Preparare i dati
Nota
Per una maggiore funzionalità, PyTorch può essere usato anche con DirectML in Windows.
Nella fase precedente di questa esercitazione è stato installato PyTorch nel computer. A questo punto, verrà usato per configurare il codice con i dati che verranno usati per creare il modello.
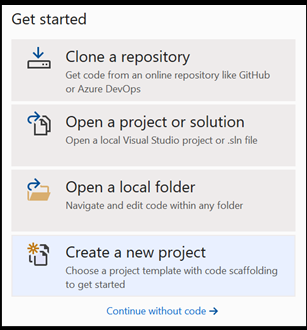
Aprire un nuovo progetto in Visual Studio.
- Aprire Visual Studio e scegliere
create a new project.
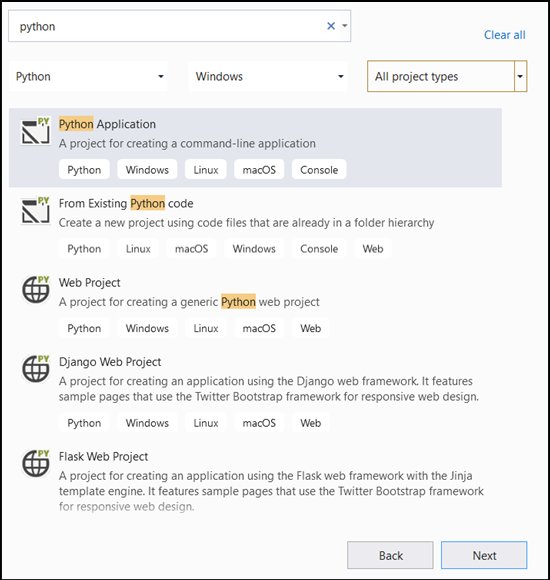
- Nella barra di ricerca digitare
Pythone selezionarePython Applicationcome modello di progetto.
- Nella finestra di configurazione:
- Assegnare un nome al progetto. Qui lo chiamiamo PyTorchTraining.
- Scegliere il percorso del progetto.
- Se si usa VS2019, verificare che
Create directory for solutionsia selezionata. - Se si esegue la ricerca di VISUAL Studio 2017, verificare che
Place solution and project in the same directorysia deselezionata.
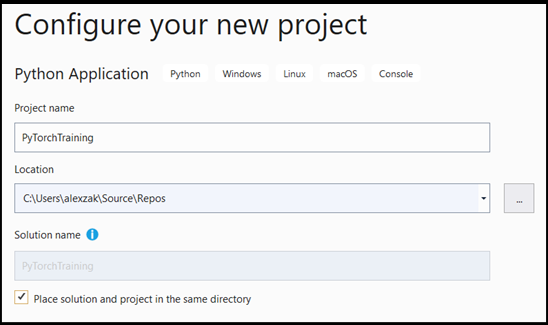
Premere create per creare il progetto.
Creare un interprete Python
A questo scopo, è necessario definire un nuovo interprete Python. Deve includere il pacchetto PyTorch installato di recente.
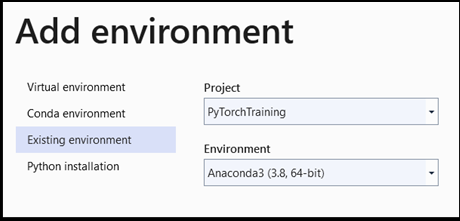
- Passare alla selezione dell'interprete e selezionare
Add environment:
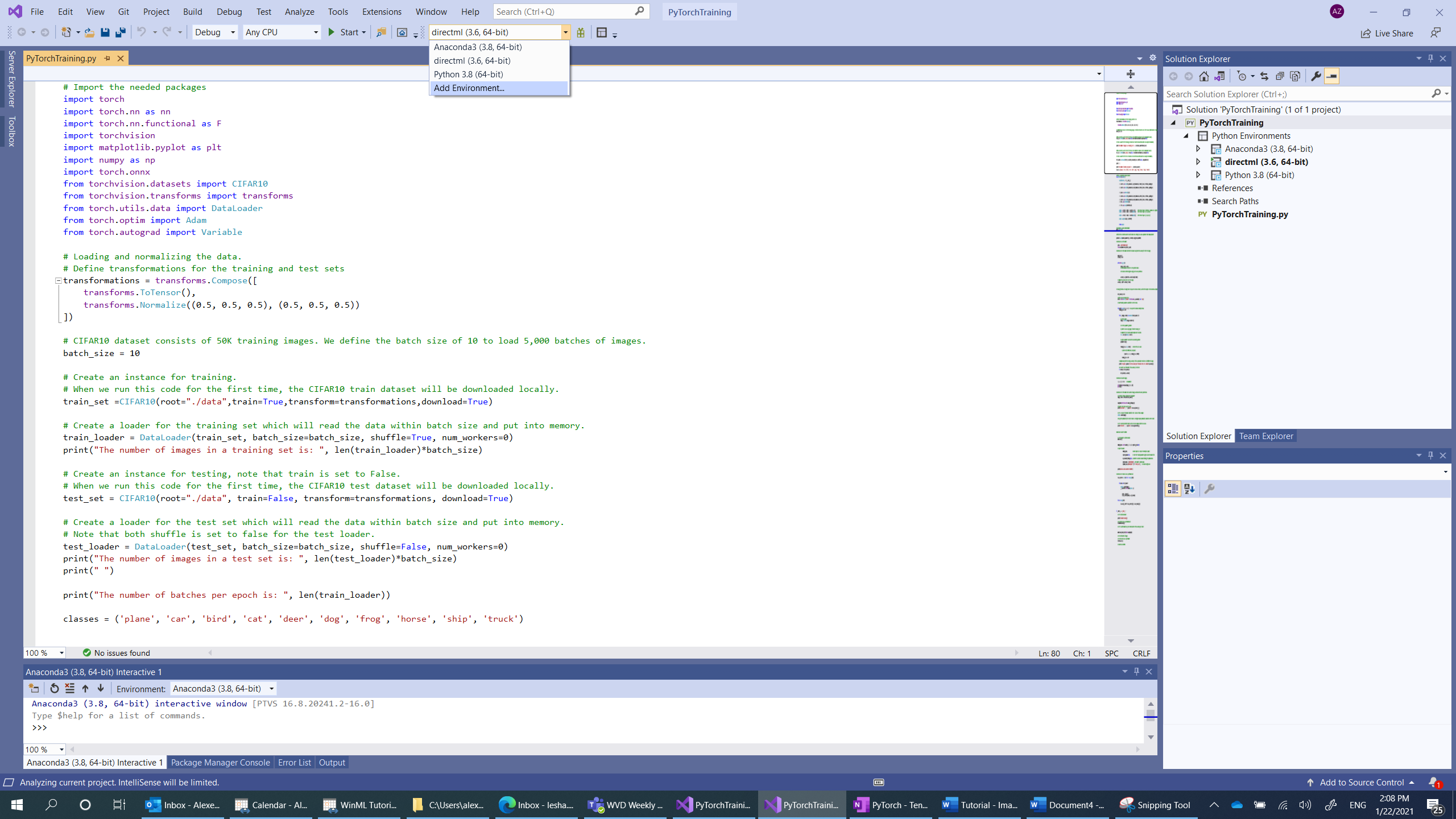
Add environmentNella finestra selezionareExisting environmente scegliereAnaconda3 (3.6, 64-bit). Questo include il pacchetto PyTorch.
Per testare il nuovo interprete Python e il pacchetto PyTorch, immettere il codice seguente nel PyTorchTraining.py file:
from __future__ import print_function
import torch
x=torch.rand(2, 3)
print(x)
L'output deve essere un tensore casuale 5x3 simile al seguente.
Nota
Sei interessato a scoprire di più? Visita il sito ufficiale di PyTorch.
Caricare il set di dati
Si userà la classe PyTorch torchvision per caricare i dati.
La libreria Torchvision include diversi set di dati comuni, ad esempio Imagenet, CIFAR10, MNIST e così via, architetture di modelli e trasformazioni di immagini comuni per la visione artificiale. Ciò rende il caricamento dei dati in PyTorch piuttosto un processo semplice.
CIFAR10
In questo caso si userà il set di dati CIFAR10 per compilare ed eseguire il training del modello di classificazione delle immagini. CIFAR10 è un set di dati ampiamente usato per la ricerca di Machine Learning. È costituito da 50.000 immagini di training e da 10.000 immagini di test. Tutte sono di dimensioni 3x32x32, il che significa immagini a colori a 3 canali di dimensioni di 32x32 pixel.
Le immagini sono suddivise in 10 classi: 'aereo' (0), 'automobile' (1), 'uccello' (2), 'gatto' (3), 'cervi' (4), 'cane' (5), 'rana' (6), 'cavallo' (7), 'nave' (8), 'camion' (9).
Si seguiranno tre passaggi per caricare e leggere il set di dati CIFAR10 in PyTorch:
- Definire le trasformazioni da applicare all'immagine: per eseguire il training del modello, è necessario trasformare le immagini in tensori dell'intervallo normalizzato [-1,1].
- Creare un'istanza del set di dati disponibile e caricare il set di dati: per caricare i dati, si userà la
torch.utils.data.Datasetclasse , ovvero una classe astratta per rappresentare un set di dati. Il set di dati verrà scaricato in locale solo la prima volta che si esegue il codice. - Accedere ai dati usando DataLoader. Per ottenere l'accesso ai dati e inserire i dati in memoria, si userà la
torch.utils.data.DataLoaderclasse . DataLoader in PyTorch esegue il wrapping di un set di dati e fornisce l'accesso ai dati sottostanti. Questo wrapper conterrà batch di immagini per ogni dimensione del batch definita.
Questi tre passaggi verranno ripetuti sia per i set di training che per i set di test.
PyTorchTraining.py fileAprire in Visual Studio e aggiungere il codice seguente. In questo modo vengono gestiti i tre passaggi precedenti per i set di dati di training e test dal set di dati CIFAR10.
from torchvision.datasets import CIFAR10
from torchvision.transforms import transforms
from torch.utils.data import DataLoader
# Loading and normalizing the data.
# Define transformations for the training and test sets
transformations = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# CIFAR10 dataset consists of 50K training images. We define the batch size of 10 to load 5,000 batches of images.
batch_size = 10
number_of_labels = 10
# Create an instance for training.
# When we run this code for the first time, the CIFAR10 train dataset will be downloaded locally.
train_set =CIFAR10(root="./data",train=True,transform=transformations,download=True)
# Create a loader for the training set which will read the data within batch size and put into memory.
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=0)
print("The number of images in a training set is: ", len(train_loader)*batch_size)
# Create an instance for testing, note that train is set to False.
# When we run this code for the first time, the CIFAR10 test dataset will be downloaded locally.
test_set = CIFAR10(root="./data", train=False, transform=transformations, download=True)
# Create a loader for the test set which will read the data within batch size and put into memory.
# Note that each shuffle is set to false for the test loader.
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False, num_workers=0)
print("The number of images in a test set is: ", len(test_loader)*batch_size)
print("The number of batches per epoch is: ", len(train_loader))
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
La prima volta che si esegue questo codice, il set di dati CIFAR10 verrà scaricato nel dispositivo.

Passaggi successivi
Con i dati pronti per l'uso, è possibile eseguire il training del modello PyTorch