プロフェッショナルな音声プロジェクトにボイス タレントの同意を追加する
ボイス タレントは個人または対象話者であり、その音声が録音され、ニューラル音声モデルの作成に使用されます。
ニューラル音声をトレーニングする前に、ボイス タレントの同意ステートメントの録音を送信する必要があります。 ボイス タレント ステートメントは、音声データを使用してカスタム音声モデルをトレーニングすることに同意するステートメントを読み上げるボイス タレントの録音です。 同意ステートメントは、ボイス タレントがトレーニング データの話者と同じ人物であることを確認するためにも使用されます。
ヒント
Speech Studio で作業を開始する前に、音声ペルソナを定義し、適切なボイス タレントを選択します。
複数の言語のボイス タレントの同意ステートメントを、GitHub で入手できます。 口頭によるステートメントの言語は、録音の言語と同じである必要があります。 「ボイス タレント向けの開示」も参照してください。
ボイス タレントの追加
ボイス タレント プロファイルを追加し、同意ステートメントをアップロードするには、次の手順に従います。
- Speech Studio にサインインします。
- [Custom Voice]> [プロジェクト名] >[ボイス タレントの設定]>[ボイス タレントの追加] の順に選択します。
- [新しいボイス タレントの追加] ウィザードで、作成する音声の特性について説明します。 ここで指定するシナリオは、アプリケーション フォームで指定したシナリオと一致している必要があります。
- [次へ] を選択します。
- [ボイス タレント ステートメントのアップロード] ページで、指示に従って、事前に録音したボイス タレント ステートメントをアップロードします。 ボイス タレント ステートメントが、トレーニング データと同じ設定、環境、話し方で録音されていることを確認します。
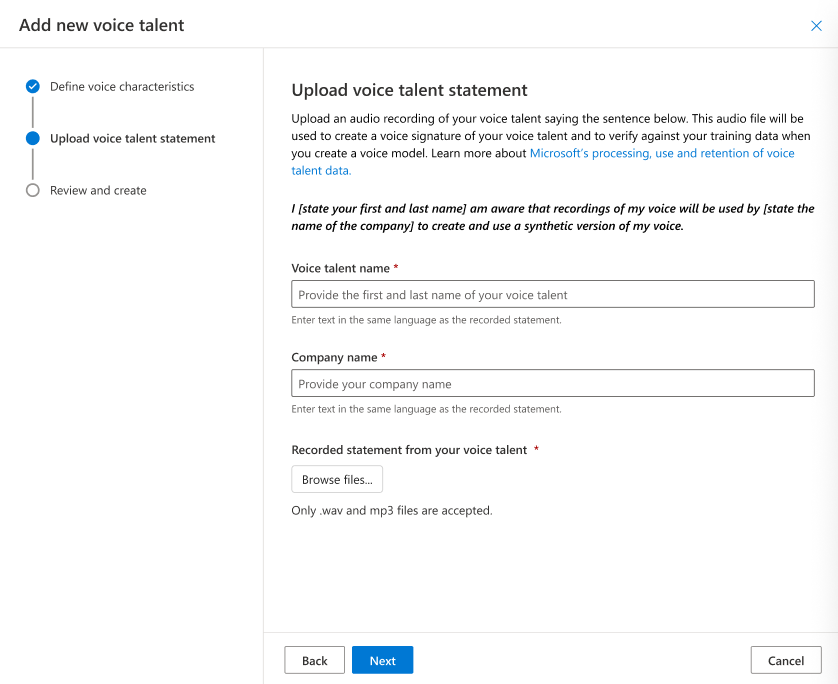
- ボイス タレント名と会社名を入力します。 ボイス タレント名は、同意ステートメントを録音した人の名前である必要があります。 録音されたステートメントで使用されたのと同じ言語で名前を入力します。 会社名は、録音されたステートメントで読み上げられた会社名と一致する必要があります。 会社名が録音されたステートメントと同じ言語で入力されていることを確認します。
- [次へ] を選択します。
- ボイス タレントとペルソナの詳細を確認し、[送信] を選択します。
ボイス タレントのステータスが [成功] になったら、カスタム音声モデルのトレーニングに進むことができます。
次のステップ
Professional Voice 機能では、すべての音声がユーザーの明示的な同意のもとに作成される必要があります。 お客様 (Azure AI Speech リソース所有者) が自身の音声を作成および使用することに同意する、ユーザーの録音されたステートメントが必要です。
プロフェッショナルな音声プロジェクトにボイス タレントの同意を追加するには、パブリックにアクセスできる URL (Consents_Create) から事前に録音された同意のオーディオ ファイルを取得するか、オーディオ ファイル (Consents_Post) をアップロードします。 この記事では、URL から同意を追加します。
同意書
ユーザーが同意ステートメントを読んでいる音声の録音が必要です。
各ロケールの同意ステートメント テキストは、GitHub のテキスト読み上げリポジトリから取得できます。 en-US ロケールの同意ステートメントについては、SpeakerAuthorization.txt を参照してください。
"I [state your first and last name] am aware that recordings of my voice will be used by [state the name of the company] to create and use a synthetic version of my voice."
URL から同意を追加する
オーディオ ファイルの URL からプロフェッショナルな音声プロジェクトに同意を追加するには、Custom Voice API の Consents_Create 操作を使用します。 次の手順に従って要求本文を作成します。
- 必須の
projectIdプロパティを設定します。 プロジェクトの作成に関する記事を参照してください。 - 必須の
voiceTalentNameプロパティを設定します。 ボイス タレント名は、同意ステートメントを録音した人の名前である必要があります。 録音されたステートメントで使用されたのと同じ言語で名前を入力します。 ボイス タレント名を後から変更することはできません。 - 必須の
companyNameプロパティを設定します。 会社名は、録音されたステートメントで読み上げられた会社名と一致する必要があります。 会社名が録音されたステートメントと同じ言語で入力されていることを確認します。 会社名を後から変更することはできません。 - 必須の
audioUrlプロパティを設定します。 ボイス タレントの同意オーディオ ファイルの URL。 Shared Access Signature (SaS) トークンを含む URI を使用します。 - 必須の
localeプロパティを設定します。 これは、同意のロケールにする必要があります。 ロケールを後から変更することはできません。 テキスト読み上げロケールの一覧はこちらにあります。
次の Consents_Create の例に示したように URI を使用して HTTP PUT 要求を行います。
YourResourceKeyをSpeech リソース キーに置き換えます。YourResourceRegionを Speech リソース リージョンに置き換えます。JessicaConsentIdを任意の同意 ID に置き換えます。 大文字と小文字を区別する ID が同意の URI で使用され、後で変更することはできません。
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"description": "Consent for Jessica voice",
"projectId": "ProjectId",
"voiceTalentName": "Jessica Smith",
"companyName": "Contoso",
"audioUrl": "https://contoso.blob.core.windows.net/public/jessica-consent.wav?mySasToken",
"locale": "en-US"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/consents/JessicaConsentId?api-version=2024-02-01-preview"
次の形式で応答本文を受け取る必要があります。
{
"id": "JessicaConsentId",
"description": "Consent for Jessica voice",
"projectId": "ProjectId",
"voiceTalentName": "Jessica Smith",
"companyName": "Contoso",
"locale": "en-US",
"status": "NotStarted",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
応答ヘッダーに Operation-Location プロパティが含まれています。 この URI を使用して、Consents_Create 操作の詳細を取得します。 応答ヘッダーの例を次に示します。
Operation-Location: https://eastus.api.cognitive.microsoft.com/customvoice/operations/070f7986-ef17-41d0-ba2b-907f0f28e314?api-version=2024-02-01-preview
Operation-Id: 070f7986-ef17-41d0-ba2b-907f0f28e314