia
ae-msl-sqlmi2-1cheae-msl-sqlmi2-2sono ora configurate come secondarie leggibili."replicas": [ { "availabilityMode": "SYNCHRONOUS_COMMIT", "connectedState": "CONNECTED", "replicaName": "ae-msl-sqlmi2-0", "role": "PRIMARY", "secondaryRoleAllowConnections": "ALL", "synchronizationState": "HEALTHY" }, { "availabilityMode": "SYNCHRONOUS_COMMIT", "connectedState": "CONNECTED", "replicaName": "ae-msl-sqlmi2-1", "role": "SECONDARY", "secondaryRoleAllowConnections": "ALL", "synchronizationState": "HEALTHY" }, { "availabilityMode": "SYNCHRONOUS_COMMIT", "connectedState": "CONNECTED", "replicaName": "ae-msl-sqlmi2-2", "role": "SECONDARY", "secondaryRoleAllowConnections": "ALL", "synchronizationState": "HEALTHY" } ]Cercare i risultati del comando dell'interfaccia della riga di comando eseguito nel passaggio 8. Cercare gli endpoint. Recuperare il valore dell'endpoint secondario.
Nella scheda Connessioni, selezionare Nuova connessione. Immettere i dettagli di connessione per l'endpoint secondario.
Selezionare Connetti.
Aprire una nuova finestra di query per la nuova connessione endpoint secondaria ed eseguire i comandi seguenti. Il nome del server non deve essere la replica primaria corrente:
Select @@ServerName; Use AdventureWorks2019 GO Select * From HumanResources.Employee;
Esercizio 2 - Individuare il livello per utilizzo generico dell’Istanza gestita di SQL abilitata per Azure Arc
Per questo esercizio si simula l'errore o la perdita del pod Kubernetes che ospita e esegue il contenitore di Istanza gestita di SQL per utilizzo generico livello Arc abilitato per l'arco.
Aprire Azure Data Studio.
Espandere la scheda Connessioni.
Fare clic con il pulsante destro del mouse sul livello per utilizzo generico dell’Istanza gestita di SQL e scegliere Nuova query.
Eseguire la query seguente per visualizzare l'accesso all'istanza di SQL Server e al database AdventureWorks2019:
Select @@ServerName; Use AdventureWorks2019 GO Select * From HumanResources.Employee;Aprire la finestra Terminale.
Eseguire i comandi seguenti per visualizzare i pod Kubernetes:
$Env:MyNamespace = 'enter your data controller namespace here' kubectl get pods -n $Env:MyNamespace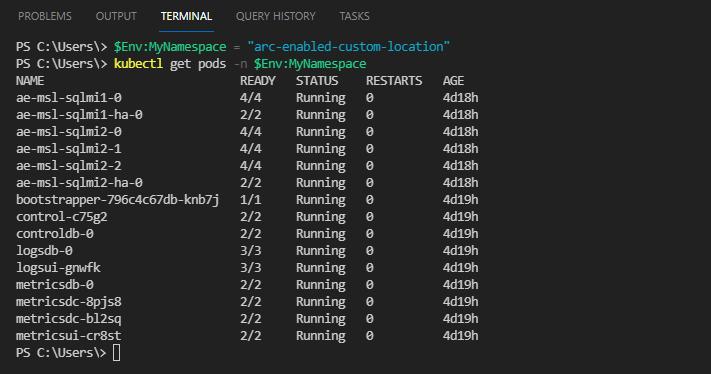
Simulare un errore del pod eseguendo il comando seguente:
$Env:MyGPPod = 'enter SQL Managed Instance Name here-0' kubectl delete pod $Env:MyGPPod -n $Env:MyNamespace
Eseguire il comando seguente per visualizzare lo stato dei pod:
kubectl get pods -n $Env:MyNamespace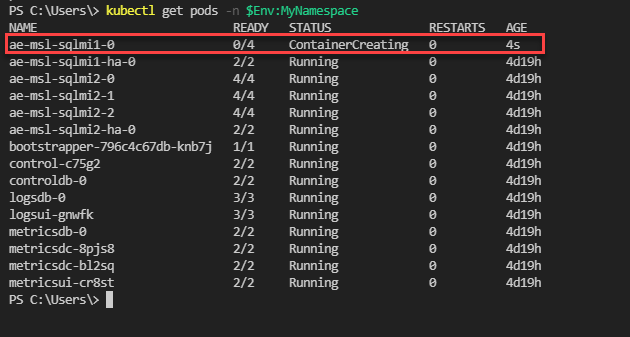
Eseguire di nuovo il passaggio 8 per monitorare la ridistribuzione del pod. Una volta che il pod è di nuovo in esecuzione, è possibile eseguire controlli standard per assicurarsi che l'istanza di SQL Server sia disponibile e funzionante in base alle esigenze.
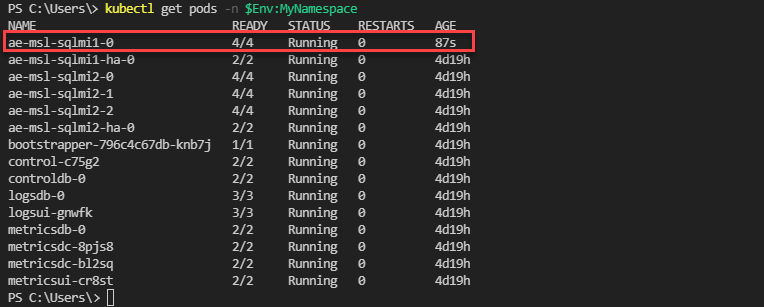
Eseguire di nuovo il passaggio 4 per verificare se l'istanza è nuovamente disponibile. Ciò dimostra che l'istanza è nuovamente disponibile e accessibile.
Esercizio 3 - Individuazione della disponibilità elevata del livello Business critical dell’Istanza gestita SQL abilitata per Arc
Per questo esercizio, verrà simulato l'errore o la perdita del pod Kubernetes che ospita ed esegue il contenitore Istanza gestita di SQL di livello Arc abilitato per l'arco business critical.
Aprire Azure Data Studio.
Espandere la scheda Connessioni.
Fare clic con il pulsante destro del mouse sul livello business critical dell’Istanza gestita di SQL e scegliere Nuova query.
Eseguire la query seguente per visualizzare l'accesso all'istanza di SQL Server e al database AdventureWorks2019:
Select @@ServerName; Use AdventureWorks2019 GO Select * From HumanResources.Employee;Aprire la finestra Terminale.
Eseguire i comandi seguenti per visualizzare i pod Kubernetes:
$Env:MyNamespace = 'enter your data controller namespace here' kubectl get pods -n $Env:MyNamespace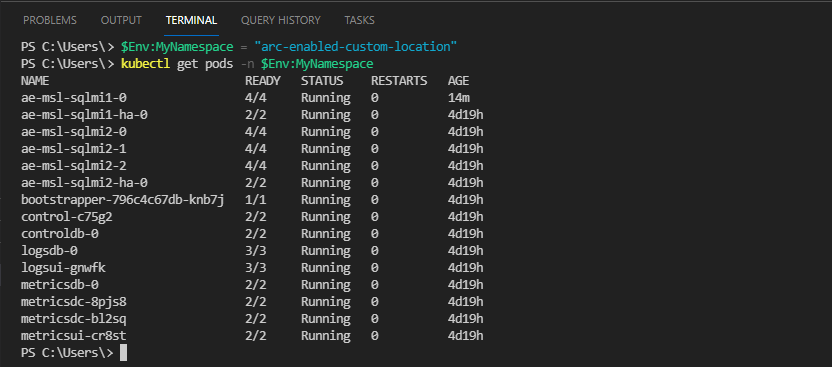
Simulare un errore del pod eseguendo il comando seguente:
$Env:MyBCPod = 'enter SQL Managed Instance Name here-0' kubectl delete pod $Env:MyBCPod -n $Env:MyNamespace
Eseguire il comando seguente per visualizzare lo stato dei pod:
kubectl get pods -n $Env:MyNamespace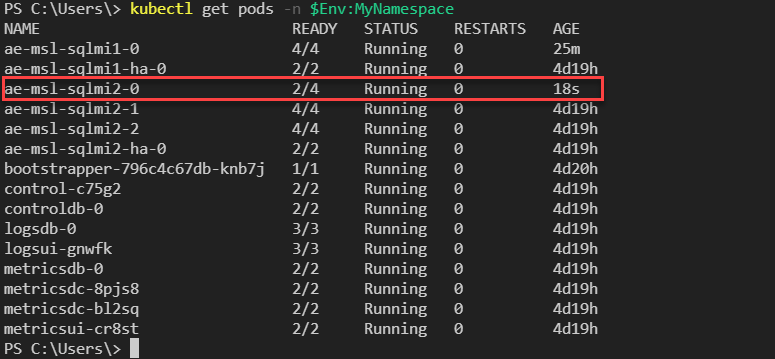
Eseguire di nuovo il passaggio 4 per determinare se l'istanza è disponibile ed in esecuzione in
SQLMI-1. L'interruzione del servizio deve essere minima e le applicazioni necessitano di una funzionalità di riconnessione.Eseguire il comando seguente per visualizzare lo stato del gruppo di disponibilità contenuto:
$Env:MyResource-group = 'enter your resource group name here' az sql mi-arc list --k8s-namespace $Env:MyNamespace --use-k8sControllare lo stato di tutte le repliche nel gruppo di disponibilità contenuto con il comando seguente. Cercare
highAvailabilitynell'output:$Env:SQLMIName = 'enter your SQLMI name here' az sql mi-arc show --name $Env:SQLMIName --resource-group $Env:MyresourceGroup"highAvailability": { "healthState": "Healthy", "lastUpdateTime": "2022-06-07T00:39:38.927189Z", "mirroringCertificate": "-----BEGIN CERTIFICATE-----\n \n-----END CERTIFICATE-----\n", "replicas": [ { "availabilityMode": "SYNCHRONOUS_COMMIT", "connectedState": "CONNECTED", "replicaName": "ae-msl-sqlmi2-0", "role": "SECONDARY", "secondaryRoleAllowConnections": "ALL", "synchronizationState": "HEALTHY" }, { "availabilityMode": "SYNCHRONOUS_COMMIT", "connectedState": "CONNECTED", "replicaName": "ae-msl-sqlmi2-1", "role": "PRIMARY", "secondaryRoleAllowConnections": "ALL", "synchronizationState": "HEALTHY" }, { "availabilityMode": "SYNCHRONOUS_COMMIT", "connectedState": "CONNECTED", "replicaName": "ae-msl-sqlmi2-2", "role": "SECONDARY", "secondaryRoleAllowConnections": "ALL", "synchronizationState": "HEALTHY" } ] }Preparare il failover manuale dalla replica primaria esistente (
'your sqlmi name-1') alla replica primaria originale ('your sqlmi name-0'). Nella finestra Terminale eseguire i comandi seguenti per impostare la replica primaria preferita:$Env:MyPreferredPrimaryReplica = 'your sqlmi name-1' az sql mi-arc update --name $Env:SQLMIName ` --k8s-namespace $Env:MyNamespace ` --use-k8s ` --preferred-primary-replica $Env:MyPreferredPrimaryReplica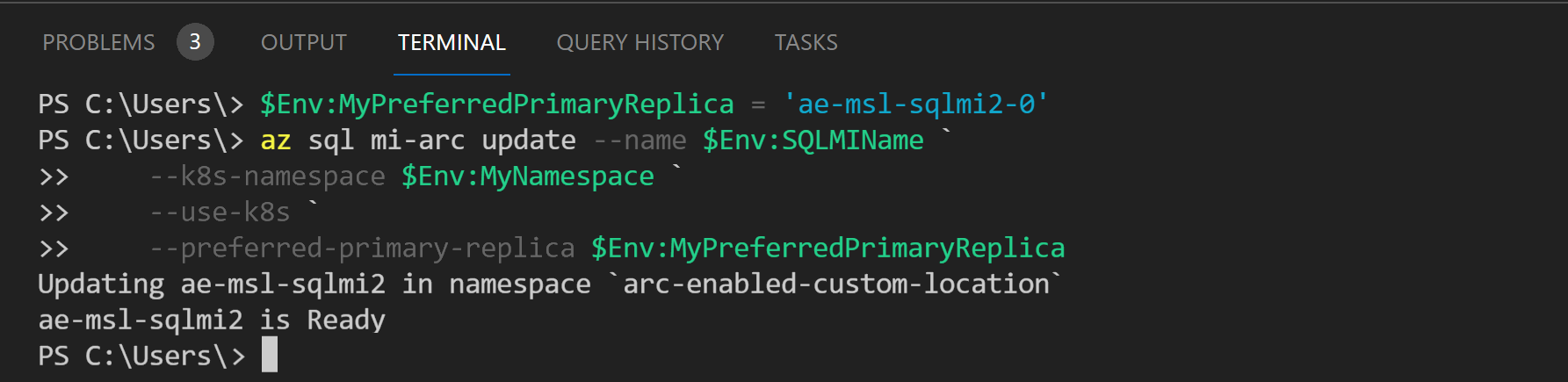
Eseguire di nuovo il comando dell'interfaccia della riga di comando
az sql mi-arc updatedal passaggio 12 per eseguire il failover effettivo.Eseguire di nuovo il passaggio 11 per confermare i ruoli di replica primaria modificati.
"highAvailability": { "healthState": "Healthy", "lastUpdateTime": "2022-06-07T00:39:38.927189Z", "mirroringCertificate": "-----BEGIN CERTIFICATE-----\n \n-----END CERTIFICATE-----\n", "replicas": [ { "availabilityMode": "SYNCHRONOUS_COMMIT", "connectedState": "CONNECTED", "replicaName": "ae-msl-sqlmi2-0", "role": "PRIMARY", "secondaryRoleAllowConnections": "ALL", "synchronizationState": "HEALTHY" }, { "availabilityMode": "SYNCHRONOUS_COMMIT", "connectedState": "CONNECTED", "replicaName": "ae-msl-sqlmi2-1", "role": "SECONDARY", "secondaryRoleAllowConnections": "ALL", "synchronizationState": "HEALTHY" }, { "availabilityMode": "SYNCHRONOUS_COMMIT", "connectedState": "CONNECTED", "replicaName": "ae-msl-sqlmi2-2", "role": "SECONDARY", "secondaryRoleAllowConnections": "ALL", "synchronizationState": "HEALTHY" } ] }
Esercizio 4 - Ripristini temporizzati
Per questo esercizio verranno usati i backup automatizzati già creati per il database AdventureWorks2019 ripristinato nell'ambiente di Istanza gestita di SQL abilitato per Arc in precedenza.
Aprire Azure Data Studio.
Espandere la scheda Connessioni.
Espandere Controller Azure Arc.
Espandere il controller dei dati Arc.
Fare clic con il pulsante destro del mouse sull'Istanza gestita di SQL abilitata per Arc e scegliere Gestisci.
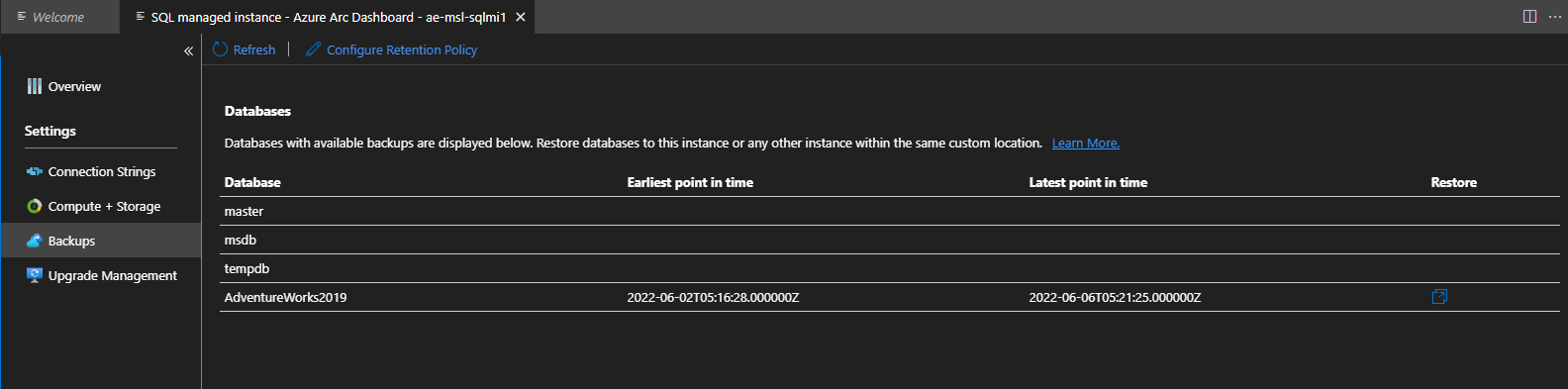
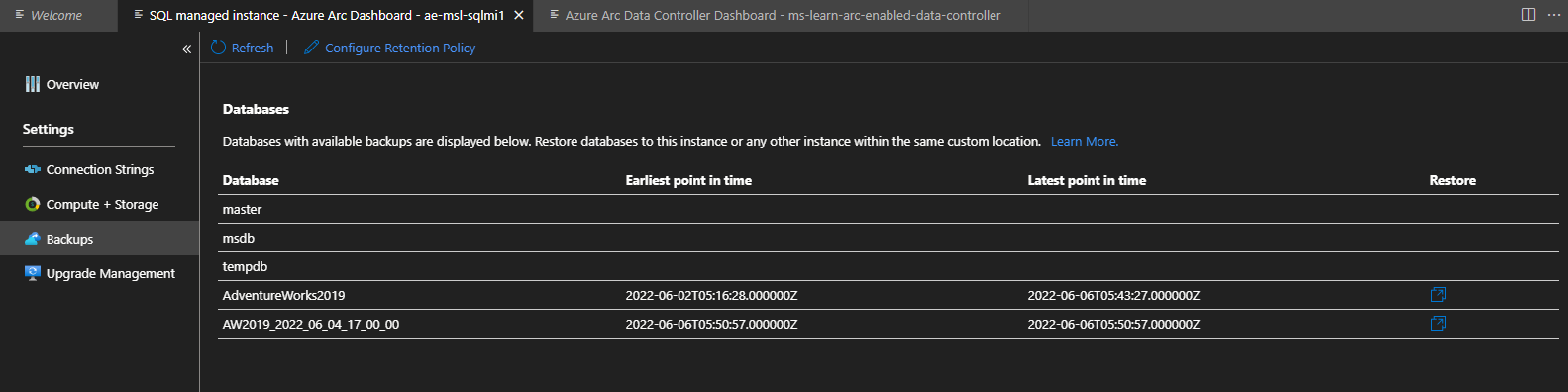
Selezionare Backup.
Esaminare il primo e l'ultimo punto di ripristino e per il database di esempio AdventureWorks2019.
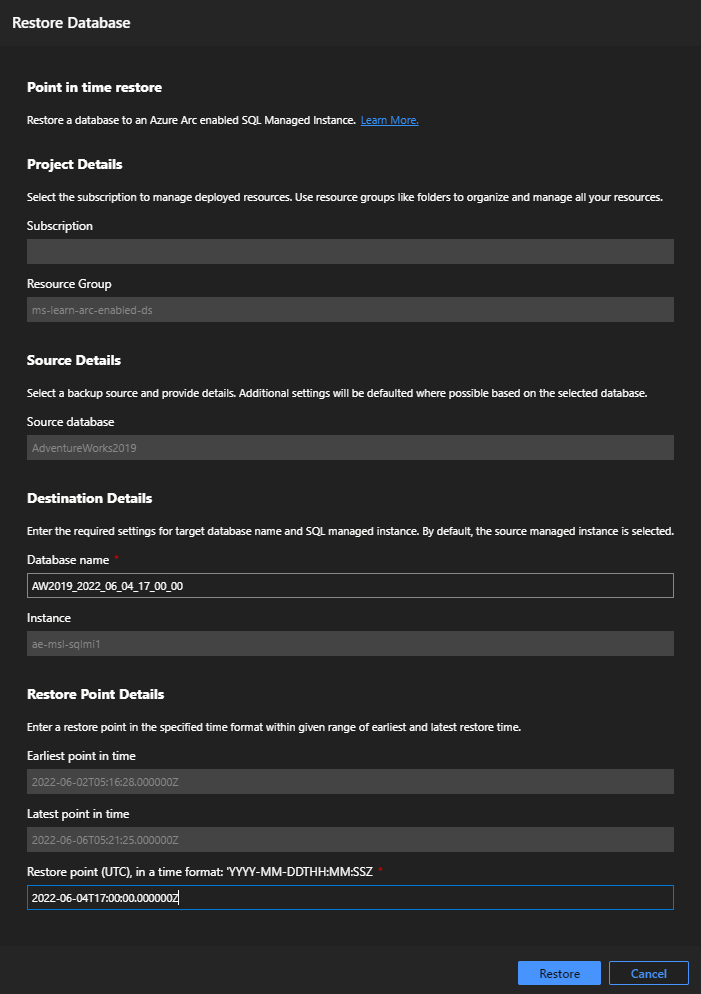
Selezionare l'icona Repristina per avviare il processo di ripristino temporizzato.
Immettere un nome per il database appena ripristinato.
Immettere un punto di ripristino compreso tra il primo e l’ultimo punto di ripristino e che si vuole ripristinare.
Selezionare Ripristina.
Per monitorare lo stato di avanzamento del ripristino temporizzato, eseguire il comando seguente nella finestra del terminale di Azure Data Studio:
kubectl get sqlmirestoretask -n 'enter your data controller namespace here'Nota
Questo comando potrebbe richiedere del tempo, a seconda del tempo scelto per il ripristino temporizzato.
Aggiornare l'elenco di database nella scheda Backup.
Connettersi all'istanza di SQL Server e confermare che il database esista e che sia possibile eseguire query sui dati.
Esercizio 5 - Distribuzione di gruppi di failover di Azure dell'Istanza gestita di SQL abilitata per Arc
In questo esercizio verrà usato un ambiente business critical dell’Istanza gestita di SQL abilitata per Arc. L'ambiente è costituito da un Istanza gestita di SQL abilitata per Arc che si trova nel sito primario e da un Istanza gestita di SQL abilitata per Arc duplicata disponibile nel sito secondario.
Prerequisiti
Prima di procedere, assicurarsi di completare i passaggi seguenti:
- Accedere a un cluster Kubernetes supportato nel sito primario.
- Accedere a un cluster Kubernetes supportato nel sito secondario.
- Assicurarsi di impostare il tipo di licenza su Ripristino di emergenza.
- Accedere a una posizione di archiviazione locale condivisa a cui entrambe le Istanze gestite di SQL abilitate per Azure Arc hanno accesso.
- Completare i moduli seguenti in questo percorso di apprendimento:
- Modulo 1: esercizio - Distribuire un controller dati di Azure Arc (per il sito primario).
- Modulo 2: esercizio - Distribuire un’Istanza gestita di SQL abilitata per Azure Arc (per il sito primario).
- Modulo 2: esercizio - Ripristinare AdventureWorks2019 nell'Istanza gestita di SQL abilitata per Arc del sito primario.
- Modulo 1: esercizio - Distribuire un controller dati di Azure Arc (per il sito secondario)
- Modulo 2: esercizio - Distribuire un’Istanza gestita di SQL abilitata per Azure Arc (per il sito secondario).
Distribuire gruppi di failover dell’Istanza gestita di SQL abilitata per Arc
In Azure Data Studio, aprire la finestra Terminale.
Assicurarsi di essere connessi all’abbonamento di Azure.
Preparare i valori dei parametri del sito primario per l’Istanza gestita di SQL abilitata per Arc:
## Primary Site Arc-enabled SQL Managed Instance parameter details $Env:MySubscription = 'enter your subscription id here' $Env:MyPrimaryResourceGroup = 'enter your primary site resource group name' $Env:MyPrimaryNamespace = 'enter your primary site data controller namespace' $Env:MyPrimaryInstance = 'enter your primary site SQL Managed Instance name' $Env:MyCertFullPath = 'enter you local path/sqlcerts' $Env:MyPrimaryCertFile = 'sqlprimary.pem' ## Use anyname you wish $Env:MyAFG = 'aemsldag' ## Use any name you wish $Env:MyPrimaryDAG = 'sqlprimary-dag' ## Use anyname you wish $Env:MyPrimaryCluster = 'enter your primary site kubernetes cluster name here'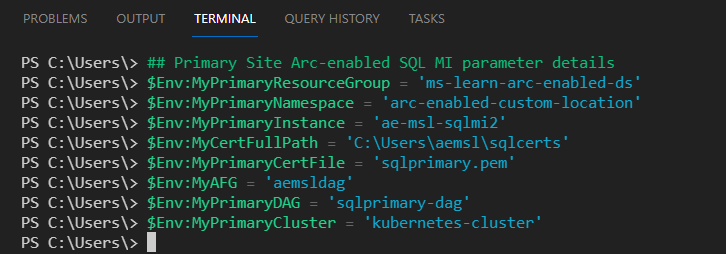
Assicurarsi di essere connessi al cluster Kubernetes del sito primario:
Kubectl config use-context $Env:MyPrimaryCluster
Recuperare il certificato di mirroring per il sito primario. Questa operazione è necessaria per accedere a entrambi i siti. In questo esempio usare il percorso home dell'account utente locale. Assicurarsi di impostarla in modo appropriato per l'ambiente in uso. È possibile confermare la creazione del file di certificato
sqlprimary.pemnel percorso locale configurato.az sql mi-arc get-mirroring-cert --subscription $Env:MySubcriptionID ` --name $Env:MyPrimaryInstance ` --cert-file "$Env:MyCertFullPath\$Env:MyPrimaryCertFile" ` --k8s-namespace $Env:MyPrimaryNamespace ` --use-k8sRecuperare l'indirizzo IP dell'endpoint di mirroring dell’Istanza gestita di SQL per il sito primario:
$PrimaryMirroringEndpoint = $( az sql mi-arc show -n $Env:MyPrimaryInstance ` --resource-group $Env:MyPrimaryResourceGroup ` -o tsv ` --query 'properties.k8SRaw.status.endpoints.mirroring' ) $Env:MyPrimaryMirroringIP = "tcp://$PrimaryMirroringEndpoint"Preparare i valori dei parametri del sito secondario dell'Istanza gestita di SQL abilitata per Arc:
$Env:MySecondaryResourceGroup = 'enter your secondary site resource group name' $Env:MySecondaryNamespace = 'enter your secondary site data controller namespace' $Env:MySecondaryInstance = 'enter your secondary site SQL Managed Instance name' $Env:MySecondaryCertFile = 'sqlsecondary.pem' ## Use anyname you wish $Env:MySecondaryDAG = 'sqlsecondary-dag' ## Use anyname you wish $Env:MySecondaryCluster = 'enter your secondary site kubernetes cluster name here'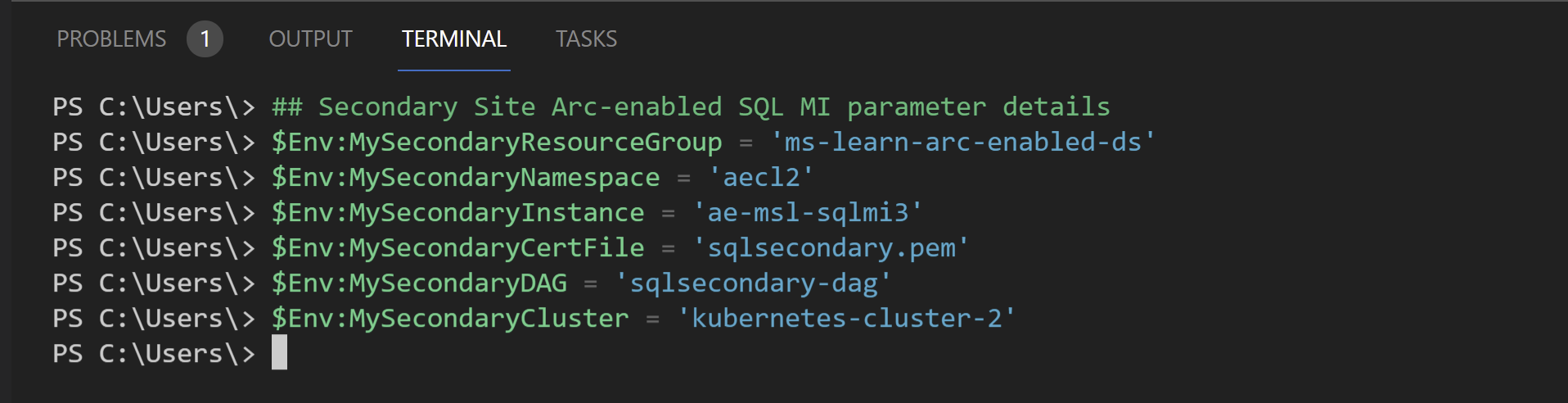
Assicurarsi di essere connessi al cluster Kubernetes del sito secondario:
Kubectl config use-context $Env:MySecondaryCluster
Recuperare il certificato di mirroring per il sito secondario. Questa operazione è necessaria per accedere a entrambi i siti. In questo esempio viene usata la posizione Home dell'account utente locale. Assicurarsi di impostarla in modo appropriato per l'ambiente in uso. È possibile confermare la creazione del file di certificato
sqlsecondary.pemnel percorso locale configurato.az sql mi-arc get-mirroring-cert --subscription $Env:MySubcriptionID ` --name $Env:MySecondaryInstance ` --cert-file "$Env:MyCertFullPath\$Env:MySecondaryCertFile" ` --k8s-namespace $Env:MySecondaryNamespace ` --use-k8sRecuperare l'indirizzo IP dell'endpoint di mirroring dell’Istanza gestita di SQL per il sito secondario:
$SecondaryMirroringEndpoint = $( az sql mi-arc show -n $Env:MySecondaryInstance ` --resource-group $Env:MySecondaryResourceGroup ` -o tsv ` --query 'properties.k8SRaw.status.endpoints.mirroring' ) $Env:MySecondaryMirroringIP = "tcp://$SecondaryMirroringEndpoint"Assicurarsi di essere connessi al cluster Kubernetes del sito primario:
Kubectl config use-context $Env:MyPrimaryClusterCreare la risorsa primaria del gruppo di failover di Azure nel sito primario:
az sql instance-failover-group-arc create --shared-name $Env:MyAFG ` --name $Env:MyPrimaryDAG ` --mi $Env:MyPrimaryInstance ` --role primary ` --partner-mi $Env:MySecondaryInstance ` --partner-mirroring-url $Env:MySecondaryMirroringIP ` --partner-mirroring-cert-file "$Env:MyCertFullPath\$Env:MySecondaryCertFile" ` --k8s-namespace $Env:MyPrimaryNamespace ` --use-k8s ## The output should display: Deploying $Env:MyPrimaryDAG in namespace $Env:MyPrimaryNamespace ## $Env:MyPrimaryDAG is Ready ## Confirm primary resource has been created az sql instance-failover-group-arc show --subscription $Env:MySubcriptionID ` --name $Env:MyPrimaryDAG ` --k8s-namespace $Env:MyPrimaryNamespace ` --use-k8s ## The output should be similar to this: "sharedName": "aemsldag", "sourceMI": "ae-msl-sqlmi2", "partnerMI": "ae-msl-sqlmi3", "partnerMirroringURL": "tcp://20.70.91.199:5022"Assicurarsi di essere connessi al cluster Kubernetes del sito secondario.
Kubectl config use-context $Env:MySecondaryClusterCreare la risorsa secondaria del gruppo di failover di Azure nel sito secondario.
az sql instance-failover-group-arc create --shared-name $Env:MyAFG ` --name $Env:MySecondaryDAG ` --mi $Env:MySecondaryInstance ` --role secondary ` --partner-mi $Env:MyPrimaryInstance ` --partner-mirroring-url $Env:MyPrimaryMirroringIP ` --partner-mirroring-cert-file "$Env:MyCertFullPath\$Env:MyPrimaryCertFile" ` --k8s-namespace $Env:MySecondaryNamespace ` --use-k8s ## The output should display: Deploying $Env:MySecondaryDAG in namespace $Env:MySecondaryNamespace ## $Env:MySecondaryDAG is Ready ## Confirm secondary resource has been created az sql instance-failover-group-arc show --subscription $Env:MySubcriptionID ` --name $Env:MySecondaryDAG ` --k8s-namespace $Env:MySecondaryNamespace ` --use-k8s ## The output should be similar to this: "sharedName": "aemsldag", "sourceMI": "ae-msl-sqlmi3", "partnerMI": "ae-msl-sqlmi2", "partnerMirroringURL": "tcp://20.92.195.233:5022"Aprire SQL Server Management Studio (SSMS) e connettersi all'endpoint esterno primario per l'istanza del sito primario. Espandere Disponibilità elevata Always On. Verrà ora visualizzato il gruppo di failover di Azure appena creato.
In SQL Server Management Studio connettersi all'endpoint esterno primario per l'istanza del sito secondario. Espandere Disponibilità elevata Always On. Verrà ora visualizzato il gruppo di failover di Azure appena creato.
Espandere l'albero del database nell'istanza del sito secondario. Verrà visualizzato il database AdventureWorks2019 ripristinato nell'istanza del sito primaria in precedenza.
Si noti che non è stato necessario eseguire alcuna attività per trasferire il database del sito primario nell'istanza del sito secondario. Con la creazione del gruppo di failover di Azure (gruppo di disponibilità distribuito), tutti i database nell'istanza primaria vengono automaticamente sottoposti a seeding nel sito secondario. A seconda delle dimensioni del database, la larghezza di banda della rete tra il sito primario e quello secondario determinerà il tempo di sincronizzazione dei database.