Gestire le analogie tra ambienti usando modelli di pipeline
Quando si distribuiscono le modifiche in più ambienti, i passaggi necessari per la distribuzione in ogni ambiente sono simili o identici. In questa unità si apprenderà come usare i modelli di pipeline per evitare la ripetizione e consentire il riutilizzo del codice della pipeline.
Distribuzione in più ambienti
Dopo aver parlato con i colleghi del team del sito Web, si decide di usare la pipeline seguente per il sito Web dell'azienda di giocattoli:
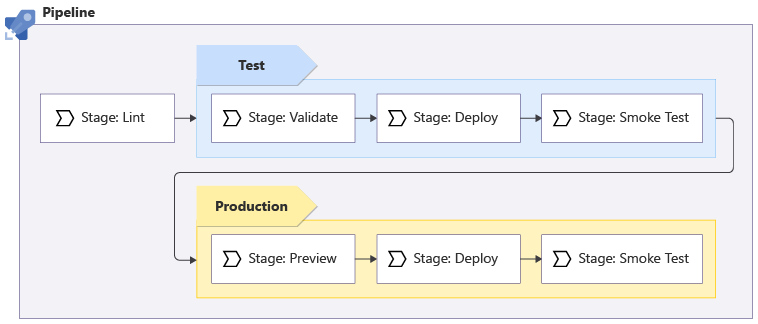
La pipeline esegue il linter Bicep per verificare che il codice Bicep sia valido e segua le procedure consigliate.
Il linting avviene nel codice Bicep senza doversi connettere ad Azure, quindi non importa il numero di ambienti in cui si esegue la distribuzione. Viene eseguito una volta sola.
La pipeline viene distribuita nell'ambiente di test. Questa fase richiede:
- Esecuzione della convalida preliminare di Azure Resource Manager.
- Distribuzione del codice Bicep.
- Esecuzione di alcuni test sull'ambiente di test.
Se una parte della pipeline ha esito negativo, l'intera pipeline viene arrestata in modo da poter analizzare e risolvere il problema. Tuttavia, se tutte le operazioni hanno esito positivo, la pipeline continua a essere distribuita nell'ambiente di produzione:
- La pipeline esegue un passaggio di anteprima, che esegue l'operazione di simulazione nell'ambiente di produzione per elencare le modifiche che verrebbero apportate alle risorse di Azure di produzione. La fase di produzione convalida anche la distribuzione, quindi non è necessario eseguire una fase di convalida separata per l'ambiente di produzione.
- La pipeline viene sospesa per la convalida manuale.
- Se si riceve l'approvazione, la pipeline esegue i test di distribuzione e gli smoke test sull'ambiente di produzione.
Alcune di queste fasi vengono ripetute tra gli ambienti di test e di produzione e alcune vengono eseguite solo per ambienti specifici:
| Fase | Ambienti |
|---|---|
| Linting | Nessuno dei due: il linting non funziona su un ambiente |
| Convalida | Solo test |
| Anteprima | Solo produzione |
| Distribuzione | Entrambi gli ambienti |
| Smoke test | Entrambi gli ambienti |
Quando è necessario ripetere i passaggi nella pipeline, è possibile provare a copiare e incollare le definizioni dei passaggi. Tuttavia, è consigliabile evitare tale pratica. È facile commettere accidentalmente piccoli errori o che si verifichino errori di sincronizzazione quando si duplica il codice della pipeline. E in futuro, quando sarà necessario apportare una modifica ai passaggi, si dovrà ricordare di applicare la modifica in più posizioni.
Modelli di pipeline
I modelli di pipeline consentono di creare sezioni riutilizzabili delle definizioni della pipeline. I modelli possono definire passaggi, processi o persino intere fasi. È possibile usare i modelli per riutilizzare parti di una pipeline più volte all'interno di una singola pipeline o anche in più pipeline. È anche possibile creare un modello per un set di variabili che si desidera riutilizzare in più pipeline.
Un modello è semplicemente un file YAML che contiene il contenuto riutilizzabile. Un modello semplice per una definizione di passaggio potrebbe essere simile al seguente ed essere salvato in un file denominato script.yml:
steps:
- script: |
echo Hello world!
È possibile usare un modello nella pipeline usando la parola chiave template nella posizione in cui si definisce normalmente il singolo passaggio:
jobs:
- job: Job1
pool:
vmImage: 'windows-latest'
steps:
- template: script.yml
- job: Job2
pool:
vmImage: 'ubuntu-latest'
steps:
- template: script.yml
Modelli annidati
È anche possibile annidare i modelli all'interno di altri modelli. Si supponga che il file precedente si chiamasse jobs.yml e si crei un file denominato azure-pipelines.yml che riutilizza il modello di processo in più fasi della pipeline:
trigger:
branches:
include:
- main
pool:
vmImage: ubuntu-latest
stages:
- stage: Stage1
jobs:
- template: jobs.yml
- stage: Stage2
jobs:
- template: jobs.yml
Quando si annidano o si riutilizzano più volte i modelli in una singola pipeline, è necessario prestare attenzione a non usare accidentalmente lo stesso nome per più risorse della pipeline. Ad esempio, ogni processo all'interno di una fase necessita del proprio identificatore. Quindi, se si definisce l'identificatore del processo in un modello, non è possibile riutilizzarlo più volte nella stessa fase.
Quando si utilizzano set complessi di pipeline di distribuzione, può essere utile creare un repository Git dedicato per i modelli di pipeline condivisi. È quindi possibile riutilizzare lo stesso repository in più pipeline, anche se questi sono pensati per progetti diversi. Nel riepilogo è disponibile un collegamento ad altre informazioni.
Parametri del modello di pipeline
I parametri del modello di pipeline semplificano il riutilizzo dei file di modello, perché è possibile consentire piccole differenze nei modelli ogni volta che questi vengono usati.
Quando si crea un modello di pipeline, è possibile indicarne i parametri nella parte superiore del file:
parameters:
- name: environmentType
type: string
default: 'Test'
- name: serviceConnectionName
type: string
È possibile definire tutti i parametri desiderati. Ma proprio come per i parametri Bicep, è consigliabile non usare i parametri del modello di pipeline. È consigliabile semplificare il riutilizzo del modello da parte di un altro utente senza dover specificare troppe impostazioni.
Ogni parametro del modello di pipeline ha tre proprietà:
- Il nome del parametro che si usa per fare riferimento al parametro nei file di modello.
- Il tipo di parametro. I parametri supportano diversi tipi di dati, tra cui stringa, numero e valore booleano. È anche possibile definire modelli più complessi che accettano oggetti strutturati.
- Il valore predefinito del parametro, facoltativo. Se non si specifica un valore predefinito, è necessario specificare un valore quando viene usato il modello di pipeline.
Nell'esempio la pipeline definisce un parametro stringa denominato environmentType, che ha un valore predefinito Test e un parametro obbligatorio denominato serviceConnectionName.
Nel modello di pipeline si usa una sintassi speciale per fare riferimento al valore del parametro. Usare la macro ${{parameters.YOUR_PARAMETER_NAME}}, come in questo esempio:
steps:
- script: |
echo Hello ${{parameters.environmentType}}!
Si passa il valore per i parametri a un modello di pipeline usando la parola chiave parameters, come in questo esempio:
steps:
- template: script.yml
parameters:
environmentType: Test
- template: script.yml
parameters:
environmentType: Production
È anche possibile usare i parametri quando si assegnano gli identificatori ai processi e alle fasi nei modelli di pipeline. Questa tecnica risulta utile quando è necessario riutilizzare lo stesso modello più volte nella pipeline, come in questo caso:
parameters:
- name: environmentType
type: string
default: 'Test'
jobs:
- job: Job1-${{parameters.environmentType}}
pool:
vmImage: 'windows-latest'
steps:
- template: script.yml
- job: Job2-${{parameters.environmentType}}
pool:
vmImage: 'ubuntu-latest'
steps:
- template: script.yml
Condizioni
È possibile usare le condizioni della pipeline per specificare se un passaggio, un processo o persino una fase deve essere eseguito in base a una regola specificata. È possibile combinare parametri di modello e condizioni della pipeline per personalizzare il processo di distribuzione per molte situazioni diverse.
Si supponga, ad esempio, di definire un modello di pipeline che esegue la procedura di script. Si prevede di riutilizzare il modello per ogni ambiente. Quando si distribuisce l'ambiente di produzione, si vuole eseguire un altro passaggio. Ecco come ottenere questo risultato usando la macro if e l'operatore eq (uguale):
parameters:
- name: environmentType
type: string
default: 'Test'
steps:
- script: |
echo Hello ${{parameters.environmentType}}!
- ${{ if eq(parameters.environmentType, 'Production') }}:
- script: |
echo This step only runs for production deployments.
La condizione in questo caso si traduce in: se il valore del parametro environmentType è uguale a Production, eseguire i passaggi seguenti.
Suggerimento
Prestare attenzione al rientro del file YAML quando si usano condizioni come quelle nell'esempio. Per i passaggi a cui si applica la condizione è necessario impostare un rientro di un livello aggiuntivo.
È anche possibile specificare la proprietà condition in una fase, in un processo o in un passaggio. Ecco un esempio che mostra come usare l'operatore ne (non uguale) per specificare una condizione come se il valore del parametro environmentType non è uguale a Production, eseguire la procedura seguente:
- script: |
echo This step only runs for non-production deployments.
condition: ne('${{ parameters.environmentType }}', 'Production')
Sebbene le condizioni siano un modo per aggiungere flessibilità alla pipeline, è consigliabile non usarne troppe. Complicano la pipeline e rendono più difficile comprendere il flusso. Se il modello di pipeline ha molte condizioni, il modello potrebbe non essere la soluzione migliore per il flusso di lavoro che si prevede di eseguire e potrebbe essere necessario riprogettare la pipeline.
Prendere in considerazione anche l'uso di commenti YAML per spiegare le condizioni usate e qualsiasi altro aspetto della pipeline che potrebbe richiedere una spiegazione più approfondita. I commenti semplificano la comprensione e l'uso della pipeline in futuro. In tutti gli esercizi di questo modulo sono presenti commenti YAML di esempio.