Esplorare la migrazione di database molto grandi
I sistemi SAP spostati nel cloud di Azure in genere includono sistemi multinazionali di grandi dimensioni con istanza singola globale. Questi sistemi sono più grandi dei primi sistemi cliente distribuiti quando la piattaforma Azure è stata certificata per i carichi di lavoro SAP.
I database di dimensioni molto estese vengono ora comunemente spostati in Azure. Per i database di dimensioni superiori a 20 TB è necessario applicare tecniche e procedure aggiuntive per effettuare una migrazione dall'ambiente locale ad Azure con rischi ridotti e tempi di inattività accettabili.
Panoramica generale
Una migrazione di database di dimensioni molto estese interamente ottimizzata dovrebbe raggiungere una velocità effettiva di circa 2 TB all'ora o possibilmente maggiore. Ciò significa che il componente per il trasferimento dei dati di una migrazione da 20 TB può essere eseguito in circa 10 ore. È necessario eseguire vari passaggi di post-elaborazione e convalida. In generale, disponendo di tempo sufficiente per la preparazione e i test, è possibile spostare in Azure quasi ogni sistema cliente di qualunque dimensione.
Le migrazioni di database di dimensioni molto estese richiedono competenze significative, attenzione ai dettagli e capacità di analisi. Ad esempio, l'effetto netto di una divisione di tabella deve essere misurato e analizzato. Le suddivisioni di una tabella di grandi dimensioni in più di 50 esportazioni parallele possono ridurre notevolmente il tempo necessario per esportare una tabella, ma troppe suddivisioni di tabelle possono comportare un aumento significativo dei tempi di importazione. È quindi necessario calcolare e testare l'effetto netto dell'azione di suddivisione della tabella. Un consulente esperto nella migrazione di sistemi operativi/database concessi su licenza dovrebbe avere sicuramente familiarità con questi concetti e strumenti. Verranno evidenziati alcuni contenuti specifici di Azure per le migrazioni di database di dimensioni molto estese.
Nello specifico verrà trattata la migrazione eterogenea di sistemi operativi/database ad Azure con SQL Server come database di destinazione, mediante strumenti come R3load e Migmon. La procedura per la migrazione non può essere applicata a copie di sistema omogenee, ovvero a una copia in cui il sistema di gestione del database e l'architettura del processore (ordine Endian) rimangono invariate. In generale, le copie di sistema omogenee presentano tempi di inattività ridotti, indipendentemente dalle dimensioni del sistema DBMS, perché è possibile usare il log shipping per sincronizzare una copia del database in Azure.
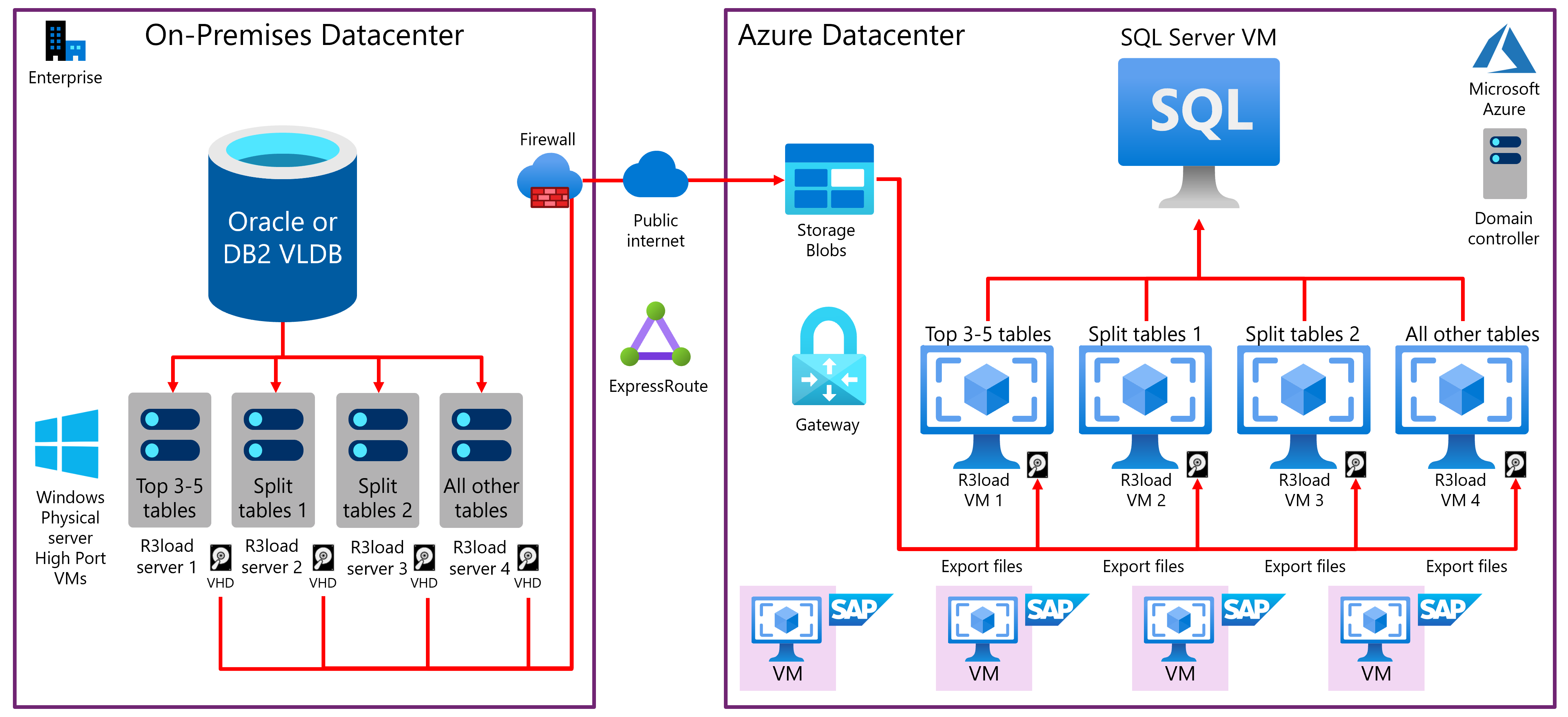
Dopo i punti chiave è riportato un diagramma a blocchi che raffigura una tipica migrazione del sistema operativo/database di dimensioni molto estese e lo spostamento in Azure:
Il sistema operativo/database di origine corrente è spesso AIX, HPUX, Solaris o Linux e DB2 o Oracle.
Il sistema operativo di destinazione è Windows, SUSE 12.3, Redhat 7.x o Oracle Linux 7.x.
Il database di destinazione è solitamente SQL Server o Oracle 12.2.
Le prestazioni dell'hardware IBM pSeries e Solaris SPARC e del thread HP Superdome sono notevolmente inferiori rispetto ai moderni server Intel a basso costo e, pertanto, R3load viene eseguito su server Intel distinti.
VMware richiede speciali procedure di ottimizzazione e configurazione per ottenere prestazioni di rete efficienti, stabili e prevedibili. In genere, vengono usati server fisici come server R3load e non macchine virtuali.
Vengono comunemente usati quattro server R3load di esportazione, anche se non esiste alcun limite nel numero di server di esportazione. Una configurazione tipica potrebbe essere:
- Server di esportazione 1: dedicato alle prime quattro tabelle più grandi (a seconda del grado di asimmetria della distribuzione dei dati nel database di origine).
- Server di esportazione 2: dedicato a tabelle sottoposte a suddivisione.
- Server di esportazione 3: dedicato a tabelle sottoposte a suddivisione.
- Server di esportazione 4: dedicato a tutte le tabelle rimanenti.
I file di dump di esportazione vengono trasferiti dal disco locale al server R3load Intel in esecuzione in Azure usando AzCopy tramite Internet pubblico. Questo è in genere più veloce rispetto a usare ExpressRoute.
Il controllo e la sequenza dell'importazione avvengono tramite il file segnale (SGN) generato automaticamente al completamento di tutti i pacchetti di esportazione. Ciò consente un'esportazione/importazione semi parallela.
L'importazione in SQL Server o in Oracle è strutturata in modo analogo alla procedura di esportazione e vengono usati quattro server di importazione separati. costituiti da server R3load dedicati con rete accelerata. È consigliabile che i server applicazioni SAP non siano per questa attività.
I database di dimensioni molto estese usano in genere macchine virtuali E64v3, M64 o M128 con Archiviazione Premium. Il log delle transazioni può essere inserito nel disco SSD locale per velocizzare le operazioni di scrittura nel log e rimuovere le operazioni di I/O al secondo e la larghezza di banda di I/O dalla quota della macchina virtuale. Al termine della migrazione, il log delle transazioni deve essere archiviato in un disco permanente.