Combinare e ottimizzare i dati
Le organizzazioni spesso raccolgono diversi tipi di informazioni da più origini. Le informazioni vengono archiviate in un numero elevato di tabelle. In alcuni casi, potrebbe essere necessario unire tramite join le tabelle in base alle relazioni logiche esistenti tra loro, per analisi o report più approfonditi. Nello scenario della società di vendita al dettaglio si usano tabelle per clienti, prodotti e informazioni di vendita.
In questo modulo vengono illustrati i vari modi per combinare i dati nelle query Kusto per fornire ai membri del team le informazioni necessarie per aumentare la consapevolezza del prodotto e aumentare le vendite.
Informazioni sui dati
Prima di iniziare a scrivere query che combinano informazioni delle tabelle, è necessario conoscere i propri dati. Quando si lavora con le query Kusto, si vuole considerare le tabelle come ampiamente appartenenti a una delle due categorie:
- Tabelle dei fatti: tabelle i cui record sono fatti non modificabili, ad esempio la tabella SalesFact nello scenario aziendale di vendita al dettaglio. In queste tabelle i record vengono aggiunti progressivamente in un flusso oppure in blocchi di grandi dimensioni. I record rimangono nella tabella fino a quando non vengono rimossi e non vengono mai aggiornati.
- Tabelle delle dimensioni: tabelle i cui record sono dimensioni modificabili, come le tabelle Customers e Products nello scenario aziendale di vendita al dettaglio. Queste tabelle contengono dati di riferimento, ad esempio tabelle di ricerca da un identificatore di entità alle relative proprietà. Le tabelle delle dimensioni non vengono aggiornate periodicamente con nuovi dati.
Nello scenario della società di vendita al dettaglio si usano le tabelle delle dimensioni per arricchire la tabella SalesFact con informazioni aggiuntive o per fornire altre opzioni per filtrare i dati per le query.
Si vogliono anche comprendere i volumi di dati usati e la relativa struttura o schema (nomi e tipi di colonna). È possibile eseguire le query seguenti per ottenere queste informazioni sostituendo TABLE_NAME con il nome della tabella da esaminare:
Per ottenere il numero di record in una tabella, usare l'operatore
count:TABLE_NAME | countPer ottenere lo schema di una tabella, usare l'operatore
getschema:TABLE_NAME | getschema
L'esecuzione di queste query sulle tabelle dei fatti e delle dimensioni nello scenario aziendale di vendita al dettaglio offre informazioni come l'esempio seguente:
| Tabella | Record | Schema |
|---|---|---|
| SalesFact | 2,832,193 | - SalesAmount (real) - TotalCost (real) - DateKey (datetime) - ProductKey (long) - CustomerKey (long) |
| Clienti | 18,484 | - CityName (string) - CompanyName (string) - ContinentName (string) - CustomerKey (long) - Education (string) - FirstName (string) - Gender (string) - LastName (string) - MaritalStatus (string) - Occupation (string) - RegionCountryName (string) - StateProvinceName (string) |
| Prodotti | 2,517 | - ProductName (string) - Manufacturer (string) - ColorName (string) - ClassName (string) - ProductCategoryName (string) - ProductSubcategoryName (string) - ProductKey (long) |
Nella tabella sono stati evidenziati gli identificatori univoci CustomerKey e ProductKey usati per combinare i record tra le tabelle.
Informazioni sulle query su più tabelle
Dopo aver analizzato i dati, è necessario comprendere come combinare le tabelle per fornire le informazioni necessarie. Le query Kusto forniscono diversi operatori che è possibile usare per combinare i dati di più tabelle, tra cui gli operatori lookup, join e union.
L'operatore join unisce le righe di due tabelle in base ai valori corrispondenti delle colonne specificate di ogni tabella. La tabella risultante dipende dal tipo di join usato. Ad esempio, se si usa un inner join, la tabella ha le stesse colonne della tabella sinistra (talvolta denominata tabella esterna), più le colonne della tabella destra (talvolta denominata tabella interna). Altre informazioni sui tipi di join sono disponibili nella sezione successiva. Per assicurare prestazioni migliori, se una tabella è sempre più piccola dell'altra, usarla come lato sinistro dell'operatore join.
L'operatore lookup è un'implementazione speciale di un operatore join che ottimizza le prestazioni delle query in cui una tabella dei fatti viene arricchita con i dati di una tabella delle dimensioni. Estende la tabella dei fatti con valori ricercati in una tabella delle dimensioni. Per prestazioni ottimali il sistema presuppone per impostazione predefinita che la tabella sinistra sia la tabella più grande (fatti) e la tabella destra sia la tabella più piccola (dimensioni). Questo presupposto è esattamente l'opposto del presupposto usato dall'operatore join .
L'operatore union restituisce tutte le righe di due o più tabelle. È utile quando si vogliono combinare i dati di più tabelle.
La funzione materialize() memorizza nella cache i risultati all'interno di un'esecuzione di query per consentirne il riutilizzo successivo nella query. È come creare uno snapshot dei risultati di una sottoquery e usarlo più volte all'interno della query. Questa funzione è utile per ottimizzare le query per gli scenari in cui i risultati:
- Sono dispendiosi da calcolare
- Non sono deterministici
Brevemente, vengono fornite altre informazioni sui vari operatori di unione di tabelle e sulla materialize() funzione e su come usarli.
Tipi di join
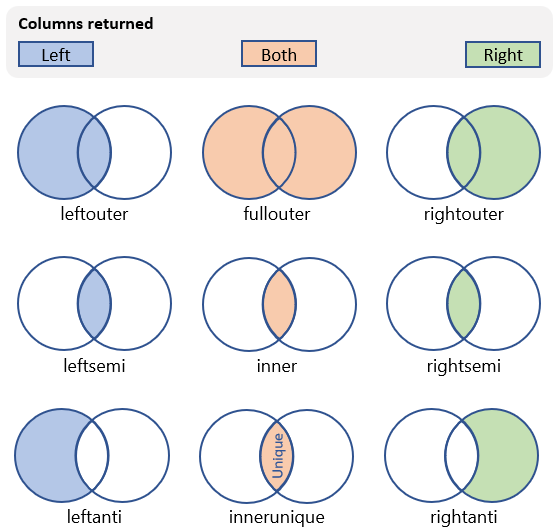
È possibile eseguire molti tipi diversi di join che influiscono sullo schema e sulle righe della tabella risultante. Nella tabella seguente sono illustrati i tipi di join supportati da Linguaggio di query Kusto, nonché lo schema e le righe restituite:
| Tipo di joint | Descrizione | Illustrazione |
|---|---|---|
innerunique (predefinito) |
Inner join con deduplicazione del lato sinistro Schema: tutte le colonne di entrambe le tabelle, incluse le chiavi corrispondenti Righe: tutte le righe deduplicate della tabella sinistra che corrispondono alle righe della tabella destra |

|
inner |
Inner join standard Schema: tutte le colonne di entrambe le tabelle, incluse le chiavi corrispondenti Righe: solo le righe corrispondenti di entrambe le tabelle |

|
leftouter |
Left outer join Schema: tutte le colonne di entrambe le tabelle, incluse le chiavi corrispondenti Righe: tutti i record della tabella sinistra e solo le righe corrispondenti della tabella destra |

|
rightouter |
Right outer join Schema: tutte le colonne di entrambe le tabelle, incluse le chiavi corrispondenti Righe: tutti i record della tabella destra e solo le righe corrispondenti della tabella sinistra |

|
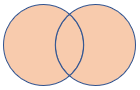
fullouter |
Full outer join Schema: tutte le colonne di entrambe le tabelle, incluse le chiavi corrispondenti Righe: tutti i record di entrambe le tabelle con celle non corrispondenti popolate con valori Null |
|
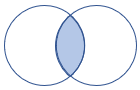
leftsemi |
Semi join di sinistra Schema: tutte le colonne della tabella sinistra Righe: tutti i record della tabella sinistra che corrispondono ai record della tabella destra |
|
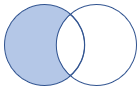
leftanti, anti, leftantisemi |
Variante anti join e semi join di sinistra Schema: tutte le colonne della tabella sinistra Righe: tutti i record della tabella sinistra che non corrispondono ai record della tabella destra |
|
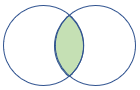
rightsemi |
Semi join di destra Schema: tutte le colonne della tabella destra Righe: tutti i record della tabella destra che corrispondono ai record della tabella sinistra |
|
rightanti, rightantisemi |
Variante anti join e semi join di destra Schema: tutte le colonne della tabella destra Righe: tutti i record della tabella destra che non corrispondono ai record della tabella sinistra |

|
Si noti che il tipo di join predefinito è inneruniquee non deve essere specificato. È tuttavia consigliabile specificare sempre in modo esplicito il tipo di join per maggiore chiarezza.
Durante l'avanzamento di questo modulo vengono fornite informazioni anche sulle arg_min() funzioni di aggregazione e arg_max() , l'operatore as come alternativa all'istruzione let e la funzione per facilitare il startofmonth() raggruppamento dei dati per mese.