Document Intelligence の請求書モデル
このコンテンツの適用対象: ![]() v4.0 (GA) | 以前のバージョン:
v4.0 (GA) | 以前のバージョン: ![]() v3.1 (GA)
v3.1 (GA) ![]() v3.0 (GA)
v3.0 (GA) ![]() v2.1 (GA)
v2.1 (GA)
::: moniker-end
このコンテンツの適用対象: ![]() v2.1 | 最新バージョン:
v2.1 | 最新バージョン: ![]() v4.0 (GA)
v4.0 (GA)
Document Intelligence の請求書モデルでは、強力な光学式文字認識 (OCR) 機能を使用して、売上請求書、公共料金、および発注書から主要なフィールドと明細項目を分析および抽出します。 電話でキャプチャされた画像、スキャンされたドキュメント、デジタル PDF など、さまざまな形式や品質の請求書を使用できます。 API によって請求書のテキストが分析され、顧客名、請求先住所、期限、支払金額などの主要な情報が抽出されて、構造化された JSON データ表現が返されます。 このモデルでは現在、27 の言語の請求書がサポートされています。
サポートされているドキュメントの種類:
- Invoices
- 光熱費
- 販売注文
- 注文書
自動請求書処理
自動請求書処理は、課金アカウント ドキュメントから accounts payable の主要なフィールドを抽出するプロセスです。 抽出されたデータには、レビューと支払いのために買掛金勘定 (AP) ワークフローと統合された請求書からの明細が含まれます。 これまで、買掛金勘定プロセスは手動で行われ、そのため、非常に時間がかかっていました。 請求書からキー データを正確に抽出することは、通常、請求書の自動化プロセスの最も重要な手順の 1 つです。
Document Intelligence Studio で処理された請求書サンプル:

Document Intelligence サンプル ラベル付けツールで処理された請求書サンプル:
開発オプション
Document Intelligence v4.0: 2024-11-30 (GA) では、以下のツール、アプリケーション、ライブラリがサポートされています。
| 機能 | リソース | モデル ID |
|---|---|---|
| 請求書モデル | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-invoice |
Document Intelligence v3.1 では、次のツール、アプリケーション、ライブラリがサポートされています。
| 機能 | リソース | モデル ID |
|---|---|---|
| 請求書モデル | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-invoice |
ドキュメント インテリジェンス v3.0 では、次のツール、アプリケーション、およびライブラリがサポートされています:
| 機能 | リソース | モデル ID |
|---|---|---|
| 請求書モデル | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-invoice |
Document Intelligence v2.1 では、次のツール、アプリケーション、ライブラリがサポートされています。
| 機能 | リソース |
|---|---|
| 請求書モデル | • Document Intelligence ラベル付けツール • REST API • クライアント ライブラリ SDK • Document Intelligence Docker コンテナー |
入力の要件
サポートされているファイル形式:
モデル PDF 画像: JPEG/JPG、PNG、BMP、TIFF、HEIFMicrosoft Office:
Word (DOCX)、Excel (XLSX)、PowerPoint (PPTX)、HTML読み込み ✔ ✔ ✔ Layout ✔ ✔ ✔ 一般的なドキュメント ✔ ✔ 事前構築済み ✔ ✔ カスタム抽出 ✔ ✔ カスタム分類 ✔ ✔ ✔ 最適な結果を得るには、ドキュメントごとに 1 つの鮮明な写真または高品質のスキャンを提供してください。
PDF および TIFF の場合、最大 2,000 ページを処理できます (Free レベルのサブスクリプションでは、最初の 2 ページのみが処理されます)。
ドキュメントを分析するためのファイル サイズは、有料 (S0) レベルでは 500 MB、無料 (F0) レベルでは
4MB です。画像のディメンションは、50 ピクセル x 50 ピクセルから 10,000 ピクセル x 10,000 ピクセルの間である必要があります。
PDF がパスワードでロックされている場合は、送信前にロックを解除する必要があります。
抽出するテキストの最小の高さは、1024 x 768 ピクセルのイメージの場合は 12 ピクセルです。 このディメンションは、150 DPI (1 インチあたりのドット数) で約
8ポイントのテキストに相当します。カスタム モデル トレーニングにおけるトレーニング データの最大ページ数は、カスタム テンプレート モデルの場合は 500、カスタム ニューラル モデルの場合は 50,000 です。
カスタム抽出モデル トレーニングにおけるトレーニング データの合計サイズは、テンプレート モデルの場合は 50 MB、ニューラル モデルの場合は
1GB です。カスタム分類モデル トレーニングの場合、トレーニング データの合計サイズは
1GB で、最大 10,000 ページです。 2024-11-30 (GA) の場合、トレーニング データの合計サイズは2GB で、最大 10,000 ページです。
- サポートされているファイル形式: JPEG、PNG、PDF、TIFF。
- PDF と TIFF では、最大 2,000 ページまでの処理がサポートされています。 Free レベルのサブスクライバーの場合は、最初の 2 ページだけが処理されます。
- サポートされているファイル サイズは 50 MB 未満で、寸法は 50 x 50 ピクセル以上、10,000 x 10,000 ピクセル以下でなければなりません。
請求書モデル データの抽出
顧客情報、ベンダーの詳細、品目などのデータが請求書からどのように抽出されるかをご覧ください。 以下のリソースが必要です。
Azure サブスクリプション—無料で作成できます。
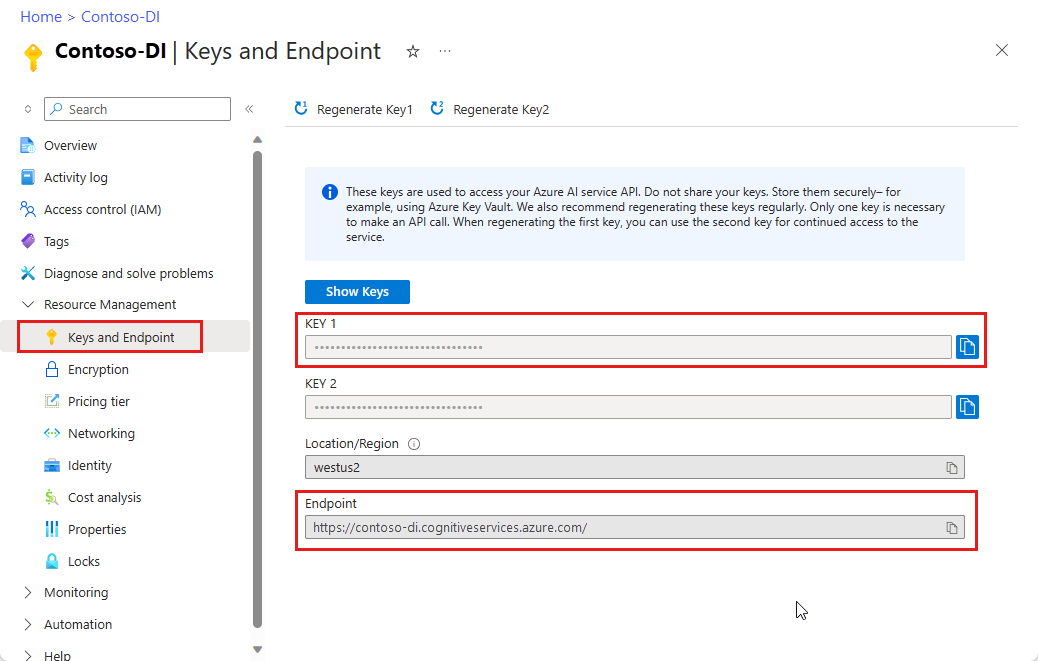
Azure portal の Document Intelligence Studio インスタンス。 Free 価格レベル (
F0) を利用して、サービスを試用できます。 リソースがデプロイされたら、[リソースに移動] を選択してキーとエンドポイントを取得します。
Document Intelligence Studio ホーム ページで、[請求書] を選択します。
サンプル請求書を分析したり、独自のファイルをアップロードしたりできます。
分析実行 ボタンを選択し、必要に応じて 分析オプション を構成します:
![Document Intelligence Studio の [分析の実行] と [分析オプション] ボタンのスクリーンショット。](../media/studio/run-analysis-analyze-options.png?view=doc-intel-4.0.0)
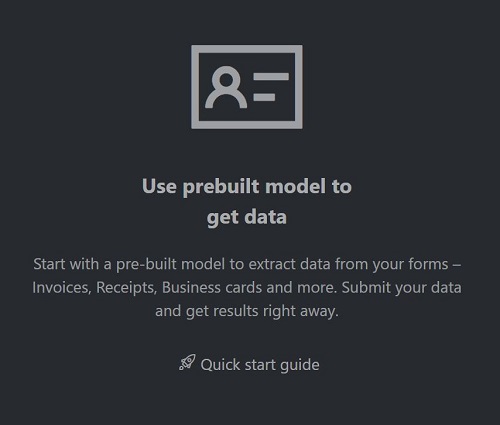
ドキュメント インテリジェンス サンプル ラベル付けツール
サンプル ツールのホーム ページで、[事前構築済みモデルを使用してデータを取得する] タイルを選択します。
ドロップダウン メニューから、分析する [フォームの種類] を選択します。
次のオプションを使用して、分析するファイルの URL を選択します。
[ソース] フィールドで、ドロップダウン メニューから [URL] を選択し、選択した URL を貼り付けて、[フェッチ] ボタンを選択します。

[Document Intelligence サービス エンドポイント] フィールドに、Document Intelligence サブスクリプションで取得したエンドポイントを貼り付けます。
[キー] フィールドに、Document Intelligence リソースから取得したキーを貼り付けます。
![[フォームの種類の選択] ドロップダウン メニューを示すスクリーンショット。](../media/fott-select-form-type.png?view=doc-intel-4.0.0)
[Run analysis](解析の実行) を選択します。 Document Intelligence サンプル ラベル付けツールは、Analyze Prebuilt API を呼び出してドキュメントを分析します。
結果を表示する - 抽出されたキーと値のペア、行項目、抽出された強調表示テキスト、および検出されたテーブルを確認します。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Note
サンプル ラベル付けツールでは、BMP ファイル形式はサポートされていません。 これは、Document Intelligence サービスではなくツールの制限です。
サポートされている言語とロケール
サポートされている言語の完全な一覧については、事前構築済みモデルの言語サポートに関するページを "参照" してください。
フィールドの抽出
サポートされているドキュメント抽出フィールドについては、GitHub サンプル リポジトリの請求書モデル スキーマに関するページを "参照してください"。
抽出された請求書のキーと値のペアと品目は、JSON 出力の
documentResultsセクションにあります。
キー値ペア
事前構築済みの請求書モデルでは、オプションとしてキーと値のペアを返すことがサポートされています。 既定では、キーと値のペアの戻り値は無効になっています。 キーと値のペアは、ラベルまたはキーとそれに関連する応答または値を識別する、請求書内の特定の範囲です。 請求書では、これらのペアはラベルと、そのフィールドまたは電話番号に対してユーザーが入力した値になります。 さまざまなドキュメントの種類、形式、構造に基づいて、識別可能なキーと値を抽出するために、AI モデルがトレーニングされています。
モデルによってキーの存在が検出されても、関連する値がない場合や、省略可能なフィールドの処理では、キーが単独で存在する可能性もあります。 たとえば、一部のインスタンスでは、フォームのミドル ネーム フィールドを空白のままにすることができます。 キーと値のペアは常に、ドキュメントに含まれるテキストの範囲です。 "顧客" と "ユーザー" など、同じ値が異なる方法で記述されるドキュメントの場合、関連付けられているキーは、(コンテキストに基づき) 顧客またはユーザーのいずれかです。
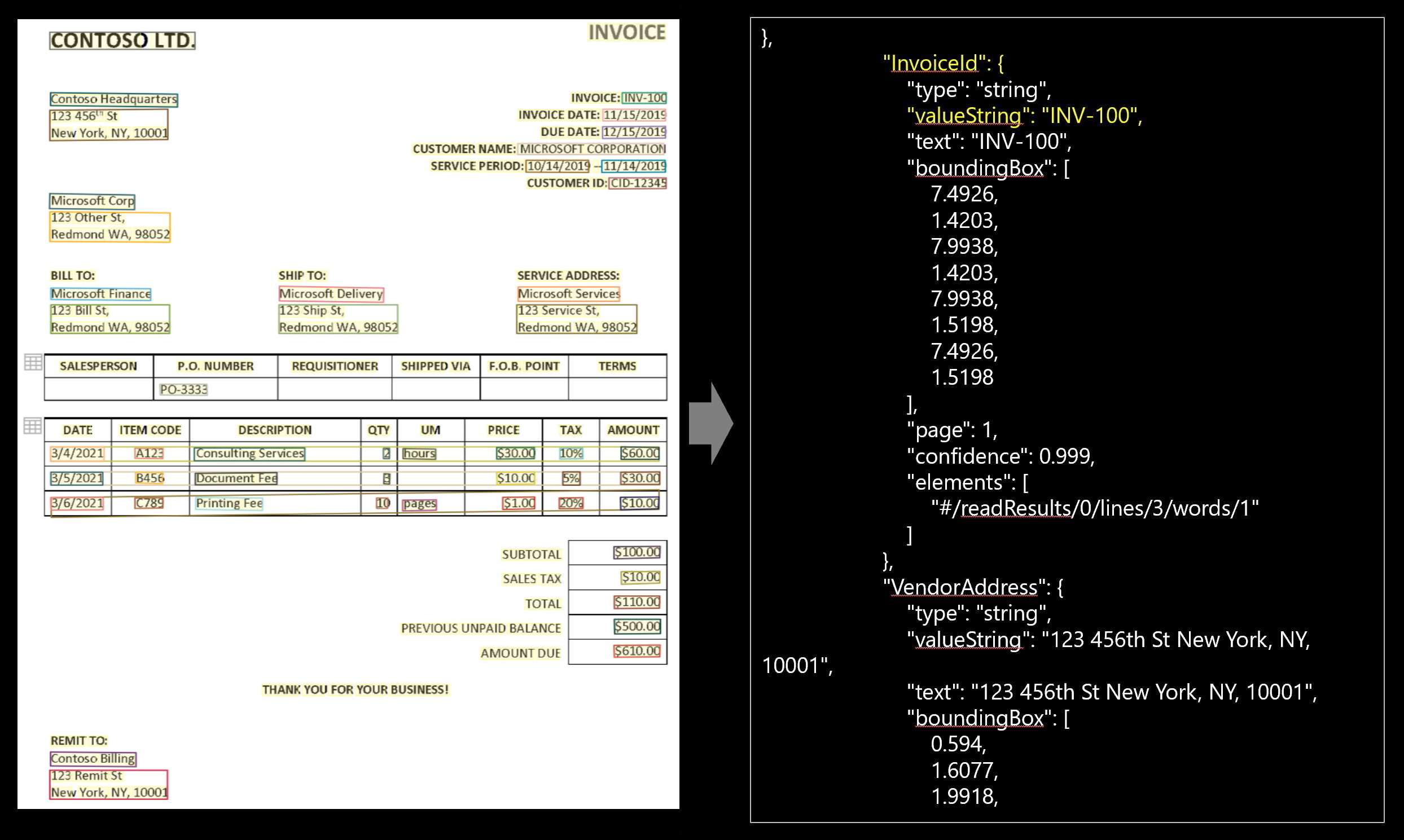
JSON 出力
JSON 出力には、次の 3 つの部分があります。
"readResults"ノードには、認識されたすべてのテキストと選択マークが格納されます。 テキストは、まずページで整理され、そのうえで行ごと、さらに個々の単語ごとに整理されます。"pageResults"ノードには、境界ボックスで抽出されたテーブルとセル、信頼度、および readResults 内の行と単語への参照が格納されます。"documentResults"ノードには、モデルによって検出された請求書固有の値と品目が格納されます。 ここで、請求書 ID、出荷先、請求先、顧客、合計、品目など、請求書のすべてのフィールドを参照できます。
移行ガイド
- アプリケーションとワークフローで v3.0 バージョンを使用する方法については、Document Intelligence v3.1 への移行ガイドの説明を参照してください。
::: moniker-end
次のステップ
Document Intelligence Studio を使用して独自のフォームとドキュメントの処理を試す。
Document Intelligence クイックスタートを完了し、選択した開発言語でドキュメント処理アプリの作成を開始します。
Document Intelligence サンプル ラベル付けツールを使用して独自のフォームとドキュメントの処理を試す。
Document Intelligence クイックスタートを完了し、選択した開発言語でドキュメント処理アプリの作成を開始します。